StarCoder2 and The Stack v2 from BigCode #662
Comments
Related issues#393: llm-vscode - Visual Studio Marketplace### DetailsSimilarity score: 0.9 - [ ] [llm-vscode - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode)LLM-powered Development for VSCode
Note: When using the Inference API, you may encounter limitations. Consider subscribing to the PRO plan to avoid rate limiting on the free tier. Hugging Face Pricing 💻 Features
🚀 InstallationInstall By default, this extension uses 🔑 HF API TokenSupply your HF API token (
If you previously logged in with ⚙ ConfigurationCheck the full list of configuration settings by opening your settings page Suggested labels{ "key": "llm-vscode", "value": "VSCode extension for LLM powered development with Hugging Face Inference API" }#324: bigcode/tiny_starcoder_py · Hugging Face### DetailsSimilarity score: 0.89 > **Note:** > > [bigcode/tiny_starcoder_py · Hugging Face](https://huggingface.co/bigcode/tiny_starcoder_py) > > TinyStarCoderPy > > This is a 164M parameters model with the same architecture as StarCoder (8k context length, MQA & FIM). It was trained on the Python data from StarCoderData for ~6 epochs which amounts to 100B tokens. > > Use > > Intended use > > The model was trained on GitHub code, to assist with some tasks like Assisted Generation. For pure code completion, we advise using our 15B models StarCoder or StarCoderBase. > > Generation > > ```python > # pip install -q transformers > from transformers import AutoModelForCausalLM, AutoTokenizer > > checkpoint = "bigcode/tiny_starcoder_py" > device = "cuda" # for GPU usage or "cpu" for CPU usage > > tokenizer = AutoTokenizer.from_pretrained(checkpoint) > model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device) > > inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device) > outputs = model.generate(inputs) > print(tokenizer.decode(outputs[0])) > ``` > > Fill-in-the-middle > > Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output: > > ```python > input_text = "def print_one_two_three():\n print('one')\n \n print('three')" > inputs = tokenizer.encode(input_text, return_tensors="pt").to(device) > outputs = model.generate(inputs) > print(tokenizer.decode(outputs[0])) > ``` > > Training > > Model > > - Architecture: GPT-2 model with multi-query attention and Fill-in-the-Middle objective > - Pretraining steps: 50k > - Pretraining tokens: 100 billion > - Precision: bfloat16 > > Hardware > > - GPUs: 32 Tesla A100 > - Training time: 18 hours > > Software > > - Orchestration: Megatron-LM > - Neural networks: PyTorch > - BP16 if applicable: apex > > License > > The model is licensed under the BigCode OpenRAIL-M v1 license agreement. You can find the full agreement [here](https://huggingface.co/bigcode/tiny_starcoder_py/blob/main/LICENSE). > > #### Suggested labels > > - { "key": "llm-pretraining", "value": "Information related to the pretraining process of Large Language Models" }#392: llm-vscode - Visual Studio Marketplace### DetailsSimilarity score: 0.89 - [ ] [llm-vscode - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode)LLM Powered Development for VSCodeWe are excited to announce the release of Note: When using the Inference API, you may encounter some limitations. To avoid getting rate limited in the free tier, consider subscribing to the PRO plan. Features
InstallationInstall like any other vscode extension. By default, this extension uses HF API TokenYou can supply your HF API token (
If you previously logged in with ConfigurationYou can check the full list of configuration settings by opening your settings page ( EndpointYou can configure the endpoint to which requests will be sent. The request body will look like: {
"inputs": "{start token}import numpy as np\nimport scipy as sp\n{end token}def hello_world():\n print("Hello world"){middle token}",
"parameters": { "max_new_tokens": 256 }
}Suggestion BehaviorYou can tune the way the suggestions behave:
For more information, see the documentation. LLM-LSBy default, Tokenizer
For more information, see the documentation. Code LlamaTo test the
Phind and WizardCoderTo test
For more information, see the documentation. DevelopingTo contribute to the development of this extension, follow these steps:
CommunityJoin our community to contribute to other related projects:
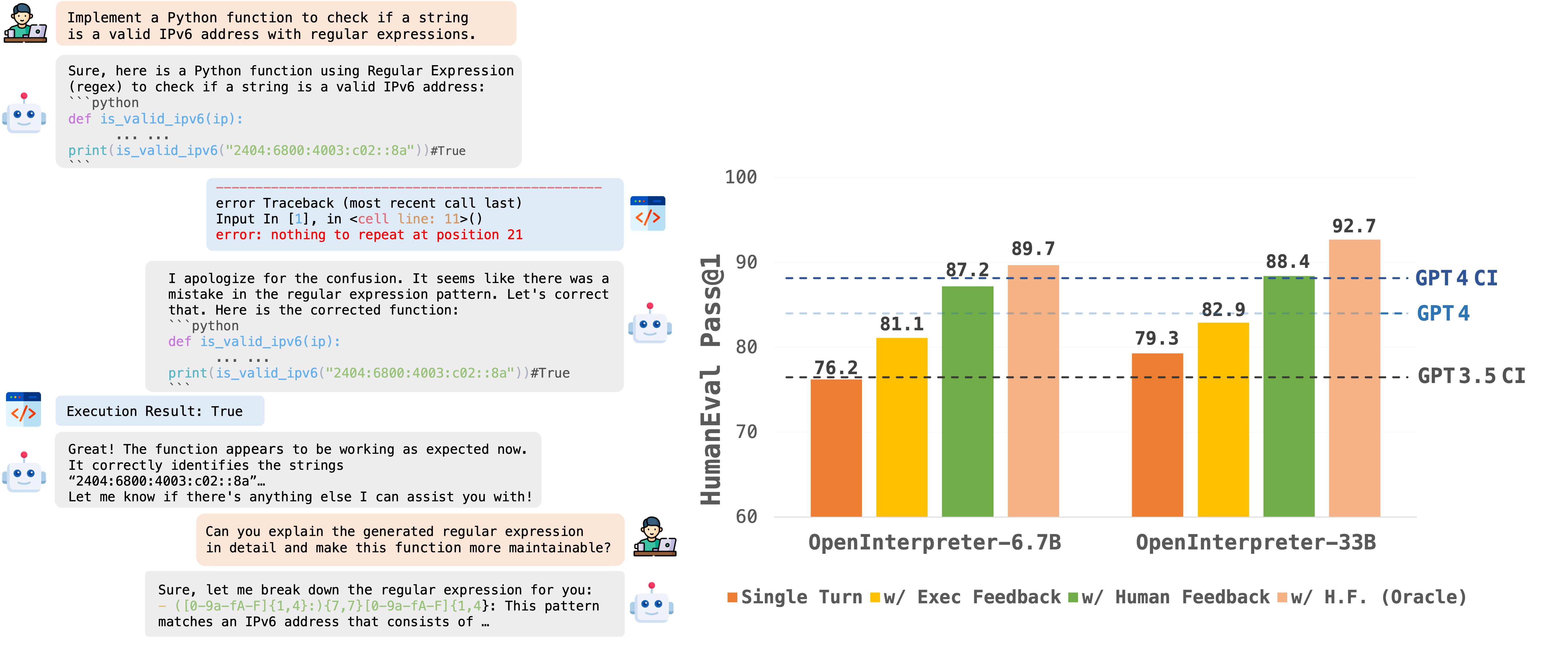
For more information, see the documentation. Suggested labels{ "key": "llm-inference-engines", "value": "Software and tools for running inference on Large Language Models" } { "key": "llama", "value": "Models and tools related to Large Language Models" }#658: OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter### DetailsSimilarity score: 0.88 - [ ] [OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/README.md?plain=1)OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreterDescriptionOpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
🌟 Upcoming Features
🔔News🛠️[2024-02-28]: We have open-sourced the Demo Local Deployment Code with a Setup Guide. ✨[2024-02-26]: We have open-sourced the OpenCodeInterpreter-DS-1.3b Model. 📘[2024-02-26]: We have open-sourced the CodeFeedback-Filtered-Instruction Dataset. 🚀[2024-02-23]: We have open-sourced the datasets used in our project named Code-Feedback. 🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series! We welcome everyone to try out our models and look forward to your participation! 😆 IntroductionOpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities. ModelsAll models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: OpenCodeInterpreter Models. Data CollectionSupported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement. EvaluationOur evaluation framework primarily utilizes HumanEval and MBP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the EvalPlus framework for a more comprehensive assessment. ContactIf you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. Suggested labels{'label-name': 'frameworks', 'label-description': 'Frameworks and tools used for evaluation and assessment.', 'gh-repo': 'OpenCodeInterpreter/OpenCodeInterpreter', 'confidence': 58.17}#189: deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2 · Hugging Face### DetailsSimilarity score: 0.87 - [ ] I cannot get this to output anything but gibberish. - [x] [LoneStriker/deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2 · Hugging Face](https://huggingface.co/LoneStriker/deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2)
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks. #628: LLaVA/README.md at main · haotian-liu/LLaVA### DetailsSimilarity score: 0.87 - [ ] [LLaVA/README.md at main · haotian-liu/LLaVA](https://github.com/haotian-liu/LLaVA/blob/main/README.md?plain=1)LLaVA/README.md at main · haotian-liu/LLaVA🌋 LLaVA: Large Language and Vision AssistantVisual instruction tuning towards large language and vision models with GPT-4 level capabilities. 📢 LLaVA-NeXT Blog Project Page Demo Data Model Zoo 🤝Community Contributions: llama.cpp Colab 🤗Space Replicate AutoGen BakLLaVA Improved Baselines with Visual Instruction Tuning Paper HF Visual Instruction Tuning (NeurIPS 2023, Oral) Paper HF Release
More
Usage and License Notices: This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses, including but not limited to the OpenAI Terms of Use for the dataset and the specific licenses for base language models for checkpoints trained using the dataset (e.g. Llama community license for LLaMA-2 and Vicuna-v1.5). This project does not impose any additional constraints beyond those stipulated in the original licenses. Furthermore, users are reminded to ensure that their use of the dataset and checkpoints is in compliance with all applicable laws and regulations. ContentsSuggested labels |

{kind=link}
blog/starcoder2.md at main · huggingface/blog
StarCoder2 and The Stack v2
BigCode is releasing StarCoder2 the next generation of transparently trained open code LLMs. All StarCoder2 variants were trained on The Stack v2, a new large and high quality code dataset. We release all models, datasets, and the processing as well as the training code. Check out the paper for details.
What is StarCoder2?
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. StarCoder2-15B is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle.
StarCoder2 offers three model sizes: a 3 billion-parameter model trained by ServiceNow, a 7 billion-parameter model trained by Hugging Face, and a 15 billion-parameter model trained by NVIDIA with NVIDIA NeMo and trained on NVIDIA accelerated infrastructure:
StarCoder2-15B is the best in its size class and matches 33B+ models on many evaluations. StarCoder2-3B matches the performance of StarCoder1-15B:
What is The Stack v2?
The Stack v2 is the largest open code dataset suitable for LLM pretraining. The Stack v2 is larger than The Stack v1, follows an improved language and license detection procedure, and better filtering heuristics. In addition, the training dataset is grouped by repositories, allowing to train models with repository context.
This dataset is derived from the Software Heritage archive, the largest public archive of software source code and accompanying development history. Software Heritage is an open, non profit initiative to collect, preserve, and share the source code of all publicly available software, launched by Inria, in partnership with UNESCO. We thank Software Heritage for providing access to this invaluable resource. For more details, visit the Software Heritage website.
The Stack v2 can be accessed through the Hugging Face Hub.
About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
Links
Models
Data & Governance
Others
You can find all the resources and links at huggingface.co/bigcode!"
URL: blog/starcoder2.md at main · huggingface/blog
Suggested labels
The text was updated successfully, but these errors were encountered: