Streaming mode implementation of the Piper TTS system in C++ with (optional) RK3588 NPU acceleration support. Named after "speaking" in Esperanto.
Before building, you will need to fulfill the following dependencies
- xtensor
- spdlog
- libfmt
- piper-phoenomize
- onnxruntime (1.14 or 1.15)
- A C++20 capable compiler
(API/Web server)
- Drogon
- libsoxr
- libopusenc
- You'll need to build this from source if on Ubuntu 22.04. Package available starting on 23.04
(RKNN support)
In which piper-phoenomize and onnxruntime binary (not the source! Unless you want to build yourselves!) likely needs to be downloaded and decompressed manually. Afterwards run CMake and point to the folders you recompressed them.
mkdir build
cd build
cmake .. -DORT_ROOT=/path/to/your/onnxruntime-linux-aarch64-1.14.1 -DPIPER_PHONEMIZE_ROOT=/path/to/your/piper-phonemize-2023-11-14 -DCMAKE_BUILD_TYPE=Release
make -j
# IMPORTANT! Copy espeak-ng-data or pass `--espeak_data` CLI flag
cp -r /path/to/your/piper-phonemize-2023-11-14/share/espeak-ng-data .Afterwards run paroli-cli and type into the console to synthesize speech. Please refer to later sections for generating the models.
./paroli-cli --encoder /path/to/your/encoder.onnx --decoder /path/to/your/decoder.onnx -c /path/to/your/model.json
...
[2023-12-23 03:13:12.452] [paroli] [info] Wrote /home/marty/Documents/rkpiper/build/./1703301190238261389.wav
[2023-12-23 03:13:12.452] [paroli] [info] Real-time factor: 0.16085024956315996 (infer=2.201744556427002 sec, audio=13.688163757324219 sec)
An web API server is also provided so other applications can easily perform text to speech. For details, please refer to the web API document for details. By default, a demo UI can be accessed at the root of the URL. The API server supports both responding with compressed audio to reduce bandwidth requirement and streaming audio via WebSocket.
To run it:
./paroli-server --encoder /path/to/your/encoder.onnx --decoder /path/to/your/decoder.onnx -c /path/to/your/model.json --ip 0.0.0.0 --port 8848And to invoke TSS
curl http://your.server.address:8848/api/v1/synthesise -X POST -H 'Content-Type: application/json' -d '{"text": "To be or not to be, that is the question"}' > test.opusDemo:
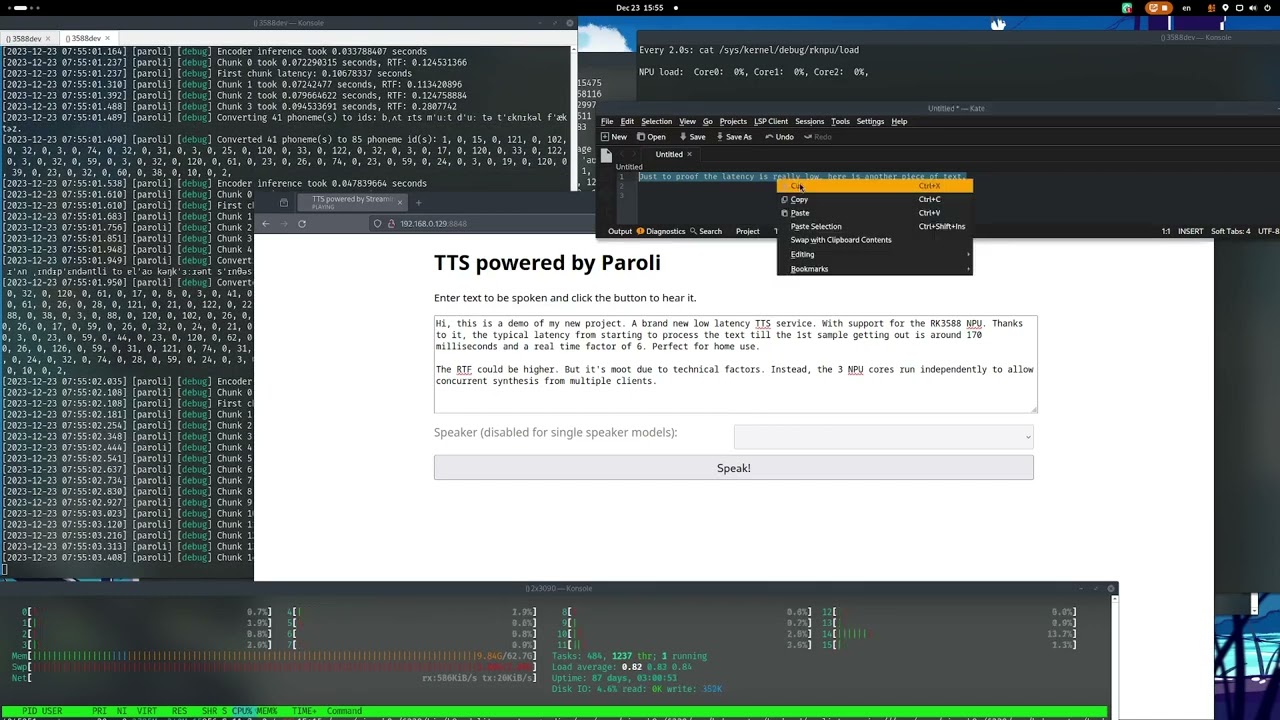
To enable use cases where the service is exposed for whatever reason. The API server supports a basic authentication scheme. The --auth flag will generate a bearer token that is different every time and both websocket and HTTP synthesis API will only work if enabled. --auth [YOUR_TOKEN] will set the token to YOUR_TOKEN. Furthermore setting the PAROLI_TOKEN environment variable will set the bearer token to whatever the environment variable is set to.
Authentication: Bearer <insert the token>
The Web UI will not work when authentication is enabled
To obtain the encoder and decoder models, you'll either need to download them or creating one from checkpoints. Checkpoints are the trained raw model piper generates. Please refer to piper's TRAINING.md for details. To convert checkpoints into ONNX file pairs, you'll need mush42's piper fork and the streaming branch. Run
python3 -m piper_train.export_onnx_streaming /path/to/your/traning/lighting_logs/version_0/checkpoints/blablablas.ckpt /path/to/output/directorySome 100% legal models are provided on HuggingFace.
By default the models run on the CPU and could be power hungry and slow. If you'd like to use a GPU and, etc.. You can pass the --accelerator cuda flag in the CLI to enable it. For now the only supported accelerator is CUDA. But ROCm can be easily supported, just I don't have the hardware to test it. Feel free to contribute.
This is the list of supported accelerators:
cuda- NVIDIA CUDAtensorrt- NVIDIA TensorRT
Additionally, on RK3588 based systems, the NPU support can be enabled by passing -DUSE_RKNN=ON into CMake and passing an RKNN model instead of ONNX as the decoder. Resulting in ~4.3x speedup compare to running on the RK3588 CPU cores. Note that the accelerator flag has no effect when the a RKNN model is used and only the decoder can run on the RK3588 NPU.
Rockchip does not provide any package of some sort to install the libraries and headers. This has to be done manually.
git clone https://github.com/rockchip-linux/rknn-toolkit2
cd rknn-toolkit2/rknpu2/runtime/Linux/librknn_api
sudo cp aarch64/librknnrt.so /usr/lib/
sudo cp include/* /usr/include/Also, converting ONNX to RKNN has to be done on an x64 computer. As of writing this document, you likely want to install the version for Python 3.10 as this is the same version that works with upstream piper. rknn-toolkit2 version 1.6.0 is required.
# Install rknn-toolkit2
git clone https://github.com/rockchip-linux/rknn-toolkit2
cd rknn-toolkit2/tree/master/rknn-toolkit2/packages
pip install rknn_toolkit2-1.6.0+81f21f4d-cp310-cp310-linux_x86_64.whl
# Run the conversion script
python tools/decoder2rknn.py /path/to/model/decoder.onnx /path/to/model/decoder.rknnTo use RKNN for inference, simply pass the RKNN model in the CLI. An error will appear if RKNN is passed in but RKNN support not enabled during compiling.
./paroli-cli --encoder /path/to/your/encoder.rknn --decoder /path/to/your/decoder.onnx -c /path/to/your/model.json
# ^^^^
# The only changeTODO:
- Code cleanup
- Investigate ArmNN to accelerate encoder inference
- Better handling for authentication
- RKNN
- Add dynamic shape support when Rockchip fixes them
- Try using quantization see if the speedup is worth the lowered quality
There's no good way to reduce synthesis latency on RK3588 besides Rockchip improving rknnrt and their compiler. The encoder is a dynamic graph thus RKNN won't work. And how they implement multi-NPU co-process prohibits faster single batch inference. Multi batch can be made faster but I don't see the value of it as it is already fast enough for home use.