Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Official Repo
Code Snippet
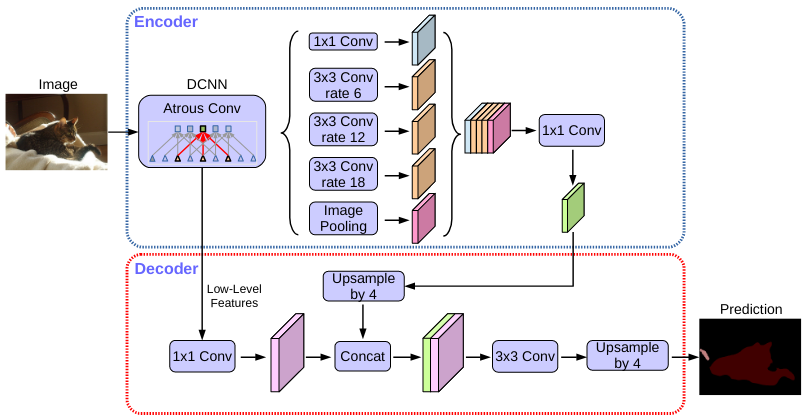
Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network. We demonstrate the effectiveness of the proposed model on PASCAL VOC 2012 and Cityscapes datasets, achieving the test set performance of 89.0% and 82.1% without any post-processing. Our paper is accompanied with a publicly available reference implementation of the proposed models in Tensorflow at this https URL.
@inproceedings{deeplabv3plus2018,
title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
booktitle={ECCV},
year={2018}
}
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-50-D8 |
512x1024 |
40000 |
7.5 |
3.94 |
79.61 |
81.01 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x1024 |
40000 |
11 |
2.60 |
80.21 |
81.82 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
769x769 |
40000 |
8.5 |
1.72 |
78.97 |
80.46 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
769x769 |
40000 |
12.5 |
1.15 |
79.46 |
80.50 |
config |
model | log |
| DeepLabV3+ |
R-18-D8 |
512x1024 |
80000 |
2.2 |
14.27 |
76.89 |
78.76 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
512x1024 |
80000 |
- |
- |
80.09 |
81.13 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x1024 |
80000 |
- |
- |
80.97 |
82.03 |
config |
model | log |
| DeepLabV3+ (FP16) |
R-101-D8 |
512x1024 |
80000 |
6.35 |
7.87 |
80.46 |
- |
config |
model | log |
| DeepLabV3+ |
R-18-D8 |
769x769 |
80000 |
2.5 |
5.74 |
76.26 |
77.91 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
769x769 |
80000 |
- |
- |
79.83 |
81.48 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
769x769 |
80000 |
- |
- |
80.65 |
81.47 |
config[1] |
model | log |
| DeepLabV3+ |
R-101-D16-MG124 |
512x1024 |
40000 |
5.8 |
7.48 |
79.09 |
80.36 |
config |
model | log |
| DeepLabV3+ |
R-101-D16-MG124 |
512x1024 |
80000 |
9.9 |
- |
79.90 |
81.33 |
config |
model | log |
| DeepLabV3+ |
R-18b-D8 |
512x1024 |
80000 |
2.1 |
14.95 |
75.87 |
77.52 |
config |
model | log |
| DeepLabV3+ |
R-50b-D8 |
512x1024 |
80000 |
7.4 |
3.94 |
80.28 |
81.44 |
config |
model | log |
| DeepLabV3+ |
R-101b-D8 |
512x1024 |
80000 |
10.9 |
2.60 |
80.16 |
81.41 |
config |
model | log |
| DeepLabV3+ |
R-18b-D8 |
769x769 |
80000 |
2.4 |
5.96 |
76.36 |
78.24 |
config |
model | log |
| DeepLabV3+ |
R-50b-D8 |
769x769 |
80000 |
8.4 |
1.72 |
79.41 |
80.56 |
config |
model | log |
| DeepLabV3+ |
R-101b-D8 |
769x769 |
80000 |
12.3 |
1.10 |
79.88 |
81.46 |
config |
model | log |
[1] The training of the model is sensitive to random seed, and the seed to train it is 1111.
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-50-D8 |
512x512 |
80000 |
10.6 |
21.01 |
42.72 |
43.75 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
80000 |
14.1 |
14.16 |
44.60 |
46.06 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
512x512 |
160000 |
- |
- |
43.95 |
44.93 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
160000 |
- |
- |
45.47 |
46.35 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-50-D8 |
512x512 |
20000 |
7.6 |
21 |
75.93 |
77.50 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
20000 |
11 |
13.88 |
77.22 |
78.59 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
512x512 |
40000 |
- |
- |
76.81 |
77.57 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
40000 |
- |
- |
78.62 |
79.53 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-101-D8 |
480x480 |
40000 |
- |
9.09 |
47.30 |
48.47 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
480x480 |
80000 |
- |
- |
47.23 |
48.26 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-101-D8 |
480x480 |
40000 |
- |
- |
52.86 |
54.54 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
480x480 |
80000 |
- |
- |
53.2 |
54.67 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-18-D8 |
512x512 |
80000 |
1.93 |
25.57 |
50.28 |
50.47 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
512x512 |
80000 |
7.37 |
6.00 |
50.99 |
50.65 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
80000 |
10.84 |
4.33 |
51.47 |
51.32 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-18-D8 |
512x512 |
80000 |
1.91 |
81.68 |
77.09 |
78.44 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
512x512 |
80000 |
7.36 |
26.44 |
78.33 |
79.27 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
80000 |
10.83 |
17.56 |
78.7 |
79.47 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-18-D8 |
512x512 |
80000 |
1.91 |
72.79 |
72.50 |
74.13 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
512x512 |
80000 |
7.36 |
26.91 |
73.97 |
75.05 |
config |
model | log |
| DeepLabV3+ |
R-101-D8 |
512x512 |
80000 |
10.83 |
18.59 |
73.06 |
74.14 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3+ |
R-18-D8 |
896x896 |
80000 |
6.19 |
24.81 |
61.35 |
62.61 |
config |
model | log |
| DeepLabV3+ |
R-50-D8 |
896x896 |
80000 |
21.45 |
8.42 |
67.06 |
68.02 |
config |
model | log |
Note:
D-8/D-16 here corresponding to the output stride 8/16 setting for DeepLab series.MG-124 stands for multi-grid dilation in the last stage of ResNet.FP16 means Mixed Precision (FP16) is adopted in training.896x896 is the Crop Size of iSAID dataset, which is followed by the implementation of PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation