Gaussian Process Gaussian Process is a very interesting/beautiful model. Besides the classic book Gaussian Processes for Machine Learning (http://www.gaussianprocess.org/gpml/), several sources can be referred as a very basic introduction of the topic:
- http://cs229.stanford.edu/section/cs229-gaussian_processes.pdf (I highly recommend this)
- http://www.cs.ubc.ca/~nando/540-2013/lectures/l6.pdf (I highly recommend this)
- http://katbailey.github.io/post/gaussian-processes-for-dummies/
- https://www.robots.ox.ac.uk/~mebden/reports/GPtutorial.pdf
- http://people.eng.unimelb.edu.au/tcohn/papers/gptut_alta14.pdf (I highly recommend this once you have some basic understanding of GPs)
- http://etheses.whiterose.ac.uk/9968/1/Damianou_Thesis.pdf (I highly recommend this once you have some basic understanding of GPs)
Even with those references, it is still quite difficult to start learning the topic. I guess this happens for many people. Here I want to give a very informal introduction to the topic.
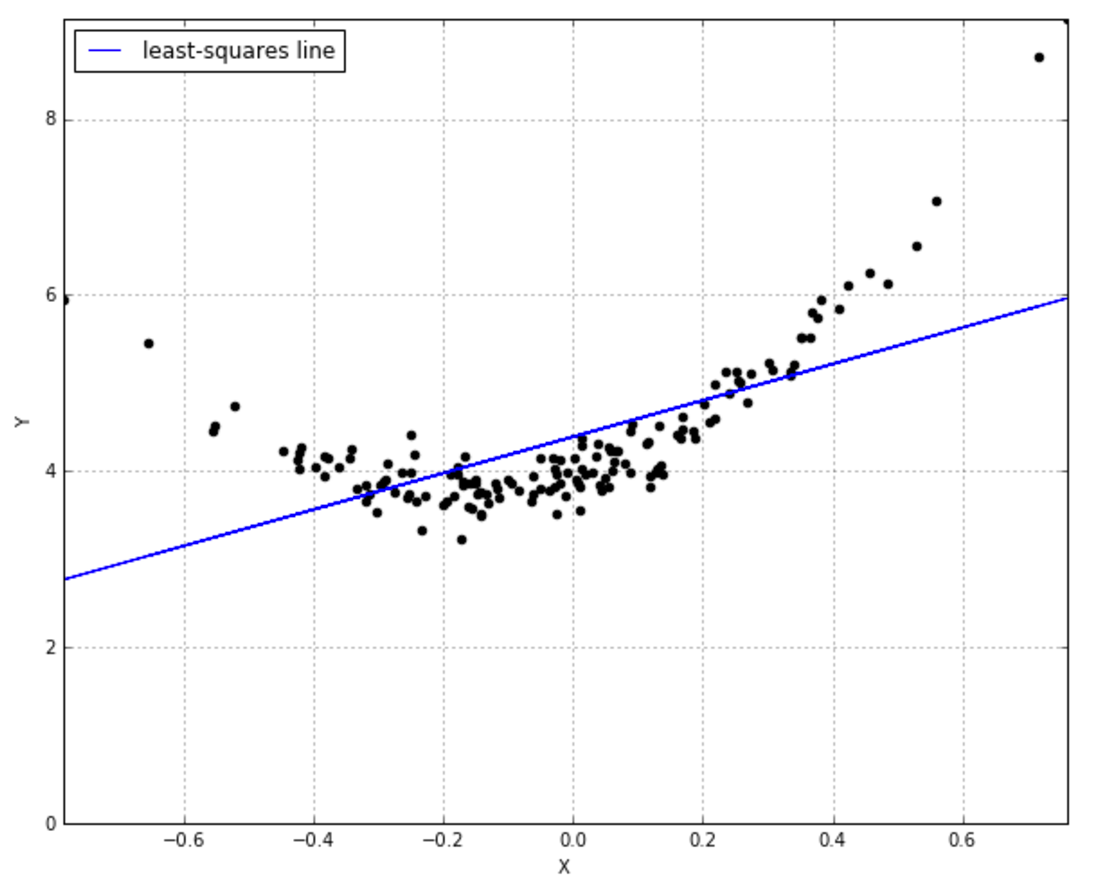
So what is GP? You can think GP as distribution over functions. It sounds fancy at first sights, but the concept is indeed straightforward. First, why do we need a set of functions instead of a specific and useful function? Think about this: in practice we may want to perform a regression, but there doesn't exist any specific function that you defined in advance, e.g. y = ax+b, that perfectly matches the data) (See this: http://katbailey.github.io/images/bad_least_squares.png). Because we cannot define such a function in advance, we then let them free: let the data speaks by itself, i.e. the shape of our functions is totally induced by the data. What we need to control is simply the type of distribution of functions. GPs assume that the function's outputs can be sampled from a multivariate Gaussian distribution with mean U and covariate matrix K in which each element ij in the matrix is defined by a specific kernel function k(x_i, x_j).
{kind=link}
Concretely, you can imagine you have a subset of points from an infinite number of points:
[x_1 = 1, x_2 = 2, x_3 = 3, x_4 = 4, x_5 = 5]
You also have a set of N functions f_1, f_2, ..., f_N from an infinite number of functions. Each specific function f transforms the set of points to another space:
[f(1), f(2), f(3), f(4), f(5)].
Let us assume we have 1000000 (It doesn't matter the specic number such functions). GPs assume [f(1), f(2), f(3), f(4), f(5)] from those 1000000 functions are sampled from a multivariate Gaussian distribution. The size of U is N, and the size of K is NxN.
Not all arbitrary matrices K give us valid Gaussian Processes: each covariate matrix needs to be positive semidefinite, i.e. x^T K x >= 0 for all vector x with size N. But how to check a matrix is positive semidefinite? I don't see many articles about this, perhaps it is not easy to do so. Also we normally don't have to do much in practice because kernel functions are well studied (well-studied valid kernel functions can be referred to this link: http://www.cs.toronto.edu/~duvenaud/cookbook/index.html). Perhaps squared exponential kernel (k(x, x') = sigma^2 exp(-0.5 * (1/param)^2 (x - x') ^ 2) is the most common one. For the sake of simplicity, I ignore sigma and param now, but keep in mind that they can be tuned automatically. This is never easier with modern automatic differentation toolkits such as autograd https://github.com/HIPS/autograd.
So the take home message is that a GP specifies a probability distribution over functions at infinite number of input points with two notable things: First, the distribution is Gaussian distribution, so that the marginal distribution over any subset of input points must have a joint multivariate Gaussian distribution (see this https://en.wikipedia.org/wiki/Multivariate_normal_distribution#Two_normally_distributed_random_variables_need_not_be_jointly_bivariate_normal). Second, the output of the function at those points to be similar if the kernel function at those points to be similar. Now you know why people usually say: "A GP defines a prior over functions". Prior means the way we assume the function's outputs can be sampled from a multivariate Gaussian distribution and the way define the kernel function.
Let me show some basic code https://github.com/hoangcuong2011/GPs. Let us assume we have 40 points
import numpy as np
import matplotlib.pyplot as pl
n = 40
Xtest = np.linspace(0, 10, n).reshape(-1,1)
Our kernel function is squared exponential kernel:
def SquaredExponentialKernel(a, b):
sqdist = (np.sum(a, 1).reshape(-1,1) - np.sum(b,1))**2
return np.exp(-.5 * sqdist)
With that kernel function, our covariate matrix is as follows:
K_ss = SquaredExponentialKernel(Xtest, Xtest)
Let us assume we want to draws 100 functions over these points. All we need to do is to sample 100 vectors from a multivariate Gaussian distribution with mean [0, ....., 0] and covariate matrix K_ss. The code is as follows:
dataPoints = 100
L = np.linalg.cholesky(K_ss + 1e-15*np.eye(n))
f_prior = np.dot(L, np.random.normal(size=(n,dataPoints)))
pl.plot(Xtest, f_prior)
pl.axis([0, 10, -5, 5])
pl.title('Samples from the GP prior')
pl.show()
Note that the code involves Get Cholesky decomposition (see this https://en.wikipedia.org/wiki/Multivariate_normal_distribution to know why)
That is all: we have just plotted a set of functions that the outputs are sampled from a motivariate zero-mean Gaussian distribution and covariate matrix K_ss.
There are plenty applications of Gaussian processes. Let me explain a toy example with The Gaussian process regression model to see how useful it is. I took the example from http://cs229.stanford.edu/section/cs229-gaussian_processes.pdf
We are given a training dataset of m i.i.d. examples: S = {x_i, y_i}. Let us assume a regression model:
y_i = f(x_i) + epsilon_i
where epsilon_i are i.i.d. noise variables with independent zero-mean and fixed variance Gaussian distribution. We assume a prior distribution over f: a zero-mean Gaussian prior: GP(0, k(.,.)).
At training time, we want to predict y*_j given each sample x*_j from a set of m* i.i.d. examples: S* = {x*_j}
As we assume a prior distribution over f: a zero-mean Gaussian prior, we have:
f, f*| X, X* sample from N(0, K) where K contains four sub-matrices: K(X,X), K(X, X*), K(X*, X), K(X*, X*)
From our i.i.d. noise assumption, we have that
epsilon, epsilon* sample from N(0, K) where K contains four sub-matrices: sigma^2I, 0, 0^T, sigma^2I
Recall that y_i = f(x_i) + epsilon_i and y*_i = f(x*_i) + epsilon*_i, we have
y, y*| X, X* sample from N(0, K) where K contains four sub-matrices: K(X,X)+sigma^2I, K(X, X*), K(X*, X), K(X*, X*)sigma^2I
In the end, we can derive y*| y, X, X* from y, y*| X, X* using the rules for conditioning Gaussian (See this http://cs229.stanford.edu/section/more_on_gaussians.pdf).
y*| y, X, X* sample from N(u*, SIGMA*), where
u* = K(X*,X)(K(X,X)+sigma^2 I)^-1 y
SIGMA* = K(X*, X*) +sigma^2 I - K(X*, X)(K(X, X)+sigma^2 I)^-1 K(X, X*)^T
Time for some code again. For convenience, I ignore the noise components in the model.
K_testtest = SquaredExponentialKernel(Xtest, Xtest, param)
Xtrain = np.array([Xtest[3], Xtest[5], Xtest[11]]).reshape(-1,1)
ytrain = np.sin(Xtrain) # I assume y = sin(x)
mu = np.dot(np.dot(K_testtrain, np.linalg.inv(K_traintrain)), ytrain)
SIGMA = K_testtest - np.dot(np.dot(K_testtrain, np.linalg.inv(K_traintrain)), K_traintest.T)
That is all. Now let us sample 100 vectors from a multivariate Gaussian distribution with mean vector mu and covariate matrix SIGMA. The code is as follows:
L = np.linalg.cholesky(SIGMA + 1e-6*np.eye(n))
f_post = mu.reshape(-1,1) + np.dot(L, np.random.normal(size=(n,100)))
pl.plot(Xtrain, ytrain, 'bs', ms=8)
pl.plot(Xtest, f_post)
pl.axis([-5, 5, -3, 3])
pl.title('Samples from the GP posterior')
pl.show()
You can change the line of code (Xtrain = np.array([Xtest[3], Xtest[5], Xtest[11]]).reshape(-1,1)) to have funs with different training examples. As the number of training examples increases, the size of the confidence region shrinks. This reflects the diminishing uncertainty in the model estimates.
Performing prediction in a Gaussian process regression model is indeed very simple and elegant. One problem with the model is computational cost: it takes O(N^3) to do inference. In practice, this problem is solved with a very neat idea of sparse GPs (See this for a reference https://github.com/hoangcuong2011/Good-Papers/blob/master/Sparse%20Gaussian%20Processes%20using%20Pseudo-inputs.md)
Updated (1st August 2017): Good code for Gaussian Processes https://github.com/keyonvafa/Gaussian-Process/blob/master/GP%20Regression.ipynb