This project, the Online Travel Agency is implemented as a distributed storage. All data can be stored in multiple machines on a common network. The implementation also includes the notion of primary and secondary data servers, similar to GFS - Google File System.
- Location transparency
- Implementation of Google File System
- Fault Tolerance - Replication of data
- Master Slave Architecture
- Heartbeat
- REST Framework
- Authentication - Register, Login, Recovery
- Book hotels and buses
- Be a service provider - create and delete hotel and bus services
- Manage services and bookings
- Be an admin - handle databases, user permissions and heartbeat rate
- Collaborate wth users to manage services
-
Location Transparency: The database (distributed) resides in several machines. The replication factor is fixed to 3, meaning data would be inserted in 3 different machines (called data servers). The user would be unaware of the location from where his data is being fetched.
-
Fault Tolerance: Replication factor of 3 ensures that even if any two systems are down, the application would still run smoothly.
-
Idea from the Google File System: The master contains the meta-data and hence knows which machines have a particular record. Since every record is stored in three different machines (data servers of that record), we call one of them as primary and the other two as secondary. Further use of this notion is described ahead :) We also would be using the notion of active and inactive data servers - which denote if a server is running or crashed respectively.
-
Handling Reads: To fetch any record, we iterate through the active data servers and try to get the required record. We return it to the user as soon as we get it from the database.
-
Handling Writes: To create a new record, we need to select 3 active machines and insert data into them. Also, we name one of them as primary.
-
Handling Updates: Updates need to be consistent, meaning all the data servers should have the same updated record. As soon as the master receives the request for update, it forwards it to the primary data server of that record. It is the primary data servers' duty to update the remaining 2 secondary servers. This technique would help to reduce the load on the master. If it happens that any of the secondary data servers is down, then the primary informs the master regarding the pending update. The master later updates the record when the secondary server becomes active again. If it happens that the primary itself is down, then the master simple chooses a new primary and makes the current one a secondary :)
-
Heartbeat: The master pings all data servers periodically to check which ones are crashed and which ones are active. The time period can be altered in the application by the admin.
For in-depth details, kindly refer to the pdf Distributed Systems.pdf
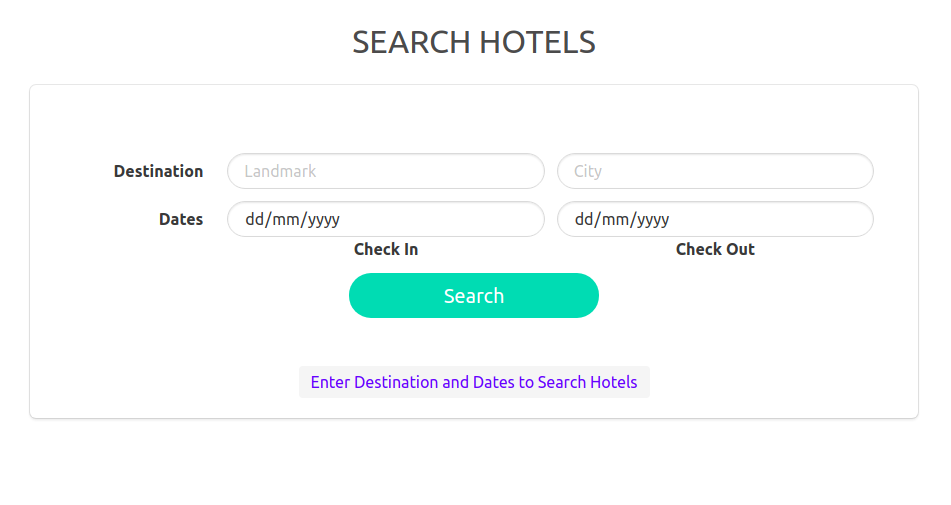
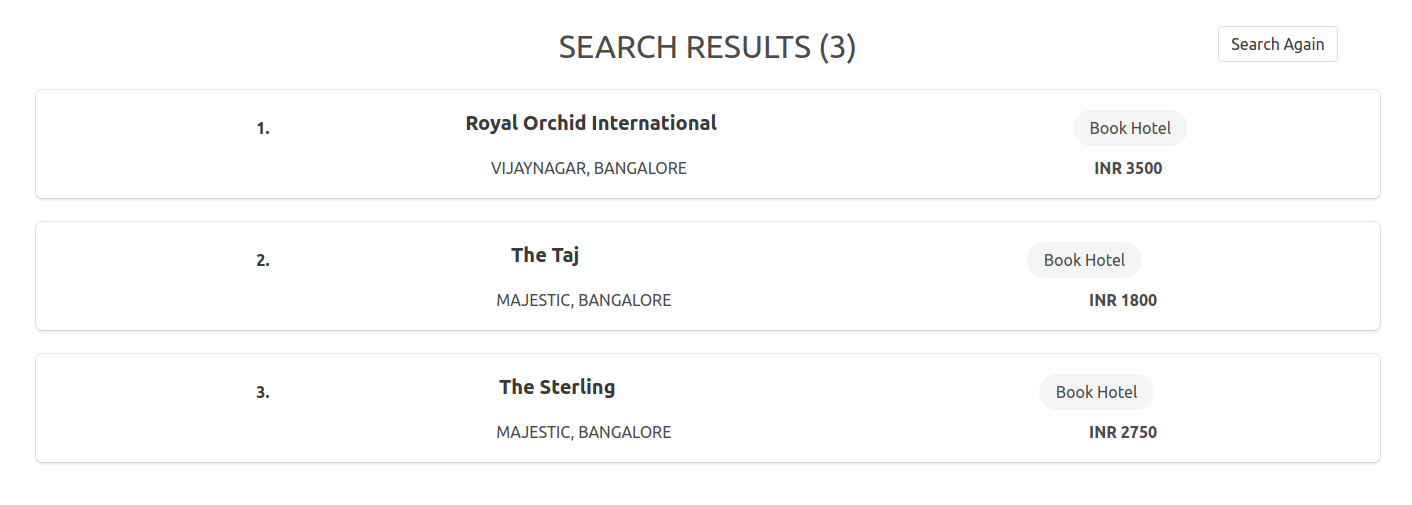
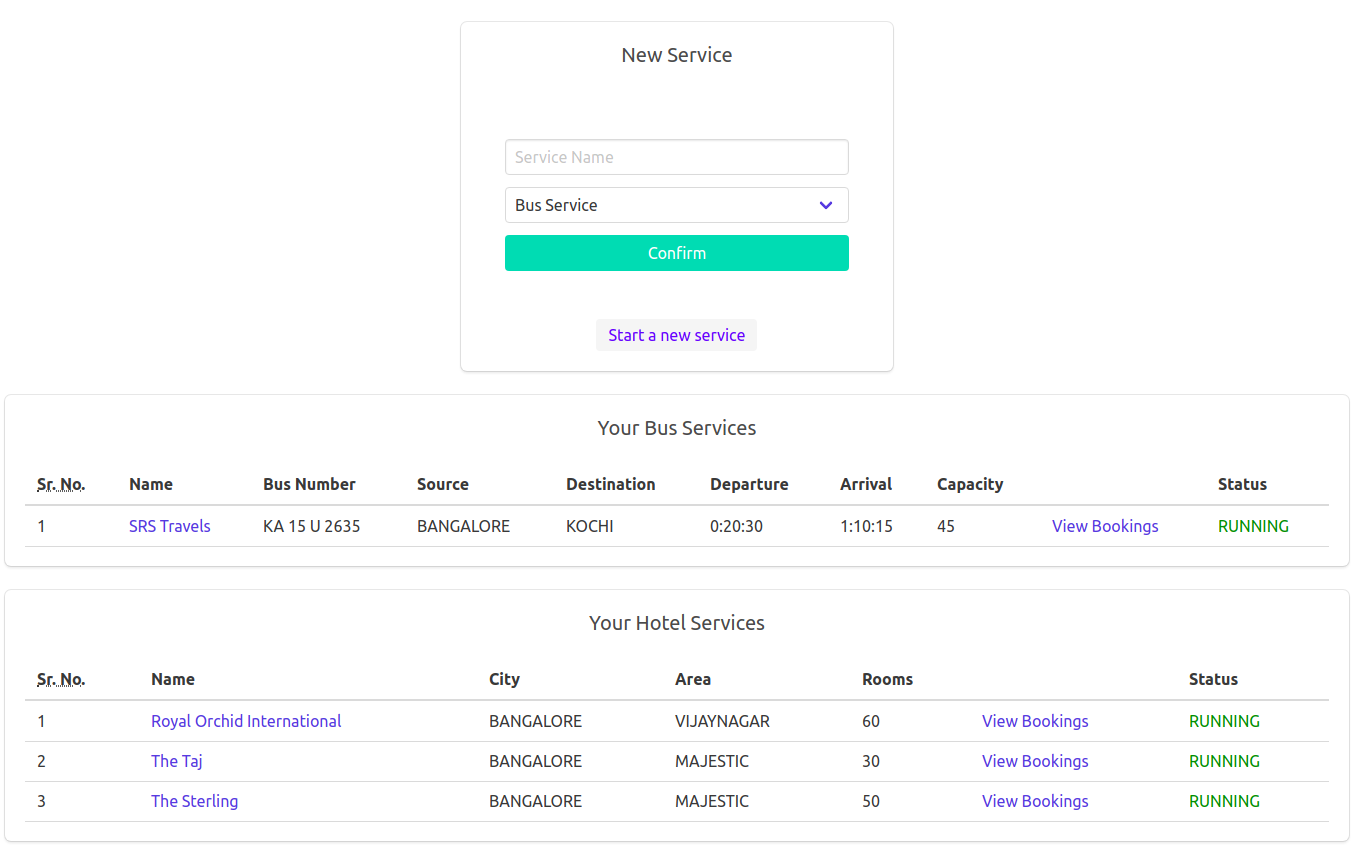
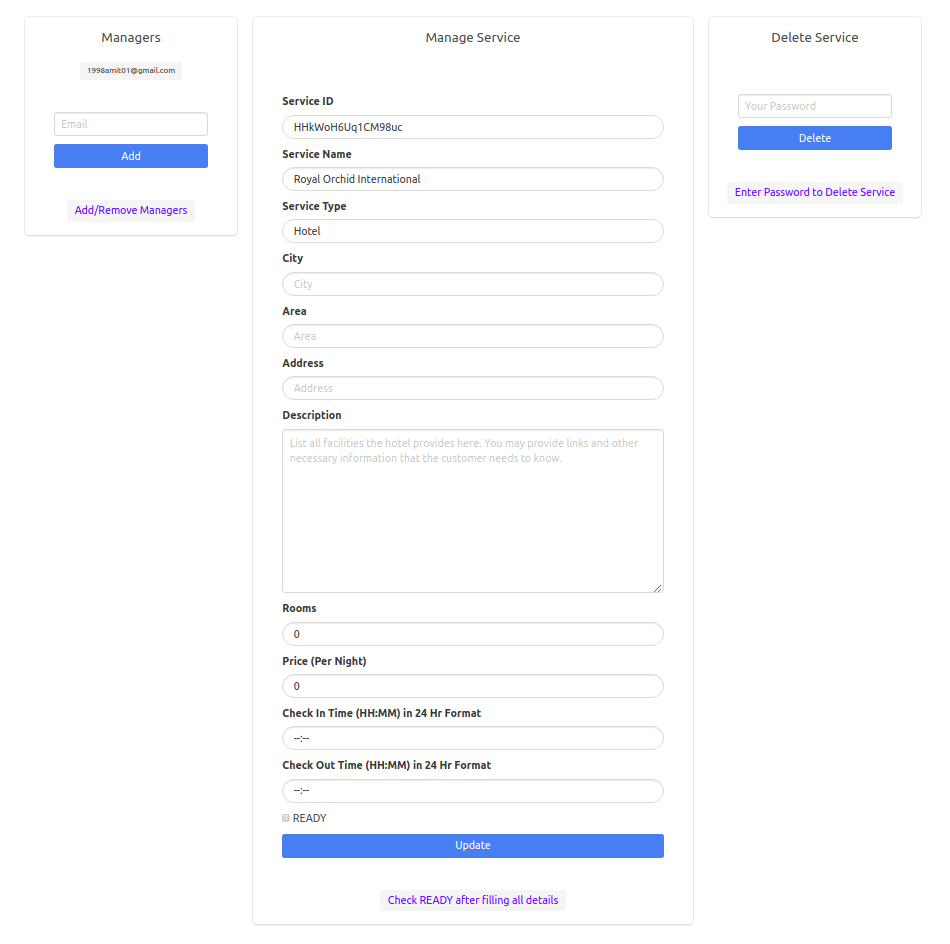

The installation of the project is complicated, however, they are provided in the file instructions.txt. The application uses multiple instances of postgres on the same machine, but on different ports which simulate data servers on different machines. I would be glad to help you out in case you run in to any problem while installing :)
Kindly note that the installation instructions are meant for UNIX based systems only.
- FrontEnd - HTML, CSS
- CSS Framework - Bulma UI - https://bulma.io
- BackEnd - Python Django
- Python modules - psycopg2, djangorestframework, requests, status, widget_tweaks
- Database - PostgreSQL
Any kind of suggestions would be appreciated :)