This is Modelling ML, a code-free Machine Learning (ML) tool presented in a Graphical user interface (GUI) which covers the most important steps in the design of Classification and Regression Machine Learning models.
Modelling ML is 100% coded in Python 3 and uses some of the most popular libraries for Data Science and ML such as Scikit-learn, Pandas, Matplotlib, Numpy, etc. The GUI was built on top of Qt using PyQt5.
This project is in constant development. Hence, make sure you use the latest version and feel free to report any bugs. There is a To-do List in the bottom of this page and suggestions are welcomed.
If you want to get involved in this project, please, feel free to contribute by submitting your pull request.
- 1.0 - Better done than Perfect (Current)
- Run src/main.py
- Use Qt Designer to update the files from resources/ui. (Trust me, you don't want to build a GUI using code).
- Run src/convert_ui_to_py.py (Do not fiddle with src/view.py nor src/ml_gui_resources_rc.py. Let the pyuic5 package called in src/convert_ui_to_py.py do its jobs.)
Ideally, this tool should be self-explanatory...
A user interface (UI) is like a joke. If you have to explain it, it’s not that good
In case this UI fails to achieve the same level as a nice joke, please, check below for some extra info regarding each separate tab from Modelling ML.
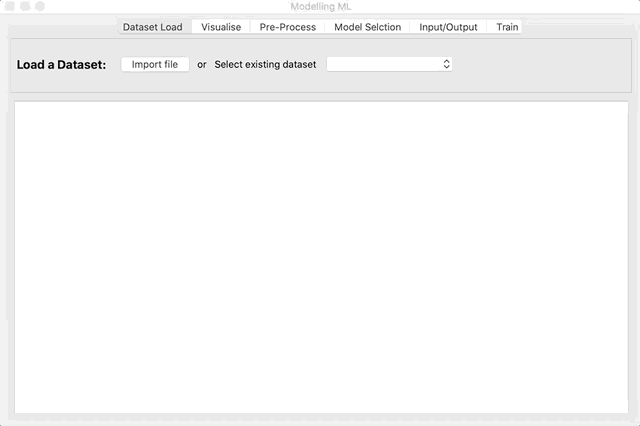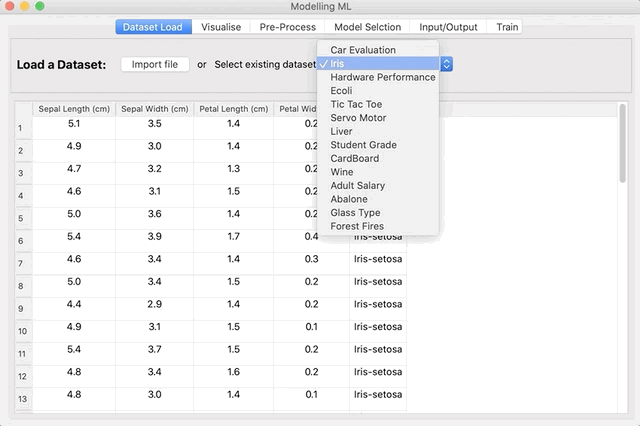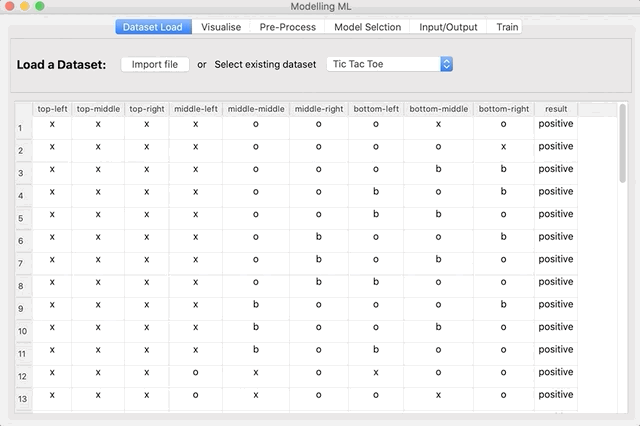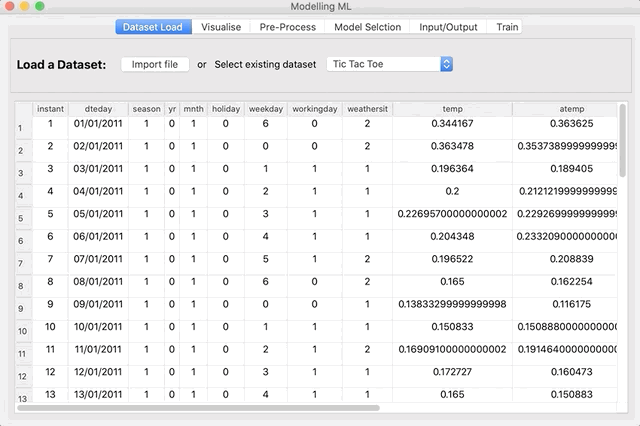
In the first tab of Modelling ML you can either select an example dataset from the dropdown box or load a dataset from a file. Currently, the file extensions accepted are .csv, .xls and .xlsx. Once the Dataset is selected, the first 50 rows are shown.
In V1.0, Modelling ML works better with datasets that contain the variable labels in the top row and a single data type per column (just like the ones from data). Funny datasets with multiple data types in the same column may cause Modelling ML to get very angry and explode 💥.
This should be improved in the future.

The visualisation tab displays some basic plots and a summary of the variable chosen in the dropdown box.

The Pre-Processing tab is where you can apply some modifications to your Dataset while it is live updated and displayed to you.
The pre-processing elements you select will be applied sequentially according to what is displayed in Pre-Processing Sequence section. Any update in the pre-processing sequence will trigger Modelling ML to run all the pre-processing steps from beginning 🔃.

The Model Selection Tab is where you choose between a Regression or Classification model. Choose Wisely!
According to your choice, different ML algorithms will be presented and you can adjust some of its main parameters 🎛.

The Input/Output tap is where you select the input and output variables for you ML model.
- When Regression is selected in the previous tab, one or more numerical variables should be used as output.
- When Classification is selected in the previous tab, a single categorical variable should be used as output.

Once a Dataset has been loaded, the ML model has been selected as well as the input and output variables, you are ready
to hit the Train Model button. If you skip any of the required steps, you will not be allowed to train your model
Whether you are training a Regression or Classification model, the correspondent metrics will be shown as well as a plot illustrating the result of your trained model.
- Finish Implementing the other ML Algorithms from Model Selection Tab
- Add a Testing Tab
- Add more example Datasets
- Accept file extensions other than (.csv, .xls and .xlsx)
- Handle Unusual Datasets files (heterogeneous columns)
- Handle Keyboard Events
- Add other Pre-Processing options
- Give the user the option to choose which variables are categorical
- Display Pre-Processed and Original Datasets in the Visualisation Tab (Combobox)
- Generate Executable files for Windows and macOS.