rust_xlsxwriter Roadmap #1
Comments
Initial performance data:Or in other words, the C version is the fastest and if we take that as 1 then the rust version is 1.2x (or 20%) slower and the Python version is 8x slower. The Rust version is ~6.5x faster than the Python version. |
|
Is polars support planned? I saw the python xlsxwriter have pandas support, I wonder if the rust xlsxwriter have any plans to support polars. |
Good suggestion. That was something that I was thinking about. I wrote the initial xlsxwriter integration into Pandas. I'll have a look in their GitHub issues/requests and see if there is any planned work. |
|
Is it possible to use rayon or std thread scope (parallelism) to do each worksheet and at the end add in the final workbook? This code was just a vain attempt: |
It wouldn't be easy. I've thought a good bit about this in the past in relation to the other language version of the library. The main issue is that the xlsx file format has a lot of interlinked "relationships" stored in However, I would like the library to have the best performance possible (within the limits of the design and file format) so I'll take a look at what can be done. Update: some backend parallelism was added in v0.44.0 |
|
Hi and thanks for the library! This is a really aweswome upgrade to the previous binding to the C lib. |
That will be the next major feature after I complete more of the chart feature. |
|
@Christoph-AK see #41 for initial table support. Update: completed in v0.40.0 |
|
Hi.. Thanks for the library!! I was in need of an active excel writer library in rust for my new project and this project seems to be most active and promising. My project may depend on a lot of existing excel templates. I understand from the readme that currently editing an existing excel file is not supported. Any chances that this could be added in the future? |
Unfortunately no, I don’t plan to tackle reading or rewriting XLSX files. The XLSX structure is difficult to parse and rewrite for anything beyond basic data (and even that it can be hard for elements like dates). Instead I’m going to concentrate my efforts to try give Rust a best in class XLSX writing library. For additional context here is a reply that I gave to a similar request to the Python version of the library: jmcnamara/XlsxWriter#653 (comment) Hopefully someone will step up at some point to combine one of the Rust XLSX readers with rust_xlsxwriter for a templating/rewriting solution. |
|
I've uploaded a new crate called It provides two interfaces for writing a Polars Rust dataframe to an Excel Xlsx file:
|
|
I've added support for Conditional Formatting. See Working with Conditional Formats in the docs. #58 |
|
I have added support for Serde serialization in v0.57.0. See Working with Serde in the Some additional serialisation features and helpers will be added in upcoming releases. |
|
Do you have any plans regarding reaching version 1.0? You seem to make a new 0.x release every week or so. Many of them don't have any breaking changes, but still require me to manually bump the version in In theory, I assume that major numbers would also make the life easier for library authors who depend on |
|
Obligatory mention of https://github.com/obi1kenobi/cargo-semver-checks - might be worth including. |
I plan to release a 1.x.x version once the feature set is ~ 100% of the Python feature set. Based on the task list above the current feature set is 25/33 features and based on ported integration test cases it is ~ 700/900. I would hope to get to 1.0.0 by the end of the year. Some of the remaining tasks are reasonable big though.
That will probably continue through this year (with an upcoming pause of 1-2 months while I work on some of the other language libraries/features).
Yes. Some, or many, of those could be patch level releases but most contain a reasonable level of new functionality. The semver docs say:
I am usually in the "MAY" category and sometimes in the "MUST".
I think I would end up incrementing a large number of major versions as well. I don't know if that would be better or worse for the end user. Anyway, overall I think you (and others) will just need to bear with me for the next year or so. The downside is that there will be several more bumps in minor versions but the (hopefully) upside is that there will be new substantive features added on a regular basis. |
|
I have released This can be useful if you are building up a spreadsheet of products with a column of images of each product. Embedded images move with the cell so they can be used in worksheet tables or data ranges that will be sorted or filtered. This functionality is the equivalent of Excel's menu option to insert an image using the option to "Place in Cell" which is available in Excel 365 versions from 2023 onwards. I was a frequently requested feature for Excel and for the xlsxwriter variants. |
|
I've added support for adding VBA Macros to Also, this lays some of the groundwork for adding cell comments (now called Notes by Excel). ExplanationAn Excel Unlike other components of an xlsx/xlsm file this data isn't stored in an XML format. Instead the functions and macros as stored as a pre-parsed binary format. As such it wouldn't be feasible to programmatically define macros and create a Instead, as a workaround, the Rust Here is an example: use rust_xlsxwriter::{Button, Workbook, XlsxError};
fn main() -> Result<(), XlsxError> {
// Create a new Excel file object.
let mut workbook = Workbook::new();
// Add the VBA macro file.
workbook.add_vba_project("examples/vbaProject.bin")?;
// Add a worksheet and some text.
let worksheet = workbook.add_worksheet();
// Widen the first column for clarity.
worksheet.set_column_width(0, 30)?;
worksheet.write(2, 0, "Press the button to say hello:")?;
// Add a button tied to a macro in the VBA project.
let button = Button::new()
.set_caption("Press Me")
.set_macro("say_hello")
.set_width(80)
.set_height(30);
worksheet.insert_button(2, 1, &button)?;
// Save the file to disk. Note the `.xlsm` extension. This is required by
// Excel or it raise a warning.
workbook.save("macros.xlsm")?;
Ok(())
}Output:
|

|
I've added support for cell Notes (previously called Comments) in v0.72.0. See https://docs.rs/rust_xlsxwriter/latest/rust_xlsxwriter/struct.Note.html Here is an example: use rust_xlsxwriter::{Note, Workbook, XlsxError};
fn main() -> Result<(), XlsxError> {
// Create a new Excel file object.
let mut workbook = Workbook::new();
// Add a worksheet to the workbook.
let worksheet = workbook.add_worksheet();
// Widen the first column for clarity.
worksheet.set_column_width(0, 16)?;
// Write some data.
let party_items = [
"Invitations",
"Doors",
"Flowers",
"Champagne",
"Menu",
"Peter",
];
worksheet.write_column(0, 0, party_items)?;
// Create a new worksheet Note.
let note = Note::new("I will get the flowers myself").set_author("Clarissa Dalloway");
// Add the note to a cell.
worksheet.insert_note(2, 0, ¬e)?;
// Save the file to disk.
workbook.save("notes.xlsx")?;
Ok(())
}And the output:
I didn't port some of the Python Note/Comment features such as note positioning since they weren't widely used and Excel's implementation tends to surprise people. If people ask of them I'll add them. The infrastructure is already in place. Note, in versions of Excel prior to Office 365 Notes were referred to as "Comments". The name Comment is now used for a newer style threaded comment and Note is used for the older non threaded version. The newer Threaded Comments are unlikely to be added to As an aside the internal traits that I had put in place for other worksheet objects (images, charts, buttons) made this feature relatively easy to add. I really like this aspect of Rust where some of the abstractions can give very clean and easy to maintain/refactor code. Overall I really enjoy using Rust as a language. |

|
I've uploaded version v0.74.0 of In Excel the data in a worksheet cell is comprised of a type, a value and a format. When using However, if required you can now write the data separately and then add the format using the new methods like For example you can now create border formatting like this with a single method call: This has always been a heavily requested feature in the Python version but due to some different design decisions it was never easy to implement. |
|
I've released v0.75.0 of An example of the size difference is shown below for one of the sample apps:
See the discussion at #108 |
|
Version v0.76.0 of See the documentation for This is the last of the "Larger functionality" features. We are probably on track to be feature complete with, or beyond, the Python version by the end of the year. |
|
Folks, I am looking for some input on "constant_memory" mode for |
|
Released version v0.77.0 of A Chartsheet in Excel is a specialized type of worksheet that doesn't have cells but instead is used to display a single chart. It supports worksheet display options such as headers and footers, margins, tab selection and print properties. Chartsheets aren't widely used these days (as far as I can see) but end users sometimes request this feature. |
|
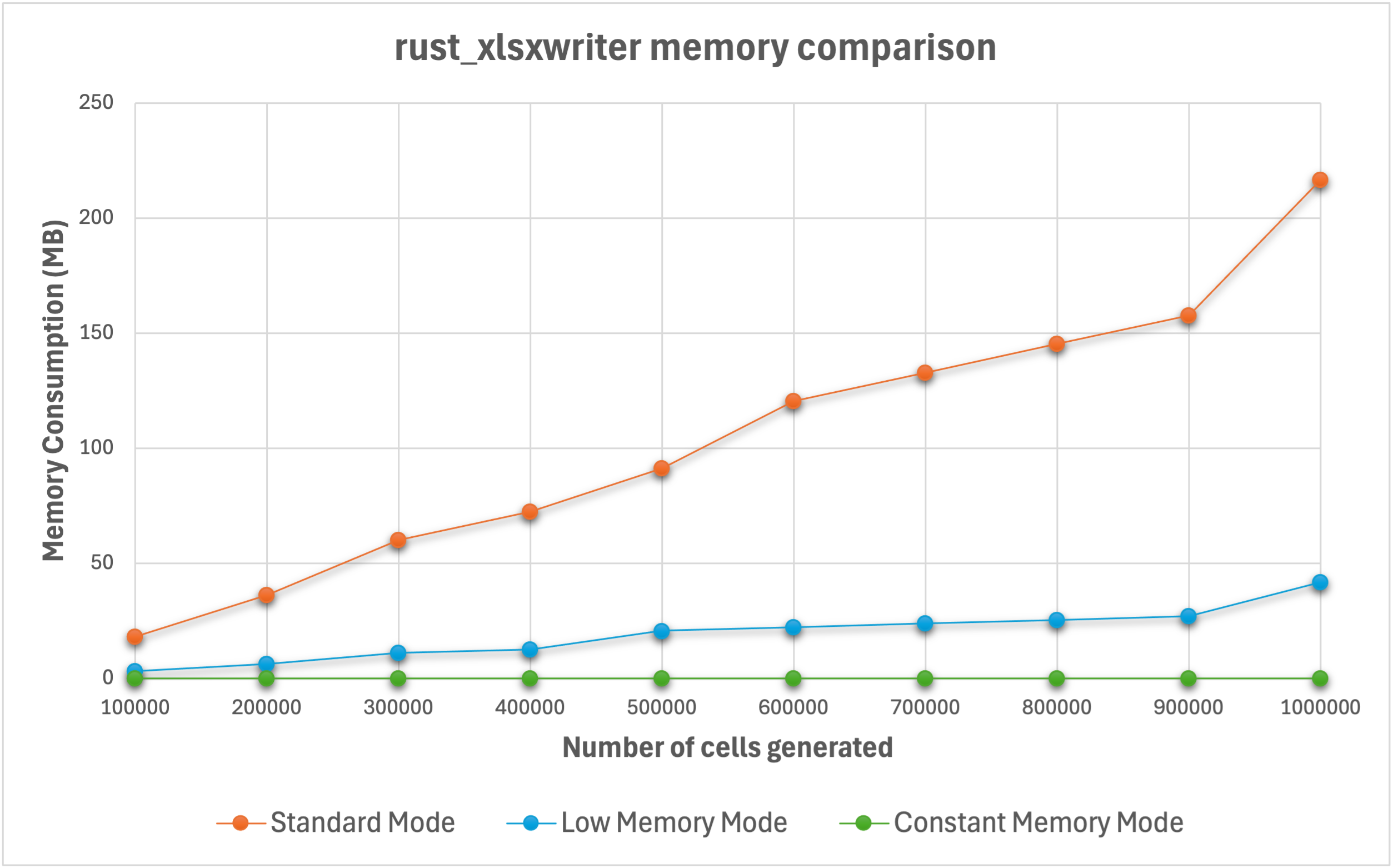
I have an initial working version of the "constant memory" mode on the The memory usage profile is effectively flat (as designed):
Which looks like this:
Similarly to the Python version the performance is also slightly better (5-15%) in this mode. Lower time is better. However for numeric only/heavy data (which is the case in practice) the performance is more of less the same.
The tests were run like this: So the initial results are good. I'll continue with the functionality. It would be good to have a few other eyes on this in #111. |


|
How about the serde sub-struct flattening support? |
@hackers267 It is probably worth opening a feature request for that. The main problem is how would a sub-structure be flattened in the 2D cell matrix of a worksheet. The obvious approach would be to flatten the sub-structure into a a string in a cell, but that might not be a great solution for some (most?) users. So it is probably best to kick off a Feature Request issue with an example of your data structure and also an Excel example of what you think the output should look like. Anyone else who is facing this issue can then add their opinion/suggestion. |
Wow, this looks incredibly promising. Are there reasons not to use this as default, or maybe switch to it intelligently if only supported features are used? |
@jmcnamara I'm dealing with a scenario where in the generated excel, there are some fixed columns like name, age, gender, etc. and some unfixed columns like 2022 results, 2023 results, January 2024 results... Until results of the month. In this, the column that is fixed can be represented by the field of Struct, while the column that changes can be represented by the sub-struct of the flatten of serde, which can be of HashMap type. I think this is one of the application scenarios for sub-structure. |
@Christoph-AK There are a number of restrictions around "constant memory" mode which don't make it suitable for all use cases. Such as:
So in general there are a few too many gotchas to turn it on as the default. In fact it will probably be behind a feature flag since it will require an additional dependency on the However, for use cases where it makes sense it will be a big efficiency gain. Also, it is possible to turn it on on a worksheet by worksheet basis so users can mix and match worksheets as required. |
@hackers267 Thanks for the description. The HashMap type at least may be feasible to support. Open a feature request and put in a sample struct and some example data and I will look at what can be done. |
|
Released v0.78.0 with support for "constant memory" mode to reduce memory usage when writing large worksheets. The @jpmckinney You asked about this a while back. If you are still interested you can check it out. |
|
I've released v0.79.0 of The |
|
For anyone who is interested I wanted to highlight a new wasm wrapper for Update: the performance of this looks good: #38 (comment) |
|
Hi @jmcnamara, I currently use nodejs/exceljs to write very large xlsx files. I'm looking into potentially faster alternatives, including this lib. I have created a quick benchmark comparing different language/lib combinations https://github.com/brunoargolo/excel-writing-multilanguage-benchmark I'm a 100% beginner in Rust, GO and Python. So I might have royally fudged something. I was hoping Rust would prove significantly faster than node but its pretty much a tie. If you find any mistakes in my approach please let me know, I tried to make the repo as easy to reproduce as possible so anyone can test it. Node and Go are using the streaming function of their respective libs, on python I used the constant memory mode on rust I tried both low_memory and constant memory with similar results.
|
Thanks. That is helpful. Overall, I don't see anything wrong with the benchmarks although the rust version does a bit too much type conversion. A real world example would probably use serde_json, or similar, and do the type conversion as part of the read step. However, this adds at most a 10% overhead to the write phase. Also, in this particular case the So overall, with some fine tuning and you could get 1.1-1.2 times better performance but that would still be in the same ballpark as the nodejs/exceljs solution, so probably not worth the effort of changing. I also crosschecked with the |
|
I really appreciate you taking the time to go over this, thank you! My guess is we're probably hitting the limits of what is viable in any language... I imagine we're not going to see 2x or 3x faster no matter the language/lib combination. The one thing that might be significantly faster could be writing to XLSB format, but it is probably a ridiculous amount of work... Do you still have any major performance related items on the roadmap or do you think this is mostly as good as it gets plus or minus a few percentage points? |
Agreed. The bottlenecks come down to IO/writing the worksheet.xml files and zipping them and other supporting files into a zip container. So most implementations will probably hit the same performance floor. Notwithstanding that I'm impressed with the ExcelJS performance.
There may be some small (< 10%) IO/writing gains still to be made but most of the low hanging fruit have been picked. A potentially bigger gain would probably come from a threaded/parallelized zip library. The C library gets a 20-30% performance improvement from using the Milo Yip DTOA library library for float to string conversion but I didn't get a similar speed increase from the ryu library except in very large files. It is also possible that a properly parallelized backend worksheet assembly using rayon or similar might improve multiple worksheet writing. I have But to take a step back it is worth noting that the Rust version is at almost 90% of the C library performance so any 2-3x gain is unlikely without a radically different approach.
Yes. I maintained a library for the similar XLS format and it wasn't fun to maintain/extend. So for me that would be a non-runner. :-) P.S. I would still be interested in the |
|
I wonder if a different allocator can give more performance in this benchmark. Combining all approaches (allocator, faster serialisation and floats, better parallelization) would probably approach the go time. I think garbage collected languages like go and js have an advantage vs default rust here as the gc can easier reuse allocated memory, and go does have an advantage when it comes to easily throwing multithreading at everything. Of cause all of those characteristics can be programmed in rust with some care, so there shouldn't really be a language other then c thats inherently faster. It might be interesting to throw the js, go and rust versions into flamegraphs and watch where each spend their time. |
|
I've released v0.80.0 or |
|
Are there any plans to support batch writing of multiple lines? Will it be much faster if it supports batch writing of multiple rows? |
fn write_to_excel(
file_name: &str,
headers: &[String],
data: &[Vec<String>],
) -> Result<(), XlsxError> {
let mut workbook = Workbook::new();
let worksheet = workbook.add_worksheet_with_constant_memory();
worksheet.write_row(0, 0, headers)?;
for (row_index, row) in data.iter().enumerate() {
worksheet.write_row((row_index + 1) as u32, 0, row)?;
// worksheet.write_multi_row(row, col, data)?; ??? like this.
}
workbook.save(file_name)?;
Ok(())
} |
The
No, it is just syntactic sugar around a loop. It is effectively the same as the code you show above. Batching won't help performance here. See the Performance section of the |
rust_xlsxwriteris a Rust library that can be used to write text, numbers, dates and formulas to multiple worksheets in an Excel 2007+ XLSX file.It is a port of the XlsxWriter Python module by the same author. I also actively maintain a C version libxlsxwriter and a Perl version Excel::Writer::XLSX. The Rust version will also try to address some limitations and frequently requested features of the previous versions, such as the separation of formatting and data writing.
The overall focus of rust_xlsxwriter is on performance, on testing, on documentation, and on fidelity with the file format created by Excel. Reading or modifying files is outside the scope of this library.
Phase 1: Basic functionality
Phase 2: Medium functionality
Phase 3: Larger functionality
The text was updated successfully, but these errors were encountered: