about steps related to the reward #11
Comments
With default "MAX_TIME_STEP" constant in constants.py, MAX_TIME_STEP is 100M. BTW, @Itsukara has also reported same result that score stops around 80M. Maybe he is using A3C-FF mode? He also tried live-loss-as-terminal, and the learning speed was faster.
Ah I see. It might take effect. There is another A3C implementation which reports higher breakout score. https://github.com/ppwwyyxx/tensorpack/tree/master/examples/Atari2600 Their A3C learning code seems not yet released, but please check once their code is released. |
{kind=link}
|
Thanks for your reply, @Itsukara improvement looks quite good. I'm trying it now. |
|
@congling And he said that he was using A3C-FF when recording this graph. |
|
Btw the code which @congling has used is not equivalent to resetting game on life lost. :p This is because all it says is that if you just lost a life, then it does not matter what the value estimate of next state is, treat it as 0. |
|
@congling conglinghello, i am a little confused where to add the code with lives in the released code. I have problem trained with Breakout and i only reached 50 when steps are 18m. Can you give me your implemention code ? thank you. |
|
@1601214542 hey i have this problem too! hmm. is 50 train or test score(in which you get 5 lives to spare)? how often is it? |
Hi Kosuke,
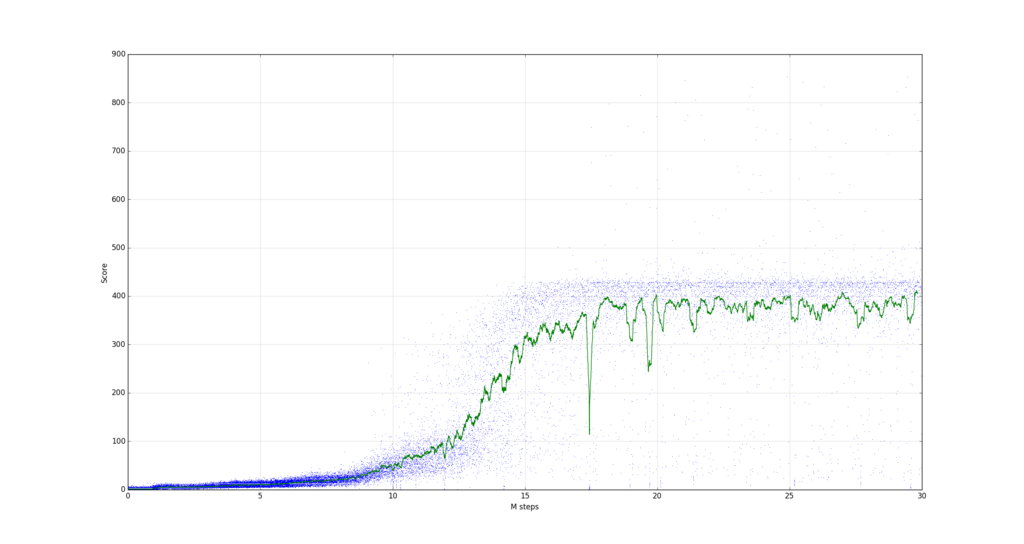
I've tried your model on breakout game. The performance was amazing, the average score went up to 520 after 80M steps. It's far more better than any other model I've tried.
But the average score didn't went up much after 80M. Sometimes game costs plenty of steps. When the bricks left 1 or 2 pieces, the ball went between your board and the wall, but never hits the remain bricks.
Do you think if it's better to add steps of games as the penalty to calculate R? such as
R-=beta*sqrt(steps)
Thanks
BTW, I've do some changes
1 changed the ACTION_SIZE= 4, because breakout have 4 actions in ALE.
2 If lives is lost, treat it as terminal
#if not terminal_end:
if lives==new_lives and not terminal_end:
R = self.local_network.run_value(sess, self.game_state.s_t)
else:
#print("lives cost from %d to %d"%(lives,new_lives))
lives = new_lives
The text was updated successfully, but these errors were encountered: