Rheumatoid arthritis (RA) is an autoimmune disease that causes swelling and pain in the joints. As others, we reckon that RA is an heterogeneous disease and that subset identification is an important first step to a better etiologic understanding. A tantalizing idea is that the factors that cause this latent clinical heterogeneity are already present in patients at baseline.
Therefore, we aim to refine the taxonomy of RA by "unlocking" the wealth of data available in the Electronic Health Records (EHR). We developed a pipeline that casts different EHR-layers, such as lab- and clinical- data, into a shared latent space and performs clustering accordingly. Next, we compare the baseline characteristics and treatment response between the clusters.
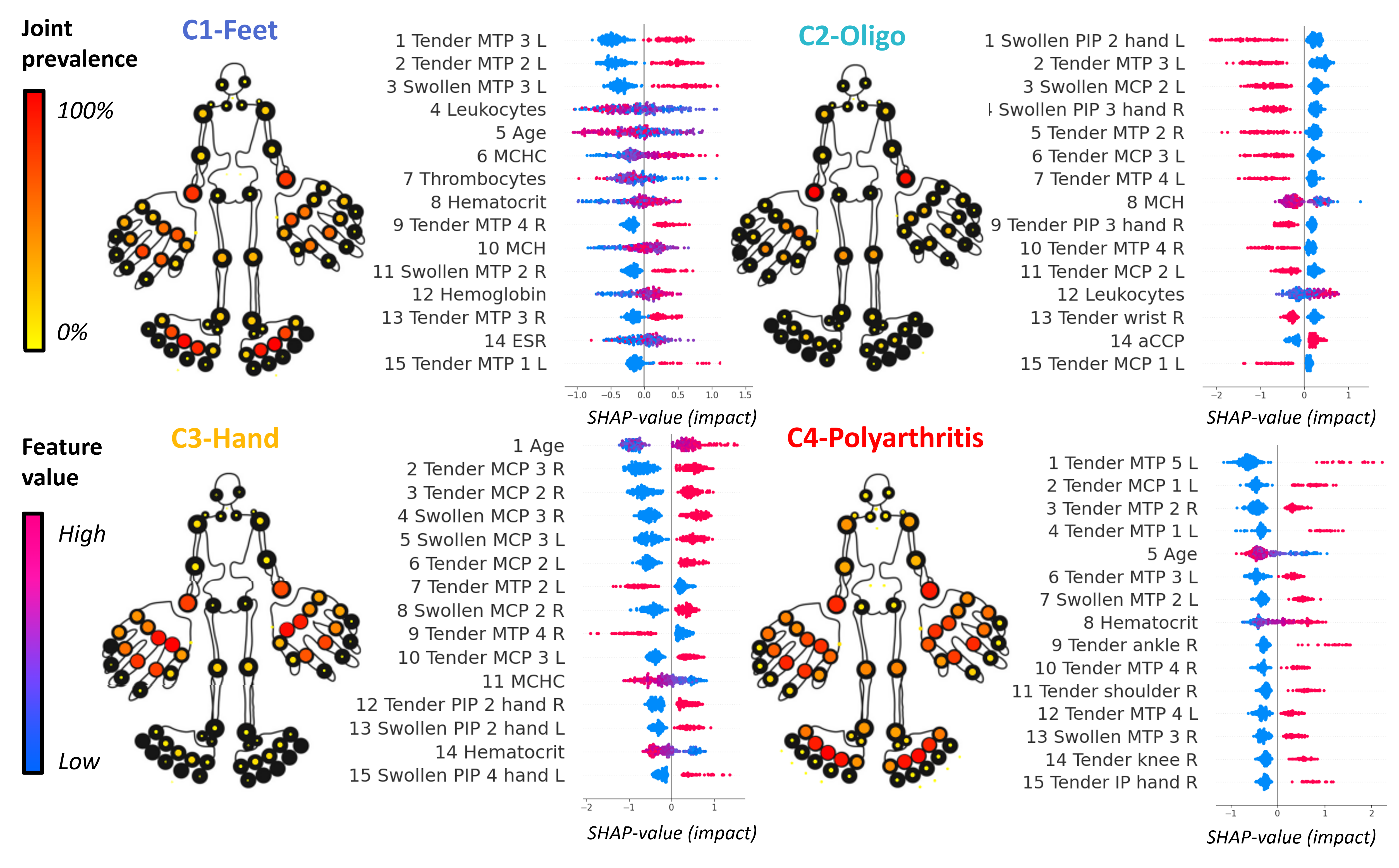
Note: we used this pipeline for our study, of which you can find a preprint here: https://doi.org/10.1101/2023.09.19.23295482. We identified four different RA subsets: 1) arthritis in feet, 2) seropositive oligo-articular disease, 3) seronegative hand arthritis, 4) polyarthritis. We conducted sensitivity analysis, external validation and 1000 times bootstrapping to ensure that our clusters were valid, generalizable and stable.

Workflow depicting the different steps of our pipeline. We start off with 25,000+ dossiers of patients that visited the outpatient clinic, then we apply a patient selection whereby we request at a minimum follow-up of 1 year and a first visit after the initialization of our digital system in 2011. Next, we feed the conclusion section - containing the physician’s verdict - to a Machine Learning Method to identify the rheumatoid arthritis (RA) patients based on their diagnosis. We end up with the records of 1,387 RA-patients which are supplied to the EHR clustering pipeline, where we preprocess the different EHR-components and combine this information to construct a patient embedding with MMAE. We employ graph clustering (w/ PhenoGraph) on this feature space to stratify patients. The clusters were further analyzed with a SHAP analysis, to identify the signatures that drive the distinct clinical manifestions
To ensure the robustness of our findings, we tested a) cluster stability (1000 fold) b) physician confounding, c) association with remission and methotrexate failure and d) generalizability to a second different data set (Leiden Early Arthritis clinic; n=769).
We replicated the clustering and the downstream analysis (SHAP & survival analysis) in an seperate independent dataset for external validation. To investigate the replicability of the clustering we projected our novel patients unto our learned patient embedding, and assigned them to a cluster based on their orientation with respect to the old data. This projection was achieved with POODLE
Prerequisite: Install Anaconda with python version 3.8+. This additionally installs the Anaconda Prompt, which you can find in the windows search bar. Use this Anaconda prompt to run the commands mentioned below.
Prerequisite: conda environment (with jupyter notebook). Use the terminal to run the commands mentioned below.
$ conda install -c anaconda notebookUse pip to install the dependecies
$ pip install -r requirements.txt- Start a notebook session in the terminal
- Open the first notebook : Notebook 1
data/*: All data is stored here (Excluded: sensitive data)embedding/*: Here you'll find the patient embedding created with MMAE, based on set Afigures/*: All figures of the project are stored herefilters/*: This directory features different lists reporting the patients eligible for the study (Excluded: sensitive data)models/*: The Machine learning model used to detect RA-patients is stored herenotebooks/*: Features the entire pipeline divided in steps over different notebooks.notebooks/1_patient_selection.ipynb: Employs machine learning to identify the diagnosis of the physician - to collect our RA-patients.notebooks/2_extract_features.ipynb: Notebook whereby we extract the relevant features from the Electronic Health Recordsnotebooks/3_process_lab.ipynb: Notebook dedicated to processing the lab data from the EHRnotebooks/4_process_mannequin.ipynb: Notebook dedicated to processing the joint mannequin data from the EHR & creating additional featuresnotebooks/5_clustering.ipynb: This notebook performs PhenoGraph graph clustering on the patient embedding created with MMAE and creates a metadata table. Several steps are taken to define the ideal number of clusters and to evaluate the robustness of the clustering technique.notebooks/6_process_medication.ipynb: Notebook that process the medication informationnotebooks/7_survival_analysis.ipynb: Notebook that performs survival analysis to see if our clusters correspond to long term outcomes (MTX-discontinuation, Remission)notebooks/8_replication_setB.ipynb: Notebook that processes & projects replication data. To see if our clusters are recurring in an independent data set.notebooks/9_treatment_analysis.ipynb: Notebook that checks for any noticeable differences in treatment response.notebooks/10_build_MTX_predictor.rmd: R Markdown notebook to perform downstream analysis steps like: checking for Physican bias, global trend in treatment response and evaluating the quality of an MTX-success predictornotebooks/additional_steps/Compute_DAS.ipynb*: Computes the disease activity scores based on the components, to counter the otherwise large missingnessresults/treatmentRespons: Stores the OR for the different patients.sql/*: Directory consisting of the different SQL-queries used to extract data from the Leiden EHR digital system (Excluded: sensitive data)src/1_emr_scripts/*: All python scripts used for preprocessing the data are stored heresrc/2_latent_space/*: Scripts for creating the patient embedding with MMAEsrc/3_downstream/*: Features scripts for downstream analysis like Bootstrapping or SHAP experimentTSNE/*: The interactive TSNE plots are stored here (Blinded)
If you experience difficulties with implementing the pipeline or if you have any other questions feel free to send me an e-mail. You can contact me on: t.d.maarseveen@lumc.nl