作者: hengyizheng, ruiwen
| 赛题 | 特点 | 成绩 |
|---|---|---|
| CCKS 2020: 面向试验鉴定的命名实体识别任务(军事科学院系统工程研究院)https://www.biendata.xyz/competition/ccks_2020_8/ | 数据集样本少(训练集400,测试集400,平均长度150,最大长度358),专业名词(军事领域),实体类别(试验要素、性能指标、系统组成、任务场景)易混淆。 | top1 |
| CCKS 2020:面向中文电子病历的医疗实体及事件抽取(一)医疗命名实体识别(医渡云)https://www.biendata.xyz/competition/ccks_2020_2_1/ | 数据集(训练集1050,测试集300,平均长度410,最大长度1664),实体边界不明确(大多是标注带来的问题) | top5 |
评测指标:

- 文本长度分布

- 实体个数(不同类别)与长度分布
- 训练集所有实体及出现次数

- Bad-case分析:对比验证集模型结果与真实标签差异,寻找模型结果存在的问题。例如军事比赛通过Bad-case分析得知,模型对于实体边界的判断较为准确,问题在于模型对实体类别存在混淆(实体类别的区分度较低),如部分实体在试验要素与系统组成、试验要素与任务场景之间难以区分。
- 对比不同单模或不同融合结果之间的差异,引导后处理规则的编写。
模型结构:[PreTrain-Model]+[Encoder]+CRF
PreTrain-Model: ELECTRA[1], RoBERTa, NEZHA[2]
Encoder: Bi-LSTM, IDCNN, TENER[3], R-Transformer[4]
| Bi-LSTM | ID-CNN | Transformer | TENER | R-Transformer | |
|---|---|---|---|---|---|
| 方向信息 | 高 | 差 | 差 | 中 | 中 |
| 相对距离信息 | 高 | 差 | 差 | 中 | 中 |
| 局部信息 | 差 | 高 | 差 | 差 | 高 |
| 长距离依赖 | 中 | 差 | 高 | 高 | 高 |
| 可并行(效率) | 差 | 高 | 高 | 高 | 中 |
Silver Bullet:
-
相对距离信息,方向信息,长距离依赖
-
局部信息
-
可并行
所用方法:
BERT多层表征融合[5]
Word Augment[6]
动态规划文本分割[7]
K-Fold Cross Validation
部分单模实验结果:
| 模型 | 策略 | 分数(线下/线上) | |
|---|---|---|---|
| ex1 | NEZHA+LSTM+CRF | dp分割文本(max_seq_len=128),五折(融合5-->1),融合后去重叠 | 0.594/0.669 |
| ex1-1 | NEZHA+LSTM+CRF | dp分割文本(max_seq_len=128),五折(融合5-->2),融合后去重叠 | /0.675 |
| ex1-2 | NEZHA+LSTM+CRF | dp分割文本(max_seq_len=128),五折(融合5-->3),融合后去重叠 | /0.664 |
-
MRC for NER[8]
-
Multi-Task for NER[9]
多任务自适应Loss权重[10]

- Continue Pretrain[11]
- FGM[12] [13]
- pseudo-label

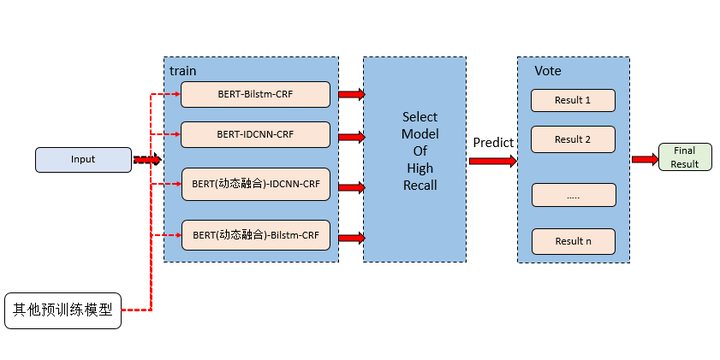
求所有模型的并集,根据所设定的阈值对实体进行投票,只保留高于阈值的实体。
部分融合结果:
| 策略 | 成绩 | |
|---|---|---|
| ex18 | 5--->2(Rule)(五折去全重叠[保留type频次相等的],ensemble去边界重叠) | 0.689 |
| ex19 | 5--->2(Rule)(五折去全重叠[保留type频次相等的],ensemble去全重叠[保留type频次相等的]) | 0.687 |
| ex20 | 5--->2(Rule)(五折去全重叠[保留type频次相等的],ensemble去全重叠[保留type频次相等的,频次不相等保留大于等于阈值3的]) | 0.690 |
| ex21 | 5--->1(Rule)(五折去全重叠[保留type频次相等的],ensemble去全重叠[保留type频次相等的,频次不相等保留大于等于阈值3的]) | 0.66 |
- 融合后去重叠:投票融合后的最终结果会有重叠的情况出现,重叠可分为两类,其一为边界相同,类别不同,其二为边界重叠。对于本次比赛来说,类别重叠的情况比较严重(实体类别区分度低),而最终将所有类别重叠的实体保留下来得到的F1值更优。边界重叠则取实体出现次数最多的那一个,将其余的舍弃。
- 实体成对标点的补齐与矫正
- 词表匹配
- 适用于当前数据特点的规则等
本次比赛历时一个月时间,获得了全国第一名的成绩,也获得了一些经验和教训。
时间轴方面,在比赛初期会开放一个官方验证集,即A榜阶段,这个阶段参赛者应着重于调研与复现现有的SOTA方案,以及寻找能够提升比赛分数tricks;在比赛结束前,大概有一周的时间开放官方测试集,即最终测试集。这时参赛者应着重于对模型融合策略的把控以及后处理规则的编写。
首先,在拿到数据以后,应根据任务对数据进行一些定量的分析,保证对任务数据有着充分的了解。然后针对赛题写出相应的Baseline方案,得到Baseline方案的效果。
第二,在A榜阶段,比赛的重心应放在对单模的提升上。这个提升也可以分为两部分,其一是模型结果上的提升,最直接的就是评测指标的提升;其二是获取多种异构的模型结构,例如本次任务中预训练模型和编码器的替换,以及尝试过的MRC、Multi-Task以及Word Argumentation的方法等。这些异构的模型有助于在融合阶段得到更好的结果。这个部分应该占到总工作量的2/3以上。
最后,在B榜阶段,利用第二阶段模型的积累以及模型融合获得较好的模型结果,对比不同融合策略下模型结果的差异,制定最优的模型融合策略与后处理规则。
通过本次比赛,基本上了解并复现了如今中文NER领域的SOTA方法,对整个中文NER领域有了较为全面的了解。且代码复用性强,解耦度高,易于理解,希望后续能在这套代码的基础上取得更多优异的成绩。
[1] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
[2] NEZHA: Neural Contextualized Representation for Chinese Language Understanding
[3] TENER: Adapting Transformer Encoder for Named Entity Recognition
[4] R-Transformer: Recurrent Neural Network Enhanced Transformer
[5] What does BERT learn about the structure of language?
[6] FLAT: Chinese NER Using Flat-Lattice Transformer
[7] https://github.com/caishiqing/joint-mrc
[8] A Unified MRC Framework for Named Entity Recognition
[9] 一种基于自适应多任务学习的细粒度医疗命名实体识别方法
[10] Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
[11] Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
[12] https://zhuanlan.zhihu.com/p/91269728
[13] Adversarial Training Methods for Semi-Supervised Text Classification