Bi-Directional Context Referencing (PubSub) #185
Comments
|
You might find the complexity level and cognitive burden can be kept much lower if you use an Observer/Observable pattern instead of Publisher/Subscriber.
Observables also play really nicely with the Functional Reactive Programming paradigm, which is the perfect & ideal fit for a problem like neural networks and machine learning. The network "supervisor" or root container "observes" it's nodes and network architecture (observables), and reacts to changes directly. All transformation functions become a composable pipeline that get fired automatically on changes. Node/Network change happens --> Transform 1 ---> Transform 2 ---> Finished Tweak, add, or remove transformation pipeline steps as needed using pure functions without having negative impact anywhere else or getting tangled in spaghetti. I don't know whether or not this would degrade speed/performance, but it's definitely something worth looking into.
|


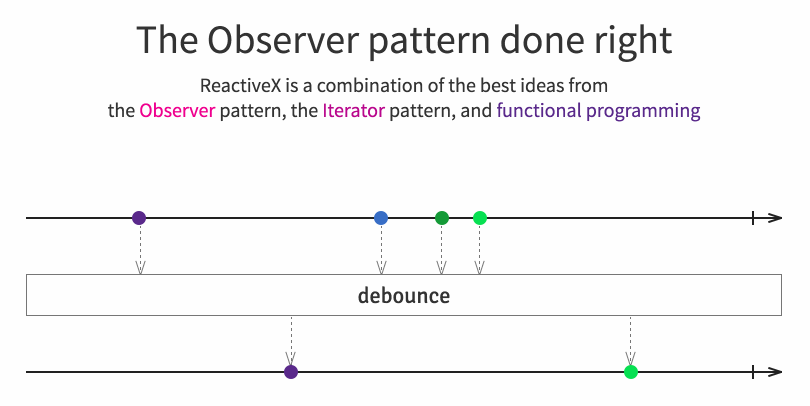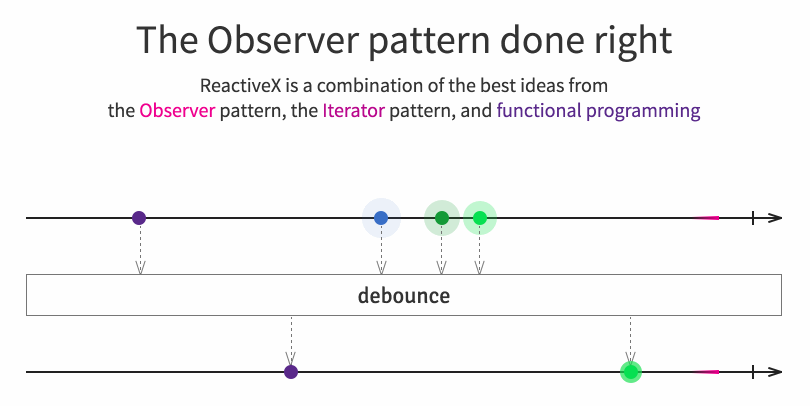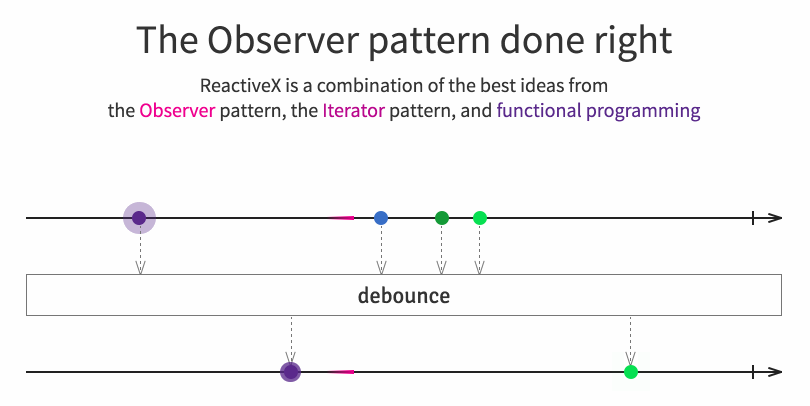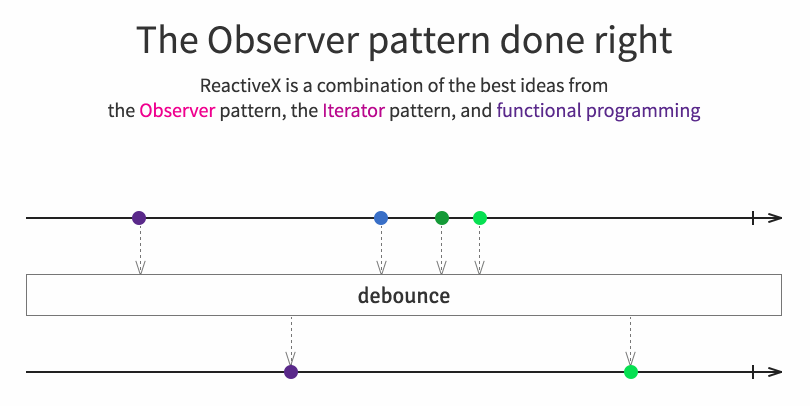
|
For an event emitter though, Mitt is probably the most lightweight: |
|
Additional Note: Lower-level abstraction objects (i.e. Connections, Nodes, Networks, etc.) should all have contextually modified behavior and keep track of the context that they exist in. Example: If a network is going to |
This is beautiful!!!!! I was checking out: Wrote myself a little playground with them as well - so I can build on top of @christianechevarria new implementation of NEAT. // Checks: https://github.com/jeromeetienne/microevent.js/blob/master/microevent.js
// Works on Browser and Node.js with a very simple API
{
// let MicroEvent = require("microevent");
// Creates a class
function Connection() {
let self = this;
this.setWeight = function() {
self.trigger("weight_set", new Date());
}
}
// Gives the class the ability to create instances that emit events
MicroEvent.mixin(Connection);
// Creates a new instance of the class
let connection = new Connection();
// Adds an EventListener to the instance
connection.bind("weight_set", function(date) {
console.log(date);
});
// Triggers an Event from within the instance
connection.setWeight(); // Should trigger a DateTime log to console
}
// Checks: https://github.com/primus/eventemitter3/blob/master/index.js
// Used: https://medium.com/beginners-guide-to-mobile-web-development/super-and-extends-in-javascript-es6-understanding-the-tough-parts-6120372d3420
// Used: https://nodejs.org/dist/latest-v12.x/docs/api/events.html
// Works on Node.js and Browser - is super fast and exhaustively documented
{
// let EventEmitter = require("eventemitter3");
// Creates a class that prototypically inherits `EventEmitter`
function Connection() {
EventEmitter.call(this);
};
Connection.prototype = Object.create(EventEmitter.prototype);
Connection.prototype.constructor = Connection;
// Creates an instance function emits an Event
Connection.prototype.setWeight = function() {
this.emit("weight_set", new Date());
};
// Creates a new instance of the class
let connection = new Connection();
// Adds an EventListener to the instance
connection.on("weight_set", function(date) {
console.log(date);
});
// Triggers an Event from within the instance
connection.setWeight(); // Should trigger a DateTime log to console
}
// Checks: https://github.com/developit/mitt |
I was looking for a way to manage a bunch of events. I'm trying to figure out an API that I can use to serialize/queue up everything into "bite-size" operations, that can be reduced/joined into matrix operations for GPU consumption. I think this will be how we deal with the variable size matrix problem. I was looking at stream merging utilities and event-queues - the idea was to go from an event to a queue of seperate streams that can be grouped together, chunked, and queried as an array. |
Expanding on this a bit... Basically, there are a bunch of different class instances emitting events - willy-nilly - and there are a bunch of things that depends on those processes "finishing" (or emitting an "end" event) to continue working...and if the work that the individual objects needs depends on multiple events being triggered, then you can get a little bit of a crazy scenario. So as a way to handle this they created an architecture that handles this with a simple idea: Events -> EventHandlers -> Streams -> StreamHandlers -> Jobs -> JobsHandlers -> Events Basically, at any given point a bunch of Events can be triggered and need to be sorted into buckets (i.e. Streams). Streams are being stuffed with information on an "on arrival" basis and the information in them is not necessarily sorted or synced across streams; so frequently, before the information can be processed you need a "StreamHandler" that is reading the first things out of the streams and grouping them with the first things out of other streams into jobs - or pushing them further back in the streams so the next information can get grouped/processed. Information that successfuly gets grouped from the streams get turned into a "Job" or the smallest executable piece of code. Some of those jobs can be done in parallel - some depend on previous jobs being done. The JobHandler manages that executional pattern - and once done triggers a bunch of new events.
|

Let's say that we're using NEAT to evolve neural networks. Let's say that within that context we're trying to keep track of innovationIDs - i.e. what connection is new to the population. In other words, when using NEAT, connections get created and destroyed all-the-time (almost constantly); what we want to to keep track of is discoveries (i.e. innovations) to the to the topology of any network in a population (i.e. group) thereof. By giving each neuron in a network an ID and using Cantor Pairing - we can track any time that a connection is "structurally" innovative. Cantor Pairs allows us to uniquely keep track and map the unique integer IDs of the Nodes to a unique ID of a connection; put another way, even if a connection between two nodes gets destroyed, we will know that it was already introduced to the population a while ago.
To be able to keep track of all of these things we need to able to have connections "communicate" with the population - and vice-a-versa. The "classes" in between should work as universal translators and communicators between the two classes.
Allowing networks to create new connections, that are potentially innovative, while concurrently updating the population's list of structural innovations.
This can get done with
EventEmittersandEvenListeners. Where multiple contextually relevant objects communicate with each other on event based triggers.Additional Information
@christianechevarria and @luiscarbonell contemplated this idea while implementing "full-NEAT" into Liquid Carrot
The text was updated successfully, but these errors were encountered: