 @@ -41,7 +39,9 @@ Welcome to join our [Slack channel](https://join.slack.com/t/data-juicer/shared_
----
## News
--  [2024-02-20] We have actively maintained an awesome list of LLM-Data, welcome to [visit](docs/awesome_llm_data.md) and contribute!
+-  [2024-03-07] We release **Data-Juicer [v0.2.0](https://github.com/alibaba/data-juicer/releases/tag/v0.2.0)** now!
+In this new version, we support more features for **multimodal data (including video now)**, and introduce **[DJ-SORA](docs/DJ_SORA.md)** to provide open large-scale, high-quality datasets for SORA-like models.
+-  [2024-02-20] We have actively maintained an *awesome list of LLM-Data*, welcome to [visit](docs/awesome_llm_data.md) and contribute!
-  [2024-02-05] Our paper has been accepted by SIGMOD'24 industrial track!
- [2024-01-10] Discover new horizons in "Data Mixture"—Our second data-centric LLM competition has kicked off! Please visit the competition's [official website](https://tianchi.aliyun.com/competition/entrance/532174) for more information.
- [2024-01-05] We release **Data-Juicer v0.1.3** now!
@@ -56,9 +56,11 @@ Besides, our paper is also updated to [v3](https://arxiv.org/abs/2309.02033).
Table of Contents
=================
-* [Data-Juicer: A One-Stop Data Processing System for Large Language Models](#data-juicer--a-one-stop-data-processing-system-for-large-language-models)
+* [Data-Juicer: A One-Stop Data Processing System for Large Language Models](#data-juicer-a-one-stop-data-processing-system-for-large-language-models)
* [Table of Contents](#table-of-contents)
* [Features](#features)
+ * [Documentation Index | 文档索引](#documentation-index--文档索引-a-namedocumentationindex)
+ * [Demos](#demos)
* [Prerequisites](#prerequisites)
* [Installation](#installation)
* [From Source](#from-source)
@@ -67,25 +69,25 @@ Table of Contents
* [Installation check](#installation-check)
* [Quick Start](#quick-start)
* [Data Processing](#data-processing)
+ * [Distributed Data Processing](#distributed-data-processing)
* [Data Analysis](#data-analysis)
* [Data Visualization](#data-visualization)
* [Build Up Config Files](#build-up-config-files)
* [Preprocess raw data (Optional)](#preprocess-raw-data-optional)
* [For Docker Users](#for-docker-users)
- * [Documentation | 文档](#documentation)
* [Data Recipes](#data-recipes)
- * [Demos](#demos)
* [License](#license)
* [Contributing](#contributing)
* [Acknowledgement](#acknowledgement)
* [References](#references)
+
## Features
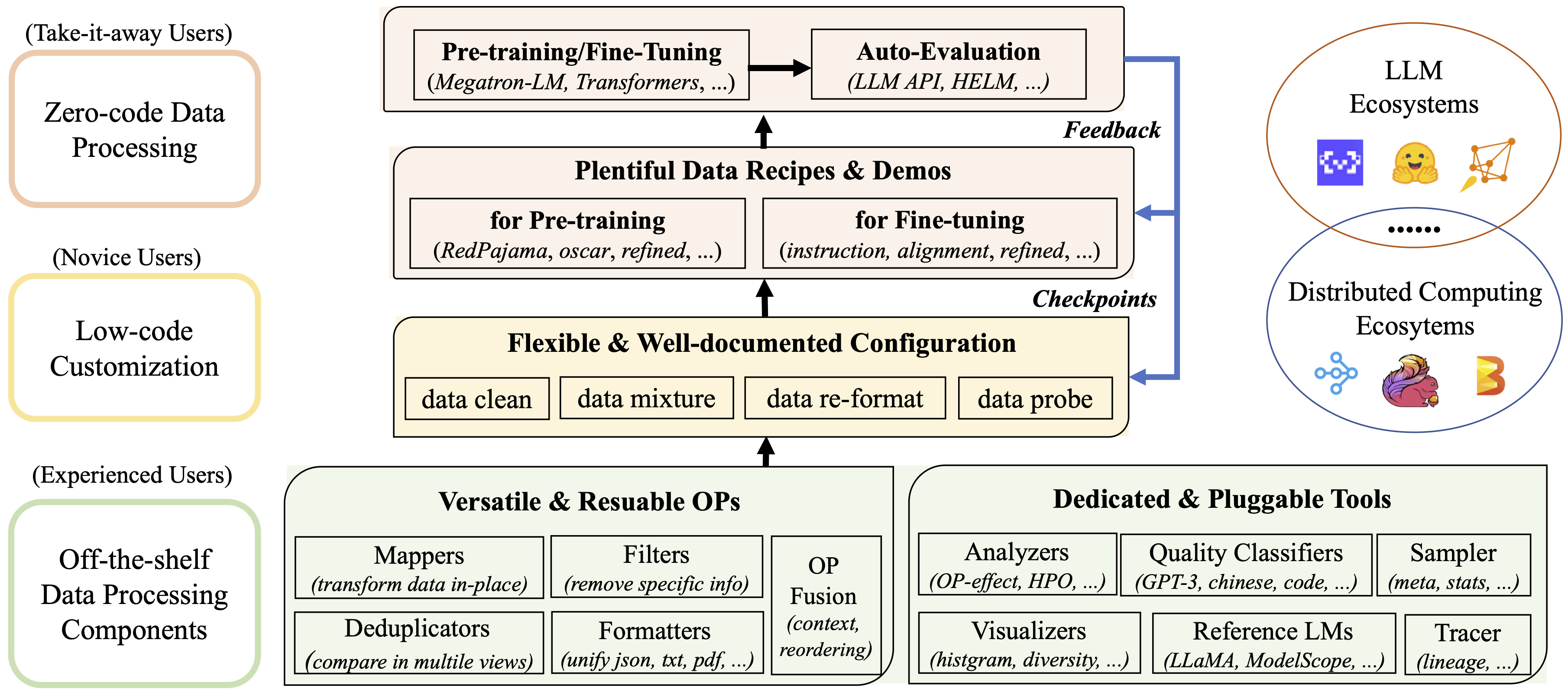
- **Systematic & Reusable**:
- Empowering users with a systematic library of 20+ reusable [config recipes](configs), 50+ core [OPs](docs/Operators.md), and feature-rich
+ Empowering users with a systematic library of 80+ core [OPs](docs/Operators.md), 20+ reusable [config recipes](configs), and 20+ feature-rich
dedicated [toolkits](#documentation), designed to
function independently of specific LLM datasets and processing pipelines.
@@ -95,7 +97,7 @@ Table of Contents
- **Comprehensive Data Processing Recipes**: Offering tens of [pre-built data
processing recipes](configs/data_juicer_recipes/README.md) for pre-training, fine-tuning, en, zh, and more scenarios. Validated on
- reference LLaMA models.
+ reference LLaMA and LLaVA models.
- **Enhanced Efficiency**: Providing a speedy data processing pipeline
@@ -107,9 +109,47 @@ Table of Contents
- **User-Friendly Experience**: Designed for simplicity, with [comprehensive documentation](#documentation), [easy start guides](#quick-start) and [demo configs](configs/README.md), and intuitive configuration with simple adding/removing OPs from [existing configs](configs/config_all.yaml).
+
+
+## Documentation Index | 文档索引
@@ -41,7 +39,9 @@ Welcome to join our [Slack channel](https://join.slack.com/t/data-juicer/shared_
----
## News
--  [2024-02-20] We have actively maintained an awesome list of LLM-Data, welcome to [visit](docs/awesome_llm_data.md) and contribute!
+-  [2024-03-07] We release **Data-Juicer [v0.2.0](https://github.com/alibaba/data-juicer/releases/tag/v0.2.0)** now!
+In this new version, we support more features for **multimodal data (including video now)**, and introduce **[DJ-SORA](docs/DJ_SORA.md)** to provide open large-scale, high-quality datasets for SORA-like models.
+-  [2024-02-20] We have actively maintained an *awesome list of LLM-Data*, welcome to [visit](docs/awesome_llm_data.md) and contribute!
-  [2024-02-05] Our paper has been accepted by SIGMOD'24 industrial track!
- [2024-01-10] Discover new horizons in "Data Mixture"—Our second data-centric LLM competition has kicked off! Please visit the competition's [official website](https://tianchi.aliyun.com/competition/entrance/532174) for more information.
- [2024-01-05] We release **Data-Juicer v0.1.3** now!
@@ -56,9 +56,11 @@ Besides, our paper is also updated to [v3](https://arxiv.org/abs/2309.02033).
Table of Contents
=================
-* [Data-Juicer: A One-Stop Data Processing System for Large Language Models](#data-juicer--a-one-stop-data-processing-system-for-large-language-models)
+* [Data-Juicer: A One-Stop Data Processing System for Large Language Models](#data-juicer-a-one-stop-data-processing-system-for-large-language-models)
* [Table of Contents](#table-of-contents)
* [Features](#features)
+ * [Documentation Index | 文档索引](#documentation-index--文档索引-a-namedocumentationindex)
+ * [Demos](#demos)
* [Prerequisites](#prerequisites)
* [Installation](#installation)
* [From Source](#from-source)
@@ -67,25 +69,25 @@ Table of Contents
* [Installation check](#installation-check)
* [Quick Start](#quick-start)
* [Data Processing](#data-processing)
+ * [Distributed Data Processing](#distributed-data-processing)
* [Data Analysis](#data-analysis)
* [Data Visualization](#data-visualization)
* [Build Up Config Files](#build-up-config-files)
* [Preprocess raw data (Optional)](#preprocess-raw-data-optional)
* [For Docker Users](#for-docker-users)
- * [Documentation | 文档](#documentation)
* [Data Recipes](#data-recipes)
- * [Demos](#demos)
* [License](#license)
* [Contributing](#contributing)
* [Acknowledgement](#acknowledgement)
* [References](#references)
+
## Features

- **Systematic & Reusable**:
- Empowering users with a systematic library of 20+ reusable [config recipes](configs), 50+ core [OPs](docs/Operators.md), and feature-rich
+ Empowering users with a systematic library of 80+ core [OPs](docs/Operators.md), 20+ reusable [config recipes](configs), and 20+ feature-rich
dedicated [toolkits](#documentation), designed to
function independently of specific LLM datasets and processing pipelines.
@@ -95,7 +97,7 @@ Table of Contents
- **Comprehensive Data Processing Recipes**: Offering tens of [pre-built data
processing recipes](configs/data_juicer_recipes/README.md) for pre-training, fine-tuning, en, zh, and more scenarios. Validated on
- reference LLaMA models.
+ reference LLaMA and LLaVA models.

- **Enhanced Efficiency**: Providing a speedy data processing pipeline
@@ -107,9 +109,47 @@ Table of Contents
- **User-Friendly Experience**: Designed for simplicity, with [comprehensive documentation](#documentation), [easy start guides](#quick-start) and [demo configs](configs/README.md), and intuitive configuration with simple adding/removing OPs from [existing configs](configs/config_all.yaml).
+
+
+## Documentation Index | 文档索引  -[](https://arxiv.org/abs/2309.02033)


-[](docs/DeveloperGuide_ZH.md)
-
[](https://pypi.org/project/py-data-juicer)
[](https://hub.docker.com/r/datajuicer/data-juicer)
-[](README.md#documentation)
-[](README_ZH.md#documentation)
-[](https://alibaba.github.io/data-juicer/)
-[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
-[](https://modelscope.cn/datasets?organization=Data-Juicer&page=1)
-[](https://modelscope.cn/models?organization=Data-Juicer&page=1)
+[](docs/DeveloperGuide_ZH.md)
+[](docs/DeveloperGuide_ZH.md)
+[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
+[](https://huggingface.co/spaces?&search=datajuicer)
+
+[](README.md#documentation-index--文档索引-a-namedocumentationindex)
+[](README_ZH.md#documentation-index--文档索引-a-namedocumentationindex)
+[](https://alibaba.github.io/data-juicer/)
+[](https://arxiv.org/abs/2309.02033)
-[](https://huggingface.co/spaces?&search=datajuicer)
-[](https://huggingface.co/datasets?&search=datajuicer)
-[](https://huggingface.co/models?&search=datajuicer)
-[](tools/quality_classifier/README_ZH.md)
-[](tools/evaluator/README_ZH.md)
+Data-Juicer 是一个一站式**多模态**数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
-Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
-本项目在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。欢迎您加入我们推进 LLM 数据的开发和研究工作!
+Data-Juicer(包含[DJ-SORA](docs/DJ_SORA_ZH.md))正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们,一起推进LLM数据的开发和研究!
如果Data-Juicer对您的研发有帮助,请引用我们的[工作](#参考文献) 。
@@ -39,7 +34,8 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
----
## 新消息
--  [2024-02-20] 我们在积极维护一份关于LLM-Data的精选列表,欢迎[访问](docs/awesome_llm_data.md)并参与贡献!
+-  [2024-03-07] 我们现在发布了 **Data-Juicer [v0.2.0](https://github.com/alibaba/data-juicer/releases/tag/v0.2.0)**! 在这个新版本中,我们支持了更多的 **多模态数据(包括视频)** 相关特性。我们还启动了 **[DJ-SORA](docs/DJ_SORA_ZH.md)** ,为SORA-like大模型构建开放的大规模高质量数据集!
+-  [2024-02-20] 我们在积极维护一份关于LLM-Data的*精选列表*,欢迎[访问](docs/awesome_llm_data.md)并参与贡献!
-  [2024-02-05] 我们的论文被SIGMOD'24 industrial track接收!
- [2024-01-10] 开启“数据混合”新视界——第二届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532174),了解赛事详情。
@@ -54,10 +50,11 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
目录
===
-
* [Data-Juicer: 为大语言模型提供更高质量、更丰富、更易“消化”的数据](#data-juicer-为大语言模型提供更高质量更丰富更易消化的数据)
* [目录](#目录)
* [特点](#特点)
+ * [Documentation Index | 文档索引](#documentation-index--文档索引-a-namedocumentationindex)
+ * [演示样例](#演示样例)
* [前置条件](#前置条件)
* [安装](#安装)
* [从源码安装](#从源码安装)
@@ -66,28 +63,28 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
* [安装校验](#安装校验)
* [快速上手](#快速上手)
* [数据处理](#数据处理)
+ * [分布式数据处理](#分布式数据处理)
* [数据分析](#数据分析)
* [数据可视化](#数据可视化)
* [构建配置文件](#构建配置文件)
* [预处理原始数据(可选)](#预处理原始数据可选)
* [对于 Docker 用户](#对于-docker-用户)
- * [Documentation | 文档](#documentation)
* [数据处理菜谱](#数据处理菜谱)
- * [演示样例](#演示样例)
* [开源协议](#开源协议)
* [贡献](#贡献)
* [致谢](#致谢)
* [参考文献](#参考文献)
+
## 特点

-* **系统化 & 可复用**:为用户提供系统化且可复用的20+[配置菜谱](configs/README_ZH.md),50+核心[算子](docs/Operators_ZH.md)和专用[工具池](#documentation),旨在让数据处理独立于特定的大语言模型数据集和处理流水线。
+* **系统化 & 可复用**:为用户提供系统化且可复用的80+核心[算子](docs/Operators_ZH.md),20+[配置菜谱](configs/README_ZH.md)和20+专用[工具池](#documentation),旨在让数据处理独立于特定的大语言模型数据集和处理流水线。
* **数据反馈回路**:支持详细的数据分析,并提供自动报告生成功能,使您深入了解您的数据集。结合多维度自动评估功能,支持在 LLM 开发过程的多个阶段进行及时反馈循环。 
-* **全面的数据处理菜谱**:为pre-training、fine-tuning、中英文等场景提供数十种[预构建的数据处理菜谱](configs/data_juicer_recipes/README_ZH.md)。 
+* **全面的数据处理菜谱**:为pre-training、fine-tuning、中英文等场景提供数十种[预构建的数据处理菜谱](configs/data_juicer_recipes/README_ZH.md)。 在LLaMA、LLaVA等模型上有效验证。 
* **效率增强**:提供高效的数据处理流水线,减少内存占用和CPU开销,提高生产力。 
@@ -96,9 +93,47 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
* **灵活 & 易扩展**:支持大多数数据格式(如jsonl、parquet、csv等),并允许灵活组合算子。支持[自定义算子](docs/DeveloperGuide_ZH.md#构建自己的算子),以执行定制化的数据处理。
+## Documentation Index | 文档索引
+
+* [Overview](README.md) | [概览](README_ZH.md)
+* [Operator Zoo](docs/Operators.md) | [算子库](docs/Operators_ZH.md)
+* [Configs](configs/README.md) | [配置系统](configs/README_ZH.md)
+* [Developer Guide](docs/DeveloperGuide.md) | [开发者指南](docs/DeveloperGuide_ZH.md)
+* ["Bad" Data Exhibition](docs/BadDataExhibition.md) | [“坏”数据展览](docs/BadDataExhibition_ZH.md)
+* Dedicated Toolkits | 专用工具箱
+ * [Quality Classifier](tools/quality_classifier/README.md) | [质量分类器](tools/quality_classifier/README_ZH.md)
+ * [Auto Evaluation](tools/evaluator/README.md) | [自动评测](tools/evaluator/README_ZH.md)
+ * [Preprocess](tools/preprocess/README.md) | [前处理](tools/preprocess/README_ZH.md)
+ * [Postprocess](tools/postprocess/README.md) | [后处理](tools/postprocess/README_ZH.md)
+* [Third-parties (LLM Ecosystems)](thirdparty/README.md) | [第三方库(大语言模型生态)](thirdparty/README_ZH.md)
+* [API references](https://alibaba.github.io/data-juicer/)
+* [Awesome LLM-Data](docs/awesome_llm_data.md)
+* [DJ-SORA](docs/DJ_SORA_ZH.md)
+
+
+## 演示样例
+
+* Data-Juicer 介绍 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/overview_scan/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/overview_scan)]
+* 数据可视化:
+ * 基础指标统计 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_statistics/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_statistics)]
+ * 词汇多样性 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_diversity/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_diversity)]
+ * 算子洞察(单OP) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visualization_op_insight/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_op_insight)]
+ * 算子效果(多OP) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_op_effect/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_op_effect)]
+* 数据处理:
+ * 科学文献 (例如 [arXiv](https://info.arxiv.org/help/bulk_data_s3.html)) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/process_sci_data/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/process_sci_data)]
+ * 编程代码 (例如 [TheStack](https://huggingface.co/datasets/bigcode/the-stack)) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/process_code_data/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/process_code_data)]
+ * 中文指令数据 (例如 [Alpaca-CoT](https://huggingface.co/datasets/QingyiSi/Alpaca-CoT)) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/process_sft_zh_data/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/process_cft_zh_data)]
+* 工具池:
+ * 按语言分割数据集 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/tool_dataset_splitting_by_language/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/tool_dataset_splitting_by_language)]
+ * CommonCrawl 质量分类器 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/tool_quality_classifier/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/tool_quality_classifier)]
+ * 基于 [HELM](https://github.com/stanford-crfm/helm) 的自动评测 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/auto_evaluation_helm/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/auto_evaluation_helm)]
+ * 数据采样及混合 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_mixture/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_mixture)]
+* 数据处理回路 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_process_loop/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_process_loop)]
+
+
## 前置条件
-* 推荐 Python>=3.7,<=3.10
+* 推荐 Python>=3.8,<=3.10
* gcc >= 5 (at least C++14 support)
## 安装
@@ -189,6 +224,25 @@ export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
```
+### 分布式数据处理
+
+现在基于RAY对多机分布式的数据处理进行了实现。
+对应Demo可以通过如下命令运行:
+
+```shell
+
+# 运行文字数据处理
+python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml
+
+# 运行视频数据处理
+python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml
+
+```
+
+ - 如果需要在多机上使用RAY运行多模态数据处理,需要确保各分布式节点可以访问对应的数据路径,将对应的数据路径挂载在文件共享系统(如NAS)中
+
+ - 用户也可以不使用RAY,拆分数据集后使用Slurm/DLC在集群上运行
+
### 数据分析
- 以配置文件路径为参数运行 `analyze_data.py` 或者 `dj-analyze` 命令行工具来分析数据集。
@@ -273,48 +327,14 @@ docker run -dit \ # 在后台启动容器
docker exec -it
-[](https://arxiv.org/abs/2309.02033)


-[](docs/DeveloperGuide_ZH.md)
-
[](https://pypi.org/project/py-data-juicer)
[](https://hub.docker.com/r/datajuicer/data-juicer)
-[](README.md#documentation)
-[](README_ZH.md#documentation)
-[](https://alibaba.github.io/data-juicer/)
-[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
-[](https://modelscope.cn/datasets?organization=Data-Juicer&page=1)
-[](https://modelscope.cn/models?organization=Data-Juicer&page=1)
+[](docs/DeveloperGuide_ZH.md)
+[](docs/DeveloperGuide_ZH.md)
+[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
+[](https://huggingface.co/spaces?&search=datajuicer)
+
+[](README.md#documentation-index--文档索引-a-namedocumentationindex)
+[](README_ZH.md#documentation-index--文档索引-a-namedocumentationindex)
+[](https://alibaba.github.io/data-juicer/)
+[](https://arxiv.org/abs/2309.02033)
-[](https://huggingface.co/spaces?&search=datajuicer)
-[](https://huggingface.co/datasets?&search=datajuicer)
-[](https://huggingface.co/models?&search=datajuicer)
-[](tools/quality_classifier/README_ZH.md)
-[](tools/evaluator/README_ZH.md)
+Data-Juicer 是一个一站式**多模态**数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
-Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
-本项目在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。欢迎您加入我们推进 LLM 数据的开发和研究工作!
+Data-Juicer(包含[DJ-SORA](docs/DJ_SORA_ZH.md))正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们,一起推进LLM数据的开发和研究!
如果Data-Juicer对您的研发有帮助,请引用我们的[工作](#参考文献) 。
@@ -39,7 +34,8 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
----
## 新消息
--  [2024-02-20] 我们在积极维护一份关于LLM-Data的精选列表,欢迎[访问](docs/awesome_llm_data.md)并参与贡献!
+-  [2024-03-07] 我们现在发布了 **Data-Juicer [v0.2.0](https://github.com/alibaba/data-juicer/releases/tag/v0.2.0)**! 在这个新版本中,我们支持了更多的 **多模态数据(包括视频)** 相关特性。我们还启动了 **[DJ-SORA](docs/DJ_SORA_ZH.md)** ,为SORA-like大模型构建开放的大规模高质量数据集!
+-  [2024-02-20] 我们在积极维护一份关于LLM-Data的*精选列表*,欢迎[访问](docs/awesome_llm_data.md)并参与贡献!
-  [2024-02-05] 我们的论文被SIGMOD'24 industrial track接收!
- [2024-01-10] 开启“数据混合”新视界——第二届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532174),了解赛事详情。
@@ -54,10 +50,11 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
目录
===
-
* [Data-Juicer: 为大语言模型提供更高质量、更丰富、更易“消化”的数据](#data-juicer-为大语言模型提供更高质量更丰富更易消化的数据)
* [目录](#目录)
* [特点](#特点)
+ * [Documentation Index | 文档索引](#documentation-index--文档索引-a-namedocumentationindex)
+ * [演示样例](#演示样例)
* [前置条件](#前置条件)
* [安装](#安装)
* [从源码安装](#从源码安装)
@@ -66,28 +63,28 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
* [安装校验](#安装校验)
* [快速上手](#快速上手)
* [数据处理](#数据处理)
+ * [分布式数据处理](#分布式数据处理)
* [数据分析](#数据分析)
* [数据可视化](#数据可视化)
* [构建配置文件](#构建配置文件)
* [预处理原始数据(可选)](#预处理原始数据可选)
* [对于 Docker 用户](#对于-docker-用户)
- * [Documentation | 文档](#documentation)
* [数据处理菜谱](#数据处理菜谱)
- * [演示样例](#演示样例)
* [开源协议](#开源协议)
* [贡献](#贡献)
* [致谢](#致谢)
* [参考文献](#参考文献)
+
## 特点

-* **系统化 & 可复用**:为用户提供系统化且可复用的20+[配置菜谱](configs/README_ZH.md),50+核心[算子](docs/Operators_ZH.md)和专用[工具池](#documentation),旨在让数据处理独立于特定的大语言模型数据集和处理流水线。
+* **系统化 & 可复用**:为用户提供系统化且可复用的80+核心[算子](docs/Operators_ZH.md),20+[配置菜谱](configs/README_ZH.md)和20+专用[工具池](#documentation),旨在让数据处理独立于特定的大语言模型数据集和处理流水线。
* **数据反馈回路**:支持详细的数据分析,并提供自动报告生成功能,使您深入了解您的数据集。结合多维度自动评估功能,支持在 LLM 开发过程的多个阶段进行及时反馈循环。 
-* **全面的数据处理菜谱**:为pre-training、fine-tuning、中英文等场景提供数十种[预构建的数据处理菜谱](configs/data_juicer_recipes/README_ZH.md)。 
+* **全面的数据处理菜谱**:为pre-training、fine-tuning、中英文等场景提供数十种[预构建的数据处理菜谱](configs/data_juicer_recipes/README_ZH.md)。 在LLaMA、LLaVA等模型上有效验证。 
* **效率增强**:提供高效的数据处理流水线,减少内存占用和CPU开销,提高生产力。 
@@ -96,9 +93,47 @@ Data-Juicer 是一个一站式数据处理系统,旨在为大语言模型 (LLM
* **灵活 & 易扩展**:支持大多数数据格式(如jsonl、parquet、csv等),并允许灵活组合算子。支持[自定义算子](docs/DeveloperGuide_ZH.md#构建自己的算子),以执行定制化的数据处理。
+## Documentation Index | 文档索引
+
+* [Overview](README.md) | [概览](README_ZH.md)
+* [Operator Zoo](docs/Operators.md) | [算子库](docs/Operators_ZH.md)
+* [Configs](configs/README.md) | [配置系统](configs/README_ZH.md)
+* [Developer Guide](docs/DeveloperGuide.md) | [开发者指南](docs/DeveloperGuide_ZH.md)
+* ["Bad" Data Exhibition](docs/BadDataExhibition.md) | [“坏”数据展览](docs/BadDataExhibition_ZH.md)
+* Dedicated Toolkits | 专用工具箱
+ * [Quality Classifier](tools/quality_classifier/README.md) | [质量分类器](tools/quality_classifier/README_ZH.md)
+ * [Auto Evaluation](tools/evaluator/README.md) | [自动评测](tools/evaluator/README_ZH.md)
+ * [Preprocess](tools/preprocess/README.md) | [前处理](tools/preprocess/README_ZH.md)
+ * [Postprocess](tools/postprocess/README.md) | [后处理](tools/postprocess/README_ZH.md)
+* [Third-parties (LLM Ecosystems)](thirdparty/README.md) | [第三方库(大语言模型生态)](thirdparty/README_ZH.md)
+* [API references](https://alibaba.github.io/data-juicer/)
+* [Awesome LLM-Data](docs/awesome_llm_data.md)
+* [DJ-SORA](docs/DJ_SORA_ZH.md)
+
+
+## 演示样例
+
+* Data-Juicer 介绍 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/overview_scan/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/overview_scan)]
+* 数据可视化:
+ * 基础指标统计 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_statistics/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_statistics)]
+ * 词汇多样性 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_diversity/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_diversity)]
+ * 算子洞察(单OP) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visualization_op_insight/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_op_insight)]
+ * 算子效果(多OP) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_op_effect/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_op_effect)]
+* 数据处理:
+ * 科学文献 (例如 [arXiv](https://info.arxiv.org/help/bulk_data_s3.html)) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/process_sci_data/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/process_sci_data)]
+ * 编程代码 (例如 [TheStack](https://huggingface.co/datasets/bigcode/the-stack)) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/process_code_data/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/process_code_data)]
+ * 中文指令数据 (例如 [Alpaca-CoT](https://huggingface.co/datasets/QingyiSi/Alpaca-CoT)) [[ModelScope](https://modelscope.cn/studios/Data-Juicer/process_sft_zh_data/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/process_cft_zh_data)]
+* 工具池:
+ * 按语言分割数据集 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/tool_dataset_splitting_by_language/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/tool_dataset_splitting_by_language)]
+ * CommonCrawl 质量分类器 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/tool_quality_classifier/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/tool_quality_classifier)]
+ * 基于 [HELM](https://github.com/stanford-crfm/helm) 的自动评测 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/auto_evaluation_helm/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/auto_evaluation_helm)]
+ * 数据采样及混合 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_mixture/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_mixture)]
+* 数据处理回路 [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_process_loop/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_process_loop)]
+
+
## 前置条件
-* 推荐 Python>=3.7,<=3.10
+* 推荐 Python>=3.8,<=3.10
* gcc >= 5 (at least C++14 support)
## 安装
@@ -189,6 +224,25 @@ export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
```
+### 分布式数据处理
+
+现在基于RAY对多机分布式的数据处理进行了实现。
+对应Demo可以通过如下命令运行:
+
+```shell
+
+# 运行文字数据处理
+python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml
+
+# 运行视频数据处理
+python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml
+
+```
+
+ - 如果需要在多机上使用RAY运行多模态数据处理,需要确保各分布式节点可以访问对应的数据路径,将对应的数据路径挂载在文件共享系统(如NAS)中
+
+ - 用户也可以不使用RAY,拆分数据集后使用Slurm/DLC在集群上运行
+
### 数据分析
- 以配置文件路径为参数运行 `analyze_data.py` 或者 `dj-analyze` 命令行工具来分析数据集。
@@ -273,48 +327,14 @@ docker run -dit \ # 在后台启动容器
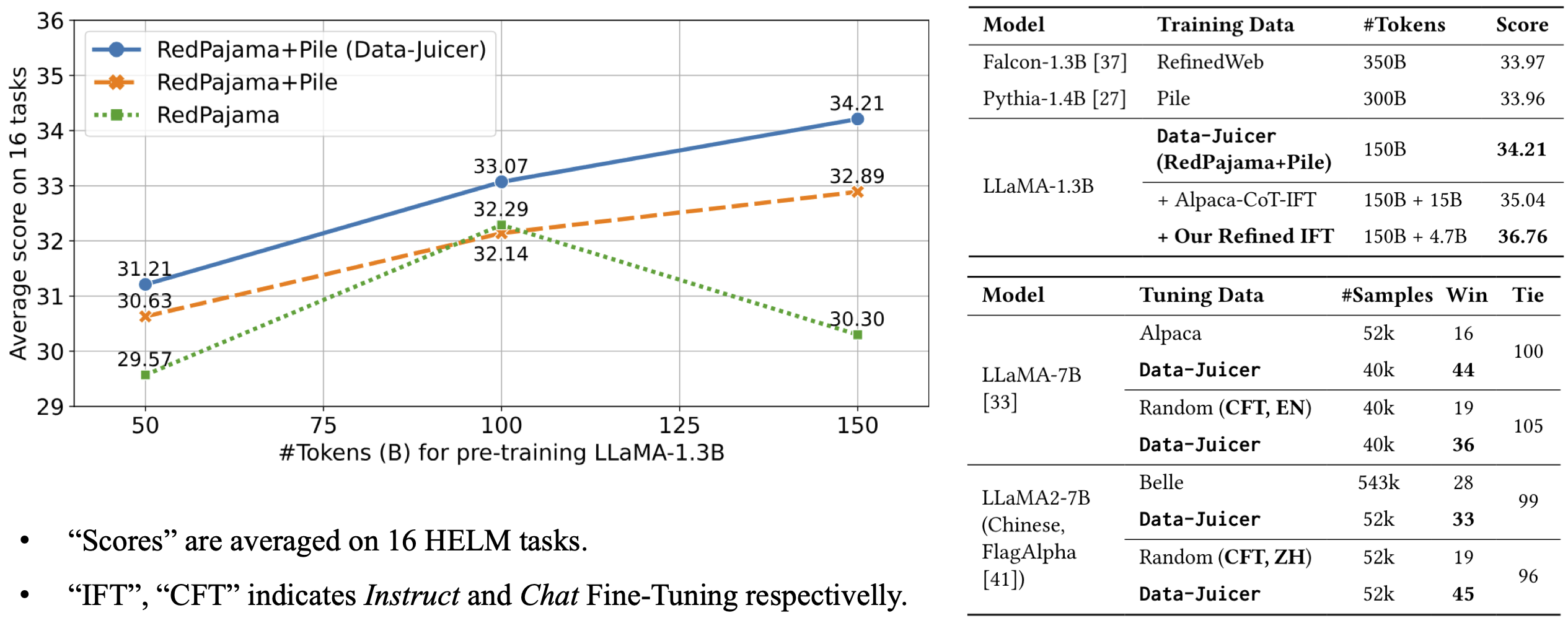
docker exec -it [ModelScope](https://modelscope.cn/datasets/Data-Juicer/alpaca-cot-en-refined-by-data-juicer/summary)
[HuggingFace](https://huggingface.co/datasets/datajuicer/alpaca-cot-en-refined-by-data-juicer) | [39 Subsets of Alpaca-CoT](alpaca_cot/README.md#refined-alpaca-cot-dataset-meta-info) | | Alpaca-Cot ZH | 21,197,246 | 9,873,214 | 46.58% | [alpaca-cot-zh-refine.yaml](alpaca_cot/alpaca-cot-zh-refine.yaml) | [Aliyun](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/LLM_data/our_refined_datasets/CFT/alpaca-cot-zh-refine_result.jsonl)
[ModelScope](https://modelscope.cn/datasets/Data-Juicer/alpaca-cot-zh-refined-by-data-juicer/summary)
[HuggingFace](https://huggingface.co/datasets/datajuicer/alpaca-cot-zh-refined-by-data-juicer) | [28 Subsets of Alpaca-CoT](alpaca_cot/README.md#refined-alpaca-cot-dataset-meta-info) | + +## Before and after refining for Multimodal Dataset + +| subset | #samples before | #samples after | keep ratio | config link | data link | source | +|---------------------------|:---------------------------:|:--------------:|:----------:|--------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------| +| LLaVA pretrain (LCS-558k) | 558,128 | 500,380 | 89.65% | [llava-pretrain-refine.yaml](llava-pretrain-refine.yaml) | [Aliyun](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/MM_data/our_refined_data/LLaVA-1.5/public/llava-pretrain-refine-result.json)
[ModelScope](https://modelscope.cn/datasets/Data-Juicer/llava-pretrain-refined-by-data-juicer/summary)
[HuggingFace](https://huggingface.co/datasets/datajuicer/llava-pretrain-refined-by-data-juicer) | [LLaVA-1.5](https://github.com/haotian-liu/LLaVA) | + +### Evaluation Results +- LLaVA pretrain (LCS-558k): models **pretrained with refined dataset** and fine-tuned with the original instruct dataset outperforms the baseline (LLaVA-1.5-13B) on 10 out of 12 benchmarks. + +| model | VQAv2 | GQA | VizWiz | SQA | TextVQA | POPE | MME | MM-Bench | MM-Bench-CN | SEED | LLaVA-Bench-Wild | MM-Vet | +|-------------------------------|-------| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | +| LLaVA-1.5-13B
(baseline) | **80.0** | 63.3 | 53.6 | 71.6 | **61.3** | 85.9 | 1531.3 | 67.7 | 63.6 | 61.6 | 72.5 | 36.1 | +| LLaVA-1.5-13B
(refined pretrain dataset) | 79.94 | **63.5** | **54.09** | **74.20** | 60.82 | **86.67** | **1565.53** | **68.2** | **63.9** | **61.8** | **75.9** | **37.4** | diff --git a/configs/data_juicer_recipes/README_ZH.md b/configs/data_juicer_recipes/README_ZH.md index af8d1d697..d7dd848d7 100644 --- a/configs/data_juicer_recipes/README_ZH.md +++ b/configs/data_juicer_recipes/README_ZH.md @@ -35,3 +35,17 @@ |-------------------|:------------------------:|:----------------------------------:|:---------:|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------| | Alpaca-Cot EN | 136,219,879 | 72,855,345 | 54.48% | [alpaca-cot-en-refine.yaml](alpaca_cot/alpaca-cot-en-refine.yaml) | [Aliyun](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/LLM_data/our_refined_datasets/CFT/alpaca-cot-en-refine_result.jsonl)
[ModelScope](https://modelscope.cn/datasets/Data-Juicer/alpaca-cot-en-refined-by-data-juicer/summary)
[HuggingFace](https://huggingface.co/datasets/datajuicer/alpaca-cot-en-refined-by-data-juicer) | [来自Alpaca-CoT的39个子集](alpaca_cot/README_ZH.md#完善的-alpaca-cot-数据集元信息) | | Alpaca-Cot ZH | 21,197,246 | 9,873,214 | 46.58% | [alpaca-cot-zh-refine.yaml](alpaca_cot/alpaca-cot-zh-refine.yaml) | [Aliyun](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/LLM_data/our_refined_datasets/CFT/alpaca-cot-zh-refine_result.jsonl)
[ModelScope](https://modelscope.cn/datasets/Data-Juicer/alpaca-cot-zh-refined-by-data-juicer/summary)
[HuggingFace](https://huggingface.co/datasets/datajuicer/alpaca-cot-zh-refined-by-data-juicer) | [来自Alpaca-CoT的28个子集](alpaca_cot/README_ZH.md#完善的-alpaca-cot-数据集元信息) | + +## 完善前后的多模态数据集 + +| 数据子集 | 完善前的样本数目 | 完善后的样本数目 | 样本保留率 | 配置链接 | 数据链接 | 来源 | +|---------------------------|:---------------------------:|:--------------:|:----------:|--------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------| +| LLaVA pretrain (LCS-558k) | 558,128 | 500,380 | 89.65% | [llava-pretrain-refine.yaml](llava-pretrain-refine.yaml) | [Aliyun](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/MM_data/our_refined_data/LLaVA-1.5/public/llava-pretrain-refine-result.json)
[ModelScope](https://modelscope.cn/datasets/Data-Juicer/llava-pretrain-refined-by-data-juicer/summary)
[HuggingFace](https://huggingface.co/datasets/datajuicer/llava-pretrain-refined-by-data-juicer) | [LLaVA-1.5](https://github.com/haotian-liu/LLaVA) | + +### 评测结果 +- LLaVA pretrain (LCS-558k): 使用**完善后的预训练数据集**预训练并使用原始的指令数据集微调后的模型在12个评测集上有10个超过了基线模型LLaVA-1.5-13B。 + +| 模型 | VQAv2 | GQA | VizWiz | SQA | TextVQA | POPE | MME | MM-Bench | MM-Bench-CN | SEED | LLaVA-Bench-Wild | MM-Vet | +|---------------------------------|-------| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | +| LLaVA-1.5-13B
(基线) | **80.0** | 63.3 | 53.6 | 71.6 | **61.3** | 85.9 | 1531.3 | 67.7 | 63.6 | 61.6 | 72.5 | 36.1 | +| LLaVA-1.5-13B
(完善后的预训练数据集) | 79.94 | **63.5** | **54.09** | **74.20** | 60.82 | **86.67** | **1565.53** | **68.2** | **63.9** | **61.8** | **75.9** | **37.4** | diff --git a/configs/data_juicer_recipes/llava-pretrain-refine.yaml b/configs/data_juicer_recipes/llava-pretrain-refine.yaml new file mode 100644 index 000000000..03a1bf23c --- /dev/null +++ b/configs/data_juicer_recipes/llava-pretrain-refine.yaml @@ -0,0 +1,60 @@ +project_name: 'llava-1.5-pretrain-dataset-refine-recipe' +dataset_path: 'blip_laion_cc_sbu_558k_dj_fmt_only_caption.jsonl' # converted LLaVA pretrain dataset in Data-Juicer format with only_keep_caption is True. See tools/multimodal/source_format_to_data_juicer_format/llava_to_dj.py +export_path: 'blip_laion_cc_sbu_558k_dj_fmt_only_caption_refined.jsonl' + +np: 42 # number of subprocess to process your dataset +text_keys: 'text' # the key name of field where the sample texts to be processed, e.g., `text`, `instruction`, `output`, ... + +# for multimodal data processing +image_key: 'images' # Key name of field to store the list of sample image paths. +image_special_token: '
" + "We welcome you to join us in promoting LLM data development and research!
", + 'demo':"You can experience the effect of the operators of Data-Juicer" + } + # image_src = covert_image_to_base64(project_img_path) + #
+ return f"""
+ :
export_path: './outputs/demo/demo-processed'
diff --git a/demos/process_on_ray/data/demo-dataset.jsonl b/demos/process_on_ray/data/demo-dataset.jsonl
new file mode 100644
index 000000000..a212d42f4
--- /dev/null
+++ b/demos/process_on_ray/data/demo-dataset.jsonl
@@ -0,0 +1,11 @@
+{"text":"What’s one thing you wish everyone knew about the brain?\nibble\nWhat’s one thing you wish everyone knew about the brain?\nThe place to have real conversations and understand each other better. Join a community or build and grow your own with groups, threads, and conversations.\nSee this content immediately after install\nGet The App\n"}
+{"text":"JavaScript must be enabled to use the system\n"}
+{"text":"中国企业又建成一座海外三峡工程!-科技-高清完整正版视频在线观看-优酷\n"}
+{"text":"Skip to content\nPOLIDEPORTES\nPeriodismo especialzado en deportes\nPrimary Menu\nPOLIDEPORTES\nPolideportes\n¿Quiénes somos?\nNoticia\nEntrevistas\nReportaje\nEquipos de Época\nOpinión\nEspeciales\nCopa Poli\nBuscar:\nSteven Villegas Ceballos patinador\nShare this...\nFacebook\nTwitter\nLinkedin\nWhatsapp\nEmail\nSeguir leyendo\nAnterior El imparable campeón Steven Villegas\nTe pueden interesar\nDeportes\nNoticia\nPiezas filatélicas llegan al Museo Olímpico Colombiano\nmarzo 17, 2023"}
+{"text":"Redirect Notice\nRedirect Notice\nThe previous page is sending you to http:\/\/sieuthikhoavantay.vn\/chi-tiet\/khoa-van-tay-dessmann-s710fp-duc.\nIf you do not want to visit that page, you can return to the previous page.\n"}
+{"text": "Do you need a cup of coffee?"}
+{"text": ".cv域名是因特网域名管理机构ICANN为佛得角共和国(The Republic of Cape Verde República de Cabo Verde)国家及地区分配的顶级域(ccTLD),作为其国家及地区因特网顶级域名。- 奇典网络\n专业的互联网服务提供商 登录 注册 控制中心 新闻中心 客户支持 交费方式 联系我们\n首页\n手机AI建站\n建站\n推广\n域名\n主机\n安全\n企业服务\n加盟\nICANN与CNNIC双认证顶级注册商 在中国,奇典网络是域名服务提供商\n.cv\n.cv域名是ICANN为佛得角共和国国家及地区分配的顶级域名,注册期限1年到10年不等。\n价格: 845 元\/1年\n注册要求: 无要求\n.cv\/.com.cv注册要求\n更多国别域名\n更多NewG域名\n相关资质\n1.什么是 .cv\/.com.cv域名?有什么优势?\n.cv域名是因特网域名管理机构ICANN为佛得角共和国(The Republic of Cape Verde República de Cabo Verde)国家及地区分配的顶级域(ccTLD),作为其国家及地区因特网顶级域名。\n2.cv\/.com.cv域名长度为多少?有什么注册规则?"}
+{"text": "Sur la plateforme MT4, plusieurs manières d'accéder à ces fonctionnalités sont conçues simultanément."}
+{"text": "欢迎来到阿里巴巴!"}
+{"text": "This paper proposed a novel method on LLM pretraining."}
+{"text":"世界十大网投平台_2022年卡塔尔世界杯官网\n177-8228-4819\n网站首页\n关于我们\n产品展示\n广告牌制作 广告灯箱制作 标识牌制作 楼宇亮化工程 门头店招制作 不锈钢金属字制作 LED发光字制作 形象墙Logo墙背景墙制作 LED显示屏制作 装饰装潢工程 铜字铜牌制作 户外广告 亚克力制品 各类广告设计 建筑工地广告制作 楼顶大字制作|楼顶发光字制作 霓虹灯制作 三维扣板|3D扣板|广告扣板 房地产广告制作设计 精神堡垒|立牌|指示牌制作 大型商业喷绘写真 展览展示 印刷服务\n合作伙伴\n新闻资讯\n公司新闻 行业新闻 制作知识 设计知识\n成功案例\n技术园地\n联系方式\n"}
diff --git a/demos/process_video_on_ray/configs/demo.yaml b/demos/process_video_on_ray/configs/demo.yaml
new file mode 100644
index 000000000..27236c08a
--- /dev/null
+++ b/demos/process_video_on_ray/configs/demo.yaml
@@ -0,0 +1,39 @@
+# Process config example for dataset
+
+# global parameters
+project_name: 'ray-demo'
+executor_type: 'ray'
+dataset_path: './demos/process_video_on_ray/data/demo-dataset.jsonl' # path to your dataset directory or file
+ray_address: 'auto' # change to your ray cluster address, e.g., ray://:
+export_path: './outputs/demo/demo-processed-ray-videos'
+
+# process schedule
+# a list of several process operators with their arguments
+
+# single node passed, multi node still under develop
+process:
+ # Filter ops
+ - video_duration_filter:
+ min_duration: 20
+ max_duration: 60
+ # Mapper ops
+ - video_split_by_duration_mapper: # Mapper to split video by duration.
+ split_duration: 10 # duration of each video split in seconds.
+ min_last_split_duration: 0 # the minimum allowable duration in seconds for the last video split. If the duration of the last split is less than this value, it will be discarded.
+ keep_original_sample: true
+ - video_resize_aspect_ratio_mapper:
+ min_ratio: 1
+ max_ratio: 1.1
+ strategy: increase
+ - video_split_by_key_frame_mapper: # Mapper to split video by key frame.
+ keep_original_sample: true # whether to keep the original sample. If it's set to False, there will be only cut sample in the final datasets and the original sample will be removed. It's True in default
+ - video_split_by_duration_mapper: # Mapper to split video by duration.
+ split_duration: 10 # duration of each video split in seconds.
+ min_last_split_duration: 0 # the minimum allowable duration in seconds for the last video split. If the duration of the last split is less than this value, it will be discarded.
+ keep_original_sample: true
+ - video_resolution_filter: # filter samples according to the resolution of videos in them
+ min_width: 1280 # the min resolution of horizontal resolution filter range (unit p)
+ max_width: 4096 # the max resolution of horizontal resolution filter range (unit p)
+ min_height: 480 # the min resolution of vertical resolution filter range (unit p)
+ max_height: 1080 # the max resolution of vertical resolution filter range (unit p)
+ any_or_all: any
diff --git a/demos/process_video_on_ray/data/Note.md b/demos/process_video_on_ray/data/Note.md
new file mode 100644
index 000000000..bf3dfece3
--- /dev/null
+++ b/demos/process_video_on_ray/data/Note.md
@@ -0,0 +1,7 @@
+# Note for dataset path
+
+The videos/images path here support both absolute path and relative path.
+Please use an address that can be accessed on all nodes (such as an address within a NAS file-sharing system).
+For relative paths, these should be relative to the directory where the dataset file is located (the dataset_path parameter in the config).
+ - if the dataset_path parameter is a directory, then it's relative to dataset_path
+ - if the dataset_path parameter is a file, then it's relative to data_path parameter's corresponding dirname
diff --git a/demos/process_video_on_ray/data/demo-dataset.jsonl b/demos/process_video_on_ray/data/demo-dataset.jsonl
new file mode 100644
index 000000000..1c9c006b0
--- /dev/null
+++ b/demos/process_video_on_ray/data/demo-dataset.jsonl
@@ -0,0 +1,3 @@
+{"videos": ["./videos/video1.mp4"], "text": "<__dj__video> 10s videos <|__dj__eoc|>'}"}
+{"videos": ["./videos/video2.mp4"], "text": "<__dj__video> 23s videos <|__dj__eoc|>'}"}
+{"videos": ["./videos/video3.mp4"], "text": "<__dj__video> 46s videos <|__dj__eoc|>'}"}
\ No newline at end of file
diff --git a/demos/process_video_on_ray/data/videos/video1.mp4 b/demos/process_video_on_ray/data/videos/video1.mp4
new file mode 100644
index 000000000..5b0cad49f
Binary files /dev/null and b/demos/process_video_on_ray/data/videos/video1.mp4 differ
diff --git a/demos/process_video_on_ray/data/videos/video2.mp4 b/demos/process_video_on_ray/data/videos/video2.mp4
new file mode 100644
index 000000000..28acb927f
Binary files /dev/null and b/demos/process_video_on_ray/data/videos/video2.mp4 differ
diff --git a/demos/process_video_on_ray/data/videos/video3.mp4 b/demos/process_video_on_ray/data/videos/video3.mp4
new file mode 100644
index 000000000..45db64a51
Binary files /dev/null and b/demos/process_video_on_ray/data/videos/video3.mp4 differ
diff --git a/docs/DJ_SORA.md b/docs/DJ_SORA.md
new file mode 100644
index 000000000..1dce43860
--- /dev/null
+++ b/docs/DJ_SORA.md
@@ -0,0 +1,106 @@
+English | [中文页面](DJ_SORA_ZH.md)
+
+---
+
+Data is the key to the unprecedented development of large multi-modal models such as SORA. How to obtain and process data efficiently and scientifically faces new challenges! DJ-SORA aims to create a series of large-scale, high-quality open source multi-modal data sets to assist the open source community in data understanding and model training.
+
+DJ-SORA is based on Data-Juicer (including hundreds of dedicated video, image, audio, text and other multi-modal data processing [operators](Operators_ZH.md) and tools) to form a series of systematic and reusable Multimodal "data recipes" for analyzing, cleaning, and generating large-scale, high-quality multimodal data.
+
+This project is being actively updated and maintained. We eagerly invite you to participate and jointly create a more open and higher-quality multi-modal data ecosystem to unleash the unlimited potential of large models!
+
+# Motivation
+- SORA only briefly mentions using DALLE-3 to generate captions and can handle varying durations, resolutions and aspect ratios.
+- High-quality large-scale fine-grained data helps to densify data points, aiding models to better learn the conditional mapping of "text -> spacetime token", and solve a series of existing challenges in text-to-video models:
+ - Smoothness of visual flow, with some generated videos exhibiting dropped frames and static states.
+ - Text comprehension and fine-grained detail, where the produced results have a low match with the given prompts.
+ - Generated content showing distortions and violations of physical laws, especially when entities are in motion.
+ - Short video content, mostly around ~10 seconds, with little to no significant changes in scenes or backdrops.
+
+# Roadmap
+## Overview
+* [Support high-performance loading and processing of video data](#Support high-performance loading and processing of video data)
+* [Basic Operators (video spatio-temporal dimension)](#Basic operator video spatio-temporal dimension)
+* [Advanced Operators (fine-grained modal matching and data generation)](#Advanced operators fine-grained modal matching and data generation)
+* [Advanced Operators (Video Content)](#Advanced Operator Video Content)
+* [DJ-SORA Data Recipes and Datasets](#DJ-SORA Data Recipes and Datasets)
+* [DJ-SORA Data Validation and Model Training](#DJ-SORA Data Validation and Model Training)
+
+
+## Support high-performance loading and processing of video data
+- [✅] Parallelize data loading and storing:
+ - [✅] lazy load with pyAV and ffmpeg
+ - [✅] Multi-modal data path signature
+- [✅] Parallelization operator processing:
+ - [✅] Support single machine multicore running
+ - [✅] GPU utilization
+ - [✅] Ray based multi-machine distributed running
+- [ ] [WIP] Distributed scheduling optimization (OP-aware, automated load balancing) --> Aliyun PAI-DLC
+- [ ] [WIP] Distributed storage optimization
+
+## Basic Operators (video spatio-temporal dimension)
+- Towards Data Quality
+ - [✅] video_resolution_filter (targeted resolution)
+ - [✅] video_aspect_ratio_filter (targeted aspect ratio)
+ - [✅] video_duration_filter (targeted) duration)
+ - [✅] video_motion_score_filter (video continuity dimension, calculating optical flow and removing statics and extreme dynamics)
+ - [✅] video_ocr_area_ratio_filter (remove samples with text areas that are too large)
+- Towards Data Diversity & Quantity
+ - [✅] video_resize_resolution_mapper (enhancement in resolution dimension)
+ - [✅] video_resize_aspect_ratio_mapper (enhancement in aspect ratio dimension)
+ - [✅] video_split_by_duration_mapper (enhancement in time dimension)
+ - [✅] video_split_by_key_frame_mapper (enhancement in time dimension with key information focus)
+ - [✅] video_split_by_scene_mapper (enhancement in time dimension with scene continuity focus)
+
+## Advanced Operators (fine-grained modal matching and data generation)
+- Towards Data Quality
+ - [✅] video_frames_text_similarity_filter (enhancement in the spatiotemporal consistency dimension, calculating the matching score of key/specified frames and text)
+- Towards Diversity & Quantity
+ - [✅] video_tagging_from_frames_mapper (with lightweight image-to-text models, spatial summary information from dense frames)
+ - [ ] [WIP] video_captioning_from_frames_mapper (heavier image-to-text models, generating more detailed spatial information from fewer frames)
+ - [✅] video_tagging_from_audio_mapper (introducing audio classification/category and other meta information)
+ - [✅] video_captioning_from_audio_mapper (incorporating voice/dialogue information; AudioCaption for environmental and global context)
+ - [✅] video_captioning_from_video_mapper (video-to-text model, generating spacetime information from continuous frames)
+ - [ ] [WIP] video_captioning_from_summarizer_mapper (combining the above sub-abilities, using pure text large models for denoising and summarizing different types of caption information)
+ - [ ] [WIP] video_interleaved_mapper (enhancement in ICL, temporal, and cross-modal dimensions), `interleaved_modes` include:
+ - text_image_interleaved (placing captions and frames of the same video in temporal order)
+ - text_audio_interleaved (placing ASR text and frames of the same video in temporal order)
+ - text_image_audio_interleaved (alternating stitching of the above two types)
+## Advanced Operators (Video Content)
+- [✅] video_deduplicator (comparing hash values to deduplicate at the file sample level)
+- [✅] video_aesthetic_filter (performing aesthetic scoring filters after frame decomposition)
+- [✅] Compatibility with existing ffmpeg video commands
+ - audio_ffmpeg_wrapped_mapper
+ - video_ffmpeg_wrapped_mapper
+- [WIP] Video content compliance and privacy protection operators (image, text, audio):
+ - [✅] Mosaic
+ - [ ] Copyright watermark
+ - [ ] Face blurring
+ - [ ] Violence and Adult Content
+- [ ] [TODO] (Beyond Interpolation) Enhancing data authenticity and density
+ - Collisions, lighting, gravity, 3D, scene and phase transitions, depth of field, etc.
+ - [ ] Filter-type operators: whether captions describe authenticity, relevance scoring/correctness of that description
+ - [ ] Mapper-type operators: enhance textual descriptions of physical phenomena in video data
+ - [ ] ...
+## DJ-SORA Data Recipes and Datasets
+- Support for unified loading and conversion of representative datasets (other-data <-> dj-data), facilitating DJ operator processing and dataset expansion.
+ - [✅] **Video-ChatGPT**: 100k video-instruction data: `{}`
+ - [✅] **Youku-mPLUG-CN**: 36TB video-caption data: `{}`
+ - [✅] **InternVid**: 234M data sample: `{}`
+ - [ ] VideoInstruct-100K, Panda70M, MSR-VTT, ......
+ - [ ] ModelScope's datasets integration
+- [ ] Large-scale high-quality DJ-SORA dataset
+ - [ ] [WIP] Continuous expansion of data sources: open-datasets, Youku, web, ...
+ - [ ] [WIP] (Data sandbox) Building and optimizing multimodal data recipes with DJ-video operators (which are also being continuously extended and improved).
+ - [ ] [WIP] Large-scale analysis and cleaning of high-quality multimodal datasets based on DJ recipes
+ - [ ] [WIP] Large-scale generation of high-quality multimodal datasets based on DJ recipes.
+ - ...
+
+## DJ-SORA Data Validation and Model Training
+ - [ ] [WIP] Exploring and refining multimodal data evaluation metrics and techniques, establishing benchmarks and insights.
+ - [ ] [WIP] Integration of SORA-like model training pipelines
+ - VideoDIT
+ - VQVAE
+ - ...
+ - [ ] [WIP] (Model-Data sandbox) With relatively small models and the DJ-SORA dataset, exploring low-cost, transferable, and instructive data-model co-design, configurations and checkpoints.
+ - [ ] Training SORA-like models with DJ-SORA data on larger scales and in more scenarios to improve model performance.
+ - ...
diff --git a/docs/DJ_SORA_ZH.md b/docs/DJ_SORA_ZH.md
new file mode 100644
index 000000000..4ccdd8866
--- /dev/null
+++ b/docs/DJ_SORA_ZH.md
@@ -0,0 +1,111 @@
+中文 | [English Page](DJ_SORA.md)
+
+---
+
+数据是SORA等前沿大模型的关键,如何高效科学地获取和处理数据面临新的挑战!DJ-SORA旨在创建一系列大规模高质量开源多模态数据集,助力开源社区数据理解和模型训练。
+
+DJ-SORA将基于Data-Juicer(包含上百个专用的视频、图像、音频、文本等多模态数据处理[算子](Operators_ZH.md)及工具),形成一系列系统化可复用的多模态“数据菜谱”,用于分析、清洗及生成大规模高质量多模态数据。
+
+本项目正在积极更新和维护中,我们热切地邀请您参与,共同打造一个更开放、更高质的多模态数据生态系统,激发大模型无限潜能!
+
+# 动机
+- SORA仅简略提及使用了DALLE-3来生成高质量caption,且模型输入数据有变化的时长、分辨率和宽高比。
+- 高质量大规模细粒度数据有助于稠密化数据点,帮助模型学好“文本 -> spacetime token”的条件映射,解决text-2-video模型的一系列现有挑战:
+ - 画面流畅性和一致性,部分生成的视频有丢帧及静止状态
+ - 文本理解能力和细粒度,生成出的结果和prompt匹配度较低
+ - 视频内容较短,大多只有~10s,且场景画面不会有大的改变
+ - 生成内容存在变形扭曲和物理规则违背情况,特别是在实体做出动作时
+
+# 路线图
+## 概览
+* [支持视频数据的高性能加载和处理](#支持视频数据的高性能加载和处理)
+* [基础算子(视频时空维度)](#基础算子视频时空维度)
+* [进阶算子(细粒度模态间匹配及生成)](#进阶算子细粒度模态间匹配及生成)
+* [进阶算子(视频内容)](#进阶算子视频内容)
+* [DJ-SORA数据菜谱及数据集](#DJ-SORA数据菜谱及数据集)
+* [DJ-SORA数据验证及模型训练](#DJ-SORA数据验证及模型训练)
+
+## 支持视频数据的高性能加载和处理
+- [✅] 并行化数据加载存储:
+ - [✅] lazy load with pyAV and ffmpeg
+ - [✅] 多模态数据路径签名
+- [✅] 并行化算子处理:
+ - [✅] 支持单机多核
+ - [✅] GPU调用
+ - [✅] Ray多机分布式
+- [ ] [WIP] 分布式调度优化(OP-aware、自动化负载均衡)--> Aliyun PAI-DLC
+- [ ] [WIP] 分布式存储优化
+
+## 基础算子(视频时空维度)
+- 面向数据质量
+ - [✅] video_resolution_filter (在分辨率维度进行过滤)
+ - [✅] video_aspect_ratio_filter (在宽高比维度进行过滤)
+ - [✅] video_duration_filter (在时间维度进行过滤)
+ - [✅] video_motion_score_filter(在视频连续性维度过滤,计算光流,去除静态和极端动态)
+ - [✅] video_ocr_area_ratio_filter (移除文本区域过大的样本)
+- 面向数据多样性及数量
+ - [✅] video_resize_resolution_mapper(在分辨率维度进行增强)
+ - [✅] video_resize_aspect_ratio_mapper(在宽高比维度进行增强)
+ - [✅] video_split_by_key_frame_mapper(基于关键帧进行切割)
+ - [✅] video_split_by_duration_mapper(在时间维度进行切割)
+ - [✅] video_split_by_scene_mapper (基于场景连续性进行切割)
+
+## 进阶算子(细粒度模态间匹配及生成)
+- 面向数据质量
+ - [✅] video_frames_text_similarity_filter(在时空一致性维度过滤,计算关键/指定帧 和文本的匹配分)
+- 面向数据多样性及数量
+ - [✅] video_tagging_from_frames_mapper (轻量图生文模型,密集帧生成空间 概要信息)
+ - [ ] [WIP] video_captioning_from_frames_mapper(更重的图生文模型,少量帧生 成更详细空间信息)
+ - [✅] video_tagging_from_audio_mapper (引入audio classification/category等meta信息)
+ - [✅] video_captioning_from_audio_mapper(引入人声/对话等信息; AudioCaption环境、场景等全局信息)
+ - [✅] video_captioning_from_video_mapper(视频生文模型,连续帧生成时序信息)
+ - [ ] [WIP] video_captioning_from_summarizer_mapper(基于上述子能力的组合,使用纯文本大模型对不同种caption信息去噪、摘要)
+ - [ ] [WIP] video_interleaved_mapper(在ICL、时间和跨模态维度增强),`interleaved_modes` include
+ - text_image_interleaved(按时序交叉放置同一视频的的caption和frames)
+ - text_audio_interleaved(按时序交叉放置同一视频的的ASR文本和frames)
+ - text_image_audio_interleaved(交替拼接上述两种)
+
+## 进阶算子(视频内容)
+- [✅] video_deduplicator (比较MD5哈希值在文件样本级别去重)
+- [✅] video_aesthetic_filter(拆帧后,进行美学度打分过滤)
+- [✅]兼容ffmpeg已有的video commands
+ - audio_ffmpeg_wrapped_mapper
+ - video_ffmpeg_wrapped_mapper
+- [WIP] 视频内容合规和隐私保护算子(图像、文字、音频):
+ - [✅] 马赛克
+ - [ ] 版权水印
+ - [ ] 人脸模糊
+ - [ ] 黄暴恐
+- [ ] [TODO] (Beyond Interpolation) 增强数据真实性和稠密性
+ - 碰撞、光影、重力、3D、场景切换(phase tranisition)、景深等
+ - [ ] Filter类算子: caption是否描述真实性,该描述的相关性得分/正确性得分
+ - [ ] Mapper类算子:增强video数据中对物理现象的文本描述
+ - [ ] ...
+
+
+
+## DJ-SORA数据菜谱及数据集
+- 支持代表性数据的统一加载和转换(other-data <-> dj-data),方便DJ算子处理及扩展数据集
+ - [✅] **Video-ChatGPT**: 100k video-instruction data:`{}`
+ - [✅] **Youku-mPLUG-CN**: 36TB video-caption data:`{}`
+ - [✅] **InternVid**: 234M data sample:`{}`
+ - [ ] VideoInstruct-100K, Panda70M, MSR-VTT, ......
+ - [ ] ModelScope数据集集成
+- [ ] 大规模高质量DJ-SORA数据集
+ - [ ] [WIP] 数据源持续扩充:open-datasets, youku, web, ...
+ - [ ] [WIP] (Data sandbox) 基于DJ-video算子构建和优化多模态数据菜谱 (算子同期持续完善)
+ - [ ] [WIP] 基于DJ菜谱规模化分析、清洗高质量多模态数据集
+ - [ ] [WIP] 基于DJ菜谱规模化生成高质量多模态数据集
+ - ...
+
+## DJ-SORA数据验证及模型训练
+ - [ ] [WIP] 探索及完善多模态数据的评估指标和评估技术,形成benchmark和insights
+ - [ ] [WIP] 类SORA模型训练pipeline集成
+ - VideoDIT
+ - VQVAE
+ - ...
+ - [ ] [WIP] (Model-Data sandbox) 在相对小的模型和DJ-SORA数据集上,探索形成低开销、可迁移、有指导性的data-model co-design、配置及检查点
+ - [ ] 更大规模、更多场景使用DJ-SORA数据训练类SORA模型,提高模型性能
+ - ...
+
+
diff --git a/docs/DeveloperGuide.md b/docs/DeveloperGuide.md
index a658b5e7c..bf248aa82 100644
--- a/docs/DeveloperGuide.md
+++ b/docs/DeveloperGuide.md
@@ -147,6 +147,52 @@ class StatsKeys(object):
# ... (same as above)
```
+ - In a mapper operator, to avoid process conflicts and data coverage, we offer an interface to make a saving path for produced extra datas. The format of the saving path is `{ORIGINAL_DATAPATH}/{OP_NAME}/{ORIGINAL_FILENAME}__dj_hash_#{HASH_VALUE}#.{EXT}`, where the `HASH_VALUE` is hashed from the init parameters of the operator, the related parameters in each sample, the process ID, and the timestamp. For convenience, we can call `self.remove_extra_parameters(locals())` at the beginning of the initiation to get the init parameters. At the same time, we can call `self.add_parameters` to add related parameters with the produced extra datas from each sample. Take the operator which enhances the images with diffusion models as example:
+ ```python
+ # ... (import some library)
+ OP_NAME = 'image_diffusion_mapper'
+ @OPERATORS.register_module(OP_NAME)
+ @LOADED_IMAGES.register_module(OP_NAME)
+ class ImageDiffusionMapper(Mapper):
+ def __init__(self,
+ # ... (OP parameters)
+ *args,
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self._init_parameters = self.remove_extra_parameters(locals())
+
+ def process(self, sample, rank=None):
+ # ... (some codes)
+ # captions[index] is the prompt for diffusion model
+ related_parameters = self.add_parameters(
+ self._init_parameters, caption=captions[index])
+ new_image_path = transfer_filename(
+ origin_image_path, OP_NAME, **related_parameters)
+ # ... (some codes)
+ ```
+ For the mapper to produce multi extra datas base on one origin data, we can add suffix at the saving path. Take the operator which splits videos according to their key frames as example:
+ ```python
+ # ... (import some library)
+ OP_NAME = 'video_split_by_key_frame_mapper'
+ @OPERATORS.register_module(OP_NAME)
+ @LOADED_VIDEOS.register_module(OP_NAME)
+ class VideoSplitByKeyFrameMapper(Mapper):
+ def __init__(self,
+ # ... (OP parameters)
+ *args,
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self._init_parameters = self.remove_extra_parameters(locals())
+
+ def process(self, sample, rank=None):
+ # ... (some codes)
+ split_video_path = transfer_filename(
+ original_video_path, OP_NAME, **self._init_parameters)
+ suffix = '_split-by-key-frame-' + str(count)
+ split_video_path = add_suffix_to_filename(split_video_path, suffix)
+ # ... (some codes)
+ ```
+
3. After implemention, add it to the OP dictionary in the `__init__.py` file in `data_juicer/ops/filter/` directory.
```python
@@ -172,8 +218,9 @@ process:
```python
import unittest
from data_juicer.ops.filter.text_length_filter import TextLengthFilter
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class TextLengthFilterTest(unittest.TestCase):
+class TextLengthFilterTest(DataJuicerTestCaseBase):
def test_func1(self):
pass
@@ -183,6 +230,9 @@ class TextLengthFilterTest(unittest.TestCase):
def test_func3(self):
pass
+
+if __name__ == '__main__':
+ unittest.main()
```
6. (Strongly Recommend) In order to facilitate the use of other users, we also need to update this new OP information to
diff --git a/docs/DeveloperGuide_ZH.md b/docs/DeveloperGuide_ZH.md
index f188aecbc..3c6bb2411 100644
--- a/docs/DeveloperGuide_ZH.md
+++ b/docs/DeveloperGuide_ZH.md
@@ -142,6 +142,52 @@ class StatsKeys(object):
# ... (same as above)
```
+ - 在mapper算子中,我们提供了产生额外数据的存储路径生成接口,避免出现进程冲突和数据覆盖的情况。生成的存储路径格式为`{ORIGINAL_DATAPATH}/{OP_NAME}/{ORIGINAL_FILENAME}__dj_hash_#{HASH_VALUE}#.{EXT}`,其中`HASH_VALUE`是算子初始化参数、每个样本中相关参数、进程ID和时间戳的哈希值。为了方便,可以在OP类初始化开头调用`self.remove_extra_parameters(locals())`获取算子初始化参数,同时可以调用`self.add_parameters`添加每个样本与生成额外数据相关的参数。例如,利用diffusion模型对图像进行增强的算子:
+ ```python
+ # ... (import some library)
+ OP_NAME = 'image_diffusion_mapper'
+ @OPERATORS.register_module(OP_NAME)
+ @LOADED_IMAGES.register_module(OP_NAME)
+ class ImageDiffusionMapper(Mapper):
+ def __init__(self,
+ # ... (OP parameters)
+ *args,
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self._init_parameters = self.remove_extra_parameters(locals())
+
+ def process(self, sample, rank=None):
+ # ... (some codes)
+ # captions[index] is the prompt for diffusion model
+ related_parameters = self.add_parameters(
+ self._init_parameters, caption=captions[index])
+ new_image_path = transfer_filename(
+ origin_image_path, OP_NAME, **related_parameters)
+ # ... (some codes)
+ ```
+ 针对一个数据源衍生出多个额外数据的情况,我们允许在生成的存储路径后面再加后缀。比如,根据关键帧将视频拆分成多个视频:
+ ```python
+ # ... (import some library)
+ OP_NAME = 'video_split_by_key_frame_mapper'
+ @OPERATORS.register_module(OP_NAME)
+ @LOADED_VIDEOS.register_module(OP_NAME)
+ class VideoSplitByKeyFrameMapper(Mapper):
+ def __init__(self,
+ # ... (OP parameters)
+ *args,
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self._init_parameters = self.remove_extra_parameters(locals())
+
+ def process(self, sample, rank=None):
+ # ... (some codes)
+ split_video_path = transfer_filename(
+ original_video_path, OP_NAME, **self._init_parameters)
+ suffix = '_split-by-key-frame-' + str(count)
+ split_video_path = add_suffix_to_filename(split_video_path, suffix)
+ # ... (some codes)
+ ```
+
3. 实现后,将其添加到 `data_juicer/ops/filter` 目录下 `__init__.py` 文件中的算子字典中:
```python
@@ -168,8 +214,10 @@ process:
```python
import unittest
from data_juicer.ops.filter.text_length_filter import TextLengthFilter
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
-class TextLengthFilterTest(unittest.TestCase):
+class TextLengthFilterTest(DataJuicerTestCaseBase):
def test_func1(self):
pass
@@ -179,6 +227,9 @@ class TextLengthFilterTest(unittest.TestCase):
def test_func3(self):
pass
+
+if __name__ == '__main__':
+ unittest.main()
```
6. (强烈推荐)为了方便其他用户使用,我们还需要将新增的算子信息更新到相应的文档中,具体包括如下文档:
diff --git a/docs/Operators.md b/docs/Operators.md
index 28fdb7306..9409449b3 100644
--- a/docs/Operators.md
+++ b/docs/Operators.md
@@ -2,6 +2,7 @@
Operators are a collection of basic processes that assist in data modification, cleaning, filtering, deduplication, etc. We support a wide range of data sources and file formats, and allow for flexible extension to custom datasets.
+This page offers a basic description of the operators (OPs) in Data-Juicer. Users can refer to the [API documentation](https://alibaba.github.io/data-juicer/) for the specific parameters of each operator. Users can refer to and run the unit tests for [examples of operator-wise usage](../tests/ops) as well as the effects of each operator when applied to built-in test data samples.
## Overview
@@ -10,9 +11,9 @@ The operators in Data-Juicer are categorized into 5 types.
| Type | Number | Description |
|-----------------------------------|:------:|-------------------------------------------------|
| [ Formatter ]( #formatter ) | 7 | Discovers, loads, and canonicalizes source data |
-| [ Mapper ]( #mapper ) | 26 | Edits and transforms samples |
-| [ Filter ]( #filter ) | 28 | Filters out low-quality samples |
-| [ Deduplicator ]( #deduplicator ) | 4 | Detects and removes duplicate samples |
+| [ Mapper ]( #mapper ) | 38 | Edits and transforms samples |
+| [ Filter ]( #filter ) | 36 | Filters out low-quality samples |
+| [ Deduplicator ]( #deduplicator ) | 5 | Detects and removes duplicate samples |
| [ Selector ]( #selector ) | 2 | Selects top samples based on ranking |
@@ -25,6 +26,7 @@ All the specific operators are listed below, each featured with several capabili
- Financial: closely related to financial sector
- Image: specific to images or multimodal
- Audio: specific to audios or multimodal
+ - Video: specific to videos or multimodal
- Multimodal: specific to multimodal
* Language Tags
- en: English
@@ -46,69 +48,88 @@ All the specific operators are listed below, each featured with several capabili
## Mapper
-| Operator | Domain | Lang | Description |
-|-----------------------------------------------------|--------------------|--------|----------------------------------------------------------------------------------------------------------------|
-| chinese_convert_mapper | General | zh | Converts Chinese between Traditional Chinese, Simplified Chinese and Japanese Kanji (by [opencc](https://github.com/BYVoid/OpenCC)) |
-| clean_copyright_mapper | Code | en, zh | Removes copyright notice at the beginning of code files (:warning: must contain the word *copyright*) |
-| clean_email_mapper | General | en, zh | Removes email information |
-| clean_html_mapper | General | en, zh | Removes HTML tags and returns plain text of all the nodes |
-| clean_ip_mapper | General | en, zh | Removes IP addresses |
-| clean_links_mapper | General, Code | en, zh | Removes links, such as those starting with http or ftp |
-| expand_macro_mapper | LaTeX | en, zh | Expands macros usually defined at the top of TeX documents |
-| fix_unicode_mapper | General | en, zh | Fixes broken Unicodes (by [ftfy](https://ftfy.readthedocs.io/)) |
-| generate_caption_mapper | Multimodal | - | generate samples whose captions are generated based on another model (such as blip2) and the figure within the original sample |
-| gpt4v_generate_mapper | Multimodal | - | generate samples whose texts are generated based on gpt-4-visison and the image |
+| Operator | Domain | Lang | Description |
+|-----------------------------------------------------|--------------------|--------|---------------------------------------------------------------------------------------------------------------|
+| audio_ffmpeg_wrapped_mapper | Audio | - | Simple wrapper to run a FFmpeg audio filter |
+| chinese_convert_mapper | General | zh | Converts Chinese between Traditional Chinese, Simplified Chinese and Japanese Kanji (by [opencc](https://github.com/BYVoid/OpenCC)) |
+| clean_copyright_mapper | Code | en, zh | Removes copyright notice at the beginning of code files (:warning: must contain the word *copyright*) |
+| clean_email_mapper | General | en, zh | Removes email information |
+| clean_html_mapper | General | en, zh | Removes HTML tags and returns plain text of all the nodes |
+| clean_ip_mapper | General | en, zh | Removes IP addresses |
+| clean_links_mapper | General, Code | en, zh | Removes links, such as those starting with http or ftp |
+| expand_macro_mapper | LaTeX | en, zh | Expands macros usually defined at the top of TeX documents |
+| fix_unicode_mapper | General | en, zh | Fixes broken Unicodes (by [ftfy](https://ftfy.readthedocs.io/)) |
| image_blur_mapper | Multimodal | - | Blur images |
+| image_captioning_from_gpt4v_mapper | Multimodal | - | generate samples whose texts are generated based on gpt-4-visison and the image |
+| image_captioning_mapper | Multimodal | - | generate samples whose captions are generated based on another model (such as blip2) and the figure within the original sample |
| image_diffusion_mapper | Multimodal | - | Generate and augment images by stable diffusion model |
-| nlpaug_en_mapper | General | en | Simply augments texts in English based on the `nlpaug` library |
-| nlpcda_zh_mapper | General | zh | Simply augments texts in Chinese based on the `nlpcda` library |
-| punctuation_normalization_mapper | General | en, zh | Normalizes various Unicode punctuations to their ASCII equivalents |
-| remove_bibliography_mapper | LaTeX | en, zh | Removes the bibliography of TeX documents |
-| remove_comments_mapper | LaTeX | en, zh | Removes the comments of TeX documents |
-| remove_header_mapper | LaTeX | en, zh | Removes the running headers of TeX documents, e.g., titles, chapter or section numbers/names |
-| remove_long_words_mapper | General | en, zh | Removes words with length outside the specified range |
+| nlpaug_en_mapper | General | en | Simply augments texts in English based on the `nlpaug` library |
+| nlpcda_zh_mapper | General | zh | Simply augments texts in Chinese based on the `nlpcda` library |
+| punctuation_normalization_mapper | General | en, zh | Normalizes various Unicode punctuations to their ASCII equivalents |
+| remove_bibliography_mapper | LaTeX | en, zh | Removes the bibliography of TeX documents |
+| remove_comments_mapper | LaTeX | en, zh | Removes the comments of TeX documents |
+| remove_header_mapper | LaTeX | en, zh | Removes the running headers of TeX documents, e.g., titles, chapter or section numbers/names |
+| remove_long_words_mapper | General | en, zh | Removes words with length outside the specified range |
| remove_non_chinese_character_mapper | General | en, zh | Remove non Chinese character in text samples. |
| remove_repeat_sentences_mapper | General | en, zh | Remove repeat sentences in text samples. |
-| remove_specific_chars_mapper | General | en, zh | Removes any user-specified characters or substrings |
+| remove_specific_chars_mapper | General | en, zh | Removes any user-specified characters or substrings |
| remove_table_text_mapper | General, Financial | en | Detects and removes possible table contents (:warning: relies on regular expression matching and thus fragile) |
-| remove_words_with_incorrect_
substrings_mapper | General | en, zh | Removes words containing specified substrings | -| replace_content_mapper | General | en, zh | Replace all content in the text that matches a specific regular expression pattern with a designated replacement string. | -| sentence_split_mapper | General | en | Splits and reorganizes sentences according to semantics | -| whitespace_normalization_mapper | General | en, zh | Normalizes various Unicode whitespaces to the normal ASCII space (U+0020) | +| remove_words_with_incorrect_
substrings_mapper | General | en, zh | Removes words containing specified substrings | +| replace_content_mapper | General | en, zh | Replace all content in the text that matches a specific regular expression pattern with a designated replacement string | +| sentence_split_mapper | General | en | Splits and reorganizes sentences according to semantics | +| video_captioning_from_audio_mapper | Multimodal | - | Caption a video according to its audio streams based on Qwen-Audio model | +| video_captioning_from_video_mapper | Multimodal | - | generate samples whose captions are generated based on another model (video-blip) and sampled video frame within the original sample | +| video_ffmpeg_wrapped_mapper | Video | - | Simple wrapper to run a FFmpeg video filter | +| video_resize_aspect_ratio_mapper | Video | - | Resize video aspect ratio to a specified range | +| video_resize_resolution_mapper | Video | - | Map videos to ones with given resolution range | +| video_split_by_duration_mapper | Multimodal | - | Mapper to split video by duration. | +| video_spit_by_key_frame_mapper | Multimodal | - | Mapper to split video by key frame. | +| video_split_by_scene_mapper | Multimodal | - | Split videos into scene clips | +| video_tagging_from_audio_mapper | Multimodal | - | Mapper to generate video tags from audio streams extracted from the video. | +| video_tagging_from_frames_mapper | Multimodal | - | Mapper to generate video tags from frames extracted from the video. | +| whitespace_normalization_mapper | General | en, zh | Normalizes various Unicode whitespaces to the normal ASCII space (U+0020) | ## Filter -| Operator | Domain | Lang | Description | -|--------------------------------|------------|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------| -| alphanumeric_filter | General | en, zh | Keeps samples with alphanumeric ratio within the specified range | -| audio_duration_filter | Audio | - | Keep data samples whose audios' durations are within a specified range | +| Operator | Domain | Lang | Description | +|--------------------------------|------------|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------| +| alphanumeric_filter | General | en, zh | Keeps samples with alphanumeric ratio within the specified range | +| audio_duration_filter | Audio | - | Keep data samples whose audios' durations are within a specified range | | audio_nmf_snr_filter | Audio | - | Keep data samples whose audios' Signal-to-Noise Ratios (SNRs, computed based on Non-Negative Matrix Factorization, NMF) are within a specified range. | -| audio_size_filter | Audio | - | Keep data samples whose audios' sizes are within a specified range | -| average_line_length_filter | Code | en, zh | Keeps samples with average line length within the specified range | -| character_repetition_filter | General | en, zh | Keeps samples with char-level n-gram repetition ratio within the specified range | -| face_area_filter | Image | - | Keeps samples containing images with face area ratios within the specified range | -| flagged_words_filter | General | en, zh | Keeps samples with flagged-word ratio below the specified threshold | -| image_aspect_ratio_filter | Image | - | Keeps samples containing images with aspect ratios within the specified range | -| image_shape_filter | Image | - | Keeps samples containing images with widths and heights within the specified range | -| image_size_filter | Image | - | Keeps samples containing images whose size in bytes are within the specified range | -| image_text_matching_filter | Multimodal | - | Keeps samples with image-text classification matching score within the specified range based on a BLIP model | -| image_text_similarity_filter | Multimodal | - | Keeps samples with image-text feature cosine similarity within the specified range based on a CLIP model | -| language_id_score_filter | General | en, zh | Keeps samples of the specified language, judged by a predicted confidence score | -| maximum_line_length_filter | Code | en, zh | Keeps samples with maximum line length within the specified range | -| perplexity_filter | General | en, zh | Keeps samples with perplexity score below the specified threshold | -| phrase_grounding_recall_filter | Multimodal | - | Keeps samples whose locating recalls of phrases extracted from text in the images are within a specified range | -| special_characters_filter | General | en, zh | Keeps samples with special-char ratio within the specified range | -| specified_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified targets | -| specified_numeric_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified range (for numeric types) | -| stopwords_filter | General | en, zh | Keeps samples with stopword ratio above the specified threshold | -| suffix_filter | General | en, zh | Keeps samples with specified suffixes | -| text_action_filter | General | en, zh | Keeps samples containing action verbs in their texts | -| text_entity_dependency_filter | General | en, zh | Keeps samples containing entity nouns related to other tokens in the dependency tree of the texts | -| text_length_filter | General | en, zh | Keeps samples with total text length within the specified range | -| token_num_filter | General | en, zh | Keeps samples with token count within the specified range | -| word_num_filter | General | en, zh | Keeps samples with word count within the specified range | -| word_repetition_filter | General | en, zh | Keeps samples with word-level n-gram repetition ratio within the specified range | +| audio_size_filter | Audio | - | Keep data samples whose audios' sizes are within a specified range | +| average_line_length_filter | Code | en, zh | Keeps samples with average line length within the specified range | +| character_repetition_filter | General | en, zh | Keeps samples with char-level n-gram repetition ratio within the specified range | +| face_area_filter | Image | - | Keeps samples containing images with face area ratios within the specified range | +| flagged_words_filter | General | en, zh | Keeps samples with flagged-word ratio below the specified threshold | +| image_aspect_ratio_filter | Image | - | Keeps samples containing images with aspect ratios within the specified range | +| image_shape_filter | Image | - | Keeps samples containing images with widths and heights within the specified range | +| image_size_filter | Image | - | Keeps samples containing images whose size in bytes are within the specified range | +| image_aesthetics_filter | Image | - | Keeps samples containing images whose aesthetics scores are within the specified range | +| image_text_matching_filter | Multimodal | - | Keeps samples with image-text classification matching score within the specified range based on a BLIP model | +| image_text_similarity_filter | Multimodal | - | Keeps samples with image-text feature cosine similarity within the specified range based on a CLIP model | +| language_id_score_filter | General | en, zh | Keeps samples of the specified language, judged by a predicted confidence score | +| maximum_line_length_filter | Code | en, zh | Keeps samples with maximum line length within the specified range | +| perplexity_filter | General | en, zh | Keeps samples with perplexity score below the specified threshold | +| phrase_grounding_recall_filter | Multimodal | - | Keeps samples whose locating recalls of phrases extracted from text in the images are within a specified range | +| special_characters_filter | General | en, zh | Keeps samples with special-char ratio within the specified range | +| specified_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified targets | +| specified_numeric_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified range (for numeric types) | +| stopwords_filter | General | en, zh | Keeps samples with stopword ratio above the specified threshold | +| suffix_filter | General | en, zh | Keeps samples with specified suffixes | +| text_action_filter | General | en, zh | Keeps samples containing action verbs in their texts | +| text_entity_dependency_filter | General | en, zh | Keeps samples containing entity nouns related to other tokens in the dependency tree of the texts | +| text_length_filter | General | en, zh | Keeps samples with total text length within the specified range | +| token_num_filter | General | en, zh | Keeps samples with token count within the specified range | +| video_aspect_ratio_filter | Video | - | Keeps samples containing videos with aspect ratios within the specified range | +| video_duration_filter | Video | - | Keep data samples whose videos' durations are within a specified range | +| video_aesthetics_filter | Video | - | Keeps samples whose specified frames have aesthetics scores within the specified range | +| video_frames_text_similarity_filter | Multimodal | - | Keep data samples whose similarities between sampled video frame images and text are within a specific range | +| video_motion_score_filter | Video | - | Keep samples with video motion scores within a specific range | +| video_ocr_area_ratio_filter | Video | - | Keep data samples whose detected text area ratios for specified frames in the video are within a specified range | +| video_resolution_filter | Video | - | Keeps samples containing videos with horizontal and vertical resolutions within the specified range | +| word_num_filter | General | en, zh | Keeps samples with word count within the specified range | +| word_repetition_filter | General | en, zh | Keeps samples with word-level n-gram repetition ratio within the specified range | ## Deduplicator @@ -119,6 +140,7 @@ All the specific operators are listed below, each featured with several capabili | document_minhash_deduplicator | General | en, zh | Deduplicates samples at document-level using MinHashLSH | | document_simhash_deduplicator | General | en, zh | Deduplicates samples at document-level using SimHash | | image_deduplicator | Image | - | Deduplicates samples at document-level using exact matching of images between documents | +| video_deduplicator | Video | - | Deduplicates samples at document-level using exact matching of videos between documents | ## Selector diff --git a/docs/Operators_ZH.md b/docs/Operators_ZH.md index f3df33d89..4517c614c 100644 --- a/docs/Operators_ZH.md +++ b/docs/Operators_ZH.md @@ -2,6 +2,8 @@ 算子 (Operator) 是协助数据修改、清理、过滤、去重等基本流程的集合。我们支持广泛的数据来源和文件格式,并支持对自定义数据集的灵活扩展。 +这个页面提供了OP的基本描述,用户可以参考[API文档](https://alibaba.github.io/data-juicer/)更细致了解每个OP的具体参数,并且可以查看、运行单元测试,来体验[各OP的用法示例](../tests/ops)以及每个OP作用于内置测试数据样本时的效果。 + ## 概览 Data-Juicer 中的算子分为以下 5 种类型。 @@ -9,9 +11,9 @@ Data-Juicer 中的算子分为以下 5 种类型。 | 类型 | 数量 | 描述 | |------------------------------------|:--:|---------------| | [ Formatter ]( #formatter ) | 7 | 发现、加载、规范化原始数据 | -| [ Mapper ]( #mapper ) | 26 | 对数据样本进行编辑和转换 | -| [ Filter ]( #filter ) | 28 | 过滤低质量样本 | -| [ Deduplicator ]( #deduplicator ) | 4 | 识别、删除重复样本 | +| [ Mapper ]( #mapper ) | 38 | 对数据样本进行编辑和转换 | +| [ Filter ]( #filter ) | 36 | 过滤低质量样本 | +| [ Deduplicator ]( #deduplicator ) | 5 | 识别、删除重复样本 | | [ Selector ]( #selector ) | 2 | 基于排序选取高质量样本 | 下面列出所有具体算子,每种算子都通过多个标签来注明其主要功能。 @@ -23,6 +25,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 - Financial: 与金融领域相关 - Image: 专用于图像或多模态 - Audio: 专用于音频或多模态 + - Video: 专用于视频或多模态 - Multimodal: 专用于多模态 * Language 标签 @@ -46,6 +49,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 | 算子 | 场景 | 语言 | 描述 | |-----------------------------------------------------|-----------------------|-----------|--------------------------------------------------------| +| audio_ffmpeg_wrapped_mapper | Audio | - | 运行 FFmpeg 语音过滤器的简单封装 | | chinese_convert_mapper | General | zh | 用于在繁体中文、简体中文和日文汉字之间进行转换(借助 [opencc](https://github.com/BYVoid/OpenCC)) | | clean_copyright_mapper | Code | en, zh | 删除代码文件开头的版权声明 (:warning: 必须包含单词 *copyright*) | | clean_email_mapper | General | en, zh | 删除邮箱信息 | @@ -54,9 +58,9 @@ Data-Juicer 中的算子分为以下 5 种类型。 | clean_links_mapper | General, Code | en, zh | 删除链接,例如以 http 或 ftp 开头的 | | expand_macro_mapper | LaTeX | en, zh | 扩展通常在 TeX 文档顶部定义的宏 | | fix_unicode_mapper | General | en, zh | 修复损坏的 Unicode(借助 [ftfy](https://ftfy.readthedocs.io/)) | -| generate_caption_mapper | Multimodal | - | 生成样本,其标题是根据另一个辅助模型(例如 blip2)和原始样本中的图形生成的。 | -| gpt4v_generate_mapper | Multimodal | - | 基于gpt-4-vision和图像生成文本 | -| image_blur_mapper | Multimodal | - | 对图像进行模糊处理 | +| image_blur_mapper | Multimodal | - | 对图像进行模糊处理 | +| image_captioning_from_gpt4v_mapper | Multimodal | - | 基于gpt-4-vision和图像生成文本 | +| image_captioning_mapper | Multimodal | - | 生成样本,其标题是根据另一个辅助模型(例如 blip2)和原始样本中的图形生成的。 | | image_diffusion_mapper | Multimodal | - | 用stable diffusion生成图像,对图像进行增强 | | nlpaug_en_mapper | General | en | 使用`nlpaug`库对英语文本进行简单增强 | | nlpcda_zh_mapper | General | zh | 使用`nlpcda`库对中文文本进行简单增强 | @@ -70,8 +74,18 @@ Data-Juicer 中的算子分为以下 5 种类型。 | remove_specific_chars_mapper | General | en, zh | 删除任何用户指定的字符或子字符串 | | remove_table_text_mapper | General, Financial | en | 检测并删除可能的表格内容(:warning: 依赖正则表达式匹配,因此很脆弱) | | remove_words_with_incorrect_
substrings_mapper | General | en, zh | 删除包含指定子字符串的单词 | -| replace_content_mapper | General | en, zh | 使用一个指定的替换字符串替换文本中满足特定正则表达式模版的所有内容 | +| replace_content_mapper | General | en, zh | 使用一个指定的替换字符串替换文本中满足特定正则表达式模版的所有内容 | | sentence_split_mapper | General | en | 根据语义拆分和重组句子 | +| video_captioning_from_audio_mapper | Multimodal | - | 基于 Qwen-Audio 模型根据视频的音频流为视频生成新的标题描述 | +| video_captioning_from_video_mapper | Multimodal | - | 生成样本,其标题是根据另一个辅助模型(video-blip)和原始样本中的视频中指定帧的图像。 | +| video_ffmpeg_wrapped_mapper | Video | - | 运行 FFmpeg 视频过滤器的简单封装 | +| video_resize_aspect_ratio_mapper | Video | - | 将视频的宽高比调整到指定范围内 | +| video_resize_resolution_mapper | Video | - | 将视频映射到给定的分辨率区间 | +| video_split_by_duration_mapper | Multimodal | - | 根据时长将视频切分为多个片段 | +| video_split_by_key_frame_mapper | Multimodal | - | 根据关键帧切分视频 | +| video_split_by_scene_mapper | Multimodal | - | 将视频切分为场景片段 | +| video_tagging_from_audio_mapper | Multimodal | - | 从视频提取的音频中生成视频标签 | +| video_tagging_from_frames_mapper | Multimodal | - | 从视频提取的帧中生成视频标签 | | whitespace_normalization_mapper | General | en, zh | 将各种 Unicode 空白标准化为常规 ASCII 空格 (U+0020) | ## Filter @@ -80,7 +94,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 |--------------------------------|------------|--------|---------------------------------------------| | alphanumeric_filter | General | en, zh | 保留字母数字比例在指定范围内的样本 | | audio_duration_filter | Audio | - | 保留样本中包含的音频的时长在指定范围内的样本 | -| audio_nmf_snr_filter | Audio | - | 保留样本中包含的音频信噪比SNR(基于非负矩阵分解方法NMF计算)在指定范围内的样本. | +| audio_nmf_snr_filter | Audio | - | 保留样本中包含的音频信噪比SNR(基于非负矩阵分解方法NMF计算)在指定范围内的样本 | | audio_size_filter | Audio | - | 保留样本中包含的音频的大小(bytes)在指定范围内的样本 | | average_line_length_filter | Code | en, zh | 保留平均行长度在指定范围内的样本 | | character_repetition_filter | General | en, zh | 保留 char-level n-gram 重复比率在指定范围内的样本 | @@ -89,6 +103,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 | image_aspect_ratio_filter | Image | - | 保留样本中包含的图片的宽高比在指定范围内的样本 | | image_shape_filter | Image | - | 保留样本中包含的图片的形状(即宽和高)在指定范围内的样本 | | image_size_filter | Image | - | 保留样本中包含的图片的大小(bytes)在指定范围内的样本 | +| image_aesthetics_filter | Image | - | 保留包含美学分数在指定范围内的图像的样本 | | image_text_matching_filter | Multimodal | - | 保留图像-文本的分类匹配分(基于BLIP模型)在指定范围内的样本 | | image_text_similarity_filter | Multimodal | - | 保留图像-文本的特征余弦相似度(基于CLIP模型)在指定范围内的样本 | | language_id_score_filter | General | en, zh | 保留特定语言的样本,通过预测的置信度得分来判断 | @@ -104,6 +119,13 @@ Data-Juicer 中的算子分为以下 5 种类型。 | text_entity_dependency_filter | General | en, zh | 保留文本部分的依存树中具有非独立实体的样本 | | text_length_filter | General | en, zh | 保留总文本长度在指定范围内的样本 | | token_num_filter | General | en, zh | 保留token数在指定范围内的样本 | +| video_aspect_ratio_filter | Video | - | 保留样本中包含的视频的宽高比在指定范围内的样本 | +| video_duration_filter | Video | - | 保留样本中包含的视频的时长在指定范围内的样本 | +| video_aesthetics_filter | Video | - | 保留指定帧的美学分数在指定范围内的样本| +| video_frames_text_similarity_filter | Multimodal | - | 保留视频中指定帧的图像-文本的特征余弦相似度(基于CLIP模型)在指定范围内的样本 | +| video_motion_score_filter | Video | - | 保留样本中包含的视频的运动份(基于稠密光流)在指定范围内的样本 | +| video_ocr_area_ratio_filter | Video | - | 保留样本中包含的视频的特定帧中检测出的文本的面积占比在指定范围内的样本 | +| video_resolution_filter | Video | - | 保留样本中包含的视频的分辨率(包括横向分辨率和纵向分辨率)在指定范围内的样本 | | word_num_filter | General | en, zh | 保留字数在指定范围内的样本 | | word_repetition_filter | General | en, zh | 保留 word-level n-gram 重复比率在指定范围内的样本 | @@ -115,6 +137,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 | document_minhash_deduplicator | General | en, zh | 使用 MinHashLSH 在文档级别对样本去重 | | document_simhash_deduplicator | General | en, zh | 使用 SimHash 在文档级别对样本去重 | | image_deduplicator | Image | - | 使用文档之间图像的精确匹配在文档级别删除重复样本 | +| video_deduplicator | Video | - | 使用文档之间视频的精确匹配在文档级别删除重复样本 | ## Selector diff --git a/environments/dist_requires.txt b/environments/dist_requires.txt index e02756318..0edc5aa35 100644 --- a/environments/dist_requires.txt +++ b/environments/dist_requires.txt @@ -1 +1 @@ -ray +ray==2.9.2 diff --git a/environments/minimal_requires.txt b/environments/minimal_requires.txt index 31ef270e8..d7696c75b 100644 --- a/environments/minimal_requires.txt +++ b/environments/minimal_requires.txt @@ -1,7 +1,8 @@ -fsspec==2023.3.0 +fsspec==2023.5.0 pyarrow<=12.0.0 pandas==2.0.0 datasets==2.11.0 +av soundfile librosa loguru diff --git a/environments/science_requires.txt b/environments/science_requires.txt index 5116c8026..4421aad0d 100644 --- a/environments/science_requires.txt +++ b/environments/science_requires.txt @@ -1,3 +1,4 @@ +easyocr fasttext-wheel kenlm sentencepiece @@ -8,10 +9,18 @@ selectolax nlpaug nlpcda nltk -transformers +transformers>=4.37 +transformers_stream_generator +einops +accelerate +tiktoken opencc==1.1.6 imagededup torch +torchaudio dlib spacy-pkuseg==0.0.32 diffusers +simple-aesthetics-predictor +scenedetect[opencv] +ffmpeg-python diff --git a/scripts/README.md b/scripts/README.md new file mode 100644 index 000000000..e20de6fab --- /dev/null +++ b/scripts/README.md @@ -0,0 +1,14 @@ +# Scripts for Running on Multi Nodes + + +#### Running Using DLC(Deep Learing Containers) + +Internally we use [DLC](https://www.alibabacloud.com/help/zh/pai/user-guide/container-training/) from [PAI](https://www.alibabacloud.com/zh/product/machine-learning) to process data on multiple nodes. + +The scripts to run are in ./dlc folder. + +#### Running Using Slurm + + - [ ] We will provide scripts to support running on slurm. + +You can also manually partition the data according to specific circumstances and then use Slurm to run it on multiple machines by yourself. \ No newline at end of file diff --git a/scripts/dlc/partition_data_dlc.py b/scripts/dlc/partition_data_dlc.py new file mode 100644 index 000000000..b0f5bbbfc --- /dev/null +++ b/scripts/dlc/partition_data_dlc.py @@ -0,0 +1,49 @@ +import argparse +import json +import os +from collections import defaultdict +from typing import List + + +def partition_data(json_file_path: str, hostnames: List[str]): + with open(json_file_path, 'r') as f: + data = [json.loads(line) for line in f] + video_to_entries_map = defaultdict(list) + for entry in data: + video_path = entry['videos'][0] + video_to_entries_map[video_path].append(entry) + nodes_data = defaultdict(list) + nodes_video_size = {k: 0 for k in hostnames} + + # distribute videos to nodes based on the total size of videos + video_sizes = { + video: os.path.getsize(video) + for video in video_to_entries_map.keys() + } + + sorted_videos = sorted(video_sizes, key=video_sizes.get, reverse=True) + for video in sorted_videos: + min_node = min(nodes_video_size, key=nodes_video_size.get) + nodes_data[min_node].extend(video_to_entries_map[video]) + nodes_video_size[min_node] += video_sizes[video] + + for hostname in hostnames: + host_file_path = f"{json_file_path.rsplit('.', 1)[0]}_{hostname}.json" + with open(host_file_path, 'w') as f: + for entry in nodes_data[hostname]: + f.write(json.dumps(entry) + '\n') + + +# Usage +if __name__ == '__main__': + parser = argparse.ArgumentParser( + description='Partition data across hostnames.') + + parser.add_argument('file_path', + type=str, + help='Path of the file to distribute.') + parser.add_argument('hostnames', nargs='+', help='The list of hostnames') + + args = parser.parse_args() + + partition_data(args.file_path, args.hostnames) diff --git a/scripts/dlc/run_on_dlc.sh b/scripts/dlc/run_on_dlc.sh new file mode 100644 index 000000000..8ed356e99 --- /dev/null +++ b/scripts/dlc/run_on_dlc.sh @@ -0,0 +1,40 @@ +#!/bin/bash + +# paremeters +datajuicer_path= # path to data-juicer +config_path= # path to config file + +# hostname +hostname=$(hostname) + +# into datajuicer_path +cd "$datajuicer_path" || { echo "Could not change directory to $datajuicer_path"; exit 1; } + +# copy and generate new config file for current host + +config_basename=$(basename "$config_path") +config_dirname=$(dirname "$config_path") +config_extension="${config_basename##*.}" +config_basename="${config_basename%.*}" + +new_config_file="${config_dirname}/${config_basename}_$hostname.$config_extension" +cp "$config_path" "$new_config_file" || { echo "Could not copy config file"; exit 1; } + +echo "$new_config_file" + +if [[ "$OSTYPE" == "darwin"* ]]; then + SED_I_SUFFIX=".bak" +else + SED_I_SUFFIX="" +fi + +if grep -q "dataset_path: .*\.json" "$new_config_file"; then + # .json data_path + sed -i$SED_I_SUFFIX "s|\(dataset_path: \)\(.*\)\(/[^/]*\)\(.json\)|\1\2\3_$hostname\4|" "$new_config_file" +else + # dir dataset_path + sed -i$SED_I_SUFFIX "s|\(dataset_path: '\)\(.*\)'\(.*\)|\1\2_$hostname'\3|" "$new_config_file" +fi + +# run to process data +python tools/process_data.py --config "$new_config_file" diff --git a/tests/config/test_config_funcs.py b/tests/config/test_config_funcs.py index 9e66e6b66..a2748ed7f 100644 --- a/tests/config/test_config_funcs.py +++ b/tests/config/test_config_funcs.py @@ -7,12 +7,13 @@ from data_juicer.config import init_configs from data_juicer.ops import load_ops +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase test_yaml_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'demo_4_test.yaml') -class ConfigTest(unittest.TestCase): +class ConfigTest(DataJuicerTestCaseBase): def test_help_info(self): out = StringIO() @@ -35,12 +36,13 @@ def test_yaml_cfg_file(self): self.assertIsInstance(cfg, Namespace) self.assertEqual(cfg.project_name, 'test_demo') self.assertDictEqual( - cfg.process[0], - {'whitespace_normalization_mapper': { - 'text_key': 'text', - 'image_key': 'images', - 'audio_key': 'audios', - }}, 'nested dict load fail, for nonparametric op') + cfg.process[0], { + 'whitespace_normalization_mapper': { + 'text_key': 'text', + 'image_key': 'images', + 'audio_key': 'audios', + } + }, 'nested dict load fail, for nonparametric op') self.assertDictEqual( cfg.process[1], { 'language_id_score_filter': { diff --git a/tests/format/data/structured/demo-dataset.jsonl b/tests/format/data/structured/demo-dataset.jsonl index 77a0a1d88..116bf29e8 100644 --- a/tests/format/data/structured/demo-dataset.jsonl +++ b/tests/format/data/structured/demo-dataset.jsonl @@ -3,4 +3,4 @@ {"text": "Today is Sunday and it's a happy day!", "meta": {"src": "Arxiv", "date": "2023-04-27", "version": "1.0"}} {"text": "Do you need a cup of coffee?", "meta": {"src": "code", "author": "xxx"}} {"text": "Today is Sunday and it's a happy day!", "meta": {"src": "Arxiv", "date": "2023-04-27", "version": "1.0"}} -{"text": "Do you need a cup of coffee?", "meta": {"src": "code", "author": "xxx"}} \ No newline at end of file +{"text": "Do you need a cup of coffee?", "meta": {"src": "code", "author": "xxx"}} diff --git a/tests/format/test_csv_formatter.py b/tests/format/test_csv_formatter.py index 9db1ad343..591ccd61a 100644 --- a/tests/format/test_csv_formatter.py +++ b/tests/format/test_csv_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.csv_formatter import CsvFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CsvFormatterTest(unittest.TestCase): +class CsvFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), diff --git a/tests/format/test_mixture_formatter.py b/tests/format/test_mixture_formatter.py index fc16dcbe1..a4d339695 100644 --- a/tests/format/test_mixture_formatter.py +++ b/tests/format/test_mixture_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.mixture_formatter import MixtureFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class MixtureFormatterTest(unittest.TestCase): +class MixtureFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), @@ -33,7 +34,8 @@ def test_sample_number(self): def test_sample_number_weight(self): max_samples = 2 - formatter = MixtureFormatter('0.5 ' + self._file, max_samples=max_samples) + formatter = MixtureFormatter('0.5 ' + self._file, + max_samples=max_samples) ds = formatter.load_dataset() self.assertEqual(len(ds), max_samples) self.assertEqual(list(ds.features.keys()), ['text', 'meta']) @@ -45,13 +47,6 @@ def test_multi_datasets_without_weight(self): self.assertEqual(len(ds), 12) self.assertEqual(list(ds.features.keys()), ['text', 'meta']) - def test_multi_datasets_with_weight(self): - data_path = self._file + ' ' + self._file2 - formatter = MixtureFormatter(data_path) - ds = formatter.load_dataset() - self.assertEqual(len(ds), 12) - self.assertEqual(list(ds.features.keys()), ['text', 'meta']) - def test_multi_datasets_with_one_weight(self): data_path = '0.5 ' + self._file + ' ' + self._file2 formatter = MixtureFormatter(data_path) @@ -74,5 +69,6 @@ def test_multi_datasets_with_sample(self): self.assertEqual(len(ds), max_samples) self.assertEqual(list(ds.features.keys()), ['text', 'meta']) + if __name__ == '__main__': unittest.main() diff --git a/tests/format/test_parquet_formatter.py b/tests/format/test_parquet_formatter.py index 107ea870c..6df093368 100644 --- a/tests/format/test_parquet_formatter.py +++ b/tests/format/test_parquet_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.parquet_formatter import ParquetFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CsvFormatterTest(unittest.TestCase): +class CsvFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), diff --git a/tests/format/test_tsv_formatter.py b/tests/format/test_tsv_formatter.py index cde6bed85..46f1fad4d 100644 --- a/tests/format/test_tsv_formatter.py +++ b/tests/format/test_tsv_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.tsv_formatter import TsvFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TsvFormatterTest(unittest.TestCase): +class TsvFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), diff --git a/tests/format/test_unify_format.py b/tests/format/test_unify_format.py index c9b41d19d..52b87493d 100644 --- a/tests/format/test_unify_format.py +++ b/tests/format/test_unify_format.py @@ -5,9 +5,10 @@ from data_juicer.format.formatter import load_dataset, unify_format from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class UnifyFormatTest(unittest.TestCase): +class UnifyFormatTest(DataJuicerTestCaseBase): def run_test(self, sample, args=None): if args is None: @@ -347,26 +348,26 @@ def test_hetero_meta(self): file_path = os.path.join(cur_dir, 'demo-dataset.jsonl') ds = load_dataset('json', data_files=file_path) ds = unify_format(ds) - import datetime - # the 'None' fields are missing fields after merging - sample = [{ - 'text': "Today is Sunday and it's a happy day!", - 'meta': { - 'src': 'Arxiv', - 'date': datetime.datetime(2023, 4, 27, 0, 0), - 'version': '1.0', - 'author': None - } - }, { - 'text': 'Do you need a cup of coffee?', - 'meta': { - 'src': 'code', - 'date': None, - 'version': None, - 'author': 'xxx' - } - }] + # import datetime + # the 'None' fields are missing fields after merging + # sample = [{ + # 'text': "Today is Sunday and it's a happy day!", + # 'meta': { + # 'src': 'Arxiv', + # 'date': datetime.datetime(2023, 4, 27, 0, 0), + # 'version': '1.0', + # 'author': None + # } + # }, { + # 'text': 'Do you need a cup of coffee?', + # 'meta': { + # 'src': 'code', + # 'date': None, + # 'version': None, + # 'author': 'xxx' + # } + # }] # test nested and missing field for the following cases: # 1. first row, then column unified_sample_first = ds[0] diff --git a/tests/ops/data/video1.mp4 b/tests/ops/data/video1.mp4 new file mode 100644 index 000000000..5b0cad49f Binary files /dev/null and b/tests/ops/data/video1.mp4 differ diff --git a/tests/ops/data/video2.mp4 b/tests/ops/data/video2.mp4 new file mode 100644 index 000000000..28acb927f Binary files /dev/null and b/tests/ops/data/video2.mp4 differ diff --git a/tests/ops/data/video3-no-audio.mp4 b/tests/ops/data/video3-no-audio.mp4 new file mode 100644 index 000000000..ad30ec95b Binary files /dev/null and b/tests/ops/data/video3-no-audio.mp4 differ diff --git a/tests/ops/data/video3.mp4 b/tests/ops/data/video3.mp4 new file mode 100644 index 000000000..45db64a51 Binary files /dev/null and b/tests/ops/data/video3.mp4 differ diff --git a/tests/ops/data/video4.mp4 b/tests/ops/data/video4.mp4 new file mode 100644 index 000000000..8bf5fe0ea Binary files /dev/null and b/tests/ops/data/video4.mp4 differ diff --git a/tests/ops/data/video5.mp4 b/tests/ops/data/video5.mp4 new file mode 100644 index 000000000..46a52855e Binary files /dev/null and b/tests/ops/data/video5.mp4 differ diff --git a/tests/ops/deduplicator/test_document_deduplicator.py b/tests/ops/deduplicator/test_document_deduplicator.py index 740caae18..5a37a2e91 100644 --- a/tests/ops/deduplicator/test_document_deduplicator.py +++ b/tests/ops/deduplicator/test_document_deduplicator.py @@ -4,9 +4,10 @@ from data_juicer.ops.deduplicator.document_deduplicator import \ DocumentDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class DocumentDeduplicatorTest(unittest.TestCase): +class DocumentDeduplicatorTest(DataJuicerTestCaseBase): def _run_doc_dedup(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) diff --git a/tests/ops/deduplicator/test_document_minhash_deduplicator.py b/tests/ops/deduplicator/test_document_minhash_deduplicator.py index b60209e8b..5190ed1e4 100644 --- a/tests/ops/deduplicator/test_document_minhash_deduplicator.py +++ b/tests/ops/deduplicator/test_document_minhash_deduplicator.py @@ -4,9 +4,10 @@ from data_juicer.ops.deduplicator.document_minhash_deduplicator import \ DocumentMinhashDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class DocumentMinhashDeduplicatorTest(unittest.TestCase): +class DocumentMinhashDeduplicatorTest(DataJuicerTestCaseBase): def _run_minhash_dedup(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) diff --git a/tests/ops/deduplicator/test_document_simhash_deduplicator.py b/tests/ops/deduplicator/test_document_simhash_deduplicator.py index d021423c0..ddde50e82 100644 --- a/tests/ops/deduplicator/test_document_simhash_deduplicator.py +++ b/tests/ops/deduplicator/test_document_simhash_deduplicator.py @@ -4,9 +4,10 @@ from data_juicer.ops.deduplicator.document_simhash_deduplicator import \ DocumentSimhashDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class DocumentSimhashDeduplicatorTest(unittest.TestCase): +class DocumentSimhashDeduplicatorTest(DataJuicerTestCaseBase): def _run_simhash_dedup(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) diff --git a/tests/ops/deduplicator/test_image_deduplicator.py b/tests/ops/deduplicator/test_image_deduplicator.py index 3ac131506..a643b55be 100644 --- a/tests/ops/deduplicator/test_image_deduplicator.py +++ b/tests/ops/deduplicator/test_image_deduplicator.py @@ -3,30 +3,31 @@ from datasets import Dataset -from data_juicer.ops.deduplicator.image_deduplicator import \ - ImageDeduplicator +from data_juicer.ops.deduplicator.image_deduplicator import ImageDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageDeduplicatorTest(unittest.TestCase): +class ImageDeduplicatorTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - # img4.png is a duplicate sample of img1.png - img4_path = os.path.join(data_path, 'img4.png') - # img5.jpg is a duplicate sample of img2.jpg - img5_path = os.path.join(data_path, 'img5.jpg') - # img6.jpg is a duplicate sample of img3.jpg - img6_path = os.path.join(data_path, 'img6.jpg') - # img7.jpg is a duplicate sample of img6.jpg - img7_path = os.path.join(data_path, 'img7.jpg') - - - def _run_image_deduplicator(self, - dataset: Dataset, target_list, - op): + # img1_dup.png is a duplicate sample of img1.png + img4_path = os.path.join(data_path, 'img1_dup.png') + os.symlink(img1_path, img4_path) + # img2_dup.jpg is a duplicate sample of img2.jpg + img5_path = os.path.join(data_path, 'img2_dup.jpg') + os.symlink(img2_path, img5_path) + # img3_dup.jpg is a duplicate sample of img3.jpg + img6_path = os.path.join(data_path, 'img3_dup.jpg') + os.symlink(img3_path, img6_path) + # img3_dup_dup.jpg is a duplicate sample of img6.jpg + img7_path = os.path.join(data_path, 'img3_dup_dup.jpg') + os.symlink(img6_path, img7_path) + + def _run_image_deduplicator(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) dataset, _ = op.process(dataset) @@ -63,11 +64,7 @@ def test_2(self): }, { 'images': [self.img2_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = ImageDeduplicator() self._run_image_deduplicator(dataset, tgt_list, op) @@ -216,5 +213,6 @@ def test_8(self): op = ImageDeduplicator(method='ahash') self._run_image_deduplicator(dataset, tgt_list, op) + if __name__ == '__main__': unittest.main() diff --git a/tests/ops/deduplicator/test_video_deduplicator.py b/tests/ops/deduplicator/test_video_deduplicator.py new file mode 100644 index 000000000..951ed6bf0 --- /dev/null +++ b/tests/ops/deduplicator/test_video_deduplicator.py @@ -0,0 +1,150 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.deduplicator.video_deduplicator import VideoDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoDeduplicatorTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + video1_path = os.path.join(data_path, 'video1.mp4') + video2_path = os.path.join(data_path, 'video2.mp4') + video3_path = os.path.join(data_path, 'video3.mp4') + # video1_dup.mp4 is a duplicate sample of video1.mp4 + video4_path = os.path.join(data_path, 'video1_dup.mp4') + os.symlink(video1_path, video4_path) + # video2_dup.mp4 is a duplicate sample of video2.mp4 + video5_path = os.path.join(data_path, 'video2_dup.mp4') + os.symlink(video2_path, video5_path) + # video3_dup.mp4 is a duplicate sample of video3.mp4 + video6_path = os.path.join(data_path, 'video3_dup.mp4') + os.symlink(video3_path, video6_path) + # video3_dup_dup.mp4 is a duplicate sample of video6.mp4 + video7_path = os.path.join(data_path, 'video3_dup_dup.mp4') + os.symlink(video6_path, video7_path) + + def _run_video_deduplicator(self, dataset: Dataset, target_list, op): + + dataset = dataset.map(op.compute_hash) + dataset, _ = op.process(dataset) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_1(self): + + ds_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }] + tgt_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_2(self): + + ds_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video2_path] + }] + tgt_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_3(self): + + ds_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }, { + 'videos': [self.video4_path] + }, { + 'videos': [self.video5_path] + }, { + 'videos': [self.video6_path] + }, { + 'videos': [self.video7_path] + }] + tgt_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_4(self): + + ds_list = [{ + 'videos': [self.video1_path, self.video2_path, self.video3_path] + }, { + 'videos': [self.video4_path, self.video5_path, self.video6_path] + }, { + 'videos': [self.video7_path, self.video5_path] + }, { + 'videos': [self.video6_path, self.video5_path] + }] + tgt_list = [{ + 'videos': [self.video1_path, self.video2_path, self.video3_path] + }, { + 'videos': [self.video7_path, self.video5_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_5(self): + + ds_list = [{ + 'videos': [self.video1_path, self.video2_path] + }, { + 'videos': [self.video2_path, self.video1_path] + }, { + 'videos': [self.video4_path, self.video5_path] + }, { + 'videos': [self.video7_path, self.video7_path] + }, { + 'videos': [self.video6_path, self.video6_path] + }] + tgt_list = [{ + 'videos': [self.video1_path, self.video2_path] + }, { + 'videos': [self.video2_path, self.video1_path] + }, { + 'videos': [self.video7_path, self.video7_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_alphanumeric_filter.py b/tests/ops/filter/test_alphanumeric_filter.py index a8558cf06..efca696c2 100644 --- a/tests/ops/filter/test_alphanumeric_filter.py +++ b/tests/ops/filter/test_alphanumeric_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.alphanumeric_filter import AlphanumericFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AlphanumericFilterTest(unittest.TestCase): +class AlphanumericFilterTest(DataJuicerTestCaseBase): def _run_alphanumeric_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_audio_duration_filter.py b/tests/ops/filter/test_audio_duration_filter.py index f12b45bb7..91a39bfd8 100644 --- a/tests/ops/filter/test_audio_duration_filter.py +++ b/tests/ops/filter/test_audio_duration_filter.py @@ -5,12 +5,13 @@ from data_juicer.ops.filter.audio_duration_filter import AudioDurationFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AudioDurationFilterTest(unittest.TestCase): +class AudioDurationFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') aud1_path = os.path.join(data_path, 'audio1.wav') # about 6s aud2_path = os.path.join(data_path, 'audio2.wav') # about 14s aud3_path = os.path.join(data_path, 'audio3.ogg') # about 1min59s @@ -49,7 +50,7 @@ def test_default_filter(self): op = AudioDurationFilter() self._run_audio_duration_filter(dataset, tgt_list, op) - def test_filter_short_audios(self): + def test_filter_long_audios(self): ds_list = [{ 'audios': [self.aud1_path] @@ -58,14 +59,12 @@ def test_filter_short_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }] + tgt_list = [{'audios': [self.aud1_path]}] dataset = Dataset.from_list(ds_list) op = AudioDurationFilter(max_duration=10) self._run_audio_duration_filter(dataset, tgt_list, op) - def test_filter_long_audios(self): + def test_filter_short_audios(self): ds_list = [{ 'audios': [self.aud1_path] @@ -74,9 +73,7 @@ def test_filter_long_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioDurationFilter(min_duration=60) self._run_audio_duration_filter(dataset, tgt_list, op) @@ -90,12 +87,9 @@ def test_filter_audios_within_range(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud2_path] - }] + tgt_list = [{'audios': [self.aud2_path]}] dataset = Dataset.from_list(ds_list) - op = AudioDurationFilter(min_duration=10, - max_duration=20) + op = AudioDurationFilter(min_duration=10, max_duration=20) self._run_audio_duration_filter(dataset, tgt_list, op) def test_any(self): @@ -143,12 +137,9 @@ def test_filter_in_parallel(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud2_path] - }] + tgt_list = [{'audios': [self.aud2_path]}] dataset = Dataset.from_list(ds_list) - op = AudioDurationFilter(min_duration=10, - max_duration=20) + op = AudioDurationFilter(min_duration=10, max_duration=20) self._run_audio_duration_filter(dataset, tgt_list, op, np=2) diff --git a/tests/ops/filter/test_audio_nmf_snr_filter.py b/tests/ops/filter/test_audio_nmf_snr_filter.py index 84b73d2c8..728c43f39 100644 --- a/tests/ops/filter/test_audio_nmf_snr_filter.py +++ b/tests/ops/filter/test_audio_nmf_snr_filter.py @@ -5,12 +5,13 @@ from data_juicer.ops.filter.audio_nmf_snr_filter import AudioNMFSNRFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AudioNMFSNRFilterTest(unittest.TestCase): +class AudioNMFSNRFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') aud1_path = os.path.join(data_path, 'audio1.wav') # about -7dB aud2_path = os.path.join(data_path, 'audio2.wav') # about 6dB aud3_path = os.path.join(data_path, 'audio3.ogg') # about 3dB @@ -58,11 +59,7 @@ def test_filter_low_snr_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud2_path] - }, { - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud2_path]}, {'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=0) self._run_audio_nmf_snr_filter(dataset, tgt_list, op) @@ -76,11 +73,7 @@ def test_filter_high_snr_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }, { - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud1_path]}, {'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=-1000, max_snr=5) self._run_audio_nmf_snr_filter(dataset, tgt_list, op) @@ -94,9 +87,7 @@ def test_filter_audios_within_range(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=0, max_snr=5) self._run_audio_nmf_snr_filter(dataset, tgt_list, op) @@ -142,9 +133,7 @@ def test_filter_in_parallel(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=0, max_snr=5, any_or_all='any') self._run_audio_nmf_snr_filter(dataset, tgt_list, op, np=2) diff --git a/tests/ops/filter/test_audio_size_filter.py b/tests/ops/filter/test_audio_size_filter.py index c47241965..00b4158d7 100644 --- a/tests/ops/filter/test_audio_size_filter.py +++ b/tests/ops/filter/test_audio_size_filter.py @@ -5,17 +5,18 @@ from data_juicer.ops.filter.audio_size_filter import AudioSizeFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AudioSizeFilterTest(unittest.TestCase): +class AudioSizeFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') aud1_path = os.path.join(data_path, 'audio1.wav') # 970574 / 948K aud2_path = os.path.join(data_path, 'audio2.wav') # 2494872 / 2.4M aud3_path = os.path.join(data_path, 'audio3.ogg') # 597254 / 583K - def _run_audio_size_filter(self,dataset: Dataset, target_list, op, np=1): + def _run_audio_size_filter(self, dataset: Dataset, target_list, op, np=1): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -34,11 +35,9 @@ def test_min_max(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }] + tgt_list = [{'audios': [self.aud1_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB") + op = AudioSizeFilter(min_size='800kb', max_size='1MB') self._run_audio_size_filter(dataset, tgt_list, op) def test_min(self): @@ -50,13 +49,9 @@ def test_min(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }, { - 'audios': [self.aud2_path] - }] + tgt_list = [{'audios': [self.aud1_path]}, {'audios': [self.aud2_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="900kib") + op = AudioSizeFilter(min_size='900kib') self._run_audio_size_filter(dataset, tgt_list, op) def test_max(self): @@ -68,13 +63,9 @@ def test_max(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }, { - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud1_path]}, {'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(max_size="2MiB") + op = AudioSizeFilter(max_size='2MiB') self._run_audio_size_filter(dataset, tgt_list, op) def test_any(self): @@ -92,8 +83,9 @@ def test_any(self): 'audios': [self.aud1_path, self.aud3_path] }] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB", - any_or_all='any') + op = AudioSizeFilter(min_size='800kb', + max_size='1MB', + any_or_all='any') self._run_audio_size_filter(dataset, tgt_list, op) def test_all(self): @@ -107,8 +99,9 @@ def test_all(self): }] tgt_list = [] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB", - any_or_all='all') + op = AudioSizeFilter(min_size='800kb', + max_size='1MB', + any_or_all='all') self._run_audio_size_filter(dataset, tgt_list, op) def test_filter_in_parallel(self): @@ -120,11 +113,9 @@ def test_filter_in_parallel(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }] + tgt_list = [{'audios': [self.aud1_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB") + op = AudioSizeFilter(min_size='800kb', max_size='1MB') self._run_audio_size_filter(dataset, tgt_list, op, np=2) diff --git a/tests/ops/filter/test_average_line_length_filter.py b/tests/ops/filter/test_average_line_length_filter.py index 740d5f3c4..a1c39e702 100644 --- a/tests/ops/filter/test_average_line_length_filter.py +++ b/tests/ops/filter/test_average_line_length_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.average_line_length_filter import \ AverageLineLengthFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AverageLineLengthFilterTest(unittest.TestCase): +class AverageLineLengthFilterTest(DataJuicerTestCaseBase): def _run_average_line_length_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_character_repetition_filter.py b/tests/ops/filter/test_character_repetition_filter.py index b54d76a71..85133c133 100644 --- a/tests/ops/filter/test_character_repetition_filter.py +++ b/tests/ops/filter/test_character_repetition_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.character_repetition_filter import \ CharacterRepetitionFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CharacterRepetitionFilterTest(unittest.TestCase): +class CharacterRepetitionFilterTest(DataJuicerTestCaseBase): def _run_character_repetition_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_face_area_filter.py b/tests/ops/filter/test_face_area_filter.py index 0008c9377..1e747ec59 100644 --- a/tests/ops/filter/test_face_area_filter.py +++ b/tests/ops/filter/test_face_area_filter.py @@ -5,20 +5,22 @@ from data_juicer.ops.filter.face_area_filter import FaceAreaFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class FaceAreaFilterTest(unittest.TestCase): +class FaceAreaFilterTest(DataJuicerTestCaseBase): maxDiff = None - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'cat.jpg') img2_path = os.path.join(data_path, 'lena.jpg') img3_path = os.path.join(data_path, 'lena-face.jpg') def _run_face_area_filter(self, - dataset: Dataset, target_list, + dataset: Dataset, + target_list, op, num_proc=1): if Fields.stats not in dataset.features: @@ -39,9 +41,7 @@ def test_filter_small(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img3_path] - }] + tgt_list = [{'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter(min_ratio=0.4, max_ratio=1.0) self._run_face_area_filter(dataset, tgt_list, op) @@ -55,11 +55,7 @@ def test_filter_large(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter(min_ratio=0.0, max_ratio=0.4) self._run_face_area_filter(dataset, tgt_list, op) @@ -67,20 +63,27 @@ def test_filter_large(self): def test_filter_multimodal(self): ds_list = [{ - 'text': 'a test sentence', 'images': [] + 'text': 'a test sentence', + 'images': [] }, { - 'text': 'a test sentence', 'images': [self.img1_path] + 'text': 'a test sentence', + 'images': [self.img1_path] }, { - 'text': 'a test sentence', 'images': [self.img2_path] + 'text': 'a test sentence', + 'images': [self.img2_path] }, { - 'text': 'a test sentence', 'images': [self.img3_path] + 'text': 'a test sentence', + 'images': [self.img3_path] }] tgt_list = [{ - 'text': 'a test sentence', 'images': [] + 'text': 'a test sentence', + 'images': [] }, { - 'text': 'a test sentence', 'images': [self.img1_path] + 'text': 'a test sentence', + 'images': [self.img1_path] }, { - 'text': 'a test sentence', 'images': [self.img2_path] + 'text': 'a test sentence', + 'images': [self.img2_path] }] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter() @@ -103,9 +106,7 @@ def test_any(self): 'images': [self.img1_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) - op = FaceAreaFilter(min_ratio=0.0, - max_ratio=0.4, - any_or_all='any') + op = FaceAreaFilter(min_ratio=0.0, max_ratio=0.4, any_or_all='any') self._run_face_area_filter(dataset, tgt_list, op) def test_all(self): @@ -117,13 +118,9 @@ def test_all(self): }, { 'images': [self.img1_path, self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path, self.img2_path] - }] + tgt_list = [{'images': [self.img1_path, self.img2_path]}] dataset = Dataset.from_list(ds_list) - op = FaceAreaFilter(min_ratio=0.0, - max_ratio=0.4, - any_or_all='all') + op = FaceAreaFilter(min_ratio=0.0, max_ratio=0.4, any_or_all='all') self._run_face_area_filter(dataset, tgt_list, op) def test_filter_multi_process(self): @@ -135,11 +132,7 @@ def test_filter_multi_process(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter() self._run_face_area_filter(dataset, tgt_list, op, num_proc=3) diff --git a/tests/ops/filter/test_flagged_words_filter.py b/tests/ops/filter/test_flagged_words_filter.py index af7ddf233..e346eb0f5 100644 --- a/tests/ops/filter/test_flagged_words_filter.py +++ b/tests/ops/filter/test_flagged_words_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.flagged_words_filter import FlaggedWordFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class FlaggedWordFilterTest(unittest.TestCase): +class FlaggedWordFilterTest(DataJuicerTestCaseBase): def _run_flagged_words_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_image_aesthetics_filter.py b/tests/ops/filter/test_image_aesthetics_filter.py new file mode 100644 index 000000000..ef221bf08 --- /dev/null +++ b/tests/ops/filter/test_image_aesthetics_filter.py @@ -0,0 +1,155 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.image_aesthetics_filter import \ + ImageAestheticsFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class ImageAestheticsFilterTest(DataJuicerTestCaseBase): + + maxDiff = None + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + img1_path = os.path.join(data_path, 'cat.jpg') + img2_path = os.path.join(data_path, 'blip.jpg') + img3_path = os.path.join(data_path, 'lena-face.jpg') + + model_id = \ + 'shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE' + + # with shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE + # the img1, img2, img3 gets scores 0.4382, 0.5973, 0.5216 respectively + + def _run_image_aesthetics_filter(self, + dataset: Dataset, + target_list, + op, + num_proc=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=num_proc) + dataset = dataset.filter(op.process, num_proc=num_proc) + dataset = dataset.remove_columns(Fields.stats) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_filter_small(self): + + ds_list = [{ + 'images': [self.img1_path] + }, { + 'images': [self.img2_path] + }, { + 'images': [self.img3_path] + }] + tgt_list = [{'images': [self.img2_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + min_score=0.55, + max_score=1.0) + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_large(self): + + ds_list = [{ + 'images': [self.img1_path] + }, { + 'images': [self.img2_path] + }, { + 'images': [self.img3_path] + }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + min_score=0.4, + max_score=0.55) + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_multimodal(self): + + ds_list = [{ + 'text': 'a test sentence', + 'images': [] + }, { + 'text': 'a test sentence', + 'images': [self.img1_path] + }, { + 'text': 'a test sentence', + 'images': [self.img2_path] + }, { + 'text': 'a test sentence', + 'images': [self.img3_path] + }] + tgt_list = [{ + 'text': 'a test sentence', + 'images': [] + }, { + 'text': 'a test sentence', + 'images': [self.img2_path] + }, { + 'text': 'a test sentence', + 'images': [self.img3_path] + }] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, ) + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'images': [self.img1_path, self.img2_path] + }, { + 'images': [self.img2_path, self.img3_path] + }, { + 'images': [self.img1_path, self.img3_path] + }] + tgt_list = [{ + 'images': [self.img1_path, self.img2_path] + }, { + 'images': [self.img2_path, self.img3_path] + }, { + 'images': [self.img1_path, self.img3_path] + }] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + any_or_all='any') + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'images': [self.img1_path, self.img2_path] + }, { + 'images': [self.img2_path, self.img3_path] + }, { + 'images': [self.img1_path, self.img3_path] + }] + tgt_list = [{'images': [self.img2_path, self.img3_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + any_or_all='all') + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_multi_process(self): + + ds_list = [{ + 'images': [self.img1_path] + }, { + 'images': [self.img2_path] + }, { + 'images': [self.img3_path] + }] + tgt_list = [{'images': [self.img2_path]}, {'images': [self.img3_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, ) + self._run_image_aesthetics_filter(dataset, tgt_list, op, num_proc=3) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_image_aspect_ratio_filter.py b/tests/ops/filter/test_image_aspect_ratio_filter.py index a328d934a..d8d3df0ea 100644 --- a/tests/ops/filter/test_image_aspect_ratio_filter.py +++ b/tests/ops/filter/test_image_aspect_ratio_filter.py @@ -6,18 +6,18 @@ from data_juicer.ops.filter.image_aspect_ratio_filter import \ ImageAspectRatioFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageAspectRatioFilterTest(unittest.TestCase): +class ImageAspectRatioFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_image_aspect_ratio_filter(self, - dataset: Dataset, target_list, + def _run_image_aspect_ratio_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, @@ -37,9 +37,7 @@ def test_filter1(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }] + tgt_list = [{'images': [self.img1_path]}] dataset = Dataset.from_list(ds_list) op = ImageAspectRatioFilter(min_ratio=0.8, max_ratio=1.2) self._run_image_aspect_ratio_filter(dataset, tgt_list, op) @@ -53,11 +51,7 @@ def test_filter2(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = ImageAspectRatioFilter(min_ratio=0.8) self._run_image_aspect_ratio_filter(dataset, tgt_list, op) @@ -71,11 +65,7 @@ def test_filter3(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img3_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) op = ImageAspectRatioFilter(max_ratio=1.2) self._run_image_aspect_ratio_filter(dataset, tgt_list, op) diff --git a/tests/ops/filter/test_image_shape_filter.py b/tests/ops/filter/test_image_shape_filter.py index 3cc73406c..e7e5deaed 100644 --- a/tests/ops/filter/test_image_shape_filter.py +++ b/tests/ops/filter/test_image_shape_filter.py @@ -5,20 +5,18 @@ from data_juicer.ops.filter.image_shape_filter import ImageShapeFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageShapeFilterTest(unittest.TestCase): +class ImageShapeFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_image_shape_filter(self, - dataset: Dataset, - target_list, - op): + def _run_image_shape_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -37,12 +35,9 @@ def test_filter1(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(min_width=400, - min_height=400) + op = ImageShapeFilter(min_width=400, min_height=400) self._run_image_shape_filter(dataset, tgt_list, op) def test_filter2(self): @@ -54,14 +49,9 @@ def test_filter2(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img3_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(max_width=500, - max_height=500) + op = ImageShapeFilter(max_width=500, max_height=500) self._run_image_shape_filter(dataset, tgt_list, op) def test_filter3(self): @@ -99,9 +89,7 @@ def test_any(self): 'images': [self.img2_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(min_width=400, - min_height=400, - any_or_all='any') + op = ImageShapeFilter(min_width=400, min_height=400, any_or_all='any') self._run_image_shape_filter(dataset, tgt_list, op) def test_all(self): @@ -115,9 +103,7 @@ def test_all(self): }] tgt_list = [] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(min_width=400, - min_height=400, - any_or_all='all') + op = ImageShapeFilter(min_width=400, min_height=400, any_or_all='all') self._run_image_shape_filter(dataset, tgt_list, op) diff --git a/tests/ops/filter/test_image_size_filter.py b/tests/ops/filter/test_image_size_filter.py index 46cfff62f..fcc5e3e76 100644 --- a/tests/ops/filter/test_image_size_filter.py +++ b/tests/ops/filter/test_image_size_filter.py @@ -5,19 +5,18 @@ from data_juicer.ops.filter.image_size_filter import ImageSizeFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageSizeFilterTest(unittest.TestCase): +class ImageSizeFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_image_size_filter(self, - dataset: Dataset, target_list, - op): + def _run_image_size_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -29,54 +28,56 @@ def _run_image_size_filter(self, def test_min_max(self): - ds_list = [{ - 'images': [self.img1_path] # 171KB - }, { - 'images': [self.img2_path] # 189KB - }, { - 'images': [self.img3_path] # 114KB - }] - tgt_list = [{ - 'images': [self.img1_path] - }] + ds_list = [ + { + 'images': [self.img1_path] # 171KB + }, + { + 'images': [self.img2_path] # 189KB + }, + { + 'images': [self.img3_path] # 114KB + } + ] + tgt_list = [{'images': [self.img1_path]}] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kb", max_size="180KB") + op = ImageSizeFilter(min_size='120kb', max_size='180KB') self._run_image_size_filter(dataset, tgt_list, op) def test_min(self): - ds_list = [{ - 'images': [self.img1_path] # 171KB - }, { - 'images': [self.img2_path] # 189KB - }, { - 'images': [self.img3_path] # 114KB - }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + ds_list = [ + { + 'images': [self.img1_path] # 171KB + }, + { + 'images': [self.img2_path] # 189KB + }, + { + 'images': [self.img3_path] # 114KB + } + ] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kib") + op = ImageSizeFilter(min_size='120kib') self._run_image_size_filter(dataset, tgt_list, op) def test_max(self): - ds_list = [{ - 'images': [self.img1_path] # 171KB - }, { - 'images': [self.img2_path] # 189KB - }, { - 'images': [self.img3_path] # 114KB - }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img3_path] - }] + ds_list = [ + { + 'images': [self.img1_path] # 171KB + }, + { + 'images': [self.img2_path] # 189KB + }, + { + 'images': [self.img3_path] # 114KB + } + ] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(max_size="180KiB") + op = ImageSizeFilter(max_size='180KiB') self._run_image_size_filter(dataset, tgt_list, op) def test_any(self): @@ -94,8 +95,9 @@ def test_any(self): 'images': [self.img1_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kb", max_size="180KB", - any_or_all='any') + op = ImageSizeFilter(min_size='120kb', + max_size='180KB', + any_or_all='any') self._run_image_size_filter(dataset, tgt_list, op) def test_all(self): @@ -109,7 +111,9 @@ def test_all(self): }] tgt_list = [] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kb", max_size="180KB", any_or_all='all') + op = ImageSizeFilter(min_size='120kb', + max_size='180KB', + any_or_all='all') self._run_image_size_filter(dataset, tgt_list, op) diff --git a/tests/ops/filter/test_image_text_matching_filter.py b/tests/ops/filter/test_image_text_matching_filter.py index 15adfb5d4..7620b84a8 100644 --- a/tests/ops/filter/test_image_text_matching_filter.py +++ b/tests/ops/filter/test_image_text_matching_filter.py @@ -1,13 +1,17 @@ +# flake8: noqa: E501 + import os import unittest from datasets import Dataset -from data_juicer.ops.filter.image_text_matching_filter import ImageTextMatchingFilter +from data_juicer.ops.filter.image_text_matching_filter import \ + ImageTextMatchingFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + class ImageTextMatchingFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', @@ -20,7 +24,7 @@ class ImageTextMatchingFilterTest(DataJuicerTestCaseBase): @classmethod def tearDownClass(cls) -> None: super().tearDownClass(cls.hf_blip) - + def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): if Fields.stats not in dataset.features: @@ -30,7 +34,9 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) - dataset = dataset.map(op.compute_stats, num_proc=num_proc, with_rank=True) + dataset = dataset.map(op.compute_stats, + num_proc=num_proc, + with_rank=True) dataset = dataset.filter(op.process, num_proc=num_proc) dataset = dataset.select_columns(column_names=['text', 'images']) res_list = dataset.to_list() @@ -39,23 +45,26 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): def test_no_eoc_special_token(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_eoc_special_token(self): @@ -65,7 +74,8 @@ def test_eoc_special_token(self): f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.eoc}', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ @@ -76,10 +86,10 @@ def test_eoc_special_token(self): dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_horizontal_flip(self): @@ -89,7 +99,8 @@ def test_horizontal_flip(self): f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.eoc}', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ @@ -100,12 +111,12 @@ def test_horizontal_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=True, - vertical_flip=False, - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=True, + vertical_flip=False, + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_vertical_flip(self): @@ -115,7 +126,8 @@ def test_vertical_flip(self): f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.eoc}', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ @@ -126,12 +138,12 @@ def test_vertical_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=True, - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=True, + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_keep_any(self): @@ -150,10 +162,10 @@ def test_keep_any(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_keep_all(self): @@ -167,66 +179,71 @@ def test_keep_all(self): tgt_list = [] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='all', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='all', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_reduce_avg(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_reduce_max(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='max', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='max', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_reduce_min(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='min', - any_or_all='any', - min_score=0.1, - max_score=0.9) + reduce_mode='min', + any_or_all='any', + min_score=0.1, + max_score=0.9) self._run_filter(dataset, [], op) def test_multi_process(self): @@ -245,10 +262,10 @@ def test_multi_process(self): }] * 10 dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op, num_proc=4) diff --git a/tests/ops/filter/test_image_text_similarity_filter.py b/tests/ops/filter/test_image_text_similarity_filter.py index f50637561..549ee3137 100644 --- a/tests/ops/filter/test_image_text_similarity_filter.py +++ b/tests/ops/filter/test_image_text_similarity_filter.py @@ -3,11 +3,13 @@ from datasets import Dataset -from data_juicer.ops.filter.image_text_similarity_filter import ImageTextSimilarityFilter +from data_juicer.ops.filter.image_text_similarity_filter import \ + ImageTextSimilarityFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + class ImageTextSimilarityFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', @@ -30,7 +32,9 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) - dataset = dataset.map(op.compute_stats, num_proc=num_proc, with_rank=True) + dataset = dataset.map(op.compute_stats, + num_proc=num_proc, + with_rank=True) dataset = dataset.filter(op.process, num_proc=num_proc) dataset = dataset.select_columns(column_names=['text', 'images']) res_list = dataset.to_list() @@ -52,12 +56,12 @@ def test_no_eoc_special_token(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_eoc_special_token(self): @@ -67,7 +71,8 @@ def test_eoc_special_token(self): f'{SpecialTokens.image}a photo of a cat{SpecialTokens.eoc}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image}a photo of a dog{SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image}a photo of a dog{SpecialTokens.eoc}', 'images': [self.cat_path] }] tgt_list = [{ @@ -78,12 +83,12 @@ def test_eoc_special_token(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_horizontal_flip(self): @@ -104,12 +109,12 @@ def test_horizontal_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=True, - vertical_flip=False, - min_score=0.24, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=True, + vertical_flip=False, + min_score=0.24, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_vertical_flip(self): @@ -130,12 +135,12 @@ def test_vertical_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=True, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=True, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_keep_any(self): @@ -154,12 +159,12 @@ def test_keep_any(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_keep_all(self): @@ -173,12 +178,12 @@ def test_keep_all(self): tgt_list = [] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='all', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='all', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_reduce_avg(self): @@ -195,12 +200,12 @@ def test_reduce_avg(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_reduce_max(self): @@ -217,12 +222,12 @@ def test_reduce_max(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='max', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='max', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_reduce_min(self): @@ -240,12 +245,12 @@ def test_reduce_min(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='min', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.1, - max_score=0.9) + reduce_mode='min', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.1, + max_score=0.9) self._run_filter(dataset, tgt_list, op) @@ -268,12 +273,12 @@ def test_multi_process(self): }] * 10 dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op, num_proc=4) diff --git a/tests/ops/filter/test_language_id_score_filter.py b/tests/ops/filter/test_language_id_score_filter.py index 0b6e50daa..21d71ceb5 100644 --- a/tests/ops/filter/test_language_id_score_filter.py +++ b/tests/ops/filter/test_language_id_score_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.language_id_score_filter import \ LanguageIDScoreFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class LanguageIDScoreFilterTest(unittest.TestCase): +class LanguageIDScoreFilterTest(DataJuicerTestCaseBase): def _run_language_id_score_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_maximum_line_length_filter.py b/tests/ops/filter/test_maximum_line_length_filter.py index 8bcf6aa83..ef8a6d33e 100644 --- a/tests/ops/filter/test_maximum_line_length_filter.py +++ b/tests/ops/filter/test_maximum_line_length_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.maximum_line_length_filter import \ MaximumLineLengthFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class MaximumLineLengthFilterTest(unittest.TestCase): +class MaximumLineLengthFilterTest(DataJuicerTestCaseBase): def _run_maximum_line_length_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_perplexity_filter.py b/tests/ops/filter/test_perplexity_filter.py index 4b45598dd..114bdb307 100644 --- a/tests/ops/filter/test_perplexity_filter.py +++ b/tests/ops/filter/test_perplexity_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.perplexity_filter import PerplexityFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class PerplexityFilterTest(unittest.TestCase): +class PerplexityFilterTest(DataJuicerTestCaseBase): def _run_perplexity_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_phrase_grounding_recall_filter.py b/tests/ops/filter/test_phrase_grounding_recall_filter.py index c5510014d..16d689e7d 100644 --- a/tests/ops/filter/test_phrase_grounding_recall_filter.py +++ b/tests/ops/filter/test_phrase_grounding_recall_filter.py @@ -1,13 +1,17 @@ +# flake8: noqa: E501 + import os import unittest from datasets import Dataset -from data_juicer.ops.filter.phrase_grounding_recall_filter import PhraseGroundingRecallFilter +from data_juicer.ops.filter.phrase_grounding_recall_filter import \ + PhraseGroundingRecallFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + class PhraseGroundingRecallFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', @@ -24,7 +28,7 @@ class PhraseGroundingRecallFilterTest(DataJuicerTestCaseBase): @classmethod def tearDownClass(cls) -> None: super().tearDownClass(cls.hf_owlvit) - + def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): if Fields.stats not in dataset.features: @@ -34,7 +38,9 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) - dataset = dataset.map(op.compute_stats, num_proc=num_proc, with_rank=True) + dataset = dataset.map(op.compute_stats, + num_proc=num_proc, + with_rank=True) dataset = dataset.filter(op.process, num_proc=num_proc) dataset = dataset.select_columns(column_names=['text', 'images']) res_list = dataset.to_list() @@ -43,35 +49,45 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): def test_general(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] @@ -88,29 +104,37 @@ def test_general(self): def test_high_recall(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] @@ -127,14 +151,17 @@ def test_high_recall(self): def test_high_conf_thr(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }] @@ -152,17 +179,21 @@ def test_high_conf_thr(self): def test_low_conf_thr(self): # some similar but different objects might be detected incorrectly ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] @@ -183,7 +214,8 @@ def test_low_area_ratio(self): 'text': f'{SpecialTokens.image} a photo of a woman\'s face', 'images': [self.face_path] }, { - 'text': f'{SpecialTokens.image}A bus with red advertisements is running on the street.', + 'text': + f'{SpecialTokens.image}A bus with red advertisements is running on the street.', 'images': [self.img2_path] }] tgt_list = [] @@ -205,11 +237,13 @@ def test_high_area_ratio(self): 'text': f'{SpecialTokens.image} a photo of a woman\'s face', 'images': [self.face_path] }, { - 'text': f'{SpecialTokens.image}A bus with red advertisements is running on the street.', + 'text': + f'{SpecialTokens.image}A bus with red advertisements is running on the street.', 'images': [self.img2_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}A bus with red advertisements is running on the street.', + 'text': + f'{SpecialTokens.image}A bus with red advertisements is running on the street.', 'images': [self.img2_path] }] @@ -227,17 +261,21 @@ def test_high_area_ratio(self): def test_reduce_avg(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] @@ -254,14 +292,17 @@ def test_reduce_avg(self): def test_reduce_max(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }] @@ -278,10 +319,12 @@ def test_reduce_max(self): def test_reduce_min(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] tgt_list = [] @@ -300,8 +343,8 @@ def test_keep_all(self): ds_list = [{ 'text': - f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' - f'{SpecialTokens.image} a woman sitting on the beach with a dog', + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' + f'{SpecialTokens.image} a woman sitting on the beach with a dog', 'images': [self.img1_path, self.cat_path, self.demo_path] }] tgt_list = [] @@ -320,14 +363,14 @@ def test_keep_any(self): ds_list = [{ 'text': - f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' - f'{SpecialTokens.image} a woman sitting on the beach with a dog', + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' + f'{SpecialTokens.image} a woman sitting on the beach with a dog', 'images': [self.img1_path, self.cat_path, self.demo_path] }] tgt_list = [{ 'text': - f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' - f'{SpecialTokens.image} a woman sitting on the beach with a dog', + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' + f'{SpecialTokens.image} a woman sitting on the beach with a dog', 'images': [self.img1_path, self.cat_path, self.demo_path] }] @@ -344,29 +387,37 @@ def test_keep_any(self): def test_process_in_parallel(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] diff --git a/tests/ops/filter/test_special_characters_filter.py b/tests/ops/filter/test_special_characters_filter.py index 301291bc4..4ea505968 100644 --- a/tests/ops/filter/test_special_characters_filter.py +++ b/tests/ops/filter/test_special_characters_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.special_characters_filter import \ SpecialCharactersFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SpecialCharactersFilterTest(unittest.TestCase): +class SpecialCharactersFilterTest(DataJuicerTestCaseBase): def _run_special_characters_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_specified_field_filter.py b/tests/ops/filter/test_specified_field_filter.py index a3bd51020..3086e2b00 100644 --- a/tests/ops/filter/test_specified_field_filter.py +++ b/tests/ops/filter/test_specified_field_filter.py @@ -3,9 +3,10 @@ from datasets import Dataset from data_juicer.ops.filter.specified_field_filter import SpecifiedFieldFilter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SpecifiedFieldFilterTest(unittest.TestCase): +class SpecifiedFieldFilterTest(DataJuicerTestCaseBase): def _run_specified_field_filter(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_stats) diff --git a/tests/ops/filter/test_specified_numeric_field_filter.py b/tests/ops/filter/test_specified_numeric_field_filter.py index f82fd4617..c580f6905 100644 --- a/tests/ops/filter/test_specified_numeric_field_filter.py +++ b/tests/ops/filter/test_specified_numeric_field_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.specified_numeric_field_filter import \ SpecifiedNumericFieldFilter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SpecifiedNumericFieldFilterTest(unittest.TestCase): +class SpecifiedNumericFieldFilterTest(DataJuicerTestCaseBase): def _run_specified_numeric_field_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_stop_words_filter.py b/tests/ops/filter/test_stop_words_filter.py index 60219c1c5..8772b6960 100644 --- a/tests/ops/filter/test_stop_words_filter.py +++ b/tests/ops/filter/test_stop_words_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.stopwords_filter import StopWordsFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class StopWordsFilterTest(unittest.TestCase): +class StopWordsFilterTest(DataJuicerTestCaseBase): def _run_stopwords_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_suffix_filter.py b/tests/ops/filter/test_suffix_filter.py index ea2407245..48980c120 100644 --- a/tests/ops/filter/test_suffix_filter.py +++ b/tests/ops/filter/test_suffix_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.suffix_filter import SuffixFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SuffixFilterTest(unittest.TestCase): +class SuffixFilterTest(DataJuicerTestCaseBase): def _run_suffix_filter(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_stats) diff --git a/tests/ops/filter/test_text_action_filter.py b/tests/ops/filter/test_text_action_filter.py index 9a146ea33..78b40dfad 100644 --- a/tests/ops/filter/test_text_action_filter.py +++ b/tests/ops/filter/test_text_action_filter.py @@ -1,14 +1,15 @@ -import unittest import os +import unittest from datasets import Dataset from data_juicer.ops.filter.text_action_filter import TextActionFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TextActionFilterTest(unittest.TestCase): +class TextActionFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'data') @@ -16,7 +17,8 @@ class TextActionFilterTest(unittest.TestCase): cat_path = os.path.join(data_path, 'cat.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_text_action_filter(self, dataset: Dataset, target_list, op, column_names): + def _run_text_action_filter(self, dataset: Dataset, target_list, op, + column_names): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -34,7 +36,7 @@ def test_en_text_case(self): 'text': 'Tom plays piano.' }, { 'text': 'Tom played piano.' - },{ + }, { 'text': 'I play piano.' }, { 'text': 'to play piano.' @@ -53,7 +55,7 @@ def test_en_text_case(self): 'text': 'Tom plays piano.' }, { 'text': 'Tom played piano.' - },{ + }, { 'text': 'I play piano.' }, { 'text': 'to play piano.' @@ -75,11 +77,7 @@ def test_zh_text_case(self): }, { 'text': '我有一只猫,它是一只猫' }] - tgt_list = [{ - 'text': '小明在 弹奏钢琴' - }, { - 'text': 'Tom在打篮球' - }] + tgt_list = [{'text': '小明在 弹奏钢琴'}, {'text': 'Tom在打篮球'}] dataset = Dataset.from_list(ds_list) op = TextActionFilter(lang='zh') self._run_text_action_filter(dataset, tgt_list, op, ['text']) @@ -95,14 +93,14 @@ def test_image_text_case(self): 'text': f'{SpecialTokens.image}背影{SpecialTokens.eoc}', 'images': [self.img3_path] }, { - 'text': f'雨中行走的女人背影', + 'text': '雨中行走的女人背影', 'images': [self.img3_path] }] tgt_list = [{ 'text': f'{SpecialTokens.image}小猫咪正在睡觉。{SpecialTokens.eoc}', 'images': [self.cat_path] }, { - 'text': f'雨中行走的女人背影', + 'text': '雨中行走的女人背影', 'images': [self.img3_path] }] @@ -110,5 +108,6 @@ def test_image_text_case(self): op = TextActionFilter(lang='zh') self._run_text_action_filter(dataset, tgt_list, op, ['text', 'images']) + if __name__ == '__main__': unittest.main() diff --git a/tests/ops/filter/test_text_entity_dependency_filter.py b/tests/ops/filter/test_text_entity_dependency_filter.py index a9daef1c1..6247318f7 100644 --- a/tests/ops/filter/test_text_entity_dependency_filter.py +++ b/tests/ops/filter/test_text_entity_dependency_filter.py @@ -1,14 +1,16 @@ -import unittest import os +import unittest from datasets import Dataset -from data_juicer.ops.filter.text_entity_dependency_filter import TextEntityDependencyFilter +from data_juicer.ops.filter.text_entity_dependency_filter import \ + TextEntityDependencyFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TextEntityDependencyFilterTest(unittest.TestCase): +class TextEntityDependencyFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'data') @@ -16,7 +18,8 @@ class TextEntityDependencyFilterTest(unittest.TestCase): cat_path = os.path.join(data_path, 'cat.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_text_entity_denpendency_filter(self, dataset: Dataset, target_list, op, column_names): + def _run_text_entity_denpendency_filter(self, dataset: Dataset, + target_list, op, column_names): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -34,7 +37,7 @@ def test_en_text_case(self): 'text': 'Tom is playing piano.' }, { 'text': 'piano.' - },{ + }, { 'text': 'a green tree', }, { 'text': 'tree', @@ -50,7 +53,8 @@ def test_en_text_case(self): }] dataset = Dataset.from_list(ds_list) op = TextEntityDependencyFilter(lang='en', any_or_all='any') - self._run_text_entity_denpendency_filter(dataset, tgt_list, op, ['text']) + self._run_text_entity_denpendency_filter(dataset, tgt_list, op, + ['text']) def test_zh_text_case(self): @@ -67,16 +71,11 @@ def test_zh_text_case(self): }, { 'text': '书。山。星星。土豆。' }] - tgt_list = [{ - 'text': '她在笑' - }, { - 'text': '枯藤老树昏鸦' - }, { - 'text': '一只会上树的猫' - }] + tgt_list = [{'text': '她在笑'}, {'text': '枯藤老树昏鸦'}, {'text': '一只会上树的猫'}] dataset = Dataset.from_list(ds_list) op = TextEntityDependencyFilter(lang='zh', any_or_all='all') - self._run_text_entity_denpendency_filter(dataset, tgt_list, op, ['text']) + self._run_text_entity_denpendency_filter(dataset, tgt_list, op, + ['text']) def test_image_text_case(self): ds_list = [{ @@ -89,20 +88,22 @@ def test_image_text_case(self): 'text': f'{SpecialTokens.image}背影{SpecialTokens.eoc}', 'images': [self.img3_path] }, { - 'text': f'撑着伞的女人背影', + 'text': '撑着伞的女人背影', 'images': [self.img3_path] }] tgt_list = [{ 'text': f'{SpecialTokens.image}三只缩成一团的小猫咪。{SpecialTokens.eoc}', 'images': [self.cat_path] }, { - 'text': f'撑着伞的女人背影', + 'text': '撑着伞的女人背影', 'images': [self.img3_path] }] dataset = Dataset.from_list(ds_list) op = TextEntityDependencyFilter(lang='zh', any_or_all='any') - self._run_text_entity_denpendency_filter(dataset, tgt_list, op, ['text', 'images']) + self._run_text_entity_denpendency_filter(dataset, tgt_list, op, + ['text', 'images']) + if __name__ == '__main__': unittest.main() diff --git a/tests/ops/filter/test_text_length_filter.py b/tests/ops/filter/test_text_length_filter.py index 1ff93e422..cb5df982b 100644 --- a/tests/ops/filter/test_text_length_filter.py +++ b/tests/ops/filter/test_text_length_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.text_length_filter import TextLengthFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TextLengthFilterTest(unittest.TestCase): +class TextLengthFilterTest(DataJuicerTestCaseBase): def _run_text_length_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_token_num_filter.py b/tests/ops/filter/test_token_num_filter.py index a830e91fe..514ce21c3 100644 --- a/tests/ops/filter/test_token_num_filter.py +++ b/tests/ops/filter/test_token_num_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.token_num_filter import TokenNumFilter from data_juicer.utils.constant import Fields, StatsKeys +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class WordNumFilterTest(unittest.TestCase): +class WordNumFilterTest(DataJuicerTestCaseBase): def test_token_num(self): src = [ diff --git a/tests/ops/filter/test_video_aesthetics_filter.py b/tests/ops/filter/test_video_aesthetics_filter.py new file mode 100644 index 000000000..afa6a3f0e --- /dev/null +++ b/tests/ops/filter/test_video_aesthetics_filter.py @@ -0,0 +1,244 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_aesthetics_filter import \ + VideoAestheticsFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoAestheticsFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + # vid-low: keyframes -- 0.410, uniform-3 -- 0.410, uniform-5 -- 0.406 + # vid-mid: keyframes -- 0.448, uniform-3 -- 0.419, uniform-5 -- 0.449 + # vid-high: keyframes -- 0.468, uniform-3 -- 0.474, uniform-5 -- 0.480 + vid_low_path = os.path.join(data_path, 'video4.mp4') + vid_mid_path = os.path.join(data_path, 'video1.mp4') + vid_high_path = os.path.join(data_path, 'video3.mp4') + vid_low_text = ( + f'{SpecialTokens.video} [[q]]: Can you summarize what the girls ' + f'are doing in the video?\n", "[[a]]: Sure. The video shows a girl' + f' brushing the hair of another girl who keeps moving her face ' + f'around while the first girl keeps brushing the hair.' + f'{SpecialTokens.eoc}') + vid_mid_text = (f'{SpecialTokens.video} 白色的小羊站在一旁讲话。' + f'旁边还有两只灰色猫咪和一只拉着灰狼的猫咪' + f'{SpecialTokens.eoc}') + vid_high_text = (f'两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}') + + hf_aesthetics_scorer = \ + 'shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE' + + @classmethod + def tearDownClass(cls) -> None: + super().tearDownClass(cls.hf_aesthetics_scorer) + + def _run_video_aesthetics_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_low_path] + }, { + 'videos': [self.vid_mid_path] + }, { + 'videos': [self.vid_high_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_large_score_videos(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_low_path] + }, { + 'videos': [self.vid_mid_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, max_score=0.45) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_small_score_videos(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_mid_path] + }, { + 'videos': [self.vid_high_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, min_score=0.415) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range_keyframes(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{'videos': [self.vid_mid_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.47) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_keyframes(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [ + { + 'videos': [self.vid_mid_path] + }, + ] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.411, + max_score=0.45, + frame_sampling_method='keyframe') + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_uniform_frames_with_different_frame_num(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{'videos': [self.vid_mid_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.41, + max_score=0.48, + frame_sampling_method='uniform', + frame_num=5) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_any(self): + ds_list = [{ + 'videos': [self.vid_low_path, self.vid_mid_path], + 'text': self.vid_low_text + self.vid_mid_text, + }, { + 'videos': [self.vid_mid_path, self.vid_high_path], + 'text': self.vid_mid_text + self.vid_high_text, + }, { + 'videos': [self.vid_low_path, self.vid_high_path], + 'text': self.vid_low_text + self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_low_path, self.vid_mid_path] + }, { + 'videos': [self.vid_mid_path, self.vid_high_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.45, + any_or_all='any') + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_all(self): + ds_list = [{ + 'videos': [self.vid_low_path, self.vid_mid_path], + 'text': self.vid_low_text + self.vid_mid_text, + }, { + 'videos': [self.vid_mid_path, self.vid_high_path], + 'text': self.vid_mid_text + self.vid_high_text, + }, { + 'videos': [self.vid_low_path, self.vid_high_path], + 'text': self.vid_low_text + self.vid_high_text, + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.45, + any_or_all='all') + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{'videos': [self.vid_mid_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter( + self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.45, + ) + self._run_video_aesthetics_filter(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_aspect_ratio_filter.py b/tests/ops/filter/test_video_aspect_ratio_filter.py new file mode 100644 index 000000000..b07844097 --- /dev/null +++ b/tests/ops/filter/test_video_aspect_ratio_filter.py @@ -0,0 +1,106 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_aspect_ratio_filter import \ + VideoAspectRatioFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoAspectRatioFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # 640x360, 16:9 + vid2_path = os.path.join(data_path, 'video2.mp4') # 480x640, 3:4 + vid3_path = os.path.join(data_path, 'video3.mp4') # 362x640, 181:320 + + def _run_op(self, dataset: Dataset, target_list, op, np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_params(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter() + self._run_op(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter(min_ratio='3/4', + max_ratio='16/9', + any_or_all='any') + self._run_op(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path, self.vid2_path]}] + + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter(min_ratio='3/4', + max_ratio='16/9', + any_or_all='all') + self._run_op(dataset, tgt_list, op) + + def test_parallel(self): + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}, {'videos': [self.vid2_path]}] + + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter(min_ratio='3/4', max_ratio='16/9') + self._run_op(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_duration_filter.py b/tests/ops/filter/test_video_duration_filter.py new file mode 100644 index 000000000..2954836bf --- /dev/null +++ b/tests/ops/filter/test_video_duration_filter.py @@ -0,0 +1,147 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_duration_filter import VideoDurationFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoDurationFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # about 12s + vid2_path = os.path.join(data_path, 'video2.mp4') # about 23s + vid3_path = os.path.join(data_path, 'video3.mp4') # about 50s + + def _run_video_duration_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter() + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_long_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(max_duration=15) + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_short_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=30) + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=16, max_duration=42) + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=15, + max_duration=30, + any_or_all='any') + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=15, + max_duration=30, + any_or_all='all') + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=15, max_duration=30) + self._run_video_duration_filter(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_frames_text_similarity_filter.py b/tests/ops/filter/test_video_frames_text_similarity_filter.py new file mode 100644 index 000000000..04e7355e5 --- /dev/null +++ b/tests/ops/filter/test_video_frames_text_similarity_filter.py @@ -0,0 +1,274 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_frames_text_similarity_filter import \ + VideoFramesTextSimilarityFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoFramesTextSimilarityFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + # vid1: keyframes -- 0.2515, uniform-2 -- 0.2378, uniform-3 -- 0.2342 + # vid2: keyframes -- 0.2686, uniform-2 -- 0.2741, uniform-3 -- 0.2697 + # vid3: keyframes -- 0.3020, uniform-2 -- 0.3044, uniform-3 -- 0.2998 + vid1_path = os.path.join(data_path, 'video1.mp4') + vid2_path = os.path.join(data_path, 'video2.mp4') + vid3_path = os.path.join(data_path, 'video3.mp4') + + hf_clip = 'openai/clip-vit-base-patch32' + + @classmethod + def tearDownClass(cls) -> None: + super().tearDownClass(cls.hf_clip) + + def _run_video_frames_text_similarity_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_large_score_videos(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid1_path]}, {'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, max_score=0.3) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_small_score_videos(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}, {'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, min_score=0.26) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range_keyframes(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_uniform_frames(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}, {'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform') + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_uniform_frames_with_different_frame_num(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform', + frame_num=2) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} {SpecialTokens.video} 身穿白色上衣的男子,' + f'拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}', + }, { + 'videos': [self.vid2_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }, { + 'videos': [self.vid1_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform', + frame_num=2, + any_or_all='any') + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_all(self): + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} {SpecialTokens.video} 身穿白色上衣的男子,' + f'拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}', + }, { + 'videos': [self.vid2_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }, { + 'videos': [self.vid1_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform', + frame_num=2, + any_or_all='all') + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter( + self.hf_clip, + min_score=0.26, + max_score=0.3, + ) + self._run_video_frames_text_similarity_filter(dataset, + tgt_list, + op, + np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_motion_score_filter.py b/tests/ops/filter/test_video_motion_score_filter.py new file mode 100644 index 000000000..0c7ce3f5d --- /dev/null +++ b/tests/ops/filter/test_video_motion_score_filter.py @@ -0,0 +1,140 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_motion_score_filter import \ + VideoMotionScoreFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoMotionScoreFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # 1.8210126 + vid2_path = os.path.join(data_path, 'video2.mp4') # 3.600746 + vid3_path = os.path.join(data_path, 'video3.mp4') # 1.1822891 + + def _run_helper(self, op, source_list, target_list, np=1): + dataset = Dataset.from_list(source_list) + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + op = VideoMotionScoreFilter() + self._run_helper(op, ds_list, tgt_list) + + def test_high(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + op = VideoMotionScoreFilter(min_score=3.0) + self._run_helper(op, ds_list, tgt_list) + + def test_low(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + op = VideoMotionScoreFilter(min_score=0.0, max_score=1.50) + self._run_helper(op, ds_list, tgt_list) + + def test_middle(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + op = VideoMotionScoreFilter(min_score=1.5, max_score=3.0) + self._run_helper(op, ds_list, tgt_list) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + op = VideoMotionScoreFilter(min_score=1.5, + max_score=3.0, + any_or_all='any') + self._run_helper(op, ds_list, tgt_list) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + op = VideoMotionScoreFilter(min_score=1.5, + max_score=3.0, + any_or_all='all') + self._run_helper(op, ds_list, tgt_list) + + def test_parallel(self): + import multiprocess as mp + mp.set_start_method('forkserver', force=True) + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + op = VideoMotionScoreFilter(min_score=1.5, max_score=3.0) + self._run_helper(op, ds_list, tgt_list, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_ocr_area_ratio_filter.py b/tests/ops/filter/test_video_ocr_area_ratio_filter.py new file mode 100644 index 000000000..420094d2b --- /dev/null +++ b/tests/ops/filter/test_video_ocr_area_ratio_filter.py @@ -0,0 +1,157 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_ocr_area_ratio_filter import \ + VideoOcrAreaRatioFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoOcrAreaRatioFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # about 0.067 + vid2_path = os.path.join(data_path, 'video2.mp4') # about 0.288 + vid3_path = os.path.join(data_path, 'video3.mp4') # about 0.075 + + def _run_video_ocr_area_ratio_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter() + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_large_ratio_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}, {'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(max_area_ratio=0.1) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_small_ratio_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.2) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, max_area_ratio=0.1) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, + max_area_ratio=0.1, + any_or_all='any') + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, + max_area_ratio=0.1, + any_or_all='all') + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + # WARNING: current parallel tests only work in spawn method + import multiprocess + original_method = multiprocess.get_start_method() + multiprocess.set_start_method('spawn', force=True) + # WARNING: current parallel tests only work in spawn method + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, max_area_ratio=0.1) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op, np=2) + + # WARNING: current parallel tests only work in spawn method + multiprocess.set_start_method(original_method, force=True) + # WARNING: current parallel tests only work in spawn method + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_resolution_filter.py b/tests/ops/filter/test_video_resolution_filter.py new file mode 100644 index 000000000..210662a3e --- /dev/null +++ b/tests/ops/filter/test_video_resolution_filter.py @@ -0,0 +1,151 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_resolution_filter import \ + VideoResolutionFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoResolutionFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + # video1: horizontal resolution 640p, vertical resolution 360p + # video2: horizontal resolution 480p, vertical resolution 640p + # video3: horizontal resolution 362p, vertical resolution 640p + vid1_path = os.path.join(data_path, 'video1.mp4') + vid2_path = os.path.join(data_path, 'video2.mp4') + vid3_path = os.path.join(data_path, 'video3.mp4') + + def _run_video_resolution_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter() + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_low_resolution_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=480, min_height=480) + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_high_resolution_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(max_width=640, max_height=480) + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, max_width=500) + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, + max_width=500, + any_or_all='any') + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, + max_width=500, + any_or_all='all') + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, max_width=500) + self._run_video_resolution_filter(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_word_num_filter.py b/tests/ops/filter/test_word_num_filter.py index d4ee8b239..6a4967f97 100644 --- a/tests/ops/filter/test_word_num_filter.py +++ b/tests/ops/filter/test_word_num_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.word_num_filter import WordNumFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class WordNumFilterTest(unittest.TestCase): +class WordNumFilterTest(DataJuicerTestCaseBase): def _run_word_num_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_word_repetition_filter.py b/tests/ops/filter/test_word_repetition_filter.py index 53435fd70..cf5f02330 100644 --- a/tests/ops/filter/test_word_repetition_filter.py +++ b/tests/ops/filter/test_word_repetition_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.word_repetition_filter import WordRepetitionFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class WordRepetitionFilterTest(unittest.TestCase): +class WordRepetitionFilterTest(DataJuicerTestCaseBase): def _run_word_repetition_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py b/tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py new file mode 100644 index 000000000..4ee4fdd61 --- /dev/null +++ b/tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py @@ -0,0 +1,60 @@ +import os +import unittest + +import librosa +from datasets import Dataset + +from data_juicer.ops.mapper.audio_ffmpeg_wrapped_mapper import \ + AudioFFmpegWrappedMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class AudioFFmpegWrappedMapperTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + aud1_path = os.path.join(data_path, 'audio1.wav') # 5.501678004535147 + aud2_path = os.path.join(data_path, 'audio2.wav') # 14.142426303854876 + aud3_path = os.path.join(data_path, 'audio3.ogg') # 119.87591836734694 + + def _run_op(self, ds_list, target_list, op, np=1): + dataset = Dataset.from_list(ds_list) + dataset = dataset.map(op.process, num_proc=np) + + def get_size(dataset): + durations = [] + res_list = dataset.to_list() + for sample in res_list: + sample_durations = [] + for aud_path in sample['audios']: + sample_durations.append( + librosa.get_duration(path=aud_path)) + durations.append(sample_durations) + return durations + + sizes = get_size(dataset) + self.assertEqual(sizes, target_list) + + def test_resize(self): + ds_list = [{ + 'audios': [self.aud1_path, self.aud2_path, self.aud3_path] + }] + tgt_list = [[5.501678004535147, 6.0, 6.0]] + op = AudioFFmpegWrappedMapper('atrim', + filter_kwargs={'end': 6}, + capture_stderr=False) + self._run_op(ds_list, tgt_list, op) + + def test_resize_parallel(self): + ds_list = [{ + 'audios': [self.aud1_path, self.aud2_path, self.aud3_path] + }] + tgt_list = [[5.501678004535147, 6.0, 6.0]] + op = AudioFFmpegWrappedMapper('atrim', + filter_kwargs={'end': 6}, + capture_stderr=False) + self._run_op(ds_list, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/mapper/test_chinese_convert_mapper.py b/tests/ops/mapper/test_chinese_convert_mapper.py index fd35bbbb1..9bbe8e8df 100644 --- a/tests/ops/mapper/test_chinese_convert_mapper.py +++ b/tests/ops/mapper/test_chinese_convert_mapper.py @@ -1,9 +1,10 @@ import unittest from data_juicer.ops.mapper.chinese_convert_mapper import ChineseConvertMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ChineseConvertMapperTest(unittest.TestCase): +class ChineseConvertMapperTest(DataJuicerTestCaseBase): def setUp(self, mode='s2t'): self.op = ChineseConvertMapper(mode) diff --git a/tests/ops/mapper/test_clean_copyright_mapper.py b/tests/ops/mapper/test_clean_copyright_mapper.py index 302942d26..726d829f7 100644 --- a/tests/ops/mapper/test_clean_copyright_mapper.py +++ b/tests/ops/mapper/test_clean_copyright_mapper.py @@ -1,9 +1,10 @@ import unittest from data_juicer.ops.mapper.clean_copyright_mapper import CleanCopyrightMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CleanCopyrightMapperTest(unittest.TestCase): +class CleanCopyrightMapperTest(DataJuicerTestCaseBase): def setUp(self): self.op = CleanCopyrightMapper() diff --git a/tests/ops/mapper/test_clean_email_mapper.py b/tests/ops/mapper/test_clean_email_mapper.py index 9e20aede9..b3f0e5e9a 100644 --- a/tests/ops/mapper/test_clean_email_mapper.py +++ b/tests/ops/mapper/test_clean_email_mapper.py @@ -1,9 +1,10 @@ import unittest from data_juicer.ops.mapper.clean_email_mapper import CleanEmailMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CleanEmailMapperTest(unittest.TestCase): +class CleanEmailMapperTest(DataJuicerTestCaseBase): def _run_clean_email(self, op, samples): for sample in samples: @@ -45,6 +46,7 @@ def test_replace_email(self): }] op = CleanEmailMapper(repl='')
self._run_clean_email(op, samples)
-
+
+
if __name__ == '__main__':
unittest.main()
diff --git a/tests/ops/mapper/test_clean_html_mapper.py b/tests/ops/mapper/test_clean_html_mapper.py
index ecab4114d..69249b60a 100644
--- a/tests/ops/mapper/test_clean_html_mapper.py
+++ b/tests/ops/mapper/test_clean_html_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.clean_html_mapper import CleanHtmlMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class CleanHtmlMapperTest(unittest.TestCase):
+class CleanHtmlMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = CleanHtmlMapper()
diff --git a/tests/ops/mapper/test_clean_ip_mapper.py b/tests/ops/mapper/test_clean_ip_mapper.py
index 85d61c569..ccbaf52b7 100644
--- a/tests/ops/mapper/test_clean_ip_mapper.py
+++ b/tests/ops/mapper/test_clean_ip_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.clean_ip_mapper import CleanIpMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class CleanIpMapperTest(unittest.TestCase):
+class CleanIpMapperTest(DataJuicerTestCaseBase):
def _run_clean_ip(self, op, samples):
for sample in samples:
@@ -63,5 +64,7 @@ def test_replace_ipv4(self):
}]
op = CleanIpMapper(repl='')
self._run_clean_ip(op, samples)
+
+
if __name__ == '__main__':
unittest.main()
diff --git a/tests/ops/mapper/test_clean_links_mapper.py b/tests/ops/mapper/test_clean_links_mapper.py
index 5c22e7ccd..28e14b2d9 100644
--- a/tests/ops/mapper/test_clean_links_mapper.py
+++ b/tests/ops/mapper/test_clean_links_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.clean_links_mapper import CleanLinksMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class CleanLinksMapperTest(unittest.TestCase):
+class CleanLinksMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = CleanLinksMapper()
@@ -216,22 +217,28 @@ def test_no_link_text(self):
def test_replace_links_text(self):
- samples = [{
- 'text': 'ftp://user:password@ftp.example.com:21/',
- 'target': ''
- }, {
- 'text': 'This is a sample for test',
- 'target': 'This is a sample for test',
- }, {
- 'text': 'abcd://ef is a sample for test',
- 'target': ' is a sample for test',
- }, {
+ samples = [
+ {
+ 'text': 'ftp://user:password@ftp.example.com:21/',
+ 'target': ''
+ },
+ {
+ 'text': 'This is a sample for test',
+ 'target': 'This is a sample for test',
+ },
+ {
+ 'text': 'abcd://ef is a sample for test',
+ 'target': ' is a sample for test',
+ },
+ {
'text':
'HTTP://example.com/my-page.html?param1=value1¶m2=value2',
'target': ''
- },]
+ },
+ ]
op = CleanLinksMapper(repl='')
self._run_clean_links(op, samples)
+
if __name__ == '__main__':
unittest.main()
diff --git a/tests/ops/mapper/test_exapnd_macro_mapper.py b/tests/ops/mapper/test_exapnd_macro_mapper.py
index 3cdc8a0c1..68dbf047b 100644
--- a/tests/ops/mapper/test_exapnd_macro_mapper.py
+++ b/tests/ops/mapper/test_exapnd_macro_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.expand_macro_mapper import ExpandMacroMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class ExpandMacroMapperTest(unittest.TestCase):
+class ExpandMacroMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = ExpandMacroMapper()
diff --git a/tests/ops/mapper/test_fix_unicode_mapper.py b/tests/ops/mapper/test_fix_unicode_mapper.py
index f77e53eb7..547020b51 100644
--- a/tests/ops/mapper/test_fix_unicode_mapper.py
+++ b/tests/ops/mapper/test_fix_unicode_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.fix_unicode_mapper import FixUnicodeMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class FixUnicodeMapperTest(unittest.TestCase):
+class FixUnicodeMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = FixUnicodeMapper()
diff --git a/tests/ops/mapper/test_image_blur_mapper.py b/tests/ops/mapper/test_image_blur_mapper.py
index c0885e295..632c1978b 100644
--- a/tests/ops/mapper/test_image_blur_mapper.py
+++ b/tests/ops/mapper/test_image_blur_mapper.py
@@ -1,25 +1,23 @@
import os
import unittest
-import numpy as np
+import numpy as np
from datasets import Dataset
-from data_juicer.utils.mm_utils import load_image
from data_juicer.ops.mapper.image_blur_mapper import ImageBlurMapper
+from data_juicer.utils.mm_utils import load_image
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class ImageBlurMapperTest(unittest.TestCase):
+class ImageBlurMapperTest(DataJuicerTestCaseBase):
- data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)),
- '..', 'data')
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
img1_path = os.path.join(data_path, 'img1.png')
img2_path = os.path.join(data_path, 'img2.jpg')
img3_path = os.path.join(data_path, 'img3.jpg')
- def _get_blured_img_path(self, path):
- return os.path.join(os.path.dirname(path), '_blured.'.join(os.path.basename(path).split('.')))
-
- def _get_blur_kernel(self, blur_type = 'gaussian', radius = 2):
+ def _get_blur_kernel(self, blur_type='gaussian', radius=2):
from PIL import ImageFilter
if blur_type == 'mean':
return ImageFilter.BLUR
@@ -28,11 +26,10 @@ def _get_blur_kernel(self, blur_type = 'gaussian', radius = 2):
else:
return ImageFilter.GaussianBlur(radius)
- def _run_image_blur_mapper(self, op, source_list, target_list, blur_kernel):
+ def _run_image_blur_mapper(self, op, source_list, blur_kernel):
dataset = Dataset.from_list(source_list)
dataset = dataset.map(op.process)
res_list = dataset.to_list()
- self.assertEqual(res_list, target_list)
for source, res in zip(source_list, res_list):
for s_path, r_path in zip(source[op.image_key], res[op.image_key]):
s_img = load_image(s_path).convert('RGB').filter(blur_kernel)
@@ -51,16 +48,9 @@ def test(self):
}, {
'images': [self.img3_path]
}]
- tgt_list = [{
- 'images': [self._get_blured_img_path(self.img1_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img2_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img3_path)]
- }]
- op = ImageBlurMapper(p = 1, blur_type = 'gaussian', radius = 2)
+ op = ImageBlurMapper(p=1, blur_type='gaussian', radius=2)
blur_kernel = self._get_blur_kernel('gaussian', 2)
- self._run_image_blur_mapper(op, ds_list, tgt_list, blur_kernel)
+ self._run_image_blur_mapper(op, ds_list, blur_kernel)
def test_blur_type(self):
ds_list = [{
@@ -70,16 +60,9 @@ def test_blur_type(self):
}, {
'images': [self.img1_path]
}]
- tgt_list = [{
- 'images': [self._get_blured_img_path(self.img2_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img3_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img1_path)]
- }]
- op = ImageBlurMapper(p = 1, blur_type = 'box', radius = 2)
+ op = ImageBlurMapper(p=1, blur_type='box', radius=2)
blur_kernel = self._get_blur_kernel('box', 2)
- self._run_image_blur_mapper(op, ds_list, tgt_list, blur_kernel)
+ self._run_image_blur_mapper(op, ds_list, blur_kernel)
def test_radius(self):
ds_list = [{
@@ -89,16 +72,9 @@ def test_radius(self):
}, {
'images': [self.img1_path]
}]
- tgt_list = [{
- 'images': [self._get_blured_img_path(self.img3_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img2_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img1_path)]
- }]
- op = ImageBlurMapper(p = 1, blur_type = 'gaussian', radius = 5)
+ op = ImageBlurMapper(p=1, blur_type='gaussian', radius=5)
blur_kernel = self._get_blur_kernel('gaussian', 5)
- self._run_image_blur_mapper(op, ds_list, tgt_list, blur_kernel)
+ self._run_image_blur_mapper(op, ds_list, blur_kernel)
def test_multi_img(self):
ds_list = [{
@@ -108,16 +84,9 @@ def test_multi_img(self):
}, {
'images': [self.img3_path, self.img1_path]
}]
- tgt_list = [{
- 'images': [self._get_blured_img_path(self.img1_path), self._get_blured_img_path(self.img2_path), self._get_blured_img_path(self.img3_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img2_path)]
- }, {
- 'images': [self._get_blured_img_path(self.img3_path), self._get_blured_img_path(self.img1_path)]
- }]
- op = ImageBlurMapper(p = 1, blur_type = 'gaussian', radius = 2)
+ op = ImageBlurMapper(p=1, blur_type='gaussian', radius=2)
blur_kernel = self._get_blur_kernel('gaussian', 2)
- self._run_image_blur_mapper(op, ds_list, tgt_list, blur_kernel)
+ self._run_image_blur_mapper(op, ds_list, blur_kernel)
if __name__ == '__main__':
diff --git a/tests/ops/mapper/test_image_captioning_mapper.py b/tests/ops/mapper/test_image_captioning_mapper.py
new file mode 100644
index 000000000..56d48621f
--- /dev/null
+++ b/tests/ops/mapper/test_image_captioning_mapper.py
@@ -0,0 +1,243 @@
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset
+from data_juicer.ops.mapper.image_captioning_mapper import \
+ ImageCaptioningMapper
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import (SKIPPED_TESTS,
+ DataJuicerTestCaseBase)
+
+
+# Skip tests for this OP in the GitHub actions due to disk space limitation.
+# These tests have been tested locally.
+@SKIPPED_TESTS.register_module()
+class ImageCaptioningMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+
+ cat_path = os.path.join(data_path, 'cat.jpg')
+ img3_path = os.path.join(data_path, 'img3.jpg')
+
+ hf_img2seq = 'Salesforce/blip2-opt-2.7b'
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ super().tearDownClass(cls.hf_img2seq)
+
+ def _run_mapper(self,
+ dataset: NestedDataset,
+ op,
+ num_proc=1,
+ caption_num=0):
+
+ dataset = dataset.map(op.process, num_proc=num_proc, with_rank=True)
+ dataset_list = dataset.select_columns(column_names=['text']).to_list()
+ # assert the caption is generated successfully in terms of not_none
+ # as the generated content is not deterministic
+ self.assertEqual(len(dataset_list), caption_num)
+
+ def test_no_eoc_special_token(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 1
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any')
+ self._run_mapper(dataset, op, caption_num=len(dataset) * 2)
+
+ def test_eoc_special_token(self):
+
+ ds_list = [
+ {
+ 'text':
+ f'{SpecialTokens.image}a photo of a cat{SpecialTokens.eoc}',
+ 'images': [self.cat_path]
+ },
+ {
+ 'text':
+ f'{SpecialTokens.image}a photo, a women with an umbrella{SpecialTokens.eoc}', # noqa: E501
+ 'images': [self.img3_path]
+ }
+ ]
+ caption_num = 1
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any')
+ self._run_mapper(dataset, op, caption_num=len(dataset) * 2)
+
+ def test_multi_candidate_keep_random_any(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 4
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any')
+ self._run_mapper(dataset, op, caption_num=len(dataset) * 2)
+
+ def test_multi_candidate_keep_all(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 4
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='all')
+ self._run_mapper(dataset,
+ op,
+ caption_num=(1 + caption_num) * len(dataset))
+
+ def test_multi_candidate_keep_similar_one(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 4
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='similar_one_simhash')
+ self._run_mapper(dataset, op, caption_num=len(dataset) * 2)
+
+ def test_multi_process(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }] * 10
+ caption_num = 1
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any')
+ self._run_mapper(dataset, op, num_proc=4, caption_num=len(dataset) * 2)
+
+ def test_no_eoc_special_token_remove_original_sample(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 1
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any',
+ keep_original_sample=False)
+ self._run_mapper(dataset, op, caption_num=len(dataset))
+
+ def test_eoc_special_token_remove_original_sample(self):
+
+ ds_list = [
+ {
+ 'text':
+ f'{SpecialTokens.image}a photo of a cat{SpecialTokens.eoc}',
+ 'images': [self.cat_path]
+ },
+ {
+ 'text':
+ f'{SpecialTokens.image}a photo, a women with an umbrella{SpecialTokens.eoc}', # noqa: E501
+ 'images': [self.img3_path]
+ }
+ ]
+ caption_num = 1
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any',
+ keep_original_sample=False)
+ self._run_mapper(dataset, op, caption_num=len(dataset))
+
+ def test_multi_candidate_keep_random_any_remove_original_sample(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 4
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any',
+ keep_original_sample=False)
+ self._run_mapper(dataset, op, caption_num=len(dataset))
+
+ def test_multi_candidate_keep_all_remove_original_sample(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 4
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='all',
+ keep_original_sample=False)
+ self._run_mapper(dataset, op, caption_num=caption_num * len(dataset))
+
+ def test_multi_candidate_keep_similar_one_remove_original_sample(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }, {
+ 'text': f'{SpecialTokens.image}a photo, a women with an umbrella',
+ 'images': [self.img3_path]
+ }]
+ caption_num = 4
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='similar_one_simhash',
+ keep_original_sample=False)
+ self._run_mapper(dataset, op, caption_num=len(dataset))
+
+ def test_multi_process_remove_original_sample(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.image}a photo of a cat',
+ 'images': [self.cat_path]
+ }] * 10
+ caption_num = 1
+ dataset = NestedDataset.from_list(ds_list)
+ op = ImageCaptioningMapper(hf_img2seq=self.hf_img2seq,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any',
+ keep_original_sample=False)
+ self._run_mapper(dataset, op, num_proc=4, caption_num=len(dataset))
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_image_diffusion_mapper.py b/tests/ops/mapper/test_image_diffusion_mapper.py
index 30bf3b7d3..bdc0d0ea4 100644
--- a/tests/ops/mapper/test_image_diffusion_mapper.py
+++ b/tests/ops/mapper/test_image_diffusion_mapper.py
@@ -2,11 +2,13 @@
import shutil
import unittest
+from data_juicer import _cuda_device_count
from data_juicer.core.data import NestedDataset
-from data_juicer.ops.mapper.image_diffusion_mapper import \
- ImageDiffusionMapper
+from data_juicer.ops.mapper.image_diffusion_mapper import ImageDiffusionMapper
from data_juicer.utils.mm_utils import SpecialTokens
-from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase, SKIPPED_TESTS
+from data_juicer.utils.unittest_utils import (SKIPPED_TESTS,
+ DataJuicerTestCaseBase)
+
# Skip tests for this OP in the GitHub actions due to disk space limitation.
# These tests have been tested locally.
@@ -20,7 +22,7 @@ class ImageDiffusionMapperTest(DataJuicerTestCaseBase):
img3_path = os.path.join(data_path, 'img3.jpg')
hf_diffusion = 'CompVis/stable-diffusion-v1-4'
- hf_blip2 = 'Salesforce/blip2-opt-2.7b'
+ hf_img2seq = 'Salesforce/blip2-opt-2.7b'
# dir to save the images produced in the tests
output_dir = '../diffusion_output/'
@@ -28,12 +30,18 @@ class ImageDiffusionMapperTest(DataJuicerTestCaseBase):
@classmethod
def tearDownClass(cls) -> None:
super().tearDownClass(cls.hf_diffusion)
- super().tearDownClass(cls.hf_blip2)
+ super().tearDownClass(cls.hf_img2seq)
- def _run_mapper(self, dataset: NestedDataset, op, move_to_dir, num_proc=1, total_num=1):
+ def _run_mapper(self,
+ dataset: NestedDataset,
+ op,
+ move_to_dir,
+ num_proc=1,
+ total_num=1):
dataset = dataset.map(op.process, num_proc=num_proc, with_rank=True)
- dataset_list = dataset.select_columns(column_names=['images']).to_list()
+ dataset_list = dataset.select_columns(
+ column_names=['images']).to_list()
self.assertEqual(len(dataset_list), total_num)
if not os.path.exists(move_to_dir):
@@ -42,29 +50,27 @@ def _run_mapper(self, dataset: NestedDataset, op, move_to_dir, num_proc=1, total
for image_path in data['images']:
if str(image_path) != str(self.cat_path) \
and str(image_path) != str(self.img3_path):
- move_to_path = os.path.join(move_to_dir, os.path.basename(image_path))
- shutil.move(image_path, move_to_path)
+ cp_to_path = os.path.join(move_to_dir,
+ os.path.basename(image_path))
+ shutil.copyfile(image_path, cp_to_path)
def test_for_strength(self):
ds_list = [{
'text': f'{SpecialTokens.image}a photo of a cat',
- 'caption': f'a women with an umbrella',
+ 'caption': 'a women with an umbrella',
'images': [self.cat_path]
}]
aug_num = 3
dataset = NestedDataset.from_list(ds_list)
- op = ImageDiffusionMapper(
- hf_diffusion=self.hf_diffusion,
- strength=1.0,
- aug_num=aug_num,
- keep_original_sample=True,
- caption_key='caption'
- )
- self._run_mapper(
- dataset, op,
- os.path.join(self.output_dir, 'test_for_strength'),
- total_num=(aug_num+1)*len(ds_list))
-
+ op = ImageDiffusionMapper(hf_diffusion=self.hf_diffusion,
+ strength=1.0,
+ aug_num=aug_num,
+ keep_original_sample=True,
+ caption_key='caption')
+ self._run_mapper(dataset,
+ op,
+ os.path.join(self.output_dir, 'test_for_strength'),
+ total_num=(aug_num + 1) * len(ds_list))
def test_for_given_caption_list(self):
@@ -76,16 +82,15 @@ def test_for_given_caption_list(self):
aug_num = 2
dataset = NestedDataset.from_list(ds_list)
- op = ImageDiffusionMapper(
- hf_diffusion=self.hf_diffusion,
- aug_num=aug_num,
- keep_original_sample=False,
- caption_key='captions'
- )
- self._run_mapper(
- dataset, op,
- os.path.join(self.output_dir, 'test_for_given_caption_list'),
- total_num=aug_num*len(ds_list))
+ op = ImageDiffusionMapper(hf_diffusion=self.hf_diffusion,
+ aug_num=aug_num,
+ keep_original_sample=False,
+ caption_key='captions')
+ self._run_mapper(dataset,
+ op,
+ os.path.join(self.output_dir,
+ 'test_for_given_caption_list'),
+ total_num=aug_num * len(ds_list))
def test_for_given_caption_string(self):
@@ -99,16 +104,15 @@ def test_for_given_caption_string(self):
aug_num = 1
dataset = NestedDataset.from_list(ds_list)
- op = ImageDiffusionMapper(
- hf_diffusion=self.hf_diffusion,
- aug_num=aug_num,
- keep_original_sample=False,
- caption_key='text'
- )
- self._run_mapper(
- dataset, op,
- os.path.join(self.output_dir, 'test_for_given_caption_string'),
- total_num=aug_num*len(ds_list))
+ op = ImageDiffusionMapper(hf_diffusion=self.hf_diffusion,
+ aug_num=aug_num,
+ keep_original_sample=False,
+ caption_key='text')
+ self._run_mapper(dataset,
+ op,
+ os.path.join(self.output_dir,
+ 'test_for_given_caption_string'),
+ total_num=aug_num * len(ds_list))
def test_for_no_given_caption(self):
@@ -122,16 +126,15 @@ def test_for_no_given_caption(self):
aug_num = 2
dataset = NestedDataset.from_list(ds_list)
- op = ImageDiffusionMapper(
- hf_diffusion=self.hf_diffusion,
- aug_num=aug_num,
- keep_original_sample=False,
- hf_blip2=self.hf_blip2
- )
- self._run_mapper(
- dataset, op,
- os.path.join(self.output_dir, 'test_for_no_given_caption'),
- total_num=aug_num*len(ds_list))
+ op = ImageDiffusionMapper(hf_diffusion=self.hf_diffusion,
+ aug_num=aug_num,
+ keep_original_sample=False,
+ hf_img2seq=self.hf_img2seq)
+ self._run_mapper(dataset,
+ op,
+ os.path.join(self.output_dir,
+ 'test_for_no_given_caption'),
+ total_num=aug_num * len(ds_list))
def test_for_fp16_given_caption_string(self):
@@ -145,17 +148,16 @@ def test_for_fp16_given_caption_string(self):
aug_num = 1
dataset = NestedDataset.from_list(ds_list)
- op = ImageDiffusionMapper(
- hf_diffusion=self.hf_diffusion,
- floating_point='fp16',
- aug_num=aug_num,
- keep_original_sample=False,
- caption_key='text'
- )
- self._run_mapper(
- dataset, op,
- os.path.join(self.output_dir, 'test_for_fp16_given_caption_string'),
- total_num=aug_num*len(ds_list))
+ op = ImageDiffusionMapper(hf_diffusion=self.hf_diffusion,
+ floating_point='fp16',
+ aug_num=aug_num,
+ keep_original_sample=False,
+ caption_key='text')
+ self._run_mapper(dataset,
+ op,
+ os.path.join(self.output_dir,
+ 'test_for_fp16_given_caption_string'),
+ total_num=aug_num * len(ds_list))
def test_for_multi_process_given_caption_string(self):
@@ -169,17 +171,23 @@ def test_for_multi_process_given_caption_string(self):
aug_num = 1
dataset = NestedDataset.from_list(ds_list)
- op = ImageDiffusionMapper(
- hf_diffusion=self.hf_diffusion,
- aug_num=aug_num,
- keep_original_sample=False,
- caption_key='text'
- )
- self._run_mapper(
- dataset, op,
- os.path.join(self.output_dir, 'test_for_given_caption_string'),
- num_proc=2,
- total_num=aug_num*len(ds_list))
+ op = ImageDiffusionMapper(hf_diffusion=self.hf_diffusion,
+ aug_num=aug_num,
+ keep_original_sample=False,
+ caption_key='text')
+
+ # set num_proc <= the number of CUDA if it is available
+ num_proc = 2
+ if _cuda_device_count() == 1:
+ num_proc = 1
+
+ self._run_mapper(dataset,
+ op,
+ os.path.join(self.output_dir,
+ 'test_for_given_caption_string'),
+ num_proc=num_proc,
+ total_num=aug_num * len(ds_list))
+
if __name__ == '__main__':
unittest.main()
diff --git a/tests/ops/mapper/test_nlpaug_en_mapper.py b/tests/ops/mapper/test_nlpaug_en_mapper.py
index fa93e9273..5451ffd7c 100644
--- a/tests/ops/mapper/test_nlpaug_en_mapper.py
+++ b/tests/ops/mapper/test_nlpaug_en_mapper.py
@@ -1,10 +1,13 @@
+# flake8: noqa: E501
+
import unittest
from data_juicer.core import NestedDataset
from data_juicer.ops.mapper.nlpaug_en_mapper import NlpaugEnMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class NlpaugEnMapperTest(unittest.TestCase):
+class NlpaugEnMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.samples = NestedDataset.from_dict({
@@ -119,7 +122,8 @@ def test_all_aug_methods_with_sequential_off(self):
(aug_num * aug_method_num + 1) * len(self.samples))
self.assertEqual(len(result['meta']), len(result['text']))
- def test_number_of_generated_samples_with_sequential_on_remove_original_sample(self):
+ def test_number_of_generated_samples_with_sequential_on_remove_original_sample(
+ self):
aug_num = 3
aug_method_num = 3
op = NlpaugEnMapper(
@@ -132,11 +136,11 @@ def test_number_of_generated_samples_with_sequential_on_remove_original_sample(s
)
self.assertEqual(len(op.aug), aug_method_num)
result = self.samples.map(op.process)
- self.assertEqual(len(result['text']),
- aug_num * len(self.samples))
+ self.assertEqual(len(result['text']), aug_num * len(self.samples))
self.assertEqual(len(result['meta']), len(result['text']))
- def test_number_of_generated_samples_with_sequential_off_remove_original_sample(self):
+ def test_number_of_generated_samples_with_sequential_off_remove_original_sample(
+ self):
aug_num = 3
aug_method_num = 3
op = NlpaugEnMapper(
@@ -201,8 +205,7 @@ def test_all_aug_methods_with_sequential_on_remove_original_sample(self):
)
self.assertEqual(len(op.aug), aug_method_num)
result = self.samples.map(op.process)
- self.assertEqual(len(result['text']),
- aug_num * len(self.samples))
+ self.assertEqual(len(result['text']), aug_num * len(self.samples))
self.assertEqual(len(result['meta']), len(result['text']))
def test_all_aug_methods_with_sequential_off_remove_original_sample(self):
diff --git a/tests/ops/mapper/test_nlpcda_zh_mapper.py b/tests/ops/mapper/test_nlpcda_zh_mapper.py
index 6110f0130..80aa2bf84 100644
--- a/tests/ops/mapper/test_nlpcda_zh_mapper.py
+++ b/tests/ops/mapper/test_nlpcda_zh_mapper.py
@@ -1,10 +1,13 @@
+# flake8: noqa: E501
+
import unittest
from data_juicer.core import NestedDataset
from data_juicer.ops.mapper.nlpcda_zh_mapper import NlpcdaZhMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class NlpaugEnMapperTest(unittest.TestCase):
+class NlpaugEnMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.samples = NestedDataset.from_dict({
@@ -142,7 +145,8 @@ def test_all_aug_methods_with_sequential_off(self):
self.assertGreaterEqual(len(result['text']), len(self.samples['text']))
self.assertEqual(len(result['meta']), len(result['text']))
- def test_number_of_generated_samples_with_sequential_on_remove_original_sample(self):
+ def test_number_of_generated_samples_with_sequential_on_remove_original_sample(
+ self):
aug_num = 3
aug_method_num = 3
op = NlpcdaZhMapper(
@@ -160,7 +164,8 @@ def test_number_of_generated_samples_with_sequential_on_remove_original_sample(s
self.assertGreaterEqual(len(result['text']), len(self.samples['text']))
self.assertEqual(len(result['meta']), len(result['text']))
- def test_number_of_generated_samples_with_sequential_off_remove_original_sample(self):
+ def test_number_of_generated_samples_with_sequential_off_remove_original_sample(
+ self):
aug_num = 3
aug_method_num = 3
op = NlpcdaZhMapper(
@@ -173,9 +178,9 @@ def test_number_of_generated_samples_with_sequential_off_remove_original_sample(
)
self.assertEqual(len(op.aug_pipeline), aug_method_num)
result = self.samples.map(op.process)
- self.assertLessEqual(len(result['text']),
- aug_num * aug_method_num *
- len(self.samples['text']))
+ self.assertLessEqual(
+ len(result['text']),
+ aug_num * aug_method_num * len(self.samples['text']))
self.assertGreaterEqual(len(result['text']), len(self.samples['text']))
self.assertEqual(len(result['meta']), len(result['text']))
@@ -244,9 +249,9 @@ def test_all_aug_methods_with_sequential_off_remove_original_sample(self):
)
self.assertEqual(len(op.aug_pipeline), aug_method_num)
result = self.samples.map(op.process)
- self.assertLessEqual(len(result['text']),
- aug_num * aug_method_num *
- len(self.samples['text']))
+ self.assertLessEqual(
+ len(result['text']),
+ aug_num * aug_method_num * len(self.samples['text']))
self.assertGreaterEqual(len(result['text']), len(self.samples['text']))
self.assertEqual(len(result['meta']), len(result['text']))
diff --git a/tests/ops/mapper/test_punctuation_normalization_mapper.py b/tests/ops/mapper/test_punctuation_normalization_mapper.py
index a114b83b1..a69d4040e 100644
--- a/tests/ops/mapper/test_punctuation_normalization_mapper.py
+++ b/tests/ops/mapper/test_punctuation_normalization_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.punctuation_normalization_mapper import \
PunctuationNormalizationMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class PunctuationNormalizationMapperTest(unittest.TestCase):
+class PunctuationNormalizationMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = PunctuationNormalizationMapper()
diff --git a/tests/ops/mapper/test_remove_bibliography_mapper.py b/tests/ops/mapper/test_remove_bibliography_mapper.py
index 449cb59c7..76096fe93 100644
--- a/tests/ops/mapper/test_remove_bibliography_mapper.py
+++ b/tests/ops/mapper/test_remove_bibliography_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.remove_bibliography_mapper import \
RemoveBibliographyMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveBibliographyMapperTest(unittest.TestCase):
+class RemoveBibliographyMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = RemoveBibliographyMapper()
diff --git a/tests/ops/mapper/test_remove_comments_mapper.py b/tests/ops/mapper/test_remove_comments_mapper.py
index d61494c14..81a0df5de 100644
--- a/tests/ops/mapper/test_remove_comments_mapper.py
+++ b/tests/ops/mapper/test_remove_comments_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.remove_comments_mapper import RemoveCommentsMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveCommentsMapperTest(unittest.TestCase):
+class RemoveCommentsMapperTest(DataJuicerTestCaseBase):
def _run_remove_comments(self, samples, op):
for sample in samples:
diff --git a/tests/ops/mapper/test_remove_header_mapper.py b/tests/ops/mapper/test_remove_header_mapper.py
index ea7170fad..c91bfe790 100644
--- a/tests/ops/mapper/test_remove_header_mapper.py
+++ b/tests/ops/mapper/test_remove_header_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.remove_header_mapper import RemoveHeaderMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveHeaderMapperTest(unittest.TestCase):
+class RemoveHeaderMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = RemoveHeaderMapper()
diff --git a/tests/ops/mapper/test_remove_long_words_mapper.py b/tests/ops/mapper/test_remove_long_words_mapper.py
index 01962e508..533d7a717 100644
--- a/tests/ops/mapper/test_remove_long_words_mapper.py
+++ b/tests/ops/mapper/test_remove_long_words_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.remove_long_words_mapper import \
RemoveLongWordsMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveLongWordsMapperTest(unittest.TestCase):
+class RemoveLongWordsMapperTest(DataJuicerTestCaseBase):
def _run_remove_long_words(self, samples, op):
for sample in samples:
diff --git a/tests/ops/mapper/test_remove_non_chinese_character_mapper.py b/tests/ops/mapper/test_remove_non_chinese_character_mapper.py
index d7c1953c8..283a75ab0 100644
--- a/tests/ops/mapper/test_remove_non_chinese_character_mapper.py
+++ b/tests/ops/mapper/test_remove_non_chinese_character_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.remove_non_chinese_character_mapper import \
RemoveNonChineseCharacterlMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveNonChineseCharacterlMapperrTest(unittest.TestCase):
+class RemoveNonChineseCharacterlMapperrTest(DataJuicerTestCaseBase):
def setUp(self, keep_alphabet=True, keep_number=True, keep_punc=True):
self.op = RemoveNonChineseCharacterlMapper(keep_alphabet, keep_number,
diff --git a/tests/ops/mapper/test_remove_repeat_sentences_mapper.py b/tests/ops/mapper/test_remove_repeat_sentences_mapper.py
index 923ac5824..a7fe347fe 100644
--- a/tests/ops/mapper/test_remove_repeat_sentences_mapper.py
+++ b/tests/ops/mapper/test_remove_repeat_sentences_mapper.py
@@ -1,9 +1,13 @@
+# flake8: noqa: E501
+
import unittest
-from data_juicer.ops.mapper.remove_repeat_sentences_mapper import RemoveRepeatSentencesMapper
+from data_juicer.ops.mapper.remove_repeat_sentences_mapper import \
+ RemoveRepeatSentencesMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveRepeatSentencesMapperTest(unittest.TestCase):
+class RemoveRepeatSentencesMapperTest(DataJuicerTestCaseBase):
def _run_helper(self, samples, op):
for sample in samples:
@@ -12,44 +16,52 @@ def _run_helper(self, samples, op):
def test_text(self):
- samples = [
- {
- 'text': '今天天气真不错,阳光明媚,适合出去散步。小明说:“今天天气真不错,我们去海边吧。” 小红回答说:“好主意!” 但是,小李觉得:“今天天气真不错,我们去爬山吧。” 今天天气真不错,阳光明媚,适合出去散步。昨天下了一整天的雨,今天终于放晴了。昨天下了一整天的雨,今天终于放晴了。',
- 'target': '今天天气真不错,阳光明媚,适合出去散步。小明说:“今天天气真不错,我们去海边吧。” 小红回答说:“好主意!” 但是,小李觉得:“今天天气真不错,我们去爬山吧。”昨天下了一整天的雨,今天终于放晴了。',
- }, {
- 'text': 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? The quick brown fox jumps over the lazy dog. Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? "Let\'s seize the day," Tom exclaimed, full of enthusiasm. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.',
- 'target': 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.'
- }, {
- 'text': '''我很开心 。但是你不开心 。我很开心 。\n你好呀!我很开心 。我好的。你好呀!''',
- 'target': '''我很开心 。但是你不开心 。\n你好呀!我好的。'''
- }, {
- 'text': '默认配置下,长度低于2的句子不会被去重。去重?去重。去重!重。重...... 重! 1234?3215. 1234. 3. 3. 3',
- 'target': '默认配置下,长度低于2的句子不会被去重。去重?重。重...... 重! 1234?3215. 3. 3. 3'
- }
- ]
+ samples = [{
+ 'text':
+ '今天天气真不错,阳光明媚,适合出去散步。小明说:“今天天气真不错,我们去海边吧。” 小红回答说:“好主意!” 但是,小李觉得:“今天天气真不错,我们去爬山吧。” 今天天气真不错,阳光明媚,适合出去散步。昨天下了一整天的雨,今天终于放晴了。昨天下了一整天的雨,今天终于放晴了。',
+ 'target':
+ '今天天气真不错,阳光明媚,适合出去散步。小明说:“今天天气真不错,我们去海边吧。” 小红回答说:“好主意!” 但是,小李觉得:“今天天气真不错,我们去爬山吧。”昨天下了一整天的雨,今天终于放晴了。',
+ }, {
+ 'text':
+ 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? The quick brown fox jumps over the lazy dog. Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? "Let\'s seize the day," Tom exclaimed, full of enthusiasm. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.',
+ 'target':
+ 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.'
+ }, {
+ 'text': '''我很开心 。但是你不开心 。我很开心 。\n你好呀!我很开心 。我好的。你好呀!''',
+ 'target': '''我很开心 。但是你不开心 。\n你好呀!我好的。'''
+ }, {
+ 'text':
+ '默认配置下,长度低于2的句子不会被去重。去重?去重。去重!重。重...... 重! 1234?3215. 1234. 3. 3. 3',
+ 'target':
+ '默认配置下,长度低于2的句子不会被去重。去重?重。重...... 重! 1234?3215. 3. 3. 3'
+ }]
op = RemoveRepeatSentencesMapper()
self._run_helper(samples, op)
def test_text2(self):
- samples = [
- {
- 'text': 'Life is what happens when you\'re busy making other plans. John Lennon once said. Life is what happens when you\'re busy making other plans. This phrase has resonated with many people over the years. 人生就是当你忙于制定其他计划时发生的事情。对很多人来说,这句话引起了共鸣。',
- 'target': 'Life is what happens when you\'re busy making other plans. John Lennon once said. This phrase has resonated with many people over the years. 人生就是当你忙于制定其他计划时发生的事情。对很多人来说,这句话引起了共鸣。',
- }, {
- 'text': 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? The quick brown fox jumps over the lazy dog. Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? "Let\'s seize the day," Tom exclaimed, full of enthusiasm. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.',
- 'target': 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.'
- }, {
- 'text': '''我很开心 。但是你不开心 。我很开心 。\n你好呀!我很开心 。我好的。你好呀!''',
- 'target': '''我很开心 。但是你不开心 。\n你好呀!我好的。你好呀!'''
- }, {
- 'text': '去重?去重。去重!重。重...... 重! 1234?3215. 1234. 3. 3. 3',
- 'target': '去重?去重。去重!重。重...... 重! 1234?3215. 1234. 3. 3. 3'
- }
- ]
-
- op = RemoveRepeatSentencesMapper(lowercase=True, ignore_special_character=False, min_repeat_sentence_length=5)
+ samples = [{
+ 'text':
+ 'Life is what happens when you\'re busy making other plans. John Lennon once said. Life is what happens when you\'re busy making other plans. This phrase has resonated with many people over the years. 人生就是当你忙于制定其他计划时发生的事情。对很多人来说,这句话引起了共鸣。',
+ 'target':
+ 'Life is what happens when you\'re busy making other plans. John Lennon once said. This phrase has resonated with many people over the years. 人生就是当你忙于制定其他计划时发生的事情。对很多人来说,这句话引起了共鸣。',
+ }, {
+ 'text':
+ 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? The quick brown fox jumps over the lazy dog. Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? "Let\'s seize the day," Tom exclaimed, full of enthusiasm. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.',
+ 'target':
+ 'The quick brown fox jumps over the lazy dog. Isn\'t it amazing how a simple sentence can contain every letter of the alphabet? Speaking of weather, yesterday was quite dreary; however, today is absolutely delightful. "Let\'s seize the day," Tom exclaimed, full of enthusiasm.'
+ }, {
+ 'text': '''我很开心 。但是你不开心 。我很开心 。\n你好呀!我很开心 。我好的。你好呀!''',
+ 'target': '''我很开心 。但是你不开心 。\n你好呀!我好的。你好呀!'''
+ }, {
+ 'text': '去重?去重。去重!重。重...... 重! 1234?3215. 1234. 3. 3. 3',
+ 'target': '去重?去重。去重!重。重...... 重! 1234?3215. 1234. 3. 3. 3'
+ }]
+
+ op = RemoveRepeatSentencesMapper(lowercase=True,
+ ignore_special_character=False,
+ min_repeat_sentence_length=5)
self._run_helper(samples, op)
diff --git a/tests/ops/mapper/test_remove_specific_chars_mapper.py b/tests/ops/mapper/test_remove_specific_chars_mapper.py
index 4073d45df..f61a3f6fc 100644
--- a/tests/ops/mapper/test_remove_specific_chars_mapper.py
+++ b/tests/ops/mapper/test_remove_specific_chars_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.remove_specific_chars_mapper import \
RemoveSpecificCharsMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveSpecificCharsMapperTest(unittest.TestCase):
+class RemoveSpecificCharsMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = RemoveSpecificCharsMapper()
diff --git a/tests/ops/mapper/test_remove_table_text_mapper.py b/tests/ops/mapper/test_remove_table_text_mapper.py
index d08585d3e..2be4a2453 100644
--- a/tests/ops/mapper/test_remove_table_text_mapper.py
+++ b/tests/ops/mapper/test_remove_table_text_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.remove_table_text_mapper import \
RemoveTableTextMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveTableTextMapperTest(unittest.TestCase):
+class RemoveTableTextMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = RemoveTableTextMapper()
diff --git a/tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py b/tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py
index ad1fbe183..02157ad52 100644
--- a/tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py
+++ b/tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.remove_words_with_incorrect_substrings_mapper import \
RemoveWordsWithIncorrectSubstringsMapper # noqa: E501
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class RemoveWordsWithIncorrectSubstringsMapperTest(unittest.TestCase):
+class RemoveWordsWithIncorrectSubstringsMapperTest(DataJuicerTestCaseBase):
def _run_remove_words_with_incorrect_sbstrings(self, samples, op):
for sample in samples:
diff --git a/tests/ops/mapper/test_replace_content_mapper.py b/tests/ops/mapper/test_replace_content_mapper.py
index ec6ae512e..64f88c888 100644
--- a/tests/ops/mapper/test_replace_content_mapper.py
+++ b/tests/ops/mapper/test_replace_content_mapper.py
@@ -1,12 +1,12 @@
import unittest
-from data_juicer.ops.mapper.replace_content_mapper import \
- ReplaceContentMapper
+from data_juicer.ops.mapper.replace_content_mapper import ReplaceContentMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class ReplaceContentMapperTest(unittest.TestCase):
+class ReplaceContentMapperTest(DataJuicerTestCaseBase):
- def _run_helper(self,op, samples):
+ def _run_helper(self, op, samples):
for sample in samples:
result = op.process(sample)
self.assertEqual(result['text'], result['target'])
@@ -34,7 +34,6 @@ def test_special_char_pattern_text(self):
op = ReplaceContentMapper(pattern='●■', repl='')
self._run_helper(op, samples)
-
def test_raw_digit_pattern_text(self):
samples = [
@@ -45,7 +44,7 @@ def test_raw_digit_pattern_text(self):
]
op = ReplaceContentMapper(pattern=r'\d+(?:,\d+)*', repl='')
self._run_helper(op, samples)
-
+
def test_regular_digit_pattern_text(self):
samples = [
@@ -57,5 +56,6 @@ def test_regular_digit_pattern_text(self):
op = ReplaceContentMapper(pattern='\\d+(?:,\\d+)*', repl='')
self._run_helper(op, samples)
+
if __name__ == '__main__':
unittest.main()
diff --git a/tests/ops/mapper/test_sentence_split_mapper.py b/tests/ops/mapper/test_sentence_split_mapper.py
index abd914bda..3cdf3a977 100644
--- a/tests/ops/mapper/test_sentence_split_mapper.py
+++ b/tests/ops/mapper/test_sentence_split_mapper.py
@@ -1,9 +1,10 @@
import unittest
from data_juicer.ops.mapper.sentence_split_mapper import SentenceSplitMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class SentenceSplitMapperTest(unittest.TestCase):
+class SentenceSplitMapperTest(DataJuicerTestCaseBase):
def _run_helper(self, op, samples):
for sample in samples:
diff --git a/tests/ops/mapper/test_video_captioning_from_audio_mapper.py b/tests/ops/mapper/test_video_captioning_from_audio_mapper.py
new file mode 100644
index 000000000..3a842bab8
--- /dev/null
+++ b/tests/ops/mapper/test_video_captioning_from_audio_mapper.py
@@ -0,0 +1,160 @@
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset
+from data_juicer.ops.mapper.video_captioning_from_audio_mapper import \
+ VideoCaptioningFromAudioMapper
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import (SKIPPED_TESTS,
+ DataJuicerTestCaseBase)
+
+
+# Skip tests for this OP in the GitHub actions due to disk space limitation.
+# These tests have been tested locally.
+@SKIPPED_TESTS.register_module()
+class VideoCaptioningFromAudioMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4')
+ vid2_path = os.path.join(data_path, 'video2.mp4')
+ vid3_path = os.path.join(data_path, 'video3.mp4')
+
+ @staticmethod
+ def _count_generated_caption_num(text):
+ chunks = text.split(SpecialTokens.eoc)
+ vid_num = 0
+ cap_num = 0
+ for chunk in chunks:
+ if chunk.strip() == '':
+ continue
+ vid_num += chunk.count(SpecialTokens.video)
+ caps = [
+ cap for cap in chunk.split(SpecialTokens.video) if cap.strip()
+ ]
+ cap_num += len(caps)
+ return vid_num, cap_num
+
+ def _run_op(self, dataset: NestedDataset, caption_num, op, np=1):
+ dataset = dataset.map(op.process, num_proc=np)
+ text_list = dataset.select_columns(column_names=['text']).to_list()
+ for txt in text_list:
+ vid_num, cap_num = self._count_generated_caption_num(txt['text'])
+ self.assertEqual(vid_num, cap_num)
+ self.assertEqual(len(dataset), caption_num)
+
+ def test_default_params(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。',
+ 'videos': [self.vid3_path]
+ }]
+ dataset = NestedDataset.from_list(ds_list)
+ op = VideoCaptioningFromAudioMapper()
+ self._run_op(dataset, len(dataset) * 2, op)
+
+ def test_with_eoc(self):
+
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。'
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。 '
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ dataset = NestedDataset.from_list(ds_list)
+ op = VideoCaptioningFromAudioMapper()
+ self._run_op(dataset, len(dataset) * 2, op)
+
+ def test_no_original_samples(self):
+
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。'
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。 '
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ dataset = NestedDataset.from_list(ds_list)
+ op = VideoCaptioningFromAudioMapper(keep_original_sample=False)
+ self._run_op(dataset, len(dataset), op)
+
+ def test_multi_chunk_samples(self):
+
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。'
+ f'{SpecialTokens.eoc} {SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,'
+ f'拍打自己的胃部。 {SpecialTokens.eoc}',
+ 'videos': [self.vid1_path, self.vid2_path]
+ }, {
+ 'text':
+ f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc} '
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid3_path, self.vid1_path]
+ }]
+ dataset = NestedDataset.from_list(ds_list)
+ op = VideoCaptioningFromAudioMapper()
+ self._run_op(dataset, len(dataset) * 2, op)
+
+ def test_multi_video_samples(self):
+
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。 '
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。 '
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid1_path, self.vid2_path]
+ }, {
+ 'text':
+ f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc} '
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。 '
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。 '
+ f'{SpecialTokens.eoc} {SpecialTokens.video} 白色的小羊站在一旁讲话。'
+ f'旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos':
+ [self.vid3_path, self.vid1_path, self.vid2_path, self.vid1_path]
+ }]
+ dataset = NestedDataset.from_list(ds_list)
+ op = VideoCaptioningFromAudioMapper()
+ self._run_op(dataset, len(dataset) * 2, op)
+
+ def test_parallel(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。',
+ 'videos': [self.vid3_path]
+ }]
+ dataset = NestedDataset.from_list(ds_list)
+ op = VideoCaptioningFromAudioMapper()
+ self._run_op(dataset, len(dataset) * 2, op, np=2)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_captioning_from_video_mapper.py b/tests/ops/mapper/test_video_captioning_from_video_mapper.py
new file mode 100644
index 000000000..012761af5
--- /dev/null
+++ b/tests/ops/mapper/test_video_captioning_from_video_mapper.py
@@ -0,0 +1,232 @@
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset as Dataset
+from data_juicer.ops.mapper.video_captioning_from_video_mapper import \
+ VideoCaptioningFromVideoMapper
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import (SKIPPED_TESTS,
+ DataJuicerTestCaseBase)
+
+
+# Skip tests for this OP in the GitHub actions due to disk space limitation.
+# These tests have been tested locally.
+@SKIPPED_TESTS.register_module()
+class VideoCaptioningFromVideoMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4')
+ vid2_path = os.path.join(data_path, 'video2.mp4')
+ hf_video_blip = 'kpyu/video-blip-opt-2.7b-ego4d'
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ super().tearDownClass(cls.hf_video_blip)
+
+ def _run_mapper(self, ds_list, op, num_proc=1, caption_num=0):
+
+ dataset = Dataset.from_list(ds_list)
+ dataset = dataset.map(op.process, num_proc=num_proc, with_rank=True)
+ dataset_list = dataset.select_columns(column_names=['text']).to_list()
+ # assert the caption is generated successfully in terms of not_none
+ # as the generated content is not deterministic
+ self.assertEqual(len(dataset_list), caption_num)
+
+ def test_default_params_no_eoc(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_default_params_with_eoc(self):
+
+ ds_list = [
+ {
+ 'text':
+ f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪'
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid1_path]
+ },
+ {
+ 'text':
+ f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃{SpecialTokens.eoc}', # noqa: E501
+ 'videos': [self.vid2_path]
+ }
+ ]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_multi_candidate_keep_random_any(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ caption_num = 4
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ caption_num=caption_num,
+ keep_candidate_mode='random_any')
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_multi_candidate_keep_all(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ caption_num = 4
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ caption_num=caption_num,
+ keep_candidate_mode='all')
+ self._run_mapper(ds_list,
+ op,
+ caption_num=(1 + caption_num) * len(ds_list))
+
+ def test_multi_candidate_keep_similar_one(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ caption_num = 4
+ op = VideoCaptioningFromVideoMapper(
+ hf_video_blip=self.hf_video_blip,
+ caption_num=caption_num,
+ keep_candidate_mode='similar_one_simhash')
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_remove_original_sample(self):
+
+ ds_list = [
+ {
+ 'text':
+ f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ },
+ {
+ 'text':
+ f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃', # noqa: E501
+ 'videos': [self.vid2_path]
+ }
+ ]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ keep_original_sample=False)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list))
+
+ def test_multi_candidate_remove_original_sample(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ caption_num = 4
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ caption_num=caption_num,
+ keep_original_sample=False)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list))
+
+ def test_multi_process(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }] * 10
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip)
+ self._run_mapper(ds_list, op, num_proc=4, caption_num=len(ds_list) * 2)
+
+ def test_multi_process_remove_original_sample(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }] * 10
+
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ keep_original_sample=False)
+ self._run_mapper(ds_list, op, num_proc=4, caption_num=len(ds_list))
+
+ def test_frame_sampling_method(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ frame_sampling_method='uniform')
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_frame_num(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ frame_sampling_method='uniform',
+ frame_num=5)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_horizontal_flip(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ horizontal_flip=True)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_vertical_flip(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video}身穿白色上衣的男子,拿着一个东西,拍打自己的胃',
+ 'videos': [self.vid2_path]
+ }]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip,
+ vertical_flip=True)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+ def test_multi_tag(self):
+
+ ds_list = [{
+ 'text': f'{SpecialTokens.video}{SpecialTokens.video}'
+ '白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪',
+ 'videos': [
+ self.vid1_path,
+ self.vid1_path,
+ ]
+ }]
+ op = VideoCaptioningFromVideoMapper(hf_video_blip=self.hf_video_blip)
+ self._run_mapper(ds_list, op, caption_num=len(ds_list) * 2)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_ffmpeg_wrapped_mapper.py b/tests/ops/mapper/test_video_ffmpeg_wrapped_mapper.py
new file mode 100644
index 000000000..1071bd864
--- /dev/null
+++ b/tests/ops/mapper/test_video_ffmpeg_wrapped_mapper.py
@@ -0,0 +1,69 @@
+import os
+import unittest
+
+from datasets import Dataset
+
+from data_juicer.ops.mapper.video_ffmpeg_wrapped_mapper import \
+ VideoFFmpegWrappedMapper
+from data_juicer.utils.mm_utils import load_video
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoFFmpegWrappedMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4') # 640x360, 16:9
+ vid2_path = os.path.join(data_path, 'video2.mp4') # 480x640, 3:4
+ vid3_path = os.path.join(data_path, 'video3.mp4') # 362x640, 181:320
+
+ def _run_op(self, ds_list, target_list, op, np=1):
+ dataset = Dataset.from_list(ds_list)
+ dataset = dataset.map(op.process, num_proc=np)
+
+ def get_size(dataset):
+ sizes = []
+ res_list = dataset.to_list()
+ for sample in res_list:
+ sample_list = []
+ for value in sample['videos']:
+ video = load_video(value)
+ width = video.streams.video[0].codec_context.width
+ height = video.streams.video[0].codec_context.height
+ sample_list.append((width, height))
+ video.close()
+ sizes.append(sample_list)
+ return sizes
+
+ sizes = get_size(dataset)
+ self.assertEqual(sizes, target_list)
+
+ def test_resize(self):
+ ds_list = [{
+ 'videos': [self.vid1_path, self.vid2_path, self.vid3_path]
+ }]
+ tgt_list = [[(400, 480), (400, 480), (400, 480)]]
+ op = VideoFFmpegWrappedMapper('scale',
+ filter_kwargs={
+ 'width': 400,
+ 'height': 480
+ },
+ capture_stderr=False)
+ self._run_op(ds_list, tgt_list, op)
+
+ def test_resize_parallel(self):
+ ds_list = [{
+ 'videos': [self.vid1_path, self.vid2_path, self.vid3_path]
+ }]
+ tgt_list = [[(400, 480), (400, 480), (400, 480)]]
+ op = VideoFFmpegWrappedMapper('scale',
+ filter_kwargs={
+ 'width': 400,
+ 'height': 480
+ },
+ capture_stderr=False)
+ self._run_op(ds_list, tgt_list, op, np=2)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_resize_aspect_ratio_mapper.py b/tests/ops/mapper/test_video_resize_aspect_ratio_mapper.py
new file mode 100644
index 000000000..3db841646
--- /dev/null
+++ b/tests/ops/mapper/test_video_resize_aspect_ratio_mapper.py
@@ -0,0 +1,150 @@
+import os
+import unittest
+
+from datasets import Dataset
+
+from data_juicer.ops.mapper.video_resize_aspect_ratio_mapper import \
+ VideoResizeAspectRatioMapper
+from data_juicer.utils.mm_utils import load_video
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoResizeAspectRatioMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4') # 640x360, 16:9
+ vid2_path = os.path.join(data_path, 'video2.mp4') # 480x640, 3:4
+ vid3_path = os.path.join(data_path, 'video3.mp4') # 362x640, 181:320
+
+ def _run_op(self, dataset: Dataset, target_list, op, np=1):
+ dataset = dataset.map(op.process, num_proc=np)
+
+ def get_size(dataset):
+ sizes = []
+ res_list = dataset.to_list()
+ for sample in res_list:
+ sample_list = []
+ for value in sample['videos']:
+ video = load_video(value)
+ width = video.streams.video[0].codec_context.width
+ height = video.streams.video[0].codec_context.height
+ sample_list.append((width, height))
+ video.close()
+ sizes.append(sample_list)
+ return sizes
+
+ sizes = get_size(dataset)
+ self.assertEqual(sizes, target_list)
+
+ def test_default_params(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [
+ [(640, 360)], # no change
+ [(480, 640)], # no change
+ [(362, 640)] # no change
+ ]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeAspectRatioMapper()
+ self._run_op(dataset, tgt_list, op)
+
+ def test_min_ratio_increase(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [
+ [(640, 360)], # no change
+ [(480, 640)], # no change
+ [(480, 640)] # 181:320 to 3:4
+ ]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeAspectRatioMapper(min_ratio='3/4', strategy='increase')
+ self._run_op(dataset, tgt_list, op)
+
+ def test_min_ratio_decrease(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [
+ [(640, 360)], # no change
+ [(480, 640)], # no change
+ [(362, 482)] # ratio 181:320 to 3:4
+ ]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeAspectRatioMapper(min_ratio='3/4', strategy='decrease')
+ self._run_op(dataset, tgt_list, op)
+
+ def test_max_ratio_increase(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [
+ [(640, 480)], # 16:9 to 4:3
+ [(480, 640)], # no change
+ [(362, 640)] # no change
+ ]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeAspectRatioMapper(max_ratio='4/3', strategy='increase')
+ self._run_op(dataset, tgt_list, op)
+
+ def test_max_ratio_decrease(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [
+ [(480, 360)], # 16:9 to 4:3
+ [(480, 640)], # no change
+ [(362, 640)] # no change
+ ]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeAspectRatioMapper(max_ratio='4/3', strategy='decrease')
+ self._run_op(dataset, tgt_list, op)
+
+ def test_parallel(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [
+ [(480, 360)], # 16:9 to 4:3
+ [(480, 640)], # no change
+ [(362, 640)] # no change
+ ]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeAspectRatioMapper(max_ratio='4/3', strategy='decrease')
+ self._run_op(dataset, tgt_list, op, np=2)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_resize_resolution_mapper.py b/tests/ops/mapper/test_video_resize_resolution_mapper.py
new file mode 100644
index 000000000..8f8b2cafa
--- /dev/null
+++ b/tests/ops/mapper/test_video_resize_resolution_mapper.py
@@ -0,0 +1,187 @@
+import os
+import unittest
+
+import ffmpeg
+from datasets import Dataset
+
+from data_juicer.ops.mapper.video_resize_resolution_mapper import \
+ VideoResizeResolutionMapper
+from data_juicer.utils.constant import Fields
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoResizeResolutionMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ # video1: horizontal resolution 640p, vertical resolution 360p
+ # video2: horizontal resolution 480p, vertical resolution 640p
+ # video3: horizontal resolution 362p, vertical resolution 640p
+ vid1_path = os.path.join(data_path, 'video1.mp4')
+ vid2_path = os.path.join(data_path, 'video2.mp4')
+ vid3_path = os.path.join(data_path, 'video3.mp4')
+
+ def _get_size_list(self, dataset: Dataset):
+ res_list = []
+ for sample in dataset.to_list():
+ cur_list = []
+ for value in sample['videos']:
+ print(value)
+ probe = ffmpeg.probe(value)
+ video_stream = next((stream for stream in probe['streams']
+ if stream['codec_type'] == 'video'), None)
+ width = int(video_stream['width'])
+ height = int(video_stream['height'])
+ cur_list.append((width, height))
+ res_list.append(cur_list)
+ return res_list
+
+ def _run_video_resize_resolution_mapper(self,
+ dataset: Dataset,
+ target_list,
+ op,
+ test_name,
+ np=1):
+ if Fields.stats not in dataset.features:
+ dataset = dataset.add_column(name=Fields.stats,
+ column=[{}] * dataset.num_rows)
+ dataset = dataset.map(op.process, num_proc=np)
+ dataset = dataset.select_columns(column_names=[op.video_key])
+
+ # check each video personally
+ # output_dir = '../video_resize_resolution_mapper'
+ # move_to_dir = os.path.join(output_dir, test_name)
+ # if not os.path.exists(move_to_dir):
+ # os.makedirs(move_to_dir)
+ # for sample in dataset.to_list():
+ # for value in sample['videos']:
+ # move_to_path = os.path.join(move_to_dir,
+ # os.path.basename(value))
+ # shutil.copyfile(value, move_to_path)
+
+ res_list = self._get_size_list(dataset)
+ self.assertEqual(res_list, target_list)
+
+ def test_default_mapper(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [[(640, 360)], [(480, 640)], [(362, 640)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper()
+ self._run_video_resize_resolution_mapper(dataset, tgt_list, op,
+ 'test_default_mapper')
+
+ def test_width_mapper(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [[(480, 270)], [(480, 640)], [(400, 708)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(min_width=400, max_width=480)
+ self._run_video_resize_resolution_mapper(dataset, tgt_list, op,
+ 'test_width_mapper')
+
+ def test_height_mapper(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [[(854, 480)], [(360, 480)], [(272, 480)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(min_height=480, max_height=480)
+ self._run_video_resize_resolution_mapper(dataset, tgt_list, op,
+ 'test_width_mapper')
+
+ def test_width_and_height_mapper(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path, self.vid2_path, self.vid3_path]
+ }]
+ tgt_list = [[(480, 480), (400, 480), (400, 480)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(min_width=400,
+ max_width=480,
+ min_height=480,
+ max_height=480)
+ self._run_video_resize_resolution_mapper(
+ dataset, tgt_list, op, 'test_width_and_height_mapper')
+
+ def test_keep_aspect_ratio_decrease_mapper(self):
+
+ ds_list = [{'videos': [self.vid1_path]}]
+ tgt_list = [[(480, 270)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(
+ min_width=400,
+ max_width=480,
+ min_height=480,
+ max_height=480,
+ force_original_aspect_ratio='decrease')
+ self._run_video_resize_resolution_mapper(
+ dataset, tgt_list, op, 'test_keep_aspect_ratio_decrease_mapper')
+
+ def test_keep_aspect_ratio_increase_mapper(self):
+
+ ds_list = [{'videos': [self.vid1_path]}]
+ tgt_list = [[(854, 480)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(
+ min_width=400,
+ max_width=480,
+ min_height=480,
+ max_height=480,
+ force_original_aspect_ratio='increase')
+ self._run_video_resize_resolution_mapper(
+ dataset, tgt_list, op, 'test_keep_aspect_ratio_increase_mapper')
+
+ def test_force_divisible_by(self):
+
+ ds_list = [{'videos': [self.vid1_path]}]
+ tgt_list = [[(480, 272)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(
+ min_width=400,
+ max_width=480,
+ min_height=480,
+ max_height=480,
+ force_original_aspect_ratio='decrease',
+ force_divisible_by=4)
+ self._run_video_resize_resolution_mapper(dataset, tgt_list, op,
+ 'test_force_divisible_by')
+
+ def test_filter_in_parallel(self):
+
+ ds_list = [{
+ 'videos': [self.vid1_path]
+ }, {
+ 'videos': [self.vid2_path]
+ }, {
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [[(480, 270)], [(480, 640)], [(400, 708)]]
+ dataset = Dataset.from_list(ds_list)
+ op = VideoResizeResolutionMapper(min_width=400, max_width=480)
+ self._run_video_resize_resolution_mapper(dataset,
+ tgt_list,
+ op,
+ 'test_filter_in_parallel',
+ np=2)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_split_by_duration_mapper.py b/tests/ops/mapper/test_video_split_by_duration_mapper.py
new file mode 100644
index 000000000..43089dfa7
--- /dev/null
+++ b/tests/ops/mapper/test_video_split_by_duration_mapper.py
@@ -0,0 +1,232 @@
+# flake8: noqa: E501
+
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset
+from data_juicer.ops.mapper.video_split_by_duration_mapper import \
+ VideoSplitByDurationMapper
+from data_juicer.utils.file_utils import add_suffix_to_filename
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoSplitByDurationMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4')
+ vid2_path = os.path.join(data_path, 'video2.mp4')
+ vid3_path = os.path.join(data_path, 'video3.mp4')
+
+ def _get_res_list(self, dataset, source_list):
+ res_list = []
+ origin_paths = [self.vid1_path, self.vid2_path, self.vid3_path]
+ idx = 0
+ for sample in dataset.to_list():
+ output_paths = sample['videos']
+
+ # for keep_original_sample=True
+ if set(output_paths) <= set(origin_paths):
+ res_list.append(sample)
+ continue
+
+ source = source_list[idx]
+ idx += 1
+
+ output_file_names = [
+ os.path.splitext(os.path.basename(p))[0] for p in output_paths
+ ]
+ split_frames_nums = []
+ for origin_path in source['videos']:
+ origin_file_name = os.path.splitext(
+ os.path.basename(origin_path))[0]
+ cnt = 0
+ for output_file_name in output_file_names:
+ if origin_file_name in output_file_name:
+ cnt += 1
+ split_frames_nums.append(cnt)
+
+ res_list.append({
+ 'text': sample['text'],
+ 'split_frames_num': split_frames_nums
+ })
+
+ return res_list
+
+ def _run_video_split_by_duration_mapper(self,
+ op,
+ source_list,
+ target_list,
+ num_proc=1):
+ dataset = NestedDataset.from_list(source_list)
+ dataset = dataset.map(op.process, num_proc=num_proc)
+ res_list = self._get_res_list(dataset, source_list)
+ self.assertEqual(res_list, target_list)
+
+ def test(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [2]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [5]
+ }]
+ op = VideoSplitByDurationMapper(split_duration=10,
+ keep_original_sample=False)
+ self._run_video_split_by_duration_mapper(op, ds_list, tgt_list)
+
+ def test_keep_ori_sample(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [2]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [5]
+ }]
+ op = VideoSplitByDurationMapper()
+ self._run_video_split_by_duration_mapper(op, ds_list, tgt_list)
+
+ def test_multi_process(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [2]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [5]
+ }]
+ op = VideoSplitByDurationMapper(keep_original_sample=False)
+ self._run_video_split_by_duration_mapper(op,
+ ds_list,
+ tgt_list,
+ num_proc=2)
+
+ def test_multi_chunk(self):
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid2_path, self.vid3_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid1_path, self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [2, 3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [3, 5]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [2, 5]
+ }]
+ op = VideoSplitByDurationMapper(keep_original_sample=False)
+ self._run_video_split_by_duration_mapper(op, ds_list, tgt_list)
+
+ def test_min_last_split_duration(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [1]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [5]
+ }]
+ op = VideoSplitByDurationMapper(split_duration=10,
+ min_last_split_duration=3,
+ keep_original_sample=False)
+ self._run_video_split_by_duration_mapper(op, ds_list, tgt_list)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_split_by_key_frame_mapper.py b/tests/ops/mapper/test_video_split_by_key_frame_mapper.py
new file mode 100644
index 000000000..997ae9ed8
--- /dev/null
+++ b/tests/ops/mapper/test_video_split_by_key_frame_mapper.py
@@ -0,0 +1,200 @@
+# flake8: noqa: E501
+
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset
+from data_juicer.ops.mapper.video_split_by_key_frame_mapper import \
+ VideoSplitByKeyFrameMapper
+from data_juicer.utils.file_utils import add_suffix_to_filename
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoSplitByKeyFrameMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4')
+ vid2_path = os.path.join(data_path, 'video2.mp4')
+ vid3_path = os.path.join(data_path, 'video3.mp4')
+
+ def _get_res_list(self, dataset, source_list):
+ res_list = []
+ origin_paths = [self.vid1_path, self.vid2_path, self.vid3_path]
+ idx = 0
+ for sample in dataset.to_list():
+ output_paths = sample['videos']
+
+ # for keep_original_sample=True
+ if set(output_paths) <= set(origin_paths):
+ res_list.append(sample)
+ continue
+
+ source = source_list[idx]
+ idx += 1
+
+ output_file_names = [
+ os.path.splitext(os.path.basename(p))[0] for p in output_paths
+ ]
+ split_frames_nums = []
+ for origin_path in source['videos']:
+ origin_file_name = os.path.splitext(
+ os.path.basename(origin_path))[0]
+ cnt = 0
+ for output_file_name in output_file_names:
+ if origin_file_name in output_file_name:
+ cnt += 1
+ split_frames_nums.append(cnt)
+
+ res_list.append({
+ 'text': sample['text'],
+ 'split_frames_num': split_frames_nums
+ })
+
+ return res_list
+
+ def _run_video_split_by_key_frame_mapper(self,
+ op,
+ source_list,
+ target_list,
+ num_proc=1):
+ dataset = NestedDataset.from_list(source_list)
+ dataset = dataset.map(op.process, num_proc=num_proc)
+ res_list = self._get_res_list(dataset, source_list)
+ self.assertEqual(res_list, target_list)
+
+ def test(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [6]
+ }]
+ op = VideoSplitByKeyFrameMapper(keep_original_sample=False)
+ self._run_video_split_by_key_frame_mapper(op, ds_list, tgt_list)
+
+ def test_keep_ori_sample(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [6]
+ }]
+ op = VideoSplitByKeyFrameMapper()
+ self._run_video_split_by_key_frame_mapper(op, ds_list, tgt_list)
+
+ def test_multi_process(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [6]
+ }]
+ op = VideoSplitByKeyFrameMapper(keep_original_sample=False)
+ self._run_video_split_by_key_frame_mapper(op,
+ ds_list,
+ tgt_list,
+ num_proc=2)
+
+ def test_multi_chunk(self):
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid2_path, self.vid3_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid1_path, self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'split_frames_num': [3, 3]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [3, 6]
+ }, {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'split_frames_num': [3, 6]
+ }]
+ op = VideoSplitByKeyFrameMapper(keep_original_sample=False)
+ self._run_video_split_by_key_frame_mapper(op, ds_list, tgt_list)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_split_by_scene_mapper.py b/tests/ops/mapper/test_video_split_by_scene_mapper.py
new file mode 100644
index 000000000..f4b3263aa
--- /dev/null
+++ b/tests/ops/mapper/test_video_split_by_scene_mapper.py
@@ -0,0 +1,171 @@
+import os
+import unittest
+
+from datasets import Dataset
+
+from data_juicer.ops.mapper.video_split_by_scene_mapper import \
+ VideoSplitBySceneMapper
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoSplitBySceneMapperTest(DataJuicerTestCaseBase):
+
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4') # about 12s
+ vid2_path = os.path.join(data_path, 'video2.mp4') # about 23s
+ vid3_path = os.path.join(data_path, 'video3.mp4') # about 50s
+
+ vid1_base, vid1_ext = os.path.splitext(os.path.basename(vid1_path))
+ vid2_base, vid2_ext = os.path.splitext(os.path.basename(vid2_path))
+ vid3_base, vid3_ext = os.path.splitext(os.path.basename(vid3_path))
+
+ op_name = 'video_split_by_scene_mapper'
+
+ def get_res_list(self, dataset: Dataset):
+ res_list = []
+ for sample in dataset.to_list():
+ scene_num = len(sample['videos'])
+ if 'text' in sample:
+ res_list.append({
+ 'scene_num': scene_num,
+ 'text': sample['text']
+ })
+ else:
+ res_list.append({'scene_num': scene_num})
+ return res_list
+
+ def _run_helper(self, op, source_list, target_list):
+ dataset = Dataset.from_list(source_list)
+ dataset = dataset.map(op.process)
+ res_list = self.get_res_list(dataset)
+ self.assertEqual(res_list, target_list)
+
+ def test_ContentDetector(self):
+ ds_list = [
+ {
+ 'videos': [self.vid1_path] # 3 scenes
+ },
+ {
+ 'videos': [self.vid2_path] # 1 scene
+ },
+ {
+ 'videos': [self.vid3_path] # 2 scenes
+ }
+ ]
+ tgt_list = [{'scene_num': 3}, {'scene_num': 1}, {'scene_num': 2}]
+ op = VideoSplitBySceneMapper(detector='ContentDetector',
+ threshold=27.0,
+ min_scene_len=15)
+ self._run_helper(op, ds_list, tgt_list)
+
+ def test_AdaptiveDetector(self):
+ ds_list = [
+ {
+ 'videos': [self.vid1_path] # 3 scenes
+ },
+ {
+ 'videos': [self.vid2_path] # 1 scene
+ },
+ {
+ 'videos': [self.vid3_path] # 8 scenes
+ }
+ ]
+ tgt_list = [{'scene_num': 3}, {'scene_num': 1}, {'scene_num': 8}]
+ op = VideoSplitBySceneMapper(detector='AdaptiveDetector',
+ threshold=3.0,
+ min_scene_len=15)
+ self._run_helper(op, ds_list, tgt_list)
+
+ def test_ThresholdDetector(self):
+ ds_list = [
+ {
+ 'videos': [self.vid1_path] # 1 scene
+ },
+ {
+ 'videos': [self.vid2_path] # 1 scene
+ },
+ {
+ 'videos': [self.vid3_path] # 1 scene
+ }
+ ]
+ tgt_list = [{'scene_num': 1}, {'scene_num': 1}, {'scene_num': 1}]
+ op = VideoSplitBySceneMapper(detector='ThresholdDetector',
+ threshold=12.0,
+ min_scene_len=15)
+ self._run_helper(op, ds_list, tgt_list)
+
+ def test_default_progress(self):
+ ds_list = [
+ {
+ 'videos': [self.vid1_path] # 3 scenes
+ },
+ {
+ 'videos': [self.vid2_path] # 1 scene
+ },
+ {
+ 'videos': [self.vid3_path] # 2 scenes
+ }
+ ]
+ tgt_list = [{'scene_num': 3}, {'scene_num': 1}, {'scene_num': 2}]
+ op = VideoSplitBySceneMapper(show_progress=True)
+ self._run_helper(op, ds_list, tgt_list)
+
+ def test_default_kwargs(self):
+ ds_list = [
+ {
+ 'videos': [self.vid1_path] # 2 scenes
+ },
+ {
+ 'videos': [self.vid2_path] # 1 scene
+ },
+ {
+ 'videos': [self.vid3_path] # 2 scenes
+ }
+ ]
+ tgt_list = [{'scene_num': 2}, {'scene_num': 1}, {'scene_num': 2}]
+ op = VideoSplitBySceneMapper(luma_only=True, kernel_size=5)
+ self._run_helper(op, ds_list, tgt_list)
+
+ def test_default_with_text(self):
+ ds_list = [
+ {
+ 'text':
+ f'{SpecialTokens.video} this is video1 {SpecialTokens.eoc}',
+ 'videos': [self.vid1_path] # 3 scenes
+ },
+ {
+ 'text':
+ f'{SpecialTokens.video} this is video2 {SpecialTokens.eoc}',
+ 'videos': [self.vid2_path] # 1 scene
+ },
+ {
+ 'text':
+ f'{SpecialTokens.video} this is video3 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path] # 2 scenes
+ }
+ ]
+ tgt_list = [
+ {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video}{SpecialTokens.video} this is video1 {SpecialTokens.eoc}', # noqa: E501
+ 'scene_num': 3
+ },
+ {
+ 'text':
+ f'{SpecialTokens.video} this is video2 {SpecialTokens.eoc}',
+ 'scene_num': 1
+ },
+ {
+ 'text':
+ f'{SpecialTokens.video}{SpecialTokens.video} this is video3 {SpecialTokens.eoc}', # noqa: E501
+ 'scene_num': 2
+ }
+ ]
+ op = VideoSplitBySceneMapper()
+ self._run_helper(op, ds_list, tgt_list)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_tagging_from_audio_mapper.py b/tests/ops/mapper/test_video_tagging_from_audio_mapper.py
new file mode 100644
index 000000000..042109d86
--- /dev/null
+++ b/tests/ops/mapper/test_video_tagging_from_audio_mapper.py
@@ -0,0 +1,155 @@
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset
+from data_juicer.ops.mapper.video_tagging_from_audio_mapper import \
+ VideoTaggingFromAudioMapper
+from data_juicer.utils.constant import Fields
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoTaggingFromAudioMapperTest(DataJuicerTestCaseBase):
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4') # Music
+ vid2_path = os.path.join(data_path, 'video2.mp4') # Music
+ vid3_path = os.path.join(data_path, 'video3.mp4') # Music
+ vid4_path = os.path.join(data_path, 'video4.mp4') # Speech
+ vid5_path = os.path.join(data_path, 'video5.mp4') # Speech
+ vid3_no_aud_path = os.path.join(data_path, 'video3-no-audio.mp4') # EMPTY
+
+ hf_ast = 'MIT/ast-finetuned-audioset-10-10-0.4593'
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ super().tearDownClass(cls.hf_ast)
+
+ def _run_video_tagging_from_audio_mapper(self,
+ op,
+ source_list,
+ target_list,
+ num_proc=1):
+ dataset = NestedDataset.from_list(source_list)
+ dataset = dataset.map(op.process, num_proc=num_proc)
+ res_list = dataset.select_columns([Fields.video_audio_tags
+ ])[Fields.video_audio_tags]
+ self.assertEqual(res_list, target_list)
+
+ def test(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。'
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 一个人在帮另一个人梳头发。 {SpecialTokens.eoc}',
+ 'videos': [self.vid4_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 一个穿着红色连衣裙的女人在试衣服。 {SpecialTokens.eoc}',
+ 'videos': [self.vid5_path]
+ }]
+ tgt_list = [['Music'], ['Music'], ['Speech'], ['Speech']]
+ op = VideoTaggingFromAudioMapper(self.hf_ast)
+ self._run_video_tagging_from_audio_mapper(op, ds_list, tgt_list)
+
+ def test_multi_chunk(self):
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。'
+ f'{SpecialTokens.eoc}{SpecialTokens.video} '
+ f'身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。'
+ f'{SpecialTokens.eoc}{SpecialTokens.video} 一个人在帮另一个人梳头发。 '
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path, self.vid4_path]
+ }, {
+ 'text':
+ f'一个穿着红色连衣裙的女人在试衣服。 {SpecialTokens.video} {SpecialTokens.eoc} '
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid5_path, self.vid1_path]
+ }]
+ tgt_list = [['Music', 'Music'], ['Music', 'Speech'],
+ ['Speech', 'Music']]
+ op = VideoTaggingFromAudioMapper(self.hf_ast)
+ self._run_video_tagging_from_audio_mapper(op, ds_list, tgt_list)
+
+ def test_multi_video(self):
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} {SpecialTokens.video} 白色的小羊站在一旁讲话。'
+ f'旁边还有两只灰色猫咪和一只拉着灰狼的猫咪; 一个人在帮另一个人梳头发 {SpecialTokens.eoc}'
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid4_path, self.vid2_path]
+ }, {
+ 'text':
+ f'一个穿着红色连衣裙的女人在试衣服。 {SpecialTokens.video} {SpecialTokens.video} '
+ f'白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid5_path, self.vid1_path]
+ }]
+ tgt_list = [['Music', 'Speech', 'Music'], ['Speech', 'Music']]
+ op = VideoTaggingFromAudioMapper(self.hf_ast)
+ self._run_video_tagging_from_audio_mapper(op, ds_list, tgt_list)
+
+ def test_no_video(self):
+ ds_list = [{
+ 'text': '白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': []
+ }, {
+ 'text': f'身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}'
+ f'{SpecialTokens.video} 一个人在帮另一个人梳头发。 {SpecialTokens.eoc}',
+ 'videos': [self.vid4_path]
+ }]
+ tgt_list = [[], ['Speech']]
+ op = VideoTaggingFromAudioMapper(self.hf_ast)
+ self._run_video_tagging_from_audio_mapper(op, ds_list, tgt_list)
+
+ def test_no_audio(self):
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} {SpecialTokens.video} 白色的小羊站在一旁讲话。'
+ f'旁边还有两只灰色猫咪和一只拉着灰狼的猫咪; 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}'
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid3_no_aud_path, self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} {SpecialTokens.video} '
+ f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} 一个人在帮另一个人梳头发。',
+ 'videos': [self.vid3_path, self.vid3_no_aud_path, self.vid4_path]
+ }]
+ tgt_list = [['Music', 'EMPTY', 'Music'], ['Music', 'EMPTY', 'Speech']]
+ op = VideoTaggingFromAudioMapper(self.hf_ast)
+ self._run_video_tagging_from_audio_mapper(op, ds_list, tgt_list)
+
+ def test_multi_process(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。'
+ f'{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text': f'{SpecialTokens.video} 一个人在帮另一个人梳头发。 {SpecialTokens.eoc}',
+ 'videos': [self.vid4_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 一个穿着红色连衣裙的女人在试衣服。 {SpecialTokens.eoc}',
+ 'videos': [self.vid5_path]
+ }]
+ tgt_list = [['Music'], ['Music'], ['Speech'], ['Speech']]
+ op = VideoTaggingFromAudioMapper(self.hf_ast)
+ self._run_video_tagging_from_audio_mapper(op,
+ ds_list,
+ tgt_list,
+ num_proc=2)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_video_tagging_from_frames_mapper.py b/tests/ops/mapper/test_video_tagging_from_frames_mapper.py
new file mode 100644
index 000000000..ea13109fc
--- /dev/null
+++ b/tests/ops/mapper/test_video_tagging_from_frames_mapper.py
@@ -0,0 +1,244 @@
+# flake8: noqa: E501
+import os
+import unittest
+
+from data_juicer.core.data import NestedDataset
+from data_juicer.ops.mapper.video_tagging_from_frames_mapper import \
+ VideoTaggingFromFramesMapper
+from data_juicer.utils.constant import Fields
+from data_juicer.utils.mm_utils import SpecialTokens
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
+
+
+class VideoTaggingFromFramesMapperTest(DataJuicerTestCaseBase):
+ data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..',
+ 'data')
+ vid1_path = os.path.join(data_path, 'video1.mp4')
+ vid2_path = os.path.join(data_path, 'video2.mp4')
+ vid3_path = os.path.join(data_path, 'video3.mp4')
+
+ def _run_video_tagging_from_frames_mapper(self,
+ op,
+ source_list,
+ target_list,
+ num_proc=1):
+ dataset = NestedDataset.from_list(source_list)
+ dataset = dataset.map(op.process, num_proc=num_proc)
+ res_list = dataset.to_list()
+ self.assertEqual(res_list, target_list)
+
+ def test(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path],
+ Fields.video_frame_tags: [[
+ 'animal', 'ray', 'text', 'writing', 'yellow', 'game',
+ 'screenshot', 'cartoon', 'cartoon character', 'person', 'robe',
+ 'sky'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path],
+ Fields.video_frame_tags: [[
+ 'man', 'shirt', 't shirt', 't-shirt', 'wear', 'white', 'boy',
+ 'catch', 'hand', 'blind', 'cotton candy', 'ball', 'person'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path],
+ Fields.video_frame_tags: [[
+ 'woman', 'table', 'girl', 'sit', 'person', 'laptop',
+ 'bookshelf', 'conversation', 'round table', 'computer', 'man',
+ 'closet', 'stool', 'computer screen', 'laugh', 'cabinet',
+ 'hand', 'selfie', 'stand'
+ ]]
+ }]
+ op = VideoTaggingFromFramesMapper()
+ self._run_video_tagging_from_frames_mapper(op, ds_list, tgt_list)
+
+ def test_uniform(self):
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path],
+ Fields.video_frame_tags: [[
+ 'animal', 'cartoon', 'anime', 'game', 'screenshot',
+ 'video game', 'robe', 'ray', 'text', 'writing', 'yellow',
+ 'doll', 'tail', 'cartoon character', 'sky', 'person'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path],
+ Fields.video_frame_tags: [[
+ 'man', 'shirt', 't shirt', 't-shirt', 'wear', 'white', 'boy',
+ 'hand', 'catch', 'bulletin board', 'blind', 'play', 'Wii',
+ 'cotton candy', 'tennis racket', 'game controller', 'remote',
+ 'stand', 'video game', 'Wii controller', 'racket',
+ 'baseball uniform', 'toy', 'green'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path],
+ Fields.video_frame_tags: [[
+ 'table', 'sit', 'woman', 'bookshelf', 'conversation', 'person',
+ 'round table', 'computer', 'girl', 'laptop', 'man', 'closet',
+ 'stand', 'computer screen', 'talk', 'room', 'stool', 'hand',
+ 'point'
+ ]]
+ }]
+ op = VideoTaggingFromFramesMapper(frame_sampling_method='uniform',
+ frame_num=10)
+ self._run_video_tagging_from_frames_mapper(op, ds_list, tgt_list)
+
+ def test_multi_process(self):
+ # WARNING: current parallel tests only work in spawn method
+ import multiprocess
+ original_method = multiprocess.get_start_method()
+ multiprocess.set_start_method('spawn', force=True)
+ # WARNING: current parallel tests only work in spawn method
+ ds_list = [{
+ 'text': f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。',
+ 'videos': [self.vid1_path],
+ Fields.video_frame_tags: [[
+ 'animal', 'ray', 'text', 'writing', 'yellow', 'game',
+ 'screenshot', 'cartoon', 'cartoon character', 'person', 'robe',
+ 'sky'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}',
+ 'videos': [self.vid2_path],
+ Fields.video_frame_tags: [[
+ 'man', 'shirt', 't shirt', 't-shirt', 'wear', 'white', 'boy',
+ 'catch', 'hand', 'blind', 'cotton candy', 'ball', 'person'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid3_path],
+ Fields.video_frame_tags: [[
+ 'woman', 'table', 'girl', 'sit', 'person', 'laptop',
+ 'bookshelf', 'conversation', 'round table', 'computer', 'man',
+ 'closet', 'stool', 'computer screen', 'laugh', 'cabinet',
+ 'hand', 'selfie', 'stand'
+ ]]
+ }]
+ op = VideoTaggingFromFramesMapper()
+ self._run_video_tagging_from_frames_mapper(op,
+ ds_list,
+ tgt_list,
+ num_proc=2)
+ # WARNING: current parallel tests only work in spawn method
+ multiprocess.set_start_method(original_method, force=True)
+ # WARNING: current parallel tests only work in spawn method
+
+ def test_multi_chunk(self):
+ ds_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid2_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid2_path, self.vid3_path]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid1_path, self.vid3_path]
+ }]
+ tgt_list = [{
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。',
+ 'videos': [self.vid1_path, self.vid2_path],
+ Fields.video_frame_tags:
+ [[
+ 'animal', 'ray', 'text', 'writing', 'yellow', 'game',
+ 'screenshot', 'cartoon', 'cartoon character', 'person', 'robe',
+ 'sky'
+ ],
+ [
+ 'man', 'shirt', 't shirt', 't-shirt', 'wear', 'white', 'boy',
+ 'catch', 'hand', 'blind', 'cotton candy', 'ball', 'person'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid2_path, self.vid3_path],
+ Fields.video_frame_tags: [[
+ 'man', 'shirt', 't shirt', 't-shirt', 'wear', 'white', 'boy',
+ 'catch', 'hand', 'blind', 'cotton candy', 'ball', 'person'
+ ],
+ [
+ 'woman', 'table', 'girl', 'sit',
+ 'person', 'laptop', 'bookshelf',
+ 'conversation', 'round table',
+ 'computer', 'man', 'closet', 'stool',
+ 'computer screen', 'laugh',
+ 'cabinet', 'hand', 'selfie', 'stand'
+ ]]
+ }, {
+ 'text':
+ f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。{SpecialTokens.eoc}{SpecialTokens.video} 两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.eoc}',
+ 'videos': [self.vid1_path, self.vid3_path],
+ Fields.video_frame_tags: [[
+ 'animal', 'ray', 'text', 'writing', 'yellow', 'game',
+ 'screenshot', 'cartoon', 'cartoon character', 'person', 'robe',
+ 'sky'
+ ],
+ [
+ 'woman', 'table', 'girl', 'sit',
+ 'person', 'laptop', 'bookshelf',
+ 'conversation', 'round table',
+ 'computer', 'man', 'closet', 'stool',
+ 'computer screen', 'laugh',
+ 'cabinet', 'hand', 'selfie', 'stand'
+ ]]
+ }]
+ op = VideoTaggingFromFramesMapper()
+ self._run_video_tagging_from_frames_mapper(op, ds_list, tgt_list)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/ops/mapper/test_whitespace_normalization_mapper.py b/tests/ops/mapper/test_whitespace_normalization_mapper.py
index 0bffdf60c..985cc7076 100644
--- a/tests/ops/mapper/test_whitespace_normalization_mapper.py
+++ b/tests/ops/mapper/test_whitespace_normalization_mapper.py
@@ -2,9 +2,10 @@
from data_juicer.ops.mapper.whitespace_normalization_mapper import \
WhitespaceNormalizationMapper
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class WhitespaceNormalizationMapperTest(unittest.TestCase):
+class WhitespaceNormalizationMapperTest(DataJuicerTestCaseBase):
def setUp(self):
self.op = WhitespaceNormalizationMapper()
diff --git a/tests/ops/selector/test_frequency_specified_field_selector.py b/tests/ops/selector/test_frequency_specified_field_selector.py
index 8e6e32440..4593e83ef 100644
--- a/tests/ops/selector/test_frequency_specified_field_selector.py
+++ b/tests/ops/selector/test_frequency_specified_field_selector.py
@@ -4,9 +4,10 @@
from data_juicer.ops.selector.frequency_specified_field_selector import \
FrequencySpecifiedFieldSelector
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class FrequencySpecifiedFieldSelectorTest(unittest.TestCase):
+class FrequencySpecifiedFieldSelectorTest(DataJuicerTestCaseBase):
def _run_frequency_selector(self, dataset: Dataset, target_list, op):
dataset = op.process(dataset)
diff --git a/tests/ops/selector/test_topk_specified_field_selector.py b/tests/ops/selector/test_topk_specified_field_selector.py
index 0f386a1e2..f10129ded 100644
--- a/tests/ops/selector/test_topk_specified_field_selector.py
+++ b/tests/ops/selector/test_topk_specified_field_selector.py
@@ -4,9 +4,10 @@
from data_juicer.ops.selector.topk_specified_field_selector import \
TopkSpecifiedFieldSelector
+from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase
-class TopkSpecifiedFieldSelectorTest(unittest.TestCase):
+class TopkSpecifiedFieldSelectorTest(DataJuicerTestCaseBase):
def _run_topk_selector(self, dataset: Dataset, target_list, op):
dataset = op.process(dataset)
diff --git a/tests/ops/test_op_fusion.py b/tests/ops/test_op_fusion.py
index 7f13ad431..ad50ba472 100644
--- a/tests/ops/test_op_fusion.py
+++ b/tests/ops/test_op_fusion.py
@@ -1,11 +1,12 @@
import unittest
from data_juicer.ops.load import load_ops
-from data_juicer.utils.unittest_utils import SKIPPED_TESTS
+from data_juicer.utils.unittest_utils import (SKIPPED_TESTS,
+ DataJuicerTestCaseBase)
@SKIPPED_TESTS.register_module()
-class OpFusionTest(unittest.TestCase):
+class OpFusionTest(DataJuicerTestCaseBase):
def _run_op_fusion(self, original_process_list, target_process_list):
new_process_list, _ = load_ops(original_process_list, op_fusion=True)
@@ -165,9 +166,9 @@ def test_regular_config(self):
}
},
{
- 'OpFusion:(words_num_filter,word_repetition_filter,stopwords_filter,flagged_words_filter,perplexity_filter)':
+ 'OpFusion:(words_num_filter,word_repetition_filter,stopwords_filter,flagged_words_filter,perplexity_filter)': # noqa: E501
[
- { # noqa: E501
+ {
'words_num_filter': {
'lang': 'en',
'max_num': 100000,
@@ -622,9 +623,9 @@ def test_multiple_groups(self):
}
},
{
- 'OpFusion:(words_num_filter,word_repetition_filter,perplexity_filter)':
+ 'OpFusion:(words_num_filter,word_repetition_filter,perplexity_filter)': # noqa: E501
[
- { # noqa: E501
+ {
'words_num_filter': {
'lang': 'en',
'max_num': 100000,
@@ -713,9 +714,9 @@ def test_only_fusible_ops(self):
}
}]
target_process = [{
- 'OpFusion:(words_num_filter,word_repetition_filter,stopwords_filter,flagged_words_filter,perplexity_filter)':
+ 'OpFusion:(words_num_filter,word_repetition_filter,stopwords_filter,flagged_words_filter,perplexity_filter)': # noqa: E501
[
- { # noqa: E501
+ {
'words_num_filter': {
'lang': 'en',
'max_num': 100000,
@@ -931,9 +932,9 @@ def test_different_intermediate_vars(self):
}
},
{
- 'OpFusion:(average_line_length_filter,maximum_line_length_filter)':
+ 'OpFusion:(average_line_length_filter,maximum_line_length_filter)': # noqa: E501
[
- { # noqa: E501
+ {
'average_line_length_filter': {
'min_len': 10,
'text_key': 'text',
@@ -948,9 +949,9 @@ def test_different_intermediate_vars(self):
]
},
{
- 'OpFusion:(words_num_filter,word_repetition_filter,stopwords_filter,flagged_words_filter,perplexity_filter)':
+ 'OpFusion:(words_num_filter,word_repetition_filter,stopwords_filter,flagged_words_filter,perplexity_filter)': # noqa: E501
[
- { # noqa: E501
+ {
'words_num_filter': {
'lang': 'en',
'max_num': 100000,
diff --git a/tools/multimodal/README.md b/tools/multimodal/README.md
index 33f2ddcb4..7b1426c2d 100644
--- a/tools/multimodal/README.md
+++ b/tools/multimodal/README.md
@@ -69,11 +69,15 @@ These tools consist of two types:
For now, dataset formats that are supported by Data-Juicer are listed in the following table.
-| Format | Type | source_format_to_data_juicer_format | data_juicer_format_to_target_format | Ref. |
-|------------|------------|-------------------------------------|-------------------------------------|------------------------------------------------------------------------------------------------------------------|
-| LLaVA-like | image-text | `llava_to_dj.py` | `dj_to_llava.py` | [Format Description](https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md#dataset-format) |
-| MMC4-like | image-text | `mmc4_to_dj.py` | `dj_to_mmc4.py` | [Format Description](https://github.com/allenai/mmc4#documents) |
-| WavCaps-like | audio-text | `wavcaps_to_dj.py` | `dj_to_wavcaps.py` | [Format Description](https://github.com/XinhaoMei/WavCaps#table-of-contents) |
+| Format | Type | source_format_to_data_juicer_format | data_juicer_format_to_target_format | Ref. |
+|--------------------|------------|-------------------------------------|-------------------------------------|------------------------------------------------------------------------------------------------------------------|
+| LLaVA-like | image-text | `llava_to_dj.py` | `dj_to_llava.py` | [Format Description](https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md#dataset-format) |
+| MMC4-like | image-text | `mmc4_to_dj.py` | `dj_to_mmc4.py` | [Format Description](https://github.com/allenai/mmc4#documents) |
+| WavCaps-like | audio-text | `wavcaps_to_dj.py` | `dj_to_wavcaps.py` | [Format Description](https://github.com/XinhaoMei/WavCaps#table-of-contents) |
+| Video-ChatGPT-like | video-text | `video_chatgpt_to_dj.py` | `dj_to_video_chatgpt.py` | [Format Description]( https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data) | |
+| Youku-mPLUG-like | video-text | `youku_to_dj.py` | `dj_to_youku.py` | [Format Description](https://modelscope.cn/datasets/modelscope/Youku-AliceMind/summary) | |
+| InternVid-like | video-text | `internvid_to_dj.py` | `dj_to_internvid.py` | [Format Description](https://huggingface.co/datasets/OpenGVLab/InternVid) | |
+
For all tools, you can run the following command to find out the usage of them:
@@ -161,7 +165,7 @@ Users should be cautious about this point if you need this matrix in later usage
Despite these extra fields, tools for MMC4 can perfectly convert MMC4-like datasets to Data-Juicer-format datasets and convert them back~
-### WavCaps-like
+#### WavCaps-like
The [WavCaps](https://github.com/XinhaoMei/WavCaps#dataset) is composed of four sub-datasets: [FreeSound](https://freesound.org/), [BBC Sound Effects](https://sound-effects.bbcrewind.co.uk/),[SoundBible](https://soundbible.com/) and [AudioSet Strongly-labelled Subset](https://research.google.com/audioset/download_strong.html). Each sub-dataset has different fields. For example, the 'description' field is included in SoundBible, but does not exist in AudioSet. To ensure that the different sub-datasets can be properly merged after conversion, the union of all fields from the sub-datasets is used during the wavcaps_to_dj stage, and all fields are fully retained during the dj_to_wavcaps stage.
@@ -196,3 +200,35 @@ The [WavCaps](https://github.com/XinhaoMei/WavCaps#dataset) is composed of four
"tags": "" }]
}
```
+
+#### Video-ChatGPT-like
+
+The Video-ChatGPT dataset contains 3 types of data with unified format:
+- Topics for Video summarization
+- Description-based question-answers (exploring spatial, temporal, relationships, and reasoning concepts);
+- and Creative/generative question-answers.
+They all obey the `` format, where the `video_id` is in the form "v_youtube_id". We suppose that users have downloaded these videos already, and they need to specify the corresponding storage directory when using the converter tool.
+
+
+
+#### Youku-mPLUG-like
+
+The Youku-mPLUG dataset contains 4 types of format: pretrain, classification, retrieval, captioning.
+They are slightly different from each other in field name or other attributes, but all of them obey the `` format.
+
+#### InternVid-like
+
+The InternVid dataset contains 4 fields:
+- `YoutubeID`: the Youtube ID of the video used in the sample.
+We suppose that users have downloaded these videos already
+and this field is replaced with its storage path.
+- `Start_timestamp`: the start timestamp in string of the video clip for the
+corresponding caption.
+- `End_timestamp`: the end timestamp in string of the video clip for the
+corresponding caption.
+- `Caption`: the corresponding caption for the video clip.
+
+As we can see, the caption in this dataset corresponds to the video clip
+specified by the start/end timestamps instead of the whole video. So the
+conversion tool will cut the specified video clip for you if the argument
+`cut_videos` is set to True. You can cut before conversion by yourself as well.
diff --git a/tools/multimodal/README_ZH.md b/tools/multimodal/README_ZH.md
index 996bdbb54..8e29df36f 100644
--- a/tools/multimodal/README_ZH.md
+++ b/tools/multimodal/README_ZH.md
@@ -62,11 +62,14 @@
目前,Data-Juicer 支持的数据集格式在下面表格中列出。
-| 格式 | 类型 | source_format_to_data_juicer_format | data_juicer_format_to_target_format | 格式参考 |
-|----------|-------|-------------------------------------|-------------------------------------|----------------------------------------------------------------------------------------------------|
-| 类LLaVA格式 | 图像-文本 | `llava_to_dj.py` | `dj_to_llava.py` | [格式描述](https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md#dataset-format) |
-| 类MMC4格式 | 图像-文本 | `mmc4_to_dj.py` | `dj_to_mmc4.py` | [格式描述](https://github.com/allenai/mmc4#documents) |
-| 类WavCaps格式 | 音频-文本 | `wavcaps_to_dj.py` | `dj_to_wavcaps.py` | [格式描述](https://github.com/XinhaoMei/WavCaps#table-of-contents) |
+| 格式 | 类型 | source_format_to_data_juicer_format | data_juicer_format_to_target_format | 格式参考 |
+|------------------|-------|-------------------------------------|-------------------------------------|----------------------------------------------------------------------------------------------------|
+| 类LLaVA格式 | 图像-文本 | `llava_to_dj.py` | `dj_to_llava.py` | [格式描述](https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md#dataset-format) |
+| 类MMC4格式 | 图像-文本 | `mmc4_to_dj.py` | `dj_to_mmc4.py` | [格式描述](https://github.com/allenai/mmc4#documents) |
+| 类WavCaps格式 | 音频-文本 | `wavcaps_to_dj.py` | `dj_to_wavcaps.py` | [格式描述](https://github.com/XinhaoMei/WavCaps#table-of-contents) |
+| 类Video-ChatGPT格式 |视频-文本 | `video_chatgpt_to_dj.py` | `dj_to_video_chatgpt.py` | [格式描述]( https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data) | |
+| 类Youku-mPLUG格式 | 视频-文本 | `youku_to_dj.py` | `dj_to_youku.py` | [格式描述](https://modelscope.cn/datasets/modelscope/Youku-AliceMind/summary) | |
+| 类InternVid格式 | 视频-文本 | `internvid_to_dj.py` | `dj_to_internvid.py` | [格式描述](https://huggingface.co/datasets/OpenGVLab/InternVid) | |
对于所有工具,您可以运行以下命令来了解它们的详细用法:
@@ -168,3 +171,27 @@ python tools/multimodal/source_format_to_data_juicer_format/llava_to_dj.py --hel
"tags": "" }]
}
```
+
+#### 类Video-ChatGPT格式
+Video-ChatGPT数据集包含3种统一格式的数据:
+- 视频摘要主题
+- 基于描述的问题答案(探索空间、时间、关系和推理概念);
+- 以及创意/生成性问题解答。
+它们都遵循“”格式,其中“video_id”表示为YouTube视频的id:“v_youtube_id”。 我们假设用户已经下载了这些视频,在使用转换工具时需要指定相应的存储目录。
+#### 类Youku-mPLUG格式
+
+Youku-mPLUG数据集中一共有4种类型的格式:pretrain,classification,
+retrieval,captioning。它们在字段名称或者其他属性上会有轻微的差异,但是所有类型都遵从 `` 的格式。
+
+#### 类InternVid格式
+
+InternVid数据集包括4个字段:
+- `YoutubeID`: 样本中使用的视频的Youtube ID。我们假设用户已经下载了这些视频,
+并且这个字段已经被替换为了视频的存储路径。
+- `Start_timestamp`: 与caption对应的视频片段的开始时间戳字符串。
+- `End_timestamp`: 与caption对应的视频片段的结束时间戳字符串
+- `Caption`: 与视频片段对应的caption。
+
+正如我们看到,该数据集中的caption对应到了一段由开始/结束时间戳指定的视频片段,而非整段视频。
+因此,如果 `cut_videos` 参数设置为 True,针对该数据集的转换工具会为您剪辑出指定的视频片段。
+您也可以在转换前自行对下载的视频进行剪辑。
diff --git a/tools/multimodal/__init__.py b/tools/multimodal/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/tools/multimodal/data_juicer_format_to_target_format/dj_to_internvid.py b/tools/multimodal/data_juicer_format_to_target_format/dj_to_internvid.py
new file mode 100644
index 000000000..89d1e8a38
--- /dev/null
+++ b/tools/multimodal/data_juicer_format_to_target_format/dj_to_internvid.py
@@ -0,0 +1,154 @@
+# This tool is used to convert multimodal dataset in Data-Juicer format to a
+# target dataset in InternVid format.
+#
+# Data-Juicer format:
+# - two extra fields:
+# - text: a chunk of text with the video special token.
+# - videos: video paths list, including cut videos according to their timestamps # noqa: E501
+# - other fields in the original format can be kept or not
+# - in jsonl
+# {'videos': ['videos/qJrOyggIB-w-cut.mp4'],
+# 'text': 'a screen shot of heroes of the storm with people in action',
+# 'Start_timestamp': '00:07:33.689',
+# 'End_timestamp': '00:07:51.085',
+# 'Aesthetic_Score': 4.29296875,
+# 'UMT_Score': 0.4501953125}
+#
+# Corresponding InternVid format:
+# - in jsonl
+# - restore to Caption and YoutubeID
+# {'YoutubeID': 'videos/qJrOyggIB-w.mp4',
+# 'Start_timestamp': '00:07:33.689',
+# 'End_timestamp': '00:07:51.085',
+# 'Caption': 'a screen shot of heroes of the storm with people in action',
+# 'Aesthetic_Score': 4.29296875,
+# 'UMT_Score': 0.4501953125}
+#
+# Reference:
+# https://huggingface.co/datasets/OpenGVLab/InternVid
+
+import os
+
+import fire
+import jsonlines as jl
+from loguru import logger
+from tqdm import tqdm
+
+from data_juicer.utils.mm_utils import SpecialTokens
+from tools.multimodal.utils import remove_dj_special_tokens
+
+
+def main(
+ dj_ds_path: str,
+ target_internvid_ds_path: str,
+ eoc_special_token: str = SpecialTokens.eoc,
+ video_special_token: str = SpecialTokens.video,
+ sent_seperator: str = ' ',
+ convert_to_relative_paths: bool = False,
+ original_internvid_ds_path: str = None,
+):
+ """
+ Convert a Data-Juicer-format dataset to a InternVid-like dataset.
+
+ :param dj_ds_path: path to the input dataset in Data-Juicer format.
+ :param target_internvid_ds_path: path to store the converted dataset in
+ InternVid format.
+ :param eoc_special_token: the special token for "end of a chunk". It's used
+ to split sentence chunks explicitly. Default: <|__dj__eoc|> (from
+ Data-Juicer).
+ :param video_special_token: the special token for videos. It's used to
+ locate the videos in the text. In typical InternVide-like datasets,
+ this special token is not specified. So we simply use the default video
+ special token from our Data-Juicer. Default: <__dj__video> (from
+ Data-Juicer).
+ :param sent_seperator: seperator to split different sentences. Default: " "
+ :param convert_to_relative_paths: whether convert the video paths in this
+ dataset to relative paths to the original dataset. If it's True, an
+ extra argument original_internvid_ds_path is required. When the
+ processed and converted dataset will be used in another machine, it's
+ better to set this argument to True. Default: False.
+ :param original_internvid_ds_path: path to the original unprocessed
+ InternVid dataset, which is used to help to recover the relative video
+ paths for better migration. Default: None.
+ """
+ # ----- Constant settings. Better not to change them. -----
+ text_key = 'text' # default key of field to store the sample text
+ video_key = 'videos' # default key of field to store the video list
+ tgt_text_key = 'Caption' # default target key of field to store texts
+ tgt_video_key = 'YoutubeID' # default target field to store videos
+ # ----- Constant settings. Better not to change them. -----
+
+ # check arguments
+ # check paths
+ if not os.path.exists(dj_ds_path):
+ raise FileNotFoundError(
+ f'Input dataset [{dj_ds_path}] can not be found.')
+ if not target_internvid_ds_path.endswith('.jsonl'):
+ raise ValueError(
+ 'Only support "jsonl" target dataset file for InternVid now.')
+ if os.path.dirname(target_internvid_ds_path) \
+ and not os.path.exists(os.path.dirname(target_internvid_ds_path)):
+ logger.info(
+ f'Create directory [{os.path.dirname(target_internvid_ds_path)}] '
+ f'for the target dataset.')
+ os.makedirs(os.path.dirname(target_internvid_ds_path))
+ # if convert_to_relative_paths is True, check if the
+ # original_internvid_ds_path is provided as well.
+ if convert_to_relative_paths:
+ if not original_internvid_ds_path:
+ raise ValueError('When convert_to_relative_paths is set to True, '
+ 'the original_internvid_ds_path must be provided '
+ 'for recovering the relative paths. Please '
+ 'check and retry.')
+ original_internvid_ds_path = os.path.abspath(
+ original_internvid_ds_path)
+ # if provided original_internvid_ds_path is the dataset file path, only
+ # keep the directory path.
+ if os.path.isfile(original_internvid_ds_path):
+ original_internvid_ds_path = os.path.dirname(
+ original_internvid_ds_path)
+
+ # save InternVid dataset from Data-Juicer format
+ logger.info('Start converting the original dataset to InternVid format...')
+ with jl.open(dj_ds_path) as reader:
+ with jl.open(target_internvid_ds_path, mode='w') as writer:
+ for line_num, s in enumerate(tqdm(reader)):
+ video = s.pop(video_key)[0]
+ text = s.pop(text_key)
+
+ new_sample = {}
+ # add other fields
+ for key in s:
+ new_sample[key] = s[key]
+
+ # add video
+ if convert_to_relative_paths:
+ if video.startswith(original_internvid_ds_path):
+ video = os.path.relpath(video,
+ original_internvid_ds_path)
+ else:
+ raise ValueError(
+ f'The original_internvid_ds_path '
+ f'[{original_internvid_ds_path}] is not the '
+ f'directory that contains the video '
+ f'[{video}] in the sample of line number '
+ f'[{line_num}]. Please check if the correct '
+ f'original_internvid_ds_path is provided or '
+ f'something wrong with this sample, and try '
+ f'again later.')
+ new_sample[tgt_video_key] = video
+
+ # add caption
+ text = remove_dj_special_tokens(text.strip(),
+ eoc_special_token,
+ sent_seperator,
+ video_special_token)
+
+ new_sample[tgt_text_key] = text
+
+ writer.write(new_sample)
+ logger.info(f'Store the target dataset into [{target_internvid_ds_path}].')
+
+
+if __name__ == '__main__':
+ fire.Fire(main)
diff --git a/tools/multimodal/data_juicer_format_to_target_format/dj_to_mmc4.py b/tools/multimodal/data_juicer_format_to_target_format/dj_to_mmc4.py
index c3ccf8faa..8c7c4dc0d 100644
--- a/tools/multimodal/data_juicer_format_to_target_format/dj_to_mmc4.py
+++ b/tools/multimodal/data_juicer_format_to_target_format/dj_to_mmc4.py
@@ -128,7 +128,7 @@ def main(
Data-Juicer, such as "images", "text", ... Default: False.
:param convert_to_relative_paths: whether convert the image paths in this
dataset to relative paths to the original dataset. If it's True, an
- extra argument original_llava_ds_path is required. When the processed
+ extra argument original_mmc4_ds_path is required. When the processed
and converted dataset will be used in another machine, it's better to
set this argument to True. Default: False.
:param original_mmc4_ds_path: path to the original unprocessed MMC4
@@ -157,7 +157,7 @@ def main(
f'the target dataset.')
os.makedirs(os.path.dirname(target_mmc4_ds_path))
- # if convert_to_relative_paths is True, check if the original_llava_ds_path
+ # if convert_to_relative_paths is True, check if the original_mmc4_ds_path
# is provided as well.
if convert_to_relative_paths:
if not original_mmc4_ds_path:
diff --git a/tools/multimodal/data_juicer_format_to_target_format/dj_to_video_chatgpt.py b/tools/multimodal/data_juicer_format_to_target_format/dj_to_video_chatgpt.py
new file mode 100644
index 000000000..27b1ddb9f
--- /dev/null
+++ b/tools/multimodal/data_juicer_format_to_target_format/dj_to_video_chatgpt.py
@@ -0,0 +1,167 @@
+# This tool is used to convert multimodal dataset in Data-Juicer format to a
+# target dataset in Video-ChatGPT format.
+#
+# Reference:
+# https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data
+#
+# # Corresponding Data-Juicer format:
+# - two new fields to store the main data: 'youtube_id' and 'text',
+# the 'videos' is actual path to the video files
+# {'youtube_id': 'k_ZXmr8pmrs',
+# 'videos': ['youtube_video_dir/v_k_ZXmr8pmrs.mp4'],
+# 'text':
+# '<__dj__video>'
+# '[[q]]: What are the main activities that take place in the video? \n'
+# '[[a]]: The main activities that take place in the video are the
+# preparation of camera equipment by a man.... <|__dj__eoc|>'
+# }
+#
+# Video-ChatGPT format:
+# - Topics for Video summarization; Description-based question-answers
+# (exploring spatial, temporal, relationships, and reasoning concepts);
+# and Creative/generative question-answers
+# - in json file, a single line storing text-video tuples in a list,
+# below is an example
+#
+# [{'q': 'What are the main activities that take place in the video?',
+# 'a': 'The main activities that take place in the video are the preparation of
+# camera equipment by a man, a group of men riding a helicopter, and a man
+# sailing a boat through the water.',
+# 'video_id': 'v_k_ZXmr8pmrs'}, ...]
+#
+import json
+import os
+
+import fire
+import jsonlines as jl
+from loguru import logger
+from tqdm import tqdm
+
+from data_juicer.utils.mm_utils import SpecialTokens
+from tools.multimodal.utils import remove_dj_special_tokens
+
+
+def main(
+ dj_ds_path: str,
+ target_video_chatgpt_ds_path: str,
+ eoc_special_token: str = SpecialTokens.eoc,
+ video_special_token: str = SpecialTokens.video,
+ sent_seperator: str = ' ',
+ convert_to_relative_paths: bool = False,
+ original_video_chatgpt_ds_path: str = None,
+):
+ """
+ Convert a Data-Juicer-format dataset to a Video-ChatGPT-like dataset.
+
+ :param dj_ds_path: path to the input dataset in Data-Juicer format.
+ :param target_video_chatgpt_ds_path: path to store the converted dataset in
+ Video-ChatGPT format.
+ :param eoc_special_token: the special token for "end of a chunk". It's used
+ to split sentence chunks explicitly. Default: <|__dj__eoc|> (from
+ Data-Juicer).
+ :param video_special_token: the special token for videos. It's used to
+ locate the videos in the text. In typical Video-ChatGPT-like datasets,
+ this special token is not specified. So we simply use the default video
+ special token from our Data-Juicer. Default: <__dj__video> (from
+ Data-Juicer).
+ :param sent_seperator: seperator to split different sentences. Default: " "
+ :param convert_to_relative_paths: whether convert the video paths in this
+ dataset to relative paths to the original dataset. If it's True, an
+ extra argument original_video_chatgpt_ds_path is required. When the
+ processed and converted dataset will be used in another machine, it's
+ better to set this argument to True. Default: False.
+ :param original_video_chatgpt_ds_path: path to the original unprocessed
+ Video-ChatGPT dataset, which is used to help to recover the relative video
+ paths for better migration. Default: None.
+ """
+ # ----- Constant settings. Better not to change them. -----
+ text_key = 'text' # default key of field to store the sample text
+ video_key = 'videos' # default key of field to store video files path
+ video_id_key = 'youtube_id' # default key of field to store youtube id
+ tgt_q_key = 'q' # default original key of field to store texts
+ tgt_a_key = 'a'
+ tgt_video_key = 'video_id' # default original field to store videos
+ # ----- Constant settings. Better not to change them. -----
+
+ # check arguments
+ if not os.path.exists(dj_ds_path):
+ raise FileNotFoundError(f'Input Video_ChatGPT dataset in dj format, '
+ f'[{dj_ds_path}], can not be found.')
+ if not target_video_chatgpt_ds_path.endswith('.json'):
+ raise ValueError(
+ 'Only support "json" target dataset file for Video_ChatGPT now.')
+ if (os.path.dirname(target_video_chatgpt_ds_path) and
+ not os.path.exists(os.path.dirname(target_video_chatgpt_ds_path))):
+ logger.info(f'Create directory '
+ f'[{os.path.dirname(target_video_chatgpt_ds_path)}] '
+ f'for the target dataset.')
+ os.makedirs(os.path.dirname(target_video_chatgpt_ds_path))
+
+ # if convert_to_relative_paths is True, check if the
+ # original_video_chatgpt_ds_path is provided as well.
+ if convert_to_relative_paths:
+ if not original_video_chatgpt_ds_path:
+ raise ValueError(
+ 'When convert_to_relative_paths is set to True, '
+ 'the original_video_chatgpt_ds_path must be provided '
+ 'for recovering the relative paths. Please '
+ 'check and retry.')
+ original_video_chatgpt_ds_path = os.path.abspath(
+ original_video_chatgpt_ds_path)
+ # if provided original_video_chatgpt_ds_path is the dataset file path,
+ # only keep the directory path.
+ if os.path.isfile(original_video_chatgpt_ds_path):
+ original_video_chatgpt_ds_path = os.path.dirname(
+ original_video_chatgpt_ds_path)
+
+ # save Video-ChatGPT dataset from Data-Juicer format
+ logger.info('Start converting the DJ dataset to Video-ChatGPT format...')
+ all_samples = []
+ with jl.open(dj_ds_path) as reader:
+ for line_num, s in enumerate(tqdm(reader)):
+ video_path = s.pop(video_key)[0]
+ new_sample = {}
+
+ video_id = s.pop(video_id_key)
+ new_sample[tgt_video_key] = 'v_' + video_id
+ # add video
+ if convert_to_relative_paths:
+ if video_path.startswith(original_video_chatgpt_ds_path):
+ video_path = os.path.relpath(
+ video_path, original_video_chatgpt_ds_path)
+ else:
+ raise ValueError(
+ f'The original_video_chatgpt_ds_path '
+ f'[{original_video_chatgpt_ds_path}] is not the '
+ f'directory that contains the video '
+ f'[{video_path}] in the sample of line number '
+ f'[{line_num}]. Please check if the correct '
+ f'original_video_chatgpt_ds_path is provided or '
+ f'something wrong with this sample, and try '
+ f'again later.')
+ new_sample[video_key] = video_path
+
+ # add question and answer
+ text = s.pop(text_key).strip()
+ text = remove_dj_special_tokens(text, eoc_special_token,
+ sent_seperator,
+ video_special_token)
+ # get the question and answer
+ parts = text.split(f'[[{tgt_q_key}]]:')[1]
+ q, a = parts.split(f'[[{tgt_a_key}]]:')
+ new_sample[tgt_q_key] = q.strip()
+ new_sample[tgt_a_key] = a.strip()
+
+ # add other fields
+ for key in s:
+ if key not in [tgt_q_key, tgt_a_key]:
+ new_sample[key] = s[key]
+
+ all_samples.append(new_sample)
+ with open(target_video_chatgpt_ds_path, 'w') as file:
+ json.dump(all_samples, file)
+ logger.info(f'Store the dataset into [{target_video_chatgpt_ds_path}].')
+
+
+if __name__ == '__main__':
+ fire.Fire(main)
diff --git a/tools/multimodal/data_juicer_format_to_target_format/dj_to_youku.py b/tools/multimodal/data_juicer_format_to_target_format/dj_to_youku.py
new file mode 100644
index 000000000..923576b70
--- /dev/null
+++ b/tools/multimodal/data_juicer_format_to_target_format/dj_to_youku.py
@@ -0,0 +1,214 @@
+# This tool is used to convert multimodal dataset in Data-Juicer format to a
+# target dataset in Youku-mPLUG-like format.
+#
+# Corresponding Data-Juicer format:
+# - two new fields to store the main data:
+# - text: a chunk of text with the video special token.
+# - videos: video paths list
+# - other fields in the original format can be kept or not
+# - in jsonl
+#
+# Youku-mPLUG-pretrain Data-Juicer format:
+# {'videos': ['videos/pretrain/14111Y1211b-1134b18bAE55bFE7Jbb7135YE3aY54EaB14ba7CbAa1AbACB24527A.flv'], # noqa: E501
+# 'text': '<__dj__video> 妈妈给宝宝听胎心,看看宝宝是怎么做的,太调皮了 <|__dj__eoc|>'}
+#
+# Youku-mPLUG-classification Data-Juicer format:
+# {'videos': ['videos/classification/14111B1211bFBCBCJYF48B55b7523C51F3-8b3a5YbCa5817aBb38a5YAC-241F71J.mp4'], # noqa: E501
+# 'text': '<__dj__video> 兔宝宝刚出生,为什么兔妈妈要把它们吃掉?看完涨见识了 <|__dj__eoc|>',
+# 'label': '宠物'}
+#
+# Youku-mPLUG-retrieval Data-Juicer format:
+# {'videos': ['videos/retrieval/14111B1211bA1F31-E-2YB57--C518FCEBC553abJYFa5541a31C8a57522AYJbYF4aTdfofa112.mp4'], # noqa: E501
+# 'text': '<__dj__video> 身穿黑色上衣戴着头盔的女子在路上骑着摩托车四周还停放了一些车 <|__dj__eoc|>'}
+#
+# Youku-mPLUG-captioning Data-Juicer format:
+# {'videos': ['videos/caption/14111B1211bEJB-1b3b-J3b7b8Y213BJ32-521a1EA8a53-3aBA72aA-4-2-CF1EJ8aTdfofa114.mp4'], # noqa: E501
+# 'text': '<__dj__video> 穿白色球服的女生高高跳起,接住了球。 <|__dj__eoc|> <__dj__video> 一排穿红色短袖的女生正在接受颁奖。 <|__dj__eoc|>']} # noqa: E501
+#
+# Youku-mPLUG format:
+# - 4 types: pretrain, classification, retrieval, captioning
+# - in csv
+# - text-video pair with other fields (label, ...)
+#
+# Youku-mPLUG-pretrain format:
+# {'video_id:FILE': 'videos/pretrain/14111Y1211b-1134b18bAE55bFE7Jbb7135YE3aY54EaB14ba7CbAa1AbACB24527A.flv', # noqa: E501
+# 'title': '妈妈给宝宝听胎心,看看宝宝是怎么做的,太调皮了'}
+#
+# Youku-mPLUG-classification format:
+# {'video_id:FILE': 'videos/classification/14111B1211bFBCBCJYF48B55b7523C51F3-8b3a5YbCa5817aBb38a5YAC-241F71J.mp4', # noqa: E501
+# 'title': '兔宝宝刚出生,为什么兔妈妈要把它们吃掉?看完涨见识了',
+# 'label': '宠物'}
+#
+# Youku-mPLUG-retrieval format:
+# {'clip_name:FILE': 'videos/retrieval/14111B1211bA1F31-E-2YB57--C518FCEBC553abJYFa5541a31C8a57522AYJbYF4aTdfofa112.mp4', # noqa: E501
+# 'caption': '身穿黑色上衣戴着头盔的女子在路上骑着摩托车四周还停放了一些车'}
+#
+# Youku-mPLUG-captioning format:
+# {'video_id:FILE': 'videos/caption/14111B1211bEJB-1b3b-J3b7b8Y213BJ32-521a1EA8a53-3aBA72aA-4-2-CF1EJ8aTdfofa114.mp4', # noqa: E501
+# 'golden_caption': '穿白色球服的女生高高跳起,接住了球。']}
+#
+# Reference:
+# https://modelscope.cn/datasets/modelscope/Youku-AliceMind/summary
+
+import csv
+import os
+
+import fire
+import jsonlines as jl
+from loguru import logger
+from tqdm import tqdm
+
+from data_juicer.utils.mm_utils import SpecialTokens
+from tools.multimodal.utils import remove_dj_special_tokens
+
+
+def main(
+ dj_ds_path: str,
+ target_youku_ds_path: str,
+ eoc_special_token: str = SpecialTokens.eoc,
+ video_special_token: str = SpecialTokens.video,
+ sent_seperator: str = ' ',
+ subset_type: str = 'classification',
+ convert_to_relative_paths: bool = False,
+ original_youku_ds_path: str = None,
+):
+ """
+ Convert a Data-Juicer-format dataset to a Youku-mPLUG-like dataset.
+
+ :param dj_ds_path: path to the input dataset in Data-Juicer format.
+ :param target_youku_ds_path: path to store the converted dataset in
+ Youku-mPLUG format.
+ :param eoc_special_token: the special token for "end of a chunk". It's used
+ to split sentence chunks explicitly. Default: <|__dj__eoc|> (from
+ Data-Juicer).
+ :param video_special_token: the special token for videos. It's used to
+ locate the videos in the text. In typical Youku-mPLUG-like datasets,
+ this special token is not specified. So we simply use the default video
+ special token from our Data-Juicer. Default: <__dj__video> (from
+ Data-Juicer).
+ :param sent_seperator: seperator to split different sentences. Default: " "
+ :param subset_type: the subset type of the input dataset. Should be one of
+ ["pretrain", "classification", "retrieval", "captioning"]. Default:
+ "classification".
+ :param convert_to_relative_paths: whether convert the video paths in this
+ dataset to relative paths to the original dataset. If it's True, an
+ extra argument original_youku_ds_path is required. When the processed
+ and converted dataset will be used in another machine, it's better to
+ set this argument to True. Default: False.
+ :param original_youku_ds_path: path to the original unprocessed Youku-mPLUG
+ dataset, which is used to help to recover the relative video paths for
+ better migration. Default: None.
+ """
+ # ----- Constant settings. Better not to change them. -----
+ text_key = 'text' # default key of field to store the sample text
+ video_key = 'videos' # default key of field to store the video list
+ fields_infos = {
+ 'pretrain': {
+ 'video_key': 'video_id:FILE',
+ 'text_key': 'title',
+ 'other_required_keys': [],
+ },
+ 'classification': {
+ 'video_key': 'video_id:FILE',
+ 'text_key': 'title',
+ 'other_required_keys': ['label'],
+ },
+ 'retrieval': {
+ 'video_key': 'clip_name:FILE',
+ 'text_key': 'caption',
+ 'other_required_keys': [],
+ },
+ 'captioning': {
+ 'video_key': 'video_id:FILE',
+ 'text_key': 'golden_caption',
+ 'other_required_keys': [],
+ }
+ }
+ # ----- Constant settings. Better not to change them. -----
+
+ # check arguments
+ # check paths
+ if not os.path.exists(dj_ds_path):
+ raise FileNotFoundError(
+ f'Input dataset [{dj_ds_path}] can not be found.')
+ if not target_youku_ds_path.endswith('.csv'):
+ raise ValueError(
+ 'Only support "csv" target dataset file for Youku-mPLUG now.')
+ if os.path.dirname(target_youku_ds_path) \
+ and not os.path.exists(os.path.dirname(target_youku_ds_path)):
+ logger.info(
+ f'Create directory [{os.path.dirname(target_youku_ds_path)}] for '
+ f'the target dataset.')
+ os.makedirs(os.path.dirname(target_youku_ds_path))
+ # check subset type
+ if subset_type not in fields_infos:
+ logger.error(f'Arg subset_type should be one of ["pretrain", '
+ f'"classification", "retrieval", "captioning"], but '
+ f'given [{subset_type}].')
+ tgt_video_key = fields_infos[subset_type]['video_key']
+ tgt_text_key = fields_infos[subset_type]['text_key']
+ tgt_required_keys = fields_infos[subset_type]['other_required_keys']
+
+ # if convert_to_relative_paths is True, check if the original_youku_ds_path
+ # is provided as well.
+ if convert_to_relative_paths:
+ if not original_youku_ds_path:
+ raise ValueError('When convert_to_relative_paths is set to True, '
+ 'the original_youku_ds_path must be provided '
+ 'for recovering the relative paths. Please '
+ 'check and retry.')
+ original_youku_ds_path = os.path.abspath(original_youku_ds_path)
+ # if provided original_youku_ds_path is the dataset file path, only
+ # keep the directory path.
+ if os.path.isfile(original_youku_ds_path):
+ original_youku_ds_path = os.path.dirname(original_youku_ds_path)
+
+ # save Youku-mPLUG dataset from Data-Juicer format
+ logger.info(
+ 'Start converting the original dataset to Youku-mPLUG format...')
+ with jl.open(dj_ds_path) as reader:
+ with open(target_youku_ds_path, 'w') as csvfile:
+ writer = csv.DictWriter(csvfile,
+ fieldnames=[tgt_video_key, tgt_text_key] +
+ tgt_required_keys)
+ # write headers first
+ writer.writeheader()
+ for line_num, s in enumerate(tqdm(reader)):
+ new_sample = {}
+ # add required fields
+ for key in tgt_required_keys:
+ if key not in s:
+ raise ValueError(f'Required key [{key}] is not in the '
+ f'original Data-Juicer dataset.')
+ new_sample[key] = s[key]
+
+ # add video, only keep the first one
+ video = s[video_key][0]
+ if convert_to_relative_paths:
+ if video.startswith(original_youku_ds_path):
+ video = os.path.relpath(video, original_youku_ds_path)
+ else:
+ raise ValueError(
+ f'The original_youku_ds_path '
+ f'[{original_youku_ds_path}] is not the '
+ f'directory that contains the video '
+ f'[{video}] in the sample of line number '
+ f'[{line_num}]. Please check if the correct '
+ f'original_youku_ds_path is provided or '
+ f'something wrong with this sample, and try '
+ f'again later.')
+ new_sample[tgt_video_key] = video
+
+ # add text, remove extra special tokens
+ text = s[text_key].strip()
+ text = remove_dj_special_tokens(text, eoc_special_token,
+ sent_seperator,
+ video_special_token)
+ new_sample[tgt_text_key] = text
+
+ writer.writerow(new_sample)
+ logger.info(f'Store the target dataset into [{target_youku_ds_path}].')
+
+
+if __name__ == '__main__':
+ fire.Fire(main)
diff --git a/tools/multimodal/source_format_to_data_juicer_format/internvid_to_dj.py b/tools/multimodal/source_format_to_data_juicer_format/internvid_to_dj.py
new file mode 100644
index 000000000..93b51ccb8
--- /dev/null
+++ b/tools/multimodal/source_format_to_data_juicer_format/internvid_to_dj.py
@@ -0,0 +1,159 @@
+# This tool is used to convert multimodal dataset in InternVid format to a
+# target dataset in Data-Juicer format.
+#
+# InternVid format:
+# - in jsonl
+# - caption-video pair with other fields (CLIP_Score, ...)
+# - videos are from Youtube, and start/end timestamps are given
+# - **Notice**: only YoutubeIDs are provided in the original dataset.
+# Here we suppose that users have downloaded these videos already,
+# and the YoutubeIDs are replaced with their video paths.
+# {'YoutubeID': 'videos/qJrOyggIB-w.mp4',
+# 'Start_timestamp': '00:07:33.689',
+# 'End_timestamp': '00:07:51.085',
+# 'Caption': 'a screen shot of heroes of the storm with people in action',
+# 'Aesthetic_Score': 4.29296875,
+# 'UMT_Score': 0.4501953125}
+#
+# Corresponding Data-Juicer format:
+# - two new fields are added:
+# - text: a chunk of text with the video special token.
+# - videos: video paths list, including cut videos according to their timestamps # noqa: E501
+# - other fields in the original format can be kept or not
+# - in jsonl
+# {'videos': ['videos/qJrOyggIB-w-cut.mp4'],
+# 'text': 'a screen shot of heroes of the storm with people in action',
+# 'Start_timestamp': '00:07:33.689',
+# 'End_timestamp': '00:07:51.085',
+# 'Aesthetic_Score': 4.29296875,
+# 'UMT_Score': 0.4501953125}
+#
+#
+# Reference:
+# https://huggingface.co/datasets/OpenGVLab/InternVid
+
+import os
+
+import fire
+import jsonlines as jl
+from loguru import logger
+from tqdm import tqdm
+
+from data_juicer.utils.file_utils import add_suffix_to_filename
+from data_juicer.utils.mm_utils import (SpecialTokens, cut_video_by_seconds,
+ timecode_string_to_seconds)
+from tools.multimodal.utils import (check_args_load_to_dj_data,
+ convert_text_to_dj)
+
+
+def main(
+ internvid_ds_path: str,
+ target_ds_path: str,
+ eoc_special_token: str = SpecialTokens.eoc,
+ video_special_token: str = SpecialTokens.video,
+ add_eoc_at_last: bool = True,
+ sent_seperator: str = ' ',
+ video_special_token_insert_pos: str = 'before',
+ cut_videos: bool = True,
+ cut_video_store_path: str = None,
+ keep_other_fields: bool = True,
+):
+ """
+ Convert an InternVid-like dataset to the Data-Juicer format.
+
+ :param internvid_ds_path: path to the input InternVid-like dataset.
+ :param target_ds_path: path to store the converted dataset in Data-Juicer
+ format.
+ :param eoc_special_token: the special token for "end of a chunk". It's used
+ to split sentence chunks explicitly. Default: <|__dj__eoc|> (from
+ Data-Juicer).
+ :param video_special_token: the special token for videos. It's used to
+ locate the videos in the text. In typical InternVide-like datasets,
+ this special token is not specified. So we simply use the default video
+ special token from our Data-Juicer. Default: <__dj__video> (from
+ Data-Juicer).
+ :param add_eoc_at_last: whether to add an extra eoc_special_token at the
+ end of text. Default: False.
+ :param sent_seperator: seperator to split different sentences or tokens.
+ Default: " "
+ :param video_special_token_insert_pos: the position in the sentence to
+ insert the corresponding video special token. Should be one of: [
+ "before", "after", "random"]. Default: "before".
+ :param cut_videos: whether to cut the videos into smaller ones according to
+ their start/end timestamps. Default: True. If you did this process
+ before converting, please set it to False.
+ :param cut_video_store_path: a path to store the cut videos. If cut_videos
+ is True and this path is None, store the cut videos into the same
+ directory as the original videos.
+ :param keep_other_fields: whether to keep other fields in the original
+ datasets. Default: False.
+ """
+ # ----- Constant settings. Better not to change them. -----
+ text_key = 'text' # default key of field to store the sample text
+ video_key = 'videos' # default key of field to store the video list
+ ori_text_key = 'Caption' # default original key of field to store texts
+ ori_video_key = 'YoutubeID' # default original field to store videos
+ # ----- Constant settings. Better not to change them. -----
+
+ input_ds_dir = os.path.dirname(internvid_ds_path)
+
+ # check arguments
+ check_args_load_to_dj_data(add_eoc_at_last, keep_other_fields,
+ target_ds_path, internvid_ds_path,
+ video_special_token_insert_pos, '.jsonl')
+ if cut_videos:
+ logger.warning('You set the cut_videos arg to True. This tool will '
+ 'take a video cut from the input video according to '
+ 'the start/end timestamps.')
+
+ # start conversion
+ logger.info('Start converting the original InternVid dataset...')
+ with jl.open(internvid_ds_path) as reader:
+ with jl.open(target_ds_path, mode='w') as writer:
+ for s in tqdm(reader):
+ video = s.pop(ori_video_key)
+ text = s.pop(ori_text_key)
+
+ # convert text to data-juicer format
+ # add video special token
+ new_sample, text = convert_text_to_dj(
+ text, s, add_eoc_at_last, eoc_special_token,
+ keep_other_fields, sent_seperator, video_special_token,
+ video_special_token_insert_pos)
+
+ # cut videos if needed
+ if cut_videos:
+ video = os.path.join(input_ds_dir, video)
+ cut_video_path = None
+ if cut_video_store_path is None:
+ # set it to the directory stores the original videos
+ cut_video_path = os.path.dirname(
+ os.path.abspath(video))
+ else:
+ cut_video_path = cut_video_store_path
+ # cut the video and store in a new path
+ video_basename = os.path.basename(video)
+ new_video = os.path.join(
+ cut_video_path,
+ add_suffix_to_filename(
+ video_basename,
+ f'_{s["Start_timestamp"]}_{s["End_timestamp"]}'))
+ start_pts = timecode_string_to_seconds(
+ s['Start_timestamp'])
+ end_pts = timecode_string_to_seconds(s['End_timestamp'])
+ cut_video_by_seconds(video, new_video, start_pts, end_pts)
+ video = new_video
+
+ new_sample[video_key] = [video]
+ new_sample[text_key] = text
+ if cut_videos:
+ # add a meta field to record whether this video is cut
+ new_sample['is_cut'] = True
+ else:
+ new_sample['is_cut'] = False
+ writer.write(new_sample)
+ logger.info(f'Store the target dataset into [{target_ds_path}].')
+
+
+if __name__ == '__main__':
+ fire.Fire(main)
diff --git a/tools/multimodal/source_format_to_data_juicer_format/video_chatgpt_to_dj.py b/tools/multimodal/source_format_to_data_juicer_format/video_chatgpt_to_dj.py
new file mode 100644
index 000000000..6aa1db738
--- /dev/null
+++ b/tools/multimodal/source_format_to_data_juicer_format/video_chatgpt_to_dj.py
@@ -0,0 +1,134 @@
+# This tool is used to convert multimodal dataset in Video_Chatgpt format to a
+# target dataset in Data-Juicer format.
+#
+# Video-ChatGPT format:
+# - Topics for Video summarization; Description-based question-answers
+# (exploring spatial, temporal, relationships, and reasoning concepts);
+# and Creative/generative question-answers
+# - in json file, a single line storing text-video pairs in a list,
+# below is an example
+#
+# [{'q': 'What are the main activities that take place in the video?',
+# 'a': 'The main activities that take place in the video are the preparation of
+# camera equipment by a man, a group of men riding a helicopter, and a man
+# sailing a boat through the water.',
+# 'video_id': 'v_k_ZXmr8pmrs'}, ...]
+#
+#
+# # Corresponding Data-Juicer format:
+# - two new fields to store the main data: 'youtube_id' and 'text',
+# the 'videos' is actual path to the video files
+# {'youtube_id': 'k_ZXmr8pmrs',
+# 'videos': ['youtube_video_dir/v_k_ZXmr8pmrs.mp4'],
+# 'text':
+# '<__dj__video>'
+# '[[q]]: What are the main activities that take place in the video? \n'
+# '[[a]]: The main activities that take place in the video are the
+# preparation of camera equipment by a man.... <|__dj__eoc|>'
+# }
+#
+
+import json
+import os
+
+import fire
+import jsonlines as jl
+from loguru import logger
+from tqdm import tqdm
+
+from data_juicer.utils.mm_utils import SpecialTokens
+from tools.multimodal.utils import (check_args_load_to_dj_data,
+ convert_text_to_dj)
+
+
+@logger.catch
+def main(
+ video_chatgpt_ds_path: str,
+ target_ds_dj_path: str,
+ eoc_special_token: str = SpecialTokens.eoc,
+ video_special_token: str = SpecialTokens.video,
+ add_eoc_at_last: bool = True,
+ sent_seperator: str = ' ',
+ video_special_token_insert_pos: str = 'before',
+ keep_other_fields: bool = True,
+):
+ """
+ Convert a Video_Chatgpt-like dataset to the Data-Juicer format.
+
+ :param video_chatgpt_ds_path: path to the input Video_Chatgpt-like dataset.
+ :param target_ds_dj_path: path to store the converted dataset in
+ Data-Juicer format.
+ :param eoc_special_token: the special token for "end of a chunk". It's used
+ to split sentence chunks explicitly. Default: <|__dj__eoc|> (from
+ Data-Juicer).
+ :param video_special_token: the special token for videos. It's used to
+ locate the videos in the text. In typical Video_Chatgpt-like datasets,
+ this special token is not specified. So we simply use the default video
+ special token from our Data-Juicer. Default: <__dj__video> (from
+ Data-Juicer).
+ :param add_eoc_at_last: whether to add an extra eoc_special_token at the
+ end of text. Default: False.
+ :param sent_seperator: seperator to split different sentences or tokens.
+ Default: " "
+ :param video_special_token_insert_pos: the position in the sentence to
+ insert the corresponding video special token. Should be one of: [
+ "before", "after", "random"]. Default: "before".
+ :param keep_other_fields: whether to keep other fields in the original
+ datasets. Default: False.
+ """
+ # ----- Constant settings. Better not to change them. -----
+ text_key = 'text' # default key of field to store the sample text
+ video_key = 'videos' # default key of field to store the video list
+ video_id_key = 'youtube_id' # default original field to store video id
+ ori_text_key_q = 'q' # default original key of field to store texts
+ ori_text_key_a = 'a' # default original key of field to store texts
+ ori_video_key = 'video_id' # default original field to store video ids
+
+ def format_dj_text(text_q, text_a):
+ """
+ This function returns a formatted string.
+
+ :param text_q: Text for the question
+ :param text_a: Text for the answer
+ :return: Formatted string
+ """
+ return f'[[{ori_text_key_q}]]:{text_q} \n[[{ori_text_key_a}]]:{text_a}'
+
+ # ----- Constant settings. Better not to change them. -----
+
+ input_ds_dir = os.path.dirname(video_chatgpt_ds_path)
+
+ # check arguments
+ check_args_load_to_dj_data(add_eoc_at_last, keep_other_fields,
+ target_ds_dj_path, video_chatgpt_ds_path,
+ video_special_token_insert_pos, '.jsonl')
+
+ # start conversion
+ logger.info(f'Start converting the original Video_Chatgpt dataset '
+ f'from {video_chatgpt_ds_path}...')
+ with open(video_chatgpt_ds_path, 'r') as json_file:
+ ori_data = json.load(json_file)
+ with jl.open(target_ds_dj_path, mode='w') as writer:
+ for s in tqdm(ori_data):
+ # v_k_ZXmr8pmrs --> k_ZXmr8pmrs
+ video_id = s.pop(ori_video_key)[2:]
+ text_q = s.pop(ori_text_key_q)
+ text_a = s.pop(ori_text_key_a)
+
+ text = format_dj_text(text_q, text_a)
+
+ new_sample, text = convert_text_to_dj(
+ text, s, add_eoc_at_last, eoc_special_token, keep_other_fields,
+ sent_seperator, video_special_token,
+ video_special_token_insert_pos)
+
+ new_sample[video_key] = [os.path.join(input_ds_dir, video_id)]
+ new_sample[text_key] = text
+ new_sample[video_id_key] = video_id
+
+ writer.write(new_sample)
+ logger.info(f'Store the target dataset into [{target_ds_dj_path}].')
+
+
+if __name__ == '__main__':
+ fire.Fire(main)
diff --git a/tools/multimodal/source_format_to_data_juicer_format/youku_to_dj.py b/tools/multimodal/source_format_to_data_juicer_format/youku_to_dj.py
new file mode 100644
index 000000000..f347dd090
--- /dev/null
+++ b/tools/multimodal/source_format_to_data_juicer_format/youku_to_dj.py
@@ -0,0 +1,162 @@
+# This tool is used to convert multimodal dataset in Youku-mPLUG format to a
+# target dataset in Data-Juicer format.
+#
+# Youku-mPLUG format:
+# - 4 types: pretrain, classification, retrieval, captioning
+# - in csv
+# - text-video pair with other fields (label, ...)
+#
+# Youku-mPLUG-pretrain format:
+# {'video_id:FILE': 'videos/pretrain/14111Y1211b-1134b18bAE55bFE7Jbb7135YE3aY54EaB14ba7CbAa1AbACB24527A.flv', # noqa: E501
+# 'title': '妈妈给宝宝听胎心,看看宝宝是怎么做的,太调皮了'}
+#
+# Youku-mPLUG-classification format:
+# {'video_id:FILE': 'videos/classification/14111B1211bFBCBCJYF48B55b7523C51F3-8b3a5YbCa5817aBb38a5YAC-241F71J.mp4', # noqa: E501
+# 'title': '兔宝宝刚出生,为什么兔妈妈要把它们吃掉?看完涨见识了',
+# 'label': '宠物'}
+#
+# Youku-mPLUG-retrieval format:
+# {'clip_name:FILE': 'videos/retrieval/14111B1211bA1F31-E-2YB57--C518FCEBC553abJYFa5541a31C8a57522AYJbYF4aTdfofa112.mp4', # noqa: E501
+# 'caption': '身穿黑色上衣戴着头盔的女子在路上骑着摩托车四周还停放了一些车'}
+#
+# Youku-mPLUG-captioning format:
+# {'video_id:FILE': 'videos/caption/14111B1211bEJB-1b3b-J3b7b8Y213BJ32-521a1EA8a53-3aBA72aA-4-2-CF1EJ8aTdfofa114.mp4', # noqa: E501
+# 'golden_caption': '穿白色球服的女生高高跳起,接住了球。']}
+#
+# Corresponding Data-Juicer format:
+# - two new fields are added:
+# - text: a chunk of text with the video special token.
+# - videos: video paths list
+# - other fields in the original format can be kept or not
+# - in jsonl
+#
+# Youku-mPLUG-pretrain Data-Juicer format:
+# {'videos': ['videos/pretrain/14111Y1211b-1134b18bAE55bFE7Jbb7135YE3aY54EaB14ba7CbAa1AbACB24527A.flv'], # noqa: E501
+# 'text': '<__dj__video> 妈妈给宝宝听胎心,看看宝宝是怎么做的,太调皮了 <|__dj__eoc|>'}
+#
+# Youku-mPLUG-classification Data-Juicer format:
+# {'videos': ['videos/classification/14111B1211bFBCBCJYF48B55b7523C51F3-8b3a5YbCa5817aBb38a5YAC-241F71J.mp4'], # noqa: E501
+# 'text': '<__dj__video> 兔宝宝刚出生,为什么兔妈妈要把它们吃掉?看完涨见识了 <|__dj__eoc|>',
+# 'label': '宠物'}
+#
+# Youku-mPLUG-retrieval Data-Juicer format:
+# {'videos': ['videos/retrieval/14111B1211bA1F31-E-2YB57--C518FCEBC553abJYFa5541a31C8a57522AYJbYF4aTdfofa112.mp4'], # noqa: E501
+# 'text': '<__dj__video> 身穿黑色上衣戴着头盔的女子在路上骑着摩托车四周还停放了一些车 <|__dj__eoc|>'}
+#
+# Youku-mPLUG-captioning Data-Juicer format:
+# {'videos': ['videos/caption/14111B1211bEJB-1b3b-J3b7b8Y213BJ32-521a1EA8a53-3aBA72aA-4-2-CF1EJ8aTdfofa114.mp4'], # noqa: E501
+# 'text': '<__dj__video> 穿白色球服的女生高高跳起,接住了球。 <|__dj__eoc|> <__dj__video> 一排穿红色短袖的女生正在接受颁奖。 <|__dj__eoc|>']} # noqa: E501
+#
+# Reference:
+# https://modelscope.cn/datasets/modelscope/Youku-AliceMind/summary
+
+import csv
+
+import fire
+import jsonlines as jl
+from loguru import logger
+from tqdm import tqdm
+
+from data_juicer.utils.mm_utils import SpecialTokens
+from tools.multimodal.utils import (check_args_load_to_dj_data,
+ convert_text_to_dj)
+
+
+@logger.catch
+def main(
+ youku_ds_path: str,
+ target_ds_path: str,
+ eoc_special_token: str = SpecialTokens.eoc,
+ video_special_token: str = SpecialTokens.video,
+ add_eoc_at_last: bool = True,
+ sent_seperator: str = ' ',
+ video_special_token_insert_pos: str = 'before',
+ subset_type: str = 'classification',
+ keep_other_fields: bool = True,
+):
+ """
+ Convert a Youku-mPLUG-like dataset to the Data-Juicer format.
+
+ :param youku_ds_path: path to the input Youku-mPLUG-like dataset.
+ :param target_ds_path: path to store the converted dataset in Data-Juicer
+ format.
+ :param eoc_special_token: the special token for "end of a chunk". It's used
+ to split sentence chunks explicitly. Default: <|__dj__eoc|> (from
+ Data-Juicer).
+ :param video_special_token: the special token for videos. It's used to
+ locate the videos in the text. In typical Youku-mPLUG-like datasets,
+ this special token is not specified. So we simply use the default video
+ special token from our Data-Juicer. Default: <__dj__video> (from
+ Data-Juicer).
+ :param add_eoc_at_last: whether to add an extra eoc_special_token at the
+ end of text. Default: False.
+ :param sent_seperator: seperator to split different sentences or tokens.
+ Default: " "
+ :param video_special_token_insert_pos: the position in the sentence to
+ insert the corresponding video special token. Should be one of: [
+ "before", "after", "random"]. Default: "before".
+ :param subset_type: the subset type of the input dataset. Should be one of
+ ["pretrain", "classification", "retrieval", "captioning"]. Default:
+ "classification".
+ :param keep_other_fields: whether to keep other fields in the original
+ datasets. Default: False.
+ """
+ # ----- Constant settings. Better not to change them. -----
+ text_key = 'text' # default key of field to store the sample text
+ video_key = 'videos' # default key of field to store the video list
+ fields_infos = {
+ 'pretrain': {
+ 'video_key': 'video_id:FILE',
+ 'text_key': 'title',
+ },
+ 'classification': {
+ 'video_key': 'video_id:FILE',
+ 'text_key': 'title',
+ },
+ 'retrieval': {
+ 'video_key': 'clip_name:FILE',
+ 'text_key': 'caption',
+ },
+ 'captioning': {
+ 'video_key': 'video_id:FILE',
+ 'text_key': 'golden_caption',
+ }
+ }
+ # ----- Constant settings. Better not to change them. -----
+
+ # check arguments
+ check_args_load_to_dj_data(add_eoc_at_last, keep_other_fields,
+ target_ds_path, youku_ds_path,
+ video_special_token_insert_pos, '.jsonl')
+ # check subset type
+ if subset_type not in fields_infos:
+ logger.error(f'Arg subset_type should be one of ["pretrain", '
+ f'"classification", "retrieval", "captioning"], but '
+ f'given [{subset_type}].')
+ ori_video_key = fields_infos[subset_type]['video_key']
+ ori_text_key = fields_infos[subset_type]['text_key']
+
+ # load Youku-mPLUG dataset
+ logger.info('Start converting the original Youku-mPLUG dataset...')
+ with open(youku_ds_path) as csvfile:
+ reader = csv.DictReader(csvfile)
+ with jl.open(target_ds_path, mode='w') as writer:
+ for row in tqdm(reader):
+ video = row[ori_video_key]
+ text = row[ori_text_key]
+
+ # convert text to data-juicer format
+ # add video special token
+ new_sample, text = convert_text_to_dj(
+ text, row, add_eoc_at_last, eoc_special_token,
+ keep_other_fields, sent_seperator, video_special_token,
+ video_special_token_insert_pos)
+ # all sentences correspond to the same video
+ new_sample[video_key] = [video]
+ new_sample[text_key] = text
+ writer.write(new_sample)
+ logger.info(f'Store the target dataset into [{target_ds_path}].')
+
+
+if __name__ == '__main__':
+ fire.Fire(main)
diff --git a/tools/multimodal/utils.py b/tools/multimodal/utils.py
new file mode 100644
index 000000000..595c52702
--- /dev/null
+++ b/tools/multimodal/utils.py
@@ -0,0 +1,82 @@
+import os
+import random
+from copy import deepcopy
+
+from loguru import logger
+
+
+def remove_dj_special_tokens(text, eoc_special_token, sent_seperator,
+ video_special_token):
+ # remove possible sentence seperator
+ if text.startswith(sent_seperator):
+ text = text[len(sent_seperator):].strip()
+ if text.endswith(sent_seperator):
+ text = text[:-len(sent_seperator)].strip()
+ # remove eoc token
+ if text.endswith(eoc_special_token):
+ text = text[:-len(eoc_special_token)].strip()
+ # remove possible video special token
+ if text.startswith(video_special_token):
+ text = text[len(video_special_token):].strip()
+ if text.startswith(sent_seperator):
+ text = text[len(sent_seperator):].strip()
+ elif text.endswith(video_special_token):
+ text = text[:-len(video_special_token)].strip()
+ if text.endswith(sent_seperator):
+ text = text[:-len(sent_seperator)].strip()
+ return text
+
+
+def check_args_load_to_dj_data(add_eoc_at_last, keep_other_fields,
+ target_ds_dj_path, video_ds_path,
+ video_special_token_insert_pos,
+ target_ds_path_suffix):
+ if not os.path.exists(video_ds_path):
+ raise FileNotFoundError(f'Input dataset '
+ f'[{video_ds_path}] can not be found.')
+ if not target_ds_dj_path.endswith(target_ds_path_suffix):
+ raise ValueError(
+ f'Only support "{target_ds_path_suffix}" target dataset file now.')
+ if os.path.dirname(target_ds_dj_path) \
+ and not os.path.exists(os.path.dirname(target_ds_dj_path)):
+ logger.info(f'Create directory [{os.path.dirname(target_ds_dj_path)}] '
+ f'for the target dataset.')
+ os.makedirs(os.path.dirname(target_ds_dj_path))
+ # check insert position
+ if video_special_token_insert_pos not in ['random', 'before', 'after']:
+ raise ValueError(f'Arg video_special_token_insert_pos should be one '
+ f'of ["before", "after", "random"], but given '
+ f'[{video_special_token_insert_pos}]')
+ # check whether to add the eoc special token at last
+ if not add_eoc_at_last:
+ logger.warning('You choose not to add special eoc token at the last, '
+ 'which might cause some compatibility problems for '
+ 'other type of datasets (e.g. OpenFlamingo).')
+ if not keep_other_fields:
+ logger.warning('You choose not to keep other fields in the original '
+ 'dataset. Thus some information might be lost in the '
+ 'processed anc converted-back dataset!')
+
+
+def convert_text_to_dj(text, original_sample, add_eoc_at_last,
+ eoc_special_token, keep_other_fields, sent_seperator,
+ video_special_token, video_special_token_insert_pos):
+ if video_special_token_insert_pos == 'before':
+ text = video_special_token + sent_seperator + text
+ elif video_special_token_insert_pos == 'after':
+ text += sent_seperator + video_special_token
+ else:
+ if random.random() < 0.5:
+ # before
+ text = video_special_token + sent_seperator \
+ + text
+ else:
+ # after
+ text += sent_seperator + video_special_token
+ if add_eoc_at_last:
+ text += f'{sent_seperator}{eoc_special_token}'
+ if keep_other_fields:
+ new_sample = deepcopy(original_sample)
+ else:
+ new_sample = {}
+ return new_sample, text
+
+"""
+op_text = ''
+docs_file = os.path.join(project_path, 'docs/Operators.md')
+if os.path.exists(docs_file):
+ with open(os.path.join(project_path, 'docs/Operators.md'), 'r') as f:
+ op_text = f.read()
+
+def extract_op_desc(markdown_text, header):
+ start_index = markdown_text.find(header)
+ end_index = markdown_text.find("\n##", start_index + len(header))
+ return markdown_text[start_index+ len(header):end_index].strip()
+
+op_desc = f"{config.get("name", "")}
+ {config.get("description", "")}
+ {config.get("introduction", "")}
+ {config.get("demo", "")}
+{extract_op_desc(op_text, '## Overview').split('All the specific ')[0].strip()}
"
+op_list_desc = {
+ 'mapper':extract_op_desc(op_text, '## Mapper '),
+ 'filter':extract_op_desc(op_text, '## Filter '),
+ 'deduplicator':extract_op_desc(op_text, '## Deduplicator '),
+ 'selector':extract_op_desc(op_text, '## Selector '),
+}
+
+op_types = ['mapper', 'filter',]# 'deduplicator'] , 'selector']
+local_ops_dict = {op_type:[] for op_type in op_types}
+multimodal = os.getenv('MULTI_MODAL', False)
+multimodal = True
+text_key = 'text'
+image_key = 'images'
+audio_key = 'audios'
+video_key = 'videos'
+def get_op_lists(op_type):
+ use_local_op = os.getenv('USE_LOCAL_OP', False)
+ if not use_local_op:
+ all_ops = list(OPERATORS.modules.keys())
+ options = [
+ name for name in all_ops if name.endswith(op_type)
+ ]
+ else:
+ options = local_ops_dict.get(op_type, [])
+
+ for exclude in ['image', 'video', 'audio']:
+ options = [name for name in options if multimodal or exclude not in name]
+ return options
+
+def show_code(op_name):
+ op_class = OPERATORS.modules[op_name]
+ text = inspect.getsourcelines(op_class)
+ return ''.join(text[0])
+
+def decode_sample(output_sample):
+ output_text = output_sample[text_key]
+ output_image = output_sample[image_key][0] if output_sample[image_key] else None
+ output_video = output_sample[video_key][0] if output_sample[video_key] else None
+ output_audio = output_sample[audio_key][0] if output_sample[audio_key] else None
+ def copy_func(file):
+ filename = None
+ if file:
+ filename= os.path.basename(file)
+ shutil.copyfile(file, filename)
+ return filename
+
+ image_file = copy_func(output_image)
+ video_file = copy_func(output_video)
+ audio_file = copy_func(output_audio)
+ return output_text, image_file, video_file, audio_file
+
+def create_mapper_tab(op_type, op_tab):
+ with op_tab:
+ options = get_op_lists(op_type)
+ label = f'Select a {op_type} to show details'
+ with gr.Row():
+ op_selector = gr.Dropdown(value=options[0], label=label, choices=options, interactive=True)
+ run_button = gr.Button(value="🚀Run")
+ show_code_button = gr.Button(value="🔍Show Code")
+ gr.Markdown(" **Op Parameters**")
+ op_params = gr.Code(label="Yaml",language='yaml', interactive=True)
+ with gr.Column():
+ with gr.Group('Inputs'):
+ gr.Markdown(" **Inputs**")
+ with gr.Row():
+ # img = '/private/var/folders/7b/p5l9gykj1k7_tylkvwjv_sl00000gp/T/gradio/f24972121fd4d4f95f42f1cd70f859bb03839e76/image_blur_mapper/喜欢的书__dj_hash_#14a7b2e1b96410fbe63ea16a70422180db53d644661630938b2773d8efa18dde#.png'
+
+ input_text = gr.TextArea(label="Text",interactive=True,)
+ input_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ input_video = gr.Video(label='Video', visible=multimodal)
+ input_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+ with gr.Group('Outputs'):
+ gr.Markdown(" **Outputs**")
+ with gr.Row():
+ output_text = gr.TextArea(label="Text",interactive=False,)
+ output_image = gr.Image(label='Image', visible=multimodal)
+ output_video = gr.Video(label='Video', visible=multimodal)
+ output_audio = gr.Audio(label='Audio', visible=multimodal)
+ code = gr.Code(label='Source', language='python')
+ def run_op(op_name, op_params, input_text, input_image, input_video, input_audio):
+ op_class = OPERATORS.modules[op_name]
+ try:
+ params = yaml.safe_load(op_params)
+ except:
+ params = {}
+ if params is None:
+ params = {}
+ op = op_class(**params)
+ sample = dict()
+
+ sample[text_key] = input_text
+ sample[image_key] = [input_image]
+ sample[video_key] = [input_video]
+ sample[audio_key] = [input_audio]
+
+ output_sample = op.process(copy.deepcopy(sample))
+
+ return decode_sample(output_sample)
+
+ inputs = [op_selector, op_params, input_text, input_image, input_video, input_audio]
+ outputs = [output_text, output_image, output_video, output_audio]
+ run_button.click(run_op, inputs=inputs, outputs=outputs)
+ show_code_button.click(show_code, inputs=[op_selector], outputs=[code])
+
+def create_filter_tab(op_type, op_tab):
+ with op_tab:
+
+ options = get_op_lists(op_type)
+ label = f'Select a {op_type} to show details'
+ with gr.Row():
+ op_selector = gr.Dropdown(value=options[0], label=label, choices=options, interactive=True)
+ run_button = gr.Button(value="🚀Run")
+ show_code_button = gr.Button(value="🔍Show Code")
+ gr.Markdown(" **Op Parameters**")
+ op_params = gr.Code(label="Yaml",language='yaml', interactive=True)
+ with gr.Column():
+ with gr.Group('Inputs'):
+ gr.Markdown(" **Inputs**")
+ with gr.Row():
+ input_text = gr.TextArea(label="Text",interactive=True,)
+ input_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ input_video = gr.Video(label='Video', visible=multimodal)
+ input_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+ input_stats = gr.Json(label='Stats')
+
+ with gr.Group('Outputs'):
+ gr.Markdown(" **Outputs**")
+ with gr.Row():
+ output_text = gr.TextArea(label="Text",interactive=False,)
+ output_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ output_video = gr.Video(label='Video', visible=multimodal)
+ output_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+ output_stats = gr.Json(label='Stats')
+
+ code = gr.Code(label='Source', language='python')
+ def run_op(op_name, op_params, input_text, input_image, input_video, input_audio):
+ op_class = OPERATORS.modules[op_name]
+ try:
+ params = yaml.safe_load(op_params)
+ except:
+ params = {}
+ if params is None:
+ params = {}
+ op = op_class(**params)
+ sample = dict()
+ sample[Fields.stats] = dict()
+ sample[text_key] = input_text
+ sample[image_key] = [input_image]
+ sample[video_key] = [input_video]
+ sample[audio_key] = [input_audio]
+ input_stats = sample[Fields.stats]
+ output_sample = op.compute_stats(copy.deepcopy(sample))
+ output_stats = output_sample[Fields.stats]
+ return *decode_sample(output_sample), input_stats, output_stats
+
+ inputs = [op_selector, op_params, input_text, input_image, input_video, input_audio]
+ outputs = [output_text, output_image, output_video, output_audio, input_stats, output_stats]
+ run_button.click(run_op, inputs=inputs, outputs=outputs)
+ show_code_button.click(show_code, inputs=[op_selector], outputs=[code])
+
+def create_deduplicator_tab(op_type, op_tab):
+ with op_tab:
+ options = get_op_lists(op_type)
+ label = f'Select a {op_type} to show details'
+ with gr.Row():
+ op_selector = gr.Dropdown(value=options[0], label=label, choices=options, interactive=True)
+ run_button = gr.Button(value="🚀Run")
+ show_code_button = gr.Button(value="🔍Show Code")
+ gr.Markdown(" **Op Parameters**")
+ op_params = gr.Code(label="Yaml",language='yaml', interactive=True)
+ with gr.Column():
+ with gr.Group('Inputs'):
+ gr.Markdown(" **Inputs**")
+ with gr.Row():
+ input_text = gr.TextArea(label="Text",interactive=True,)
+ input_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ input_video = gr.Video(label='Video', visible=multimodal)
+ input_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+
+ with gr.Group('Outputs'):
+ gr.Markdown(" **Outputs**")
+ with gr.Row():
+ output_text = gr.TextArea(label="Text",interactive=False,)
+ output_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ output_video = gr.Video(label='Video', visible=multimodal)
+ output_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+
+ code = gr.Code(label='Source', language='python')
+ def run_op(op_name, op_params, input_text, input_images, input_video, input_audio):
+ op_class = OPERATORS.modules[op_name]
+ try:
+ params = yaml.safe_load(op_params)
+ except:
+ params = {}
+ if params is None:
+ params = {}
+ op = op_class(**params)
+ sample = dict()
+ sample[text_key] = input_text
+ sample[image_key] = input_images
+ sample[video_key] = [input_video]
+ sample[audio_key] = [input_audio]
+
+ output_sample = sample #op.compute_hash(copy.deepcopy(sample))
+ return decode_sample(output_sample)
+
+ inputs = [op_selector, op_params, input_text, input_image, input_video, input_audio]
+ outputs = [output_text, output_image, output_video, output_audio]
+ run_button.click(run_op, inputs=inputs, outputs=outputs)
+ show_code_button.click(show_code, inputs=[op_selector], outputs=[code])
+
+def create_selector_tab(op_type, op_tab):
+ with op_tab:
+ options = get_op_lists(op_type)
+ label = f'Select a {op_type} to show details'
+ with gr.Row():
+ op_selector = gr.Dropdown(value=options[0], label=label, choices=options, interactive=True)
+ run_button = gr.Button(value="🚀Run")
+ show_code_button = gr.Button(value="🔍Show Code")
+ gr.Markdown(" **Op Parameters**")
+ op_params = gr.Code(label="Yaml",language='yaml', interactive=True)
+ with gr.Column():
+ with gr.Group('Inputs'):
+ gr.Markdown(" **Inputs**")
+ with gr.Row():
+ input_text = gr.TextArea(label="Text",interactive=True,)
+ input_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ input_video = gr.Video(label='Video', visible=multimodal)
+ input_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+ input_stats = gr.Json(label='Stats')
+
+ with gr.Group('Outputs'):
+ gr.Markdown(" **Outputs**")
+ with gr.Row():
+ output_text = gr.TextArea(label="Text",interactive=False,)
+ output_image = gr.Image(label='Image', type='filepath', visible=multimodal)
+ output_video = gr.Video(label='Video', visible=multimodal)
+ output_audio = gr.Audio(label='Audio', type='filepath', visible=multimodal)
+ output_stats = gr.Json(label='Stats')
+
+ code = gr.Code(label='Source', language='python')
+ def run_op(op_name, op_params, input_text, input_image, input_video, input_audio):
+ op_class = OPERATORS.modules[op_name]
+ try:
+ params = yaml.safe_load(op_params)
+ except:
+ params = {}
+ if params is None:
+ params = {}
+ op = op_class(**params)
+ sample = dict()
+ sample[Fields.stats] = dict()
+ sample[text_key] = input_text
+ sample[image_key] = [input_image]
+ sample[video_key] = [input_video]
+ sample[audio_key] = [input_audio]
+ input_stats = sample[Fields.stats]
+ output_sample = op.compute_stats(copy.deepcopy(sample))
+ output_stats = output_sample[Fields.stats]
+
+ return *decode_sample(output_sample), input_stats, output_stats
+
+ inputs = [op_selector, op_params, input_text, input_image, input_video, input_audio]
+ outputs = [output_text, output_image, output_video, output_audio, input_stats, output_stats]
+ run_button.click(run_op, inputs=inputs, outputs=outputs)
+ show_code_button.click(show_code, inputs=[op_selector], outputs=[code])
+
+with gr.Blocks(css="./app.css") as demo:
+
+ dj_image = os.path.join(project_path, 'docs/imgs/data-juicer.jpg')
+ gr.HTML(format_cover_html(dj_image))
+
+ with gr.Accordion(label='Op Insight',open=True):
+ tabs = gr.Tabs()
+
+ with tabs:
+ op_tabs = {op_type: gr.Tab(label=op_type.capitalize() + 's') for op_type in op_types}
+ for op_type, op_tab in op_tabs.items():
+ create_op_tab_func = globals().get(f'create_{op_type}_tab', None)
+ if callable(create_op_tab_func):
+ create_op_tab_func(op_type, op_tab)
+ else:
+ gr.Error(f'{op_type} not callable')
+
+ demo.launch()
diff --git a/demos/process_on_ray/configs/demo.yaml b/demos/process_on_ray/configs/demo.yaml
index 0fefc8d39..1e3e4a55a 100644
--- a/demos/process_on_ray/configs/demo.yaml
+++ b/demos/process_on_ray/configs/demo.yaml
@@ -3,7 +3,7 @@
# global parameters
project_name: 'ray-demo'
executor_type: 'ray'
-dataset_path: './demos/process_on_ray/data/demo-dataset.json' # path to your dataset directory or file
+dataset_path: './demos/process_on_ray/data/demo-dataset.jsonl' # path to your dataset directory or file
ray_address: 'auto' # change to your ray cluster address, e.g., ray://substrings_mapper | General | en, zh | Removes words containing specified substrings | -| replace_content_mapper | General | en, zh | Replace all content in the text that matches a specific regular expression pattern with a designated replacement string. | -| sentence_split_mapper | General | en | Splits and reorganizes sentences according to semantics | -| whitespace_normalization_mapper | General | en, zh | Normalizes various Unicode whitespaces to the normal ASCII space (U+0020) | +| remove_words_with_incorrect_
substrings_mapper | General | en, zh | Removes words containing specified substrings | +| replace_content_mapper | General | en, zh | Replace all content in the text that matches a specific regular expression pattern with a designated replacement string | +| sentence_split_mapper | General | en | Splits and reorganizes sentences according to semantics | +| video_captioning_from_audio_mapper | Multimodal | - | Caption a video according to its audio streams based on Qwen-Audio model | +| video_captioning_from_video_mapper | Multimodal | - | generate samples whose captions are generated based on another model (video-blip) and sampled video frame within the original sample | +| video_ffmpeg_wrapped_mapper | Video | - | Simple wrapper to run a FFmpeg video filter | +| video_resize_aspect_ratio_mapper | Video | - | Resize video aspect ratio to a specified range | +| video_resize_resolution_mapper | Video | - | Map videos to ones with given resolution range | +| video_split_by_duration_mapper | Multimodal | - | Mapper to split video by duration. | +| video_spit_by_key_frame_mapper | Multimodal | - | Mapper to split video by key frame. | +| video_split_by_scene_mapper | Multimodal | - | Split videos into scene clips | +| video_tagging_from_audio_mapper | Multimodal | - | Mapper to generate video tags from audio streams extracted from the video. | +| video_tagging_from_frames_mapper | Multimodal | - | Mapper to generate video tags from frames extracted from the video. | +| whitespace_normalization_mapper | General | en, zh | Normalizes various Unicode whitespaces to the normal ASCII space (U+0020) | ## Filter -| Operator | Domain | Lang | Description | -|--------------------------------|------------|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------| -| alphanumeric_filter | General | en, zh | Keeps samples with alphanumeric ratio within the specified range | -| audio_duration_filter | Audio | - | Keep data samples whose audios' durations are within a specified range | +| Operator | Domain | Lang | Description | +|--------------------------------|------------|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------| +| alphanumeric_filter | General | en, zh | Keeps samples with alphanumeric ratio within the specified range | +| audio_duration_filter | Audio | - | Keep data samples whose audios' durations are within a specified range | | audio_nmf_snr_filter | Audio | - | Keep data samples whose audios' Signal-to-Noise Ratios (SNRs, computed based on Non-Negative Matrix Factorization, NMF) are within a specified range. | -| audio_size_filter | Audio | - | Keep data samples whose audios' sizes are within a specified range | -| average_line_length_filter | Code | en, zh | Keeps samples with average line length within the specified range | -| character_repetition_filter | General | en, zh | Keeps samples with char-level n-gram repetition ratio within the specified range | -| face_area_filter | Image | - | Keeps samples containing images with face area ratios within the specified range | -| flagged_words_filter | General | en, zh | Keeps samples with flagged-word ratio below the specified threshold | -| image_aspect_ratio_filter | Image | - | Keeps samples containing images with aspect ratios within the specified range | -| image_shape_filter | Image | - | Keeps samples containing images with widths and heights within the specified range | -| image_size_filter | Image | - | Keeps samples containing images whose size in bytes are within the specified range | -| image_text_matching_filter | Multimodal | - | Keeps samples with image-text classification matching score within the specified range based on a BLIP model | -| image_text_similarity_filter | Multimodal | - | Keeps samples with image-text feature cosine similarity within the specified range based on a CLIP model | -| language_id_score_filter | General | en, zh | Keeps samples of the specified language, judged by a predicted confidence score | -| maximum_line_length_filter | Code | en, zh | Keeps samples with maximum line length within the specified range | -| perplexity_filter | General | en, zh | Keeps samples with perplexity score below the specified threshold | -| phrase_grounding_recall_filter | Multimodal | - | Keeps samples whose locating recalls of phrases extracted from text in the images are within a specified range | -| special_characters_filter | General | en, zh | Keeps samples with special-char ratio within the specified range | -| specified_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified targets | -| specified_numeric_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified range (for numeric types) | -| stopwords_filter | General | en, zh | Keeps samples with stopword ratio above the specified threshold | -| suffix_filter | General | en, zh | Keeps samples with specified suffixes | -| text_action_filter | General | en, zh | Keeps samples containing action verbs in their texts | -| text_entity_dependency_filter | General | en, zh | Keeps samples containing entity nouns related to other tokens in the dependency tree of the texts | -| text_length_filter | General | en, zh | Keeps samples with total text length within the specified range | -| token_num_filter | General | en, zh | Keeps samples with token count within the specified range | -| word_num_filter | General | en, zh | Keeps samples with word count within the specified range | -| word_repetition_filter | General | en, zh | Keeps samples with word-level n-gram repetition ratio within the specified range | +| audio_size_filter | Audio | - | Keep data samples whose audios' sizes are within a specified range | +| average_line_length_filter | Code | en, zh | Keeps samples with average line length within the specified range | +| character_repetition_filter | General | en, zh | Keeps samples with char-level n-gram repetition ratio within the specified range | +| face_area_filter | Image | - | Keeps samples containing images with face area ratios within the specified range | +| flagged_words_filter | General | en, zh | Keeps samples with flagged-word ratio below the specified threshold | +| image_aspect_ratio_filter | Image | - | Keeps samples containing images with aspect ratios within the specified range | +| image_shape_filter | Image | - | Keeps samples containing images with widths and heights within the specified range | +| image_size_filter | Image | - | Keeps samples containing images whose size in bytes are within the specified range | +| image_aesthetics_filter | Image | - | Keeps samples containing images whose aesthetics scores are within the specified range | +| image_text_matching_filter | Multimodal | - | Keeps samples with image-text classification matching score within the specified range based on a BLIP model | +| image_text_similarity_filter | Multimodal | - | Keeps samples with image-text feature cosine similarity within the specified range based on a CLIP model | +| language_id_score_filter | General | en, zh | Keeps samples of the specified language, judged by a predicted confidence score | +| maximum_line_length_filter | Code | en, zh | Keeps samples with maximum line length within the specified range | +| perplexity_filter | General | en, zh | Keeps samples with perplexity score below the specified threshold | +| phrase_grounding_recall_filter | Multimodal | - | Keeps samples whose locating recalls of phrases extracted from text in the images are within a specified range | +| special_characters_filter | General | en, zh | Keeps samples with special-char ratio within the specified range | +| specified_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified targets | +| specified_numeric_field_filter | General | en, zh | Filters samples based on field, with value lies in the specified range (for numeric types) | +| stopwords_filter | General | en, zh | Keeps samples with stopword ratio above the specified threshold | +| suffix_filter | General | en, zh | Keeps samples with specified suffixes | +| text_action_filter | General | en, zh | Keeps samples containing action verbs in their texts | +| text_entity_dependency_filter | General | en, zh | Keeps samples containing entity nouns related to other tokens in the dependency tree of the texts | +| text_length_filter | General | en, zh | Keeps samples with total text length within the specified range | +| token_num_filter | General | en, zh | Keeps samples with token count within the specified range | +| video_aspect_ratio_filter | Video | - | Keeps samples containing videos with aspect ratios within the specified range | +| video_duration_filter | Video | - | Keep data samples whose videos' durations are within a specified range | +| video_aesthetics_filter | Video | - | Keeps samples whose specified frames have aesthetics scores within the specified range | +| video_frames_text_similarity_filter | Multimodal | - | Keep data samples whose similarities between sampled video frame images and text are within a specific range | +| video_motion_score_filter | Video | - | Keep samples with video motion scores within a specific range | +| video_ocr_area_ratio_filter | Video | - | Keep data samples whose detected text area ratios for specified frames in the video are within a specified range | +| video_resolution_filter | Video | - | Keeps samples containing videos with horizontal and vertical resolutions within the specified range | +| word_num_filter | General | en, zh | Keeps samples with word count within the specified range | +| word_repetition_filter | General | en, zh | Keeps samples with word-level n-gram repetition ratio within the specified range | ## Deduplicator @@ -119,6 +140,7 @@ All the specific operators are listed below, each featured with several capabili | document_minhash_deduplicator | General | en, zh | Deduplicates samples at document-level using MinHashLSH | | document_simhash_deduplicator | General | en, zh | Deduplicates samples at document-level using SimHash | | image_deduplicator | Image | - | Deduplicates samples at document-level using exact matching of images between documents | +| video_deduplicator | Video | - | Deduplicates samples at document-level using exact matching of videos between documents | ## Selector diff --git a/docs/Operators_ZH.md b/docs/Operators_ZH.md index f3df33d89..4517c614c 100644 --- a/docs/Operators_ZH.md +++ b/docs/Operators_ZH.md @@ -2,6 +2,8 @@ 算子 (Operator) 是协助数据修改、清理、过滤、去重等基本流程的集合。我们支持广泛的数据来源和文件格式,并支持对自定义数据集的灵活扩展。 +这个页面提供了OP的基本描述,用户可以参考[API文档](https://alibaba.github.io/data-juicer/)更细致了解每个OP的具体参数,并且可以查看、运行单元测试,来体验[各OP的用法示例](../tests/ops)以及每个OP作用于内置测试数据样本时的效果。 + ## 概览 Data-Juicer 中的算子分为以下 5 种类型。 @@ -9,9 +11,9 @@ Data-Juicer 中的算子分为以下 5 种类型。 | 类型 | 数量 | 描述 | |------------------------------------|:--:|---------------| | [ Formatter ]( #formatter ) | 7 | 发现、加载、规范化原始数据 | -| [ Mapper ]( #mapper ) | 26 | 对数据样本进行编辑和转换 | -| [ Filter ]( #filter ) | 28 | 过滤低质量样本 | -| [ Deduplicator ]( #deduplicator ) | 4 | 识别、删除重复样本 | +| [ Mapper ]( #mapper ) | 38 | 对数据样本进行编辑和转换 | +| [ Filter ]( #filter ) | 36 | 过滤低质量样本 | +| [ Deduplicator ]( #deduplicator ) | 5 | 识别、删除重复样本 | | [ Selector ]( #selector ) | 2 | 基于排序选取高质量样本 | 下面列出所有具体算子,每种算子都通过多个标签来注明其主要功能。 @@ -23,6 +25,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 - Financial: 与金融领域相关 - Image: 专用于图像或多模态 - Audio: 专用于音频或多模态 + - Video: 专用于视频或多模态 - Multimodal: 专用于多模态 * Language 标签 @@ -46,6 +49,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 | 算子 | 场景 | 语言 | 描述 | |-----------------------------------------------------|-----------------------|-----------|--------------------------------------------------------| +| audio_ffmpeg_wrapped_mapper | Audio | - | 运行 FFmpeg 语音过滤器的简单封装 | | chinese_convert_mapper | General | zh | 用于在繁体中文、简体中文和日文汉字之间进行转换(借助 [opencc](https://github.com/BYVoid/OpenCC)) | | clean_copyright_mapper | Code | en, zh | 删除代码文件开头的版权声明 (:warning: 必须包含单词 *copyright*) | | clean_email_mapper | General | en, zh | 删除邮箱信息 | @@ -54,9 +58,9 @@ Data-Juicer 中的算子分为以下 5 种类型。 | clean_links_mapper | General, Code | en, zh | 删除链接,例如以 http 或 ftp 开头的 | | expand_macro_mapper | LaTeX | en, zh | 扩展通常在 TeX 文档顶部定义的宏 | | fix_unicode_mapper | General | en, zh | 修复损坏的 Unicode(借助 [ftfy](https://ftfy.readthedocs.io/)) | -| generate_caption_mapper | Multimodal | - | 生成样本,其标题是根据另一个辅助模型(例如 blip2)和原始样本中的图形生成的。 | -| gpt4v_generate_mapper | Multimodal | - | 基于gpt-4-vision和图像生成文本 | -| image_blur_mapper | Multimodal | - | 对图像进行模糊处理 | +| image_blur_mapper | Multimodal | - | 对图像进行模糊处理 | +| image_captioning_from_gpt4v_mapper | Multimodal | - | 基于gpt-4-vision和图像生成文本 | +| image_captioning_mapper | Multimodal | - | 生成样本,其标题是根据另一个辅助模型(例如 blip2)和原始样本中的图形生成的。 | | image_diffusion_mapper | Multimodal | - | 用stable diffusion生成图像,对图像进行增强 | | nlpaug_en_mapper | General | en | 使用`nlpaug`库对英语文本进行简单增强 | | nlpcda_zh_mapper | General | zh | 使用`nlpcda`库对中文文本进行简单增强 | @@ -70,8 +74,18 @@ Data-Juicer 中的算子分为以下 5 种类型。 | remove_specific_chars_mapper | General | en, zh | 删除任何用户指定的字符或子字符串 | | remove_table_text_mapper | General, Financial | en | 检测并删除可能的表格内容(:warning: 依赖正则表达式匹配,因此很脆弱) | | remove_words_with_incorrect_
substrings_mapper | General | en, zh | 删除包含指定子字符串的单词 | -| replace_content_mapper | General | en, zh | 使用一个指定的替换字符串替换文本中满足特定正则表达式模版的所有内容 | +| replace_content_mapper | General | en, zh | 使用一个指定的替换字符串替换文本中满足特定正则表达式模版的所有内容 | | sentence_split_mapper | General | en | 根据语义拆分和重组句子 | +| video_captioning_from_audio_mapper | Multimodal | - | 基于 Qwen-Audio 模型根据视频的音频流为视频生成新的标题描述 | +| video_captioning_from_video_mapper | Multimodal | - | 生成样本,其标题是根据另一个辅助模型(video-blip)和原始样本中的视频中指定帧的图像。 | +| video_ffmpeg_wrapped_mapper | Video | - | 运行 FFmpeg 视频过滤器的简单封装 | +| video_resize_aspect_ratio_mapper | Video | - | 将视频的宽高比调整到指定范围内 | +| video_resize_resolution_mapper | Video | - | 将视频映射到给定的分辨率区间 | +| video_split_by_duration_mapper | Multimodal | - | 根据时长将视频切分为多个片段 | +| video_split_by_key_frame_mapper | Multimodal | - | 根据关键帧切分视频 | +| video_split_by_scene_mapper | Multimodal | - | 将视频切分为场景片段 | +| video_tagging_from_audio_mapper | Multimodal | - | 从视频提取的音频中生成视频标签 | +| video_tagging_from_frames_mapper | Multimodal | - | 从视频提取的帧中生成视频标签 | | whitespace_normalization_mapper | General | en, zh | 将各种 Unicode 空白标准化为常规 ASCII 空格 (U+0020) | ## Filter @@ -80,7 +94,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 |--------------------------------|------------|--------|---------------------------------------------| | alphanumeric_filter | General | en, zh | 保留字母数字比例在指定范围内的样本 | | audio_duration_filter | Audio | - | 保留样本中包含的音频的时长在指定范围内的样本 | -| audio_nmf_snr_filter | Audio | - | 保留样本中包含的音频信噪比SNR(基于非负矩阵分解方法NMF计算)在指定范围内的样本. | +| audio_nmf_snr_filter | Audio | - | 保留样本中包含的音频信噪比SNR(基于非负矩阵分解方法NMF计算)在指定范围内的样本 | | audio_size_filter | Audio | - | 保留样本中包含的音频的大小(bytes)在指定范围内的样本 | | average_line_length_filter | Code | en, zh | 保留平均行长度在指定范围内的样本 | | character_repetition_filter | General | en, zh | 保留 char-level n-gram 重复比率在指定范围内的样本 | @@ -89,6 +103,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 | image_aspect_ratio_filter | Image | - | 保留样本中包含的图片的宽高比在指定范围内的样本 | | image_shape_filter | Image | - | 保留样本中包含的图片的形状(即宽和高)在指定范围内的样本 | | image_size_filter | Image | - | 保留样本中包含的图片的大小(bytes)在指定范围内的样本 | +| image_aesthetics_filter | Image | - | 保留包含美学分数在指定范围内的图像的样本 | | image_text_matching_filter | Multimodal | - | 保留图像-文本的分类匹配分(基于BLIP模型)在指定范围内的样本 | | image_text_similarity_filter | Multimodal | - | 保留图像-文本的特征余弦相似度(基于CLIP模型)在指定范围内的样本 | | language_id_score_filter | General | en, zh | 保留特定语言的样本,通过预测的置信度得分来判断 | @@ -104,6 +119,13 @@ Data-Juicer 中的算子分为以下 5 种类型。 | text_entity_dependency_filter | General | en, zh | 保留文本部分的依存树中具有非独立实体的样本 | | text_length_filter | General | en, zh | 保留总文本长度在指定范围内的样本 | | token_num_filter | General | en, zh | 保留token数在指定范围内的样本 | +| video_aspect_ratio_filter | Video | - | 保留样本中包含的视频的宽高比在指定范围内的样本 | +| video_duration_filter | Video | - | 保留样本中包含的视频的时长在指定范围内的样本 | +| video_aesthetics_filter | Video | - | 保留指定帧的美学分数在指定范围内的样本| +| video_frames_text_similarity_filter | Multimodal | - | 保留视频中指定帧的图像-文本的特征余弦相似度(基于CLIP模型)在指定范围内的样本 | +| video_motion_score_filter | Video | - | 保留样本中包含的视频的运动份(基于稠密光流)在指定范围内的样本 | +| video_ocr_area_ratio_filter | Video | - | 保留样本中包含的视频的特定帧中检测出的文本的面积占比在指定范围内的样本 | +| video_resolution_filter | Video | - | 保留样本中包含的视频的分辨率(包括横向分辨率和纵向分辨率)在指定范围内的样本 | | word_num_filter | General | en, zh | 保留字数在指定范围内的样本 | | word_repetition_filter | General | en, zh | 保留 word-level n-gram 重复比率在指定范围内的样本 | @@ -115,6 +137,7 @@ Data-Juicer 中的算子分为以下 5 种类型。 | document_minhash_deduplicator | General | en, zh | 使用 MinHashLSH 在文档级别对样本去重 | | document_simhash_deduplicator | General | en, zh | 使用 SimHash 在文档级别对样本去重 | | image_deduplicator | Image | - | 使用文档之间图像的精确匹配在文档级别删除重复样本 | +| video_deduplicator | Video | - | 使用文档之间视频的精确匹配在文档级别删除重复样本 | ## Selector diff --git a/environments/dist_requires.txt b/environments/dist_requires.txt index e02756318..0edc5aa35 100644 --- a/environments/dist_requires.txt +++ b/environments/dist_requires.txt @@ -1 +1 @@ -ray +ray==2.9.2 diff --git a/environments/minimal_requires.txt b/environments/minimal_requires.txt index 31ef270e8..d7696c75b 100644 --- a/environments/minimal_requires.txt +++ b/environments/minimal_requires.txt @@ -1,7 +1,8 @@ -fsspec==2023.3.0 +fsspec==2023.5.0 pyarrow<=12.0.0 pandas==2.0.0 datasets==2.11.0 +av soundfile librosa loguru diff --git a/environments/science_requires.txt b/environments/science_requires.txt index 5116c8026..4421aad0d 100644 --- a/environments/science_requires.txt +++ b/environments/science_requires.txt @@ -1,3 +1,4 @@ +easyocr fasttext-wheel kenlm sentencepiece @@ -8,10 +9,18 @@ selectolax nlpaug nlpcda nltk -transformers +transformers>=4.37 +transformers_stream_generator +einops +accelerate +tiktoken opencc==1.1.6 imagededup torch +torchaudio dlib spacy-pkuseg==0.0.32 diffusers +simple-aesthetics-predictor +scenedetect[opencv] +ffmpeg-python diff --git a/scripts/README.md b/scripts/README.md new file mode 100644 index 000000000..e20de6fab --- /dev/null +++ b/scripts/README.md @@ -0,0 +1,14 @@ +# Scripts for Running on Multi Nodes + + +#### Running Using DLC(Deep Learing Containers) + +Internally we use [DLC](https://www.alibabacloud.com/help/zh/pai/user-guide/container-training/) from [PAI](https://www.alibabacloud.com/zh/product/machine-learning) to process data on multiple nodes. + +The scripts to run are in ./dlc folder. + +#### Running Using Slurm + + - [ ] We will provide scripts to support running on slurm. + +You can also manually partition the data according to specific circumstances and then use Slurm to run it on multiple machines by yourself. \ No newline at end of file diff --git a/scripts/dlc/partition_data_dlc.py b/scripts/dlc/partition_data_dlc.py new file mode 100644 index 000000000..b0f5bbbfc --- /dev/null +++ b/scripts/dlc/partition_data_dlc.py @@ -0,0 +1,49 @@ +import argparse +import json +import os +from collections import defaultdict +from typing import List + + +def partition_data(json_file_path: str, hostnames: List[str]): + with open(json_file_path, 'r') as f: + data = [json.loads(line) for line in f] + video_to_entries_map = defaultdict(list) + for entry in data: + video_path = entry['videos'][0] + video_to_entries_map[video_path].append(entry) + nodes_data = defaultdict(list) + nodes_video_size = {k: 0 for k in hostnames} + + # distribute videos to nodes based on the total size of videos + video_sizes = { + video: os.path.getsize(video) + for video in video_to_entries_map.keys() + } + + sorted_videos = sorted(video_sizes, key=video_sizes.get, reverse=True) + for video in sorted_videos: + min_node = min(nodes_video_size, key=nodes_video_size.get) + nodes_data[min_node].extend(video_to_entries_map[video]) + nodes_video_size[min_node] += video_sizes[video] + + for hostname in hostnames: + host_file_path = f"{json_file_path.rsplit('.', 1)[0]}_{hostname}.json" + with open(host_file_path, 'w') as f: + for entry in nodes_data[hostname]: + f.write(json.dumps(entry) + '\n') + + +# Usage +if __name__ == '__main__': + parser = argparse.ArgumentParser( + description='Partition data across hostnames.') + + parser.add_argument('file_path', + type=str, + help='Path of the file to distribute.') + parser.add_argument('hostnames', nargs='+', help='The list of hostnames') + + args = parser.parse_args() + + partition_data(args.file_path, args.hostnames) diff --git a/scripts/dlc/run_on_dlc.sh b/scripts/dlc/run_on_dlc.sh new file mode 100644 index 000000000..8ed356e99 --- /dev/null +++ b/scripts/dlc/run_on_dlc.sh @@ -0,0 +1,40 @@ +#!/bin/bash + +# paremeters +datajuicer_path= # path to data-juicer +config_path= # path to config file + +# hostname +hostname=$(hostname) + +# into datajuicer_path +cd "$datajuicer_path" || { echo "Could not change directory to $datajuicer_path"; exit 1; } + +# copy and generate new config file for current host + +config_basename=$(basename "$config_path") +config_dirname=$(dirname "$config_path") +config_extension="${config_basename##*.}" +config_basename="${config_basename%.*}" + +new_config_file="${config_dirname}/${config_basename}_$hostname.$config_extension" +cp "$config_path" "$new_config_file" || { echo "Could not copy config file"; exit 1; } + +echo "$new_config_file" + +if [[ "$OSTYPE" == "darwin"* ]]; then + SED_I_SUFFIX=".bak" +else + SED_I_SUFFIX="" +fi + +if grep -q "dataset_path: .*\.json" "$new_config_file"; then + # .json data_path + sed -i$SED_I_SUFFIX "s|\(dataset_path: \)\(.*\)\(/[^/]*\)\(.json\)|\1\2\3_$hostname\4|" "$new_config_file" +else + # dir dataset_path + sed -i$SED_I_SUFFIX "s|\(dataset_path: '\)\(.*\)'\(.*\)|\1\2_$hostname'\3|" "$new_config_file" +fi + +# run to process data +python tools/process_data.py --config "$new_config_file" diff --git a/tests/config/test_config_funcs.py b/tests/config/test_config_funcs.py index 9e66e6b66..a2748ed7f 100644 --- a/tests/config/test_config_funcs.py +++ b/tests/config/test_config_funcs.py @@ -7,12 +7,13 @@ from data_juicer.config import init_configs from data_juicer.ops import load_ops +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase test_yaml_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'demo_4_test.yaml') -class ConfigTest(unittest.TestCase): +class ConfigTest(DataJuicerTestCaseBase): def test_help_info(self): out = StringIO() @@ -35,12 +36,13 @@ def test_yaml_cfg_file(self): self.assertIsInstance(cfg, Namespace) self.assertEqual(cfg.project_name, 'test_demo') self.assertDictEqual( - cfg.process[0], - {'whitespace_normalization_mapper': { - 'text_key': 'text', - 'image_key': 'images', - 'audio_key': 'audios', - }}, 'nested dict load fail, for nonparametric op') + cfg.process[0], { + 'whitespace_normalization_mapper': { + 'text_key': 'text', + 'image_key': 'images', + 'audio_key': 'audios', + } + }, 'nested dict load fail, for nonparametric op') self.assertDictEqual( cfg.process[1], { 'language_id_score_filter': { diff --git a/tests/format/data/structured/demo-dataset.jsonl b/tests/format/data/structured/demo-dataset.jsonl index 77a0a1d88..116bf29e8 100644 --- a/tests/format/data/structured/demo-dataset.jsonl +++ b/tests/format/data/structured/demo-dataset.jsonl @@ -3,4 +3,4 @@ {"text": "Today is Sunday and it's a happy day!", "meta": {"src": "Arxiv", "date": "2023-04-27", "version": "1.0"}} {"text": "Do you need a cup of coffee?", "meta": {"src": "code", "author": "xxx"}} {"text": "Today is Sunday and it's a happy day!", "meta": {"src": "Arxiv", "date": "2023-04-27", "version": "1.0"}} -{"text": "Do you need a cup of coffee?", "meta": {"src": "code", "author": "xxx"}} \ No newline at end of file +{"text": "Do you need a cup of coffee?", "meta": {"src": "code", "author": "xxx"}} diff --git a/tests/format/test_csv_formatter.py b/tests/format/test_csv_formatter.py index 9db1ad343..591ccd61a 100644 --- a/tests/format/test_csv_formatter.py +++ b/tests/format/test_csv_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.csv_formatter import CsvFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CsvFormatterTest(unittest.TestCase): +class CsvFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), diff --git a/tests/format/test_mixture_formatter.py b/tests/format/test_mixture_formatter.py index fc16dcbe1..a4d339695 100644 --- a/tests/format/test_mixture_formatter.py +++ b/tests/format/test_mixture_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.mixture_formatter import MixtureFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class MixtureFormatterTest(unittest.TestCase): +class MixtureFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), @@ -33,7 +34,8 @@ def test_sample_number(self): def test_sample_number_weight(self): max_samples = 2 - formatter = MixtureFormatter('0.5 ' + self._file, max_samples=max_samples) + formatter = MixtureFormatter('0.5 ' + self._file, + max_samples=max_samples) ds = formatter.load_dataset() self.assertEqual(len(ds), max_samples) self.assertEqual(list(ds.features.keys()), ['text', 'meta']) @@ -45,13 +47,6 @@ def test_multi_datasets_without_weight(self): self.assertEqual(len(ds), 12) self.assertEqual(list(ds.features.keys()), ['text', 'meta']) - def test_multi_datasets_with_weight(self): - data_path = self._file + ' ' + self._file2 - formatter = MixtureFormatter(data_path) - ds = formatter.load_dataset() - self.assertEqual(len(ds), 12) - self.assertEqual(list(ds.features.keys()), ['text', 'meta']) - def test_multi_datasets_with_one_weight(self): data_path = '0.5 ' + self._file + ' ' + self._file2 formatter = MixtureFormatter(data_path) @@ -74,5 +69,6 @@ def test_multi_datasets_with_sample(self): self.assertEqual(len(ds), max_samples) self.assertEqual(list(ds.features.keys()), ['text', 'meta']) + if __name__ == '__main__': unittest.main() diff --git a/tests/format/test_parquet_formatter.py b/tests/format/test_parquet_formatter.py index 107ea870c..6df093368 100644 --- a/tests/format/test_parquet_formatter.py +++ b/tests/format/test_parquet_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.parquet_formatter import ParquetFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CsvFormatterTest(unittest.TestCase): +class CsvFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), diff --git a/tests/format/test_tsv_formatter.py b/tests/format/test_tsv_formatter.py index cde6bed85..46f1fad4d 100644 --- a/tests/format/test_tsv_formatter.py +++ b/tests/format/test_tsv_formatter.py @@ -2,9 +2,10 @@ import unittest from data_juicer.format.tsv_formatter import TsvFormatter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TsvFormatterTest(unittest.TestCase): +class TsvFormatterTest(DataJuicerTestCaseBase): def setUp(self): self._path = os.path.join(os.path.dirname(os.path.realpath(__file__)), diff --git a/tests/format/test_unify_format.py b/tests/format/test_unify_format.py index c9b41d19d..52b87493d 100644 --- a/tests/format/test_unify_format.py +++ b/tests/format/test_unify_format.py @@ -5,9 +5,10 @@ from data_juicer.format.formatter import load_dataset, unify_format from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class UnifyFormatTest(unittest.TestCase): +class UnifyFormatTest(DataJuicerTestCaseBase): def run_test(self, sample, args=None): if args is None: @@ -347,26 +348,26 @@ def test_hetero_meta(self): file_path = os.path.join(cur_dir, 'demo-dataset.jsonl') ds = load_dataset('json', data_files=file_path) ds = unify_format(ds) - import datetime - # the 'None' fields are missing fields after merging - sample = [{ - 'text': "Today is Sunday and it's a happy day!", - 'meta': { - 'src': 'Arxiv', - 'date': datetime.datetime(2023, 4, 27, 0, 0), - 'version': '1.0', - 'author': None - } - }, { - 'text': 'Do you need a cup of coffee?', - 'meta': { - 'src': 'code', - 'date': None, - 'version': None, - 'author': 'xxx' - } - }] + # import datetime + # the 'None' fields are missing fields after merging + # sample = [{ + # 'text': "Today is Sunday and it's a happy day!", + # 'meta': { + # 'src': 'Arxiv', + # 'date': datetime.datetime(2023, 4, 27, 0, 0), + # 'version': '1.0', + # 'author': None + # } + # }, { + # 'text': 'Do you need a cup of coffee?', + # 'meta': { + # 'src': 'code', + # 'date': None, + # 'version': None, + # 'author': 'xxx' + # } + # }] # test nested and missing field for the following cases: # 1. first row, then column unified_sample_first = ds[0] diff --git a/tests/ops/data/video1.mp4 b/tests/ops/data/video1.mp4 new file mode 100644 index 000000000..5b0cad49f Binary files /dev/null and b/tests/ops/data/video1.mp4 differ diff --git a/tests/ops/data/video2.mp4 b/tests/ops/data/video2.mp4 new file mode 100644 index 000000000..28acb927f Binary files /dev/null and b/tests/ops/data/video2.mp4 differ diff --git a/tests/ops/data/video3-no-audio.mp4 b/tests/ops/data/video3-no-audio.mp4 new file mode 100644 index 000000000..ad30ec95b Binary files /dev/null and b/tests/ops/data/video3-no-audio.mp4 differ diff --git a/tests/ops/data/video3.mp4 b/tests/ops/data/video3.mp4 new file mode 100644 index 000000000..45db64a51 Binary files /dev/null and b/tests/ops/data/video3.mp4 differ diff --git a/tests/ops/data/video4.mp4 b/tests/ops/data/video4.mp4 new file mode 100644 index 000000000..8bf5fe0ea Binary files /dev/null and b/tests/ops/data/video4.mp4 differ diff --git a/tests/ops/data/video5.mp4 b/tests/ops/data/video5.mp4 new file mode 100644 index 000000000..46a52855e Binary files /dev/null and b/tests/ops/data/video5.mp4 differ diff --git a/tests/ops/deduplicator/test_document_deduplicator.py b/tests/ops/deduplicator/test_document_deduplicator.py index 740caae18..5a37a2e91 100644 --- a/tests/ops/deduplicator/test_document_deduplicator.py +++ b/tests/ops/deduplicator/test_document_deduplicator.py @@ -4,9 +4,10 @@ from data_juicer.ops.deduplicator.document_deduplicator import \ DocumentDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class DocumentDeduplicatorTest(unittest.TestCase): +class DocumentDeduplicatorTest(DataJuicerTestCaseBase): def _run_doc_dedup(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) diff --git a/tests/ops/deduplicator/test_document_minhash_deduplicator.py b/tests/ops/deduplicator/test_document_minhash_deduplicator.py index b60209e8b..5190ed1e4 100644 --- a/tests/ops/deduplicator/test_document_minhash_deduplicator.py +++ b/tests/ops/deduplicator/test_document_minhash_deduplicator.py @@ -4,9 +4,10 @@ from data_juicer.ops.deduplicator.document_minhash_deduplicator import \ DocumentMinhashDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class DocumentMinhashDeduplicatorTest(unittest.TestCase): +class DocumentMinhashDeduplicatorTest(DataJuicerTestCaseBase): def _run_minhash_dedup(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) diff --git a/tests/ops/deduplicator/test_document_simhash_deduplicator.py b/tests/ops/deduplicator/test_document_simhash_deduplicator.py index d021423c0..ddde50e82 100644 --- a/tests/ops/deduplicator/test_document_simhash_deduplicator.py +++ b/tests/ops/deduplicator/test_document_simhash_deduplicator.py @@ -4,9 +4,10 @@ from data_juicer.ops.deduplicator.document_simhash_deduplicator import \ DocumentSimhashDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class DocumentSimhashDeduplicatorTest(unittest.TestCase): +class DocumentSimhashDeduplicatorTest(DataJuicerTestCaseBase): def _run_simhash_dedup(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) diff --git a/tests/ops/deduplicator/test_image_deduplicator.py b/tests/ops/deduplicator/test_image_deduplicator.py index 3ac131506..a643b55be 100644 --- a/tests/ops/deduplicator/test_image_deduplicator.py +++ b/tests/ops/deduplicator/test_image_deduplicator.py @@ -3,30 +3,31 @@ from datasets import Dataset -from data_juicer.ops.deduplicator.image_deduplicator import \ - ImageDeduplicator +from data_juicer.ops.deduplicator.image_deduplicator import ImageDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageDeduplicatorTest(unittest.TestCase): +class ImageDeduplicatorTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - # img4.png is a duplicate sample of img1.png - img4_path = os.path.join(data_path, 'img4.png') - # img5.jpg is a duplicate sample of img2.jpg - img5_path = os.path.join(data_path, 'img5.jpg') - # img6.jpg is a duplicate sample of img3.jpg - img6_path = os.path.join(data_path, 'img6.jpg') - # img7.jpg is a duplicate sample of img6.jpg - img7_path = os.path.join(data_path, 'img7.jpg') - - - def _run_image_deduplicator(self, - dataset: Dataset, target_list, - op): + # img1_dup.png is a duplicate sample of img1.png + img4_path = os.path.join(data_path, 'img1_dup.png') + os.symlink(img1_path, img4_path) + # img2_dup.jpg is a duplicate sample of img2.jpg + img5_path = os.path.join(data_path, 'img2_dup.jpg') + os.symlink(img2_path, img5_path) + # img3_dup.jpg is a duplicate sample of img3.jpg + img6_path = os.path.join(data_path, 'img3_dup.jpg') + os.symlink(img3_path, img6_path) + # img3_dup_dup.jpg is a duplicate sample of img6.jpg + img7_path = os.path.join(data_path, 'img3_dup_dup.jpg') + os.symlink(img6_path, img7_path) + + def _run_image_deduplicator(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_hash) dataset, _ = op.process(dataset) @@ -63,11 +64,7 @@ def test_2(self): }, { 'images': [self.img2_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = ImageDeduplicator() self._run_image_deduplicator(dataset, tgt_list, op) @@ -216,5 +213,6 @@ def test_8(self): op = ImageDeduplicator(method='ahash') self._run_image_deduplicator(dataset, tgt_list, op) + if __name__ == '__main__': unittest.main() diff --git a/tests/ops/deduplicator/test_video_deduplicator.py b/tests/ops/deduplicator/test_video_deduplicator.py new file mode 100644 index 000000000..951ed6bf0 --- /dev/null +++ b/tests/ops/deduplicator/test_video_deduplicator.py @@ -0,0 +1,150 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.deduplicator.video_deduplicator import VideoDeduplicator +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoDeduplicatorTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + video1_path = os.path.join(data_path, 'video1.mp4') + video2_path = os.path.join(data_path, 'video2.mp4') + video3_path = os.path.join(data_path, 'video3.mp4') + # video1_dup.mp4 is a duplicate sample of video1.mp4 + video4_path = os.path.join(data_path, 'video1_dup.mp4') + os.symlink(video1_path, video4_path) + # video2_dup.mp4 is a duplicate sample of video2.mp4 + video5_path = os.path.join(data_path, 'video2_dup.mp4') + os.symlink(video2_path, video5_path) + # video3_dup.mp4 is a duplicate sample of video3.mp4 + video6_path = os.path.join(data_path, 'video3_dup.mp4') + os.symlink(video3_path, video6_path) + # video3_dup_dup.mp4 is a duplicate sample of video6.mp4 + video7_path = os.path.join(data_path, 'video3_dup_dup.mp4') + os.symlink(video6_path, video7_path) + + def _run_video_deduplicator(self, dataset: Dataset, target_list, op): + + dataset = dataset.map(op.compute_hash) + dataset, _ = op.process(dataset) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_1(self): + + ds_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }] + tgt_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_2(self): + + ds_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video2_path] + }] + tgt_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_3(self): + + ds_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }, { + 'videos': [self.video4_path] + }, { + 'videos': [self.video5_path] + }, { + 'videos': [self.video6_path] + }, { + 'videos': [self.video7_path] + }] + tgt_list = [{ + 'videos': [self.video1_path] + }, { + 'videos': [self.video2_path] + }, { + 'videos': [self.video3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_4(self): + + ds_list = [{ + 'videos': [self.video1_path, self.video2_path, self.video3_path] + }, { + 'videos': [self.video4_path, self.video5_path, self.video6_path] + }, { + 'videos': [self.video7_path, self.video5_path] + }, { + 'videos': [self.video6_path, self.video5_path] + }] + tgt_list = [{ + 'videos': [self.video1_path, self.video2_path, self.video3_path] + }, { + 'videos': [self.video7_path, self.video5_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + def test_5(self): + + ds_list = [{ + 'videos': [self.video1_path, self.video2_path] + }, { + 'videos': [self.video2_path, self.video1_path] + }, { + 'videos': [self.video4_path, self.video5_path] + }, { + 'videos': [self.video7_path, self.video7_path] + }, { + 'videos': [self.video6_path, self.video6_path] + }] + tgt_list = [{ + 'videos': [self.video1_path, self.video2_path] + }, { + 'videos': [self.video2_path, self.video1_path] + }, { + 'videos': [self.video7_path, self.video7_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDeduplicator() + self._run_video_deduplicator(dataset, tgt_list, op) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_alphanumeric_filter.py b/tests/ops/filter/test_alphanumeric_filter.py index a8558cf06..efca696c2 100644 --- a/tests/ops/filter/test_alphanumeric_filter.py +++ b/tests/ops/filter/test_alphanumeric_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.alphanumeric_filter import AlphanumericFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AlphanumericFilterTest(unittest.TestCase): +class AlphanumericFilterTest(DataJuicerTestCaseBase): def _run_alphanumeric_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_audio_duration_filter.py b/tests/ops/filter/test_audio_duration_filter.py index f12b45bb7..91a39bfd8 100644 --- a/tests/ops/filter/test_audio_duration_filter.py +++ b/tests/ops/filter/test_audio_duration_filter.py @@ -5,12 +5,13 @@ from data_juicer.ops.filter.audio_duration_filter import AudioDurationFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AudioDurationFilterTest(unittest.TestCase): +class AudioDurationFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') aud1_path = os.path.join(data_path, 'audio1.wav') # about 6s aud2_path = os.path.join(data_path, 'audio2.wav') # about 14s aud3_path = os.path.join(data_path, 'audio3.ogg') # about 1min59s @@ -49,7 +50,7 @@ def test_default_filter(self): op = AudioDurationFilter() self._run_audio_duration_filter(dataset, tgt_list, op) - def test_filter_short_audios(self): + def test_filter_long_audios(self): ds_list = [{ 'audios': [self.aud1_path] @@ -58,14 +59,12 @@ def test_filter_short_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }] + tgt_list = [{'audios': [self.aud1_path]}] dataset = Dataset.from_list(ds_list) op = AudioDurationFilter(max_duration=10) self._run_audio_duration_filter(dataset, tgt_list, op) - def test_filter_long_audios(self): + def test_filter_short_audios(self): ds_list = [{ 'audios': [self.aud1_path] @@ -74,9 +73,7 @@ def test_filter_long_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioDurationFilter(min_duration=60) self._run_audio_duration_filter(dataset, tgt_list, op) @@ -90,12 +87,9 @@ def test_filter_audios_within_range(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud2_path] - }] + tgt_list = [{'audios': [self.aud2_path]}] dataset = Dataset.from_list(ds_list) - op = AudioDurationFilter(min_duration=10, - max_duration=20) + op = AudioDurationFilter(min_duration=10, max_duration=20) self._run_audio_duration_filter(dataset, tgt_list, op) def test_any(self): @@ -143,12 +137,9 @@ def test_filter_in_parallel(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud2_path] - }] + tgt_list = [{'audios': [self.aud2_path]}] dataset = Dataset.from_list(ds_list) - op = AudioDurationFilter(min_duration=10, - max_duration=20) + op = AudioDurationFilter(min_duration=10, max_duration=20) self._run_audio_duration_filter(dataset, tgt_list, op, np=2) diff --git a/tests/ops/filter/test_audio_nmf_snr_filter.py b/tests/ops/filter/test_audio_nmf_snr_filter.py index 84b73d2c8..728c43f39 100644 --- a/tests/ops/filter/test_audio_nmf_snr_filter.py +++ b/tests/ops/filter/test_audio_nmf_snr_filter.py @@ -5,12 +5,13 @@ from data_juicer.ops.filter.audio_nmf_snr_filter import AudioNMFSNRFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AudioNMFSNRFilterTest(unittest.TestCase): +class AudioNMFSNRFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') aud1_path = os.path.join(data_path, 'audio1.wav') # about -7dB aud2_path = os.path.join(data_path, 'audio2.wav') # about 6dB aud3_path = os.path.join(data_path, 'audio3.ogg') # about 3dB @@ -58,11 +59,7 @@ def test_filter_low_snr_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud2_path] - }, { - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud2_path]}, {'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=0) self._run_audio_nmf_snr_filter(dataset, tgt_list, op) @@ -76,11 +73,7 @@ def test_filter_high_snr_audios(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }, { - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud1_path]}, {'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=-1000, max_snr=5) self._run_audio_nmf_snr_filter(dataset, tgt_list, op) @@ -94,9 +87,7 @@ def test_filter_audios_within_range(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=0, max_snr=5) self._run_audio_nmf_snr_filter(dataset, tgt_list, op) @@ -142,9 +133,7 @@ def test_filter_in_parallel(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) op = AudioNMFSNRFilter(min_snr=0, max_snr=5, any_or_all='any') self._run_audio_nmf_snr_filter(dataset, tgt_list, op, np=2) diff --git a/tests/ops/filter/test_audio_size_filter.py b/tests/ops/filter/test_audio_size_filter.py index c47241965..00b4158d7 100644 --- a/tests/ops/filter/test_audio_size_filter.py +++ b/tests/ops/filter/test_audio_size_filter.py @@ -5,17 +5,18 @@ from data_juicer.ops.filter.audio_size_filter import AudioSizeFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AudioSizeFilterTest(unittest.TestCase): +class AudioSizeFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') aud1_path = os.path.join(data_path, 'audio1.wav') # 970574 / 948K aud2_path = os.path.join(data_path, 'audio2.wav') # 2494872 / 2.4M aud3_path = os.path.join(data_path, 'audio3.ogg') # 597254 / 583K - def _run_audio_size_filter(self,dataset: Dataset, target_list, op, np=1): + def _run_audio_size_filter(self, dataset: Dataset, target_list, op, np=1): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -34,11 +35,9 @@ def test_min_max(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }] + tgt_list = [{'audios': [self.aud1_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB") + op = AudioSizeFilter(min_size='800kb', max_size='1MB') self._run_audio_size_filter(dataset, tgt_list, op) def test_min(self): @@ -50,13 +49,9 @@ def test_min(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }, { - 'audios': [self.aud2_path] - }] + tgt_list = [{'audios': [self.aud1_path]}, {'audios': [self.aud2_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="900kib") + op = AudioSizeFilter(min_size='900kib') self._run_audio_size_filter(dataset, tgt_list, op) def test_max(self): @@ -68,13 +63,9 @@ def test_max(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }, { - 'audios': [self.aud3_path] - }] + tgt_list = [{'audios': [self.aud1_path]}, {'audios': [self.aud3_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(max_size="2MiB") + op = AudioSizeFilter(max_size='2MiB') self._run_audio_size_filter(dataset, tgt_list, op) def test_any(self): @@ -92,8 +83,9 @@ def test_any(self): 'audios': [self.aud1_path, self.aud3_path] }] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB", - any_or_all='any') + op = AudioSizeFilter(min_size='800kb', + max_size='1MB', + any_or_all='any') self._run_audio_size_filter(dataset, tgt_list, op) def test_all(self): @@ -107,8 +99,9 @@ def test_all(self): }] tgt_list = [] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB", - any_or_all='all') + op = AudioSizeFilter(min_size='800kb', + max_size='1MB', + any_or_all='all') self._run_audio_size_filter(dataset, tgt_list, op) def test_filter_in_parallel(self): @@ -120,11 +113,9 @@ def test_filter_in_parallel(self): }, { 'audios': [self.aud3_path] }] - tgt_list = [{ - 'audios': [self.aud1_path] - }] + tgt_list = [{'audios': [self.aud1_path]}] dataset = Dataset.from_list(ds_list) - op = AudioSizeFilter(min_size="800kb", max_size="1MB") + op = AudioSizeFilter(min_size='800kb', max_size='1MB') self._run_audio_size_filter(dataset, tgt_list, op, np=2) diff --git a/tests/ops/filter/test_average_line_length_filter.py b/tests/ops/filter/test_average_line_length_filter.py index 740d5f3c4..a1c39e702 100644 --- a/tests/ops/filter/test_average_line_length_filter.py +++ b/tests/ops/filter/test_average_line_length_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.average_line_length_filter import \ AverageLineLengthFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class AverageLineLengthFilterTest(unittest.TestCase): +class AverageLineLengthFilterTest(DataJuicerTestCaseBase): def _run_average_line_length_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_character_repetition_filter.py b/tests/ops/filter/test_character_repetition_filter.py index b54d76a71..85133c133 100644 --- a/tests/ops/filter/test_character_repetition_filter.py +++ b/tests/ops/filter/test_character_repetition_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.character_repetition_filter import \ CharacterRepetitionFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CharacterRepetitionFilterTest(unittest.TestCase): +class CharacterRepetitionFilterTest(DataJuicerTestCaseBase): def _run_character_repetition_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_face_area_filter.py b/tests/ops/filter/test_face_area_filter.py index 0008c9377..1e747ec59 100644 --- a/tests/ops/filter/test_face_area_filter.py +++ b/tests/ops/filter/test_face_area_filter.py @@ -5,20 +5,22 @@ from data_juicer.ops.filter.face_area_filter import FaceAreaFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class FaceAreaFilterTest(unittest.TestCase): +class FaceAreaFilterTest(DataJuicerTestCaseBase): maxDiff = None - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'cat.jpg') img2_path = os.path.join(data_path, 'lena.jpg') img3_path = os.path.join(data_path, 'lena-face.jpg') def _run_face_area_filter(self, - dataset: Dataset, target_list, + dataset: Dataset, + target_list, op, num_proc=1): if Fields.stats not in dataset.features: @@ -39,9 +41,7 @@ def test_filter_small(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img3_path] - }] + tgt_list = [{'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter(min_ratio=0.4, max_ratio=1.0) self._run_face_area_filter(dataset, tgt_list, op) @@ -55,11 +55,7 @@ def test_filter_large(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter(min_ratio=0.0, max_ratio=0.4) self._run_face_area_filter(dataset, tgt_list, op) @@ -67,20 +63,27 @@ def test_filter_large(self): def test_filter_multimodal(self): ds_list = [{ - 'text': 'a test sentence', 'images': [] + 'text': 'a test sentence', + 'images': [] }, { - 'text': 'a test sentence', 'images': [self.img1_path] + 'text': 'a test sentence', + 'images': [self.img1_path] }, { - 'text': 'a test sentence', 'images': [self.img2_path] + 'text': 'a test sentence', + 'images': [self.img2_path] }, { - 'text': 'a test sentence', 'images': [self.img3_path] + 'text': 'a test sentence', + 'images': [self.img3_path] }] tgt_list = [{ - 'text': 'a test sentence', 'images': [] + 'text': 'a test sentence', + 'images': [] }, { - 'text': 'a test sentence', 'images': [self.img1_path] + 'text': 'a test sentence', + 'images': [self.img1_path] }, { - 'text': 'a test sentence', 'images': [self.img2_path] + 'text': 'a test sentence', + 'images': [self.img2_path] }] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter() @@ -103,9 +106,7 @@ def test_any(self): 'images': [self.img1_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) - op = FaceAreaFilter(min_ratio=0.0, - max_ratio=0.4, - any_or_all='any') + op = FaceAreaFilter(min_ratio=0.0, max_ratio=0.4, any_or_all='any') self._run_face_area_filter(dataset, tgt_list, op) def test_all(self): @@ -117,13 +118,9 @@ def test_all(self): }, { 'images': [self.img1_path, self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path, self.img2_path] - }] + tgt_list = [{'images': [self.img1_path, self.img2_path]}] dataset = Dataset.from_list(ds_list) - op = FaceAreaFilter(min_ratio=0.0, - max_ratio=0.4, - any_or_all='all') + op = FaceAreaFilter(min_ratio=0.0, max_ratio=0.4, any_or_all='all') self._run_face_area_filter(dataset, tgt_list, op) def test_filter_multi_process(self): @@ -135,11 +132,7 @@ def test_filter_multi_process(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = FaceAreaFilter() self._run_face_area_filter(dataset, tgt_list, op, num_proc=3) diff --git a/tests/ops/filter/test_flagged_words_filter.py b/tests/ops/filter/test_flagged_words_filter.py index af7ddf233..e346eb0f5 100644 --- a/tests/ops/filter/test_flagged_words_filter.py +++ b/tests/ops/filter/test_flagged_words_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.flagged_words_filter import FlaggedWordFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class FlaggedWordFilterTest(unittest.TestCase): +class FlaggedWordFilterTest(DataJuicerTestCaseBase): def _run_flagged_words_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_image_aesthetics_filter.py b/tests/ops/filter/test_image_aesthetics_filter.py new file mode 100644 index 000000000..ef221bf08 --- /dev/null +++ b/tests/ops/filter/test_image_aesthetics_filter.py @@ -0,0 +1,155 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.image_aesthetics_filter import \ + ImageAestheticsFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class ImageAestheticsFilterTest(DataJuicerTestCaseBase): + + maxDiff = None + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + img1_path = os.path.join(data_path, 'cat.jpg') + img2_path = os.path.join(data_path, 'blip.jpg') + img3_path = os.path.join(data_path, 'lena-face.jpg') + + model_id = \ + 'shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE' + + # with shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE + # the img1, img2, img3 gets scores 0.4382, 0.5973, 0.5216 respectively + + def _run_image_aesthetics_filter(self, + dataset: Dataset, + target_list, + op, + num_proc=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=num_proc) + dataset = dataset.filter(op.process, num_proc=num_proc) + dataset = dataset.remove_columns(Fields.stats) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_filter_small(self): + + ds_list = [{ + 'images': [self.img1_path] + }, { + 'images': [self.img2_path] + }, { + 'images': [self.img3_path] + }] + tgt_list = [{'images': [self.img2_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + min_score=0.55, + max_score=1.0) + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_large(self): + + ds_list = [{ + 'images': [self.img1_path] + }, { + 'images': [self.img2_path] + }, { + 'images': [self.img3_path] + }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + min_score=0.4, + max_score=0.55) + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_multimodal(self): + + ds_list = [{ + 'text': 'a test sentence', + 'images': [] + }, { + 'text': 'a test sentence', + 'images': [self.img1_path] + }, { + 'text': 'a test sentence', + 'images': [self.img2_path] + }, { + 'text': 'a test sentence', + 'images': [self.img3_path] + }] + tgt_list = [{ + 'text': 'a test sentence', + 'images': [] + }, { + 'text': 'a test sentence', + 'images': [self.img2_path] + }, { + 'text': 'a test sentence', + 'images': [self.img3_path] + }] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, ) + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'images': [self.img1_path, self.img2_path] + }, { + 'images': [self.img2_path, self.img3_path] + }, { + 'images': [self.img1_path, self.img3_path] + }] + tgt_list = [{ + 'images': [self.img1_path, self.img2_path] + }, { + 'images': [self.img2_path, self.img3_path] + }, { + 'images': [self.img1_path, self.img3_path] + }] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + any_or_all='any') + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'images': [self.img1_path, self.img2_path] + }, { + 'images': [self.img2_path, self.img3_path] + }, { + 'images': [self.img1_path, self.img3_path] + }] + tgt_list = [{'images': [self.img2_path, self.img3_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, + any_or_all='all') + self._run_image_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_multi_process(self): + + ds_list = [{ + 'images': [self.img1_path] + }, { + 'images': [self.img2_path] + }, { + 'images': [self.img3_path] + }] + tgt_list = [{'images': [self.img2_path]}, {'images': [self.img3_path]}] + dataset = Dataset.from_list(ds_list) + op = ImageAestheticsFilter(hf_scorer_model=self.model_id, ) + self._run_image_aesthetics_filter(dataset, tgt_list, op, num_proc=3) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_image_aspect_ratio_filter.py b/tests/ops/filter/test_image_aspect_ratio_filter.py index a328d934a..d8d3df0ea 100644 --- a/tests/ops/filter/test_image_aspect_ratio_filter.py +++ b/tests/ops/filter/test_image_aspect_ratio_filter.py @@ -6,18 +6,18 @@ from data_juicer.ops.filter.image_aspect_ratio_filter import \ ImageAspectRatioFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageAspectRatioFilterTest(unittest.TestCase): +class ImageAspectRatioFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_image_aspect_ratio_filter(self, - dataset: Dataset, target_list, + def _run_image_aspect_ratio_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, @@ -37,9 +37,7 @@ def test_filter1(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }] + tgt_list = [{'images': [self.img1_path]}] dataset = Dataset.from_list(ds_list) op = ImageAspectRatioFilter(min_ratio=0.8, max_ratio=1.2) self._run_image_aspect_ratio_filter(dataset, tgt_list, op) @@ -53,11 +51,7 @@ def test_filter2(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) op = ImageAspectRatioFilter(min_ratio=0.8) self._run_image_aspect_ratio_filter(dataset, tgt_list, op) @@ -71,11 +65,7 @@ def test_filter3(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img3_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) op = ImageAspectRatioFilter(max_ratio=1.2) self._run_image_aspect_ratio_filter(dataset, tgt_list, op) diff --git a/tests/ops/filter/test_image_shape_filter.py b/tests/ops/filter/test_image_shape_filter.py index 3cc73406c..e7e5deaed 100644 --- a/tests/ops/filter/test_image_shape_filter.py +++ b/tests/ops/filter/test_image_shape_filter.py @@ -5,20 +5,18 @@ from data_juicer.ops.filter.image_shape_filter import ImageShapeFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageShapeFilterTest(unittest.TestCase): +class ImageShapeFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_image_shape_filter(self, - dataset: Dataset, - target_list, - op): + def _run_image_shape_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -37,12 +35,9 @@ def test_filter1(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img2_path] - }] + tgt_list = [{'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(min_width=400, - min_height=400) + op = ImageShapeFilter(min_width=400, min_height=400) self._run_image_shape_filter(dataset, tgt_list, op) def test_filter2(self): @@ -54,14 +49,9 @@ def test_filter2(self): }, { 'images': [self.img3_path] }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img3_path] - }] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(max_width=500, - max_height=500) + op = ImageShapeFilter(max_width=500, max_height=500) self._run_image_shape_filter(dataset, tgt_list, op) def test_filter3(self): @@ -99,9 +89,7 @@ def test_any(self): 'images': [self.img2_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(min_width=400, - min_height=400, - any_or_all='any') + op = ImageShapeFilter(min_width=400, min_height=400, any_or_all='any') self._run_image_shape_filter(dataset, tgt_list, op) def test_all(self): @@ -115,9 +103,7 @@ def test_all(self): }] tgt_list = [] dataset = Dataset.from_list(ds_list) - op = ImageShapeFilter(min_width=400, - min_height=400, - any_or_all='all') + op = ImageShapeFilter(min_width=400, min_height=400, any_or_all='all') self._run_image_shape_filter(dataset, tgt_list, op) diff --git a/tests/ops/filter/test_image_size_filter.py b/tests/ops/filter/test_image_size_filter.py index 46cfff62f..fcc5e3e76 100644 --- a/tests/ops/filter/test_image_size_filter.py +++ b/tests/ops/filter/test_image_size_filter.py @@ -5,19 +5,18 @@ from data_juicer.ops.filter.image_size_filter import ImageSizeFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ImageSizeFilterTest(unittest.TestCase): +class ImageSizeFilterTest(DataJuicerTestCaseBase): - data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), - '..', 'data') + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') img1_path = os.path.join(data_path, 'img1.png') img2_path = os.path.join(data_path, 'img2.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_image_size_filter(self, - dataset: Dataset, target_list, - op): + def _run_image_size_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -29,54 +28,56 @@ def _run_image_size_filter(self, def test_min_max(self): - ds_list = [{ - 'images': [self.img1_path] # 171KB - }, { - 'images': [self.img2_path] # 189KB - }, { - 'images': [self.img3_path] # 114KB - }] - tgt_list = [{ - 'images': [self.img1_path] - }] + ds_list = [ + { + 'images': [self.img1_path] # 171KB + }, + { + 'images': [self.img2_path] # 189KB + }, + { + 'images': [self.img3_path] # 114KB + } + ] + tgt_list = [{'images': [self.img1_path]}] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kb", max_size="180KB") + op = ImageSizeFilter(min_size='120kb', max_size='180KB') self._run_image_size_filter(dataset, tgt_list, op) def test_min(self): - ds_list = [{ - 'images': [self.img1_path] # 171KB - }, { - 'images': [self.img2_path] # 189KB - }, { - 'images': [self.img3_path] # 114KB - }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img2_path] - }] + ds_list = [ + { + 'images': [self.img1_path] # 171KB + }, + { + 'images': [self.img2_path] # 189KB + }, + { + 'images': [self.img3_path] # 114KB + } + ] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img2_path]}] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kib") + op = ImageSizeFilter(min_size='120kib') self._run_image_size_filter(dataset, tgt_list, op) def test_max(self): - ds_list = [{ - 'images': [self.img1_path] # 171KB - }, { - 'images': [self.img2_path] # 189KB - }, { - 'images': [self.img3_path] # 114KB - }] - tgt_list = [{ - 'images': [self.img1_path] - }, { - 'images': [self.img3_path] - }] + ds_list = [ + { + 'images': [self.img1_path] # 171KB + }, + { + 'images': [self.img2_path] # 189KB + }, + { + 'images': [self.img3_path] # 114KB + } + ] + tgt_list = [{'images': [self.img1_path]}, {'images': [self.img3_path]}] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(max_size="180KiB") + op = ImageSizeFilter(max_size='180KiB') self._run_image_size_filter(dataset, tgt_list, op) def test_any(self): @@ -94,8 +95,9 @@ def test_any(self): 'images': [self.img1_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kb", max_size="180KB", - any_or_all='any') + op = ImageSizeFilter(min_size='120kb', + max_size='180KB', + any_or_all='any') self._run_image_size_filter(dataset, tgt_list, op) def test_all(self): @@ -109,7 +111,9 @@ def test_all(self): }] tgt_list = [] dataset = Dataset.from_list(ds_list) - op = ImageSizeFilter(min_size="120kb", max_size="180KB", any_or_all='all') + op = ImageSizeFilter(min_size='120kb', + max_size='180KB', + any_or_all='all') self._run_image_size_filter(dataset, tgt_list, op) diff --git a/tests/ops/filter/test_image_text_matching_filter.py b/tests/ops/filter/test_image_text_matching_filter.py index 15adfb5d4..7620b84a8 100644 --- a/tests/ops/filter/test_image_text_matching_filter.py +++ b/tests/ops/filter/test_image_text_matching_filter.py @@ -1,13 +1,17 @@ +# flake8: noqa: E501 + import os import unittest from datasets import Dataset -from data_juicer.ops.filter.image_text_matching_filter import ImageTextMatchingFilter +from data_juicer.ops.filter.image_text_matching_filter import \ + ImageTextMatchingFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + class ImageTextMatchingFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', @@ -20,7 +24,7 @@ class ImageTextMatchingFilterTest(DataJuicerTestCaseBase): @classmethod def tearDownClass(cls) -> None: super().tearDownClass(cls.hf_blip) - + def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): if Fields.stats not in dataset.features: @@ -30,7 +34,9 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) - dataset = dataset.map(op.compute_stats, num_proc=num_proc, with_rank=True) + dataset = dataset.map(op.compute_stats, + num_proc=num_proc, + with_rank=True) dataset = dataset.filter(op.process, num_proc=num_proc) dataset = dataset.select_columns(column_names=['text', 'images']) res_list = dataset.to_list() @@ -39,23 +45,26 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): def test_no_eoc_special_token(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_eoc_special_token(self): @@ -65,7 +74,8 @@ def test_eoc_special_token(self): f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.eoc}', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ @@ -76,10 +86,10 @@ def test_eoc_special_token(self): dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_horizontal_flip(self): @@ -89,7 +99,8 @@ def test_horizontal_flip(self): f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.eoc}', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ @@ -100,12 +111,12 @@ def test_horizontal_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=True, - vertical_flip=False, - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=True, + vertical_flip=False, + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_vertical_flip(self): @@ -115,7 +126,8 @@ def test_vertical_flip(self): f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.eoc}', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ @@ -126,12 +138,12 @@ def test_vertical_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=True, - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=True, + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_keep_any(self): @@ -150,10 +162,10 @@ def test_keep_any(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_keep_all(self): @@ -167,66 +179,71 @@ def test_keep_all(self): tgt_list = [] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='all', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='all', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_reduce_avg(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_reduce_max(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='max', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='max', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op) def test_reduce_min(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog ' + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog ' f'{SpecialTokens.image} {SpecialTokens.eoc}', 'images': [self.demo_path, self.img3_path] }] dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='min', - any_or_all='any', - min_score=0.1, - max_score=0.9) + reduce_mode='min', + any_or_all='any', + min_score=0.1, + max_score=0.9) self._run_filter(dataset, [], op) def test_multi_process(self): @@ -245,10 +262,10 @@ def test_multi_process(self): }] * 10 dataset = Dataset.from_list(ds_list) op = ImageTextMatchingFilter(hf_blip=self.hf_blip, - reduce_mode='avg', - any_or_all='any', - min_score=0.003, - max_score=1.0) + reduce_mode='avg', + any_or_all='any', + min_score=0.003, + max_score=1.0) self._run_filter(dataset, tgt_list, op, num_proc=4) diff --git a/tests/ops/filter/test_image_text_similarity_filter.py b/tests/ops/filter/test_image_text_similarity_filter.py index f50637561..549ee3137 100644 --- a/tests/ops/filter/test_image_text_similarity_filter.py +++ b/tests/ops/filter/test_image_text_similarity_filter.py @@ -3,11 +3,13 @@ from datasets import Dataset -from data_juicer.ops.filter.image_text_similarity_filter import ImageTextSimilarityFilter +from data_juicer.ops.filter.image_text_similarity_filter import \ + ImageTextSimilarityFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + class ImageTextSimilarityFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', @@ -30,7 +32,9 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) - dataset = dataset.map(op.compute_stats, num_proc=num_proc, with_rank=True) + dataset = dataset.map(op.compute_stats, + num_proc=num_proc, + with_rank=True) dataset = dataset.filter(op.process, num_proc=num_proc) dataset = dataset.select_columns(column_names=['text', 'images']) res_list = dataset.to_list() @@ -52,12 +56,12 @@ def test_no_eoc_special_token(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_eoc_special_token(self): @@ -67,7 +71,8 @@ def test_eoc_special_token(self): f'{SpecialTokens.image}a photo of a cat{SpecialTokens.eoc}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image}a photo of a dog{SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image}a photo of a dog{SpecialTokens.eoc}', 'images': [self.cat_path] }] tgt_list = [{ @@ -78,12 +83,12 @@ def test_eoc_special_token(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_horizontal_flip(self): @@ -104,12 +109,12 @@ def test_horizontal_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=True, - vertical_flip=False, - min_score=0.24, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=True, + vertical_flip=False, + min_score=0.24, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_vertical_flip(self): @@ -130,12 +135,12 @@ def test_vertical_flip(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=True, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=True, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_keep_any(self): @@ -154,12 +159,12 @@ def test_keep_any(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_keep_all(self): @@ -173,12 +178,12 @@ def test_keep_all(self): tgt_list = [] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='all', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='all', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_reduce_avg(self): @@ -195,12 +200,12 @@ def test_reduce_avg(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_reduce_max(self): @@ -217,12 +222,12 @@ def test_reduce_max(self): }] dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='max', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='max', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op) def test_reduce_min(self): @@ -240,12 +245,12 @@ def test_reduce_min(self): dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='min', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.1, - max_score=0.9) + reduce_mode='min', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.1, + max_score=0.9) self._run_filter(dataset, tgt_list, op) @@ -268,12 +273,12 @@ def test_multi_process(self): }] * 10 dataset = Dataset.from_list(ds_list) op = ImageTextSimilarityFilter(hf_clip=self.hf_clip, - reduce_mode='avg', - any_or_all='any', - horizontal_flip=False, - vertical_flip=False, - min_score=0.2, - max_score=0.9) + reduce_mode='avg', + any_or_all='any', + horizontal_flip=False, + vertical_flip=False, + min_score=0.2, + max_score=0.9) self._run_filter(dataset, tgt_list, op, num_proc=4) diff --git a/tests/ops/filter/test_language_id_score_filter.py b/tests/ops/filter/test_language_id_score_filter.py index 0b6e50daa..21d71ceb5 100644 --- a/tests/ops/filter/test_language_id_score_filter.py +++ b/tests/ops/filter/test_language_id_score_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.language_id_score_filter import \ LanguageIDScoreFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class LanguageIDScoreFilterTest(unittest.TestCase): +class LanguageIDScoreFilterTest(DataJuicerTestCaseBase): def _run_language_id_score_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_maximum_line_length_filter.py b/tests/ops/filter/test_maximum_line_length_filter.py index 8bcf6aa83..ef8a6d33e 100644 --- a/tests/ops/filter/test_maximum_line_length_filter.py +++ b/tests/ops/filter/test_maximum_line_length_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.maximum_line_length_filter import \ MaximumLineLengthFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class MaximumLineLengthFilterTest(unittest.TestCase): +class MaximumLineLengthFilterTest(DataJuicerTestCaseBase): def _run_maximum_line_length_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_perplexity_filter.py b/tests/ops/filter/test_perplexity_filter.py index 4b45598dd..114bdb307 100644 --- a/tests/ops/filter/test_perplexity_filter.py +++ b/tests/ops/filter/test_perplexity_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.perplexity_filter import PerplexityFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class PerplexityFilterTest(unittest.TestCase): +class PerplexityFilterTest(DataJuicerTestCaseBase): def _run_perplexity_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_phrase_grounding_recall_filter.py b/tests/ops/filter/test_phrase_grounding_recall_filter.py index c5510014d..16d689e7d 100644 --- a/tests/ops/filter/test_phrase_grounding_recall_filter.py +++ b/tests/ops/filter/test_phrase_grounding_recall_filter.py @@ -1,13 +1,17 @@ +# flake8: noqa: E501 + import os import unittest from datasets import Dataset -from data_juicer.ops.filter.phrase_grounding_recall_filter import PhraseGroundingRecallFilter +from data_juicer.ops.filter.phrase_grounding_recall_filter import \ + PhraseGroundingRecallFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + class PhraseGroundingRecallFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', @@ -24,7 +28,7 @@ class PhraseGroundingRecallFilterTest(DataJuicerTestCaseBase): @classmethod def tearDownClass(cls) -> None: super().tearDownClass(cls.hf_owlvit) - + def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): if Fields.stats not in dataset.features: @@ -34,7 +38,9 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) - dataset = dataset.map(op.compute_stats, num_proc=num_proc, with_rank=True) + dataset = dataset.map(op.compute_stats, + num_proc=num_proc, + with_rank=True) dataset = dataset.filter(op.process, num_proc=num_proc) dataset = dataset.select_columns(column_names=['text', 'images']) res_list = dataset.to_list() @@ -43,35 +49,45 @@ def _run_filter(self, dataset: Dataset, target_list, op, num_proc=1): def test_general(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] @@ -88,29 +104,37 @@ def test_general(self): def test_high_recall(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] @@ -127,14 +151,17 @@ def test_high_recall(self): def test_high_conf_thr(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }] @@ -152,17 +179,21 @@ def test_high_conf_thr(self): def test_low_conf_thr(self): # some similar but different objects might be detected incorrectly ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'{SpecialTokens.image}a man sitting on the grass with a cat', + 'text': + f'{SpecialTokens.image}a man sitting on the grass with a cat', 'images': [self.demo_path] }] @@ -183,7 +214,8 @@ def test_low_area_ratio(self): 'text': f'{SpecialTokens.image} a photo of a woman\'s face', 'images': [self.face_path] }, { - 'text': f'{SpecialTokens.image}A bus with red advertisements is running on the street.', + 'text': + f'{SpecialTokens.image}A bus with red advertisements is running on the street.', 'images': [self.img2_path] }] tgt_list = [] @@ -205,11 +237,13 @@ def test_high_area_ratio(self): 'text': f'{SpecialTokens.image} a photo of a woman\'s face', 'images': [self.face_path] }, { - 'text': f'{SpecialTokens.image}A bus with red advertisements is running on the street.', + 'text': + f'{SpecialTokens.image}A bus with red advertisements is running on the street.', 'images': [self.img2_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}A bus with red advertisements is running on the street.', + 'text': + f'{SpecialTokens.image}A bus with red advertisements is running on the street.', 'images': [self.img2_path] }] @@ -227,17 +261,21 @@ def test_high_area_ratio(self): def test_reduce_avg(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] @@ -254,14 +292,17 @@ def test_reduce_avg(self): def test_reduce_max(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }] @@ -278,10 +319,12 @@ def test_reduce_max(self): def test_reduce_min(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog{SpecialTokens.image}', 'images': [self.demo_path, self.cat_path] }, { - 'text': f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path, self.img2_path] }] tgt_list = [] @@ -300,8 +343,8 @@ def test_keep_all(self): ds_list = [{ 'text': - f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' - f'{SpecialTokens.image} a woman sitting on the beach with a dog', + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' + f'{SpecialTokens.image} a woman sitting on the beach with a dog', 'images': [self.img1_path, self.cat_path, self.demo_path] }] tgt_list = [] @@ -320,14 +363,14 @@ def test_keep_any(self): ds_list = [{ 'text': - f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' - f'{SpecialTokens.image} a woman sitting on the beach with a dog', + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' + f'{SpecialTokens.image} a woman sitting on the beach with a dog', 'images': [self.img1_path, self.cat_path, self.demo_path] }] tgt_list = [{ 'text': - f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' - f'{SpecialTokens.image} a woman sitting on the beach with a dog', + f'{SpecialTokens.image} {SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}' + f'{SpecialTokens.image} a woman sitting on the beach with a dog', 'images': [self.img1_path, self.cat_path, self.demo_path] }] @@ -344,29 +387,37 @@ def test_keep_any(self): def test_process_in_parallel(self): ds_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} select luxury furniture 3 - inch gel memory foam mattress topper {SpecialTokens.eoc}', 'images': [self.img1_path] }, { - 'text': f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A bus with red advertisements is running on the street. {SpecialTokens.eoc}', 'images': [self.img2_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] tgt_list = [{ - 'text': f'{SpecialTokens.image}a woman sitting on the beach with a dog', + 'text': + f'{SpecialTokens.image}a woman sitting on the beach with a dog', 'images': [self.demo_path] }, { - 'text': f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', + 'text': + f'Two cats are sleeping on the couch with two remote controls{SpecialTokens.image}', 'images': [self.cat_path] }, { - 'text': f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', + 'text': + f'{SpecialTokens.image} A woman carrying a bag is walking in a rainy alley holding an umbrella {SpecialTokens.eoc}', 'images': [self.img3_path] }] diff --git a/tests/ops/filter/test_special_characters_filter.py b/tests/ops/filter/test_special_characters_filter.py index 301291bc4..4ea505968 100644 --- a/tests/ops/filter/test_special_characters_filter.py +++ b/tests/ops/filter/test_special_characters_filter.py @@ -5,9 +5,10 @@ from data_juicer.ops.filter.special_characters_filter import \ SpecialCharactersFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SpecialCharactersFilterTest(unittest.TestCase): +class SpecialCharactersFilterTest(DataJuicerTestCaseBase): def _run_special_characters_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_specified_field_filter.py b/tests/ops/filter/test_specified_field_filter.py index a3bd51020..3086e2b00 100644 --- a/tests/ops/filter/test_specified_field_filter.py +++ b/tests/ops/filter/test_specified_field_filter.py @@ -3,9 +3,10 @@ from datasets import Dataset from data_juicer.ops.filter.specified_field_filter import SpecifiedFieldFilter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SpecifiedFieldFilterTest(unittest.TestCase): +class SpecifiedFieldFilterTest(DataJuicerTestCaseBase): def _run_specified_field_filter(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_stats) diff --git a/tests/ops/filter/test_specified_numeric_field_filter.py b/tests/ops/filter/test_specified_numeric_field_filter.py index f82fd4617..c580f6905 100644 --- a/tests/ops/filter/test_specified_numeric_field_filter.py +++ b/tests/ops/filter/test_specified_numeric_field_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.specified_numeric_field_filter import \ SpecifiedNumericFieldFilter +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SpecifiedNumericFieldFilterTest(unittest.TestCase): +class SpecifiedNumericFieldFilterTest(DataJuicerTestCaseBase): def _run_specified_numeric_field_filter(self, dataset: Dataset, target_list, op): diff --git a/tests/ops/filter/test_stop_words_filter.py b/tests/ops/filter/test_stop_words_filter.py index 60219c1c5..8772b6960 100644 --- a/tests/ops/filter/test_stop_words_filter.py +++ b/tests/ops/filter/test_stop_words_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.stopwords_filter import StopWordsFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class StopWordsFilterTest(unittest.TestCase): +class StopWordsFilterTest(DataJuicerTestCaseBase): def _run_stopwords_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_suffix_filter.py b/tests/ops/filter/test_suffix_filter.py index ea2407245..48980c120 100644 --- a/tests/ops/filter/test_suffix_filter.py +++ b/tests/ops/filter/test_suffix_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.suffix_filter import SuffixFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class SuffixFilterTest(unittest.TestCase): +class SuffixFilterTest(DataJuicerTestCaseBase): def _run_suffix_filter(self, dataset: Dataset, target_list, op): dataset = dataset.map(op.compute_stats) diff --git a/tests/ops/filter/test_text_action_filter.py b/tests/ops/filter/test_text_action_filter.py index 9a146ea33..78b40dfad 100644 --- a/tests/ops/filter/test_text_action_filter.py +++ b/tests/ops/filter/test_text_action_filter.py @@ -1,14 +1,15 @@ -import unittest import os +import unittest from datasets import Dataset from data_juicer.ops.filter.text_action_filter import TextActionFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TextActionFilterTest(unittest.TestCase): +class TextActionFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'data') @@ -16,7 +17,8 @@ class TextActionFilterTest(unittest.TestCase): cat_path = os.path.join(data_path, 'cat.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_text_action_filter(self, dataset: Dataset, target_list, op, column_names): + def _run_text_action_filter(self, dataset: Dataset, target_list, op, + column_names): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -34,7 +36,7 @@ def test_en_text_case(self): 'text': 'Tom plays piano.' }, { 'text': 'Tom played piano.' - },{ + }, { 'text': 'I play piano.' }, { 'text': 'to play piano.' @@ -53,7 +55,7 @@ def test_en_text_case(self): 'text': 'Tom plays piano.' }, { 'text': 'Tom played piano.' - },{ + }, { 'text': 'I play piano.' }, { 'text': 'to play piano.' @@ -75,11 +77,7 @@ def test_zh_text_case(self): }, { 'text': '我有一只猫,它是一只猫' }] - tgt_list = [{ - 'text': '小明在 弹奏钢琴' - }, { - 'text': 'Tom在打篮球' - }] + tgt_list = [{'text': '小明在 弹奏钢琴'}, {'text': 'Tom在打篮球'}] dataset = Dataset.from_list(ds_list) op = TextActionFilter(lang='zh') self._run_text_action_filter(dataset, tgt_list, op, ['text']) @@ -95,14 +93,14 @@ def test_image_text_case(self): 'text': f'{SpecialTokens.image}背影{SpecialTokens.eoc}', 'images': [self.img3_path] }, { - 'text': f'雨中行走的女人背影', + 'text': '雨中行走的女人背影', 'images': [self.img3_path] }] tgt_list = [{ 'text': f'{SpecialTokens.image}小猫咪正在睡觉。{SpecialTokens.eoc}', 'images': [self.cat_path] }, { - 'text': f'雨中行走的女人背影', + 'text': '雨中行走的女人背影', 'images': [self.img3_path] }] @@ -110,5 +108,6 @@ def test_image_text_case(self): op = TextActionFilter(lang='zh') self._run_text_action_filter(dataset, tgt_list, op, ['text', 'images']) + if __name__ == '__main__': unittest.main() diff --git a/tests/ops/filter/test_text_entity_dependency_filter.py b/tests/ops/filter/test_text_entity_dependency_filter.py index a9daef1c1..6247318f7 100644 --- a/tests/ops/filter/test_text_entity_dependency_filter.py +++ b/tests/ops/filter/test_text_entity_dependency_filter.py @@ -1,14 +1,16 @@ -import unittest import os +import unittest from datasets import Dataset -from data_juicer.ops.filter.text_entity_dependency_filter import TextEntityDependencyFilter +from data_juicer.ops.filter.text_entity_dependency_filter import \ + TextEntityDependencyFilter from data_juicer.utils.constant import Fields from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TextEntityDependencyFilterTest(unittest.TestCase): +class TextEntityDependencyFilterTest(DataJuicerTestCaseBase): data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'data') @@ -16,7 +18,8 @@ class TextEntityDependencyFilterTest(unittest.TestCase): cat_path = os.path.join(data_path, 'cat.jpg') img3_path = os.path.join(data_path, 'img3.jpg') - def _run_text_entity_denpendency_filter(self, dataset: Dataset, target_list, op, column_names): + def _run_text_entity_denpendency_filter(self, dataset: Dataset, + target_list, op, column_names): if Fields.stats not in dataset.features: dataset = dataset.add_column(name=Fields.stats, column=[{}] * dataset.num_rows) @@ -34,7 +37,7 @@ def test_en_text_case(self): 'text': 'Tom is playing piano.' }, { 'text': 'piano.' - },{ + }, { 'text': 'a green tree', }, { 'text': 'tree', @@ -50,7 +53,8 @@ def test_en_text_case(self): }] dataset = Dataset.from_list(ds_list) op = TextEntityDependencyFilter(lang='en', any_or_all='any') - self._run_text_entity_denpendency_filter(dataset, tgt_list, op, ['text']) + self._run_text_entity_denpendency_filter(dataset, tgt_list, op, + ['text']) def test_zh_text_case(self): @@ -67,16 +71,11 @@ def test_zh_text_case(self): }, { 'text': '书。山。星星。土豆。' }] - tgt_list = [{ - 'text': '她在笑' - }, { - 'text': '枯藤老树昏鸦' - }, { - 'text': '一只会上树的猫' - }] + tgt_list = [{'text': '她在笑'}, {'text': '枯藤老树昏鸦'}, {'text': '一只会上树的猫'}] dataset = Dataset.from_list(ds_list) op = TextEntityDependencyFilter(lang='zh', any_or_all='all') - self._run_text_entity_denpendency_filter(dataset, tgt_list, op, ['text']) + self._run_text_entity_denpendency_filter(dataset, tgt_list, op, + ['text']) def test_image_text_case(self): ds_list = [{ @@ -89,20 +88,22 @@ def test_image_text_case(self): 'text': f'{SpecialTokens.image}背影{SpecialTokens.eoc}', 'images': [self.img3_path] }, { - 'text': f'撑着伞的女人背影', + 'text': '撑着伞的女人背影', 'images': [self.img3_path] }] tgt_list = [{ 'text': f'{SpecialTokens.image}三只缩成一团的小猫咪。{SpecialTokens.eoc}', 'images': [self.cat_path] }, { - 'text': f'撑着伞的女人背影', + 'text': '撑着伞的女人背影', 'images': [self.img3_path] }] dataset = Dataset.from_list(ds_list) op = TextEntityDependencyFilter(lang='zh', any_or_all='any') - self._run_text_entity_denpendency_filter(dataset, tgt_list, op, ['text', 'images']) + self._run_text_entity_denpendency_filter(dataset, tgt_list, op, + ['text', 'images']) + if __name__ == '__main__': unittest.main() diff --git a/tests/ops/filter/test_text_length_filter.py b/tests/ops/filter/test_text_length_filter.py index 1ff93e422..cb5df982b 100644 --- a/tests/ops/filter/test_text_length_filter.py +++ b/tests/ops/filter/test_text_length_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.text_length_filter import TextLengthFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class TextLengthFilterTest(unittest.TestCase): +class TextLengthFilterTest(DataJuicerTestCaseBase): def _run_text_length_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_token_num_filter.py b/tests/ops/filter/test_token_num_filter.py index a830e91fe..514ce21c3 100644 --- a/tests/ops/filter/test_token_num_filter.py +++ b/tests/ops/filter/test_token_num_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.token_num_filter import TokenNumFilter from data_juicer.utils.constant import Fields, StatsKeys +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class WordNumFilterTest(unittest.TestCase): +class WordNumFilterTest(DataJuicerTestCaseBase): def test_token_num(self): src = [ diff --git a/tests/ops/filter/test_video_aesthetics_filter.py b/tests/ops/filter/test_video_aesthetics_filter.py new file mode 100644 index 000000000..afa6a3f0e --- /dev/null +++ b/tests/ops/filter/test_video_aesthetics_filter.py @@ -0,0 +1,244 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_aesthetics_filter import \ + VideoAestheticsFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoAestheticsFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + # vid-low: keyframes -- 0.410, uniform-3 -- 0.410, uniform-5 -- 0.406 + # vid-mid: keyframes -- 0.448, uniform-3 -- 0.419, uniform-5 -- 0.449 + # vid-high: keyframes -- 0.468, uniform-3 -- 0.474, uniform-5 -- 0.480 + vid_low_path = os.path.join(data_path, 'video4.mp4') + vid_mid_path = os.path.join(data_path, 'video1.mp4') + vid_high_path = os.path.join(data_path, 'video3.mp4') + vid_low_text = ( + f'{SpecialTokens.video} [[q]]: Can you summarize what the girls ' + f'are doing in the video?\n", "[[a]]: Sure. The video shows a girl' + f' brushing the hair of another girl who keeps moving her face ' + f'around while the first girl keeps brushing the hair.' + f'{SpecialTokens.eoc}') + vid_mid_text = (f'{SpecialTokens.video} 白色的小羊站在一旁讲话。' + f'旁边还有两只灰色猫咪和一只拉着灰狼的猫咪' + f'{SpecialTokens.eoc}') + vid_high_text = (f'两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}') + + hf_aesthetics_scorer = \ + 'shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE' + + @classmethod + def tearDownClass(cls) -> None: + super().tearDownClass(cls.hf_aesthetics_scorer) + + def _run_video_aesthetics_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_low_path] + }, { + 'videos': [self.vid_mid_path] + }, { + 'videos': [self.vid_high_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_large_score_videos(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_low_path] + }, { + 'videos': [self.vid_mid_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, max_score=0.45) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_small_score_videos(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_mid_path] + }, { + 'videos': [self.vid_high_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, min_score=0.415) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range_keyframes(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{'videos': [self.vid_mid_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.47) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_keyframes(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [ + { + 'videos': [self.vid_mid_path] + }, + ] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.411, + max_score=0.45, + frame_sampling_method='keyframe') + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_uniform_frames_with_different_frame_num(self): + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{'videos': [self.vid_mid_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.41, + max_score=0.48, + frame_sampling_method='uniform', + frame_num=5) + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_any(self): + ds_list = [{ + 'videos': [self.vid_low_path, self.vid_mid_path], + 'text': self.vid_low_text + self.vid_mid_text, + }, { + 'videos': [self.vid_mid_path, self.vid_high_path], + 'text': self.vid_mid_text + self.vid_high_text, + }, { + 'videos': [self.vid_low_path, self.vid_high_path], + 'text': self.vid_low_text + self.vid_high_text, + }] + tgt_list = [{ + 'videos': [self.vid_low_path, self.vid_mid_path] + }, { + 'videos': [self.vid_mid_path, self.vid_high_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.45, + any_or_all='any') + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_all(self): + ds_list = [{ + 'videos': [self.vid_low_path, self.vid_mid_path], + 'text': self.vid_low_text + self.vid_mid_text, + }, { + 'videos': [self.vid_mid_path, self.vid_high_path], + 'text': self.vid_mid_text + self.vid_high_text, + }, { + 'videos': [self.vid_low_path, self.vid_high_path], + 'text': self.vid_low_text + self.vid_high_text, + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter(self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.45, + any_or_all='all') + self._run_video_aesthetics_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid_low_path], + 'text': self.vid_low_text, + }, { + 'videos': [self.vid_mid_path], + 'text': self.vid_mid_text, + }, { + 'videos': [self.vid_high_path], + 'text': self.vid_high_text, + }] + tgt_list = [{'videos': [self.vid_mid_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoAestheticsFilter( + self.hf_aesthetics_scorer, + min_score=0.415, + max_score=0.45, + ) + self._run_video_aesthetics_filter(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_aspect_ratio_filter.py b/tests/ops/filter/test_video_aspect_ratio_filter.py new file mode 100644 index 000000000..b07844097 --- /dev/null +++ b/tests/ops/filter/test_video_aspect_ratio_filter.py @@ -0,0 +1,106 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_aspect_ratio_filter import \ + VideoAspectRatioFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoAspectRatioFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # 640x360, 16:9 + vid2_path = os.path.join(data_path, 'video2.mp4') # 480x640, 3:4 + vid3_path = os.path.join(data_path, 'video3.mp4') # 362x640, 181:320 + + def _run_op(self, dataset: Dataset, target_list, op, np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_params(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter() + self._run_op(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter(min_ratio='3/4', + max_ratio='16/9', + any_or_all='any') + self._run_op(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path, self.vid2_path]}] + + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter(min_ratio='3/4', + max_ratio='16/9', + any_or_all='all') + self._run_op(dataset, tgt_list, op) + + def test_parallel(self): + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}, {'videos': [self.vid2_path]}] + + dataset = Dataset.from_list(ds_list) + op = VideoAspectRatioFilter(min_ratio='3/4', max_ratio='16/9') + self._run_op(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_duration_filter.py b/tests/ops/filter/test_video_duration_filter.py new file mode 100644 index 000000000..2954836bf --- /dev/null +++ b/tests/ops/filter/test_video_duration_filter.py @@ -0,0 +1,147 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_duration_filter import VideoDurationFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoDurationFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # about 12s + vid2_path = os.path.join(data_path, 'video2.mp4') # about 23s + vid3_path = os.path.join(data_path, 'video3.mp4') # about 50s + + def _run_video_duration_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter() + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_long_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(max_duration=15) + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_short_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=30) + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=16, max_duration=42) + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=15, + max_duration=30, + any_or_all='any') + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=15, + max_duration=30, + any_or_all='all') + self._run_video_duration_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoDurationFilter(min_duration=15, max_duration=30) + self._run_video_duration_filter(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_frames_text_similarity_filter.py b/tests/ops/filter/test_video_frames_text_similarity_filter.py new file mode 100644 index 000000000..04e7355e5 --- /dev/null +++ b/tests/ops/filter/test_video_frames_text_similarity_filter.py @@ -0,0 +1,274 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_frames_text_similarity_filter import \ + VideoFramesTextSimilarityFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.mm_utils import SpecialTokens +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoFramesTextSimilarityFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + # vid1: keyframes -- 0.2515, uniform-2 -- 0.2378, uniform-3 -- 0.2342 + # vid2: keyframes -- 0.2686, uniform-2 -- 0.2741, uniform-3 -- 0.2697 + # vid3: keyframes -- 0.3020, uniform-2 -- 0.3044, uniform-3 -- 0.2998 + vid1_path = os.path.join(data_path, 'video1.mp4') + vid2_path = os.path.join(data_path, 'video2.mp4') + vid3_path = os.path.join(data_path, 'video3.mp4') + + hf_clip = 'openai/clip-vit-base-patch32' + + @classmethod + def tearDownClass(cls) -> None: + super().tearDownClass(cls.hf_clip) + + def _run_video_frames_text_similarity_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_large_score_videos(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid1_path]}, {'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, max_score=0.3) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_small_score_videos(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}, {'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, min_score=0.26) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range_keyframes(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_uniform_frames(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}, {'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform') + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_uniform_frames_with_different_frame_num(self): + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform', + frame_num=2) + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} {SpecialTokens.video} 身穿白色上衣的男子,' + f'拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}', + }, { + 'videos': [self.vid2_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }, { + 'videos': [self.vid1_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform', + frame_num=2, + any_or_all='any') + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_all(self): + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} {SpecialTokens.video} 身穿白色上衣的男子,' + f'拿着一个东西,拍打自己的胃部。{SpecialTokens.eoc}', + }, { + 'videos': [self.vid2_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }, { + 'videos': [self.vid1_path, self.vid3_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。' + f'{SpecialTokens.eoc} 两个长头发的女子正坐在一张圆桌前讲话互动。 ' + f'{SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter(self.hf_clip, + min_score=0.26, + max_score=0.3, + frame_sampling_method='uniform', + frame_num=2, + any_or_all='all') + self._run_video_frames_text_similarity_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid1_path], + 'text': + f'{SpecialTokens.video} 白色的小羊站在一旁讲话。旁边还有两只灰色猫咪和一只拉着灰狼的猫咪。', + }, { + 'videos': [self.vid2_path], + 'text': + f'{SpecialTokens.video} 身穿白色上衣的男子,拿着一个东西,拍打自己的胃部。' + f'{SpecialTokens.eoc}', + }, { + 'videos': [self.vid3_path], + 'text': + f'两个长头发的女子正坐在一张圆桌前讲话互动。 {SpecialTokens.video} {SpecialTokens.eoc}', + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoFramesTextSimilarityFilter( + self.hf_clip, + min_score=0.26, + max_score=0.3, + ) + self._run_video_frames_text_similarity_filter(dataset, + tgt_list, + op, + np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_motion_score_filter.py b/tests/ops/filter/test_video_motion_score_filter.py new file mode 100644 index 000000000..0c7ce3f5d --- /dev/null +++ b/tests/ops/filter/test_video_motion_score_filter.py @@ -0,0 +1,140 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_motion_score_filter import \ + VideoMotionScoreFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoMotionScoreFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # 1.8210126 + vid2_path = os.path.join(data_path, 'video2.mp4') # 3.600746 + vid3_path = os.path.join(data_path, 'video3.mp4') # 1.1822891 + + def _run_helper(self, op, source_list, target_list, np=1): + dataset = Dataset.from_list(source_list) + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + op = VideoMotionScoreFilter() + self._run_helper(op, ds_list, tgt_list) + + def test_high(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + op = VideoMotionScoreFilter(min_score=3.0) + self._run_helper(op, ds_list, tgt_list) + + def test_low(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + op = VideoMotionScoreFilter(min_score=0.0, max_score=1.50) + self._run_helper(op, ds_list, tgt_list) + + def test_middle(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + op = VideoMotionScoreFilter(min_score=1.5, max_score=3.0) + self._run_helper(op, ds_list, tgt_list) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + op = VideoMotionScoreFilter(min_score=1.5, + max_score=3.0, + any_or_all='any') + self._run_helper(op, ds_list, tgt_list) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + op = VideoMotionScoreFilter(min_score=1.5, + max_score=3.0, + any_or_all='all') + self._run_helper(op, ds_list, tgt_list) + + def test_parallel(self): + import multiprocess as mp + mp.set_start_method('forkserver', force=True) + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + op = VideoMotionScoreFilter(min_score=1.5, max_score=3.0) + self._run_helper(op, ds_list, tgt_list, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_ocr_area_ratio_filter.py b/tests/ops/filter/test_video_ocr_area_ratio_filter.py new file mode 100644 index 000000000..420094d2b --- /dev/null +++ b/tests/ops/filter/test_video_ocr_area_ratio_filter.py @@ -0,0 +1,157 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_ocr_area_ratio_filter import \ + VideoOcrAreaRatioFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoOcrAreaRatioFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + vid1_path = os.path.join(data_path, 'video1.mp4') # about 0.067 + vid2_path = os.path.join(data_path, 'video2.mp4') # about 0.288 + vid3_path = os.path.join(data_path, 'video3.mp4') # about 0.075 + + def _run_video_ocr_area_ratio_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter() + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_large_ratio_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}, {'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(max_area_ratio=0.1) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_small_ratio_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.2) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, max_area_ratio=0.1) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, + max_area_ratio=0.1, + any_or_all='any') + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, + max_area_ratio=0.1, + any_or_all='all') + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + # WARNING: current parallel tests only work in spawn method + import multiprocess + original_method = multiprocess.get_start_method() + multiprocess.set_start_method('spawn', force=True) + # WARNING: current parallel tests only work in spawn method + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid3_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoOcrAreaRatioFilter(min_area_ratio=0.07, max_area_ratio=0.1) + self._run_video_ocr_area_ratio_filter(dataset, tgt_list, op, np=2) + + # WARNING: current parallel tests only work in spawn method + multiprocess.set_start_method(original_method, force=True) + # WARNING: current parallel tests only work in spawn method + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_video_resolution_filter.py b/tests/ops/filter/test_video_resolution_filter.py new file mode 100644 index 000000000..210662a3e --- /dev/null +++ b/tests/ops/filter/test_video_resolution_filter.py @@ -0,0 +1,151 @@ +import os +import unittest + +from datasets import Dataset + +from data_juicer.ops.filter.video_resolution_filter import \ + VideoResolutionFilter +from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class VideoResolutionFilterTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + # video1: horizontal resolution 640p, vertical resolution 360p + # video2: horizontal resolution 480p, vertical resolution 640p + # video3: horizontal resolution 362p, vertical resolution 640p + vid1_path = os.path.join(data_path, 'video1.mp4') + vid2_path = os.path.join(data_path, 'video2.mp4') + vid3_path = os.path.join(data_path, 'video3.mp4') + + def _run_video_resolution_filter(self, + dataset: Dataset, + target_list, + op, + np=1): + if Fields.stats not in dataset.features: + dataset = dataset.add_column(name=Fields.stats, + column=[{}] * dataset.num_rows) + dataset = dataset.map(op.compute_stats, num_proc=np) + dataset = dataset.filter(op.process, num_proc=np) + dataset = dataset.select_columns(column_names=[op.video_key]) + res_list = dataset.to_list() + self.assertEqual(res_list, target_list) + + def test_default_filter(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter() + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_low_resolution_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=480, min_height=480) + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_high_resolution_videos(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid1_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(max_width=640, max_height=480) + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_videos_within_range(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, max_width=500) + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_any(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, + max_width=500, + any_or_all='any') + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_all(self): + + ds_list = [{ + 'videos': [self.vid1_path, self.vid2_path] + }, { + 'videos': [self.vid2_path, self.vid3_path] + }, { + 'videos': [self.vid1_path, self.vid3_path] + }] + tgt_list = [] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, + max_width=500, + any_or_all='all') + self._run_video_resolution_filter(dataset, tgt_list, op) + + def test_filter_in_parallel(self): + + ds_list = [{ + 'videos': [self.vid1_path] + }, { + 'videos': [self.vid2_path] + }, { + 'videos': [self.vid3_path] + }] + tgt_list = [{'videos': [self.vid2_path]}] + dataset = Dataset.from_list(ds_list) + op = VideoResolutionFilter(min_width=400, max_width=500) + self._run_video_resolution_filter(dataset, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/filter/test_word_num_filter.py b/tests/ops/filter/test_word_num_filter.py index d4ee8b239..6a4967f97 100644 --- a/tests/ops/filter/test_word_num_filter.py +++ b/tests/ops/filter/test_word_num_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.word_num_filter import WordNumFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class WordNumFilterTest(unittest.TestCase): +class WordNumFilterTest(DataJuicerTestCaseBase): def _run_word_num_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/filter/test_word_repetition_filter.py b/tests/ops/filter/test_word_repetition_filter.py index 53435fd70..cf5f02330 100644 --- a/tests/ops/filter/test_word_repetition_filter.py +++ b/tests/ops/filter/test_word_repetition_filter.py @@ -4,9 +4,10 @@ from data_juicer.ops.filter.word_repetition_filter import WordRepetitionFilter from data_juicer.utils.constant import Fields +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class WordRepetitionFilterTest(unittest.TestCase): +class WordRepetitionFilterTest(DataJuicerTestCaseBase): def _run_word_repetition_filter(self, dataset: Dataset, target_list, op): if Fields.stats not in dataset.features: diff --git a/tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py b/tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py new file mode 100644 index 000000000..4ee4fdd61 --- /dev/null +++ b/tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py @@ -0,0 +1,60 @@ +import os +import unittest + +import librosa +from datasets import Dataset + +from data_juicer.ops.mapper.audio_ffmpeg_wrapped_mapper import \ + AudioFFmpegWrappedMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase + + +class AudioFFmpegWrappedMapperTest(DataJuicerTestCaseBase): + + data_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', + 'data') + aud1_path = os.path.join(data_path, 'audio1.wav') # 5.501678004535147 + aud2_path = os.path.join(data_path, 'audio2.wav') # 14.142426303854876 + aud3_path = os.path.join(data_path, 'audio3.ogg') # 119.87591836734694 + + def _run_op(self, ds_list, target_list, op, np=1): + dataset = Dataset.from_list(ds_list) + dataset = dataset.map(op.process, num_proc=np) + + def get_size(dataset): + durations = [] + res_list = dataset.to_list() + for sample in res_list: + sample_durations = [] + for aud_path in sample['audios']: + sample_durations.append( + librosa.get_duration(path=aud_path)) + durations.append(sample_durations) + return durations + + sizes = get_size(dataset) + self.assertEqual(sizes, target_list) + + def test_resize(self): + ds_list = [{ + 'audios': [self.aud1_path, self.aud2_path, self.aud3_path] + }] + tgt_list = [[5.501678004535147, 6.0, 6.0]] + op = AudioFFmpegWrappedMapper('atrim', + filter_kwargs={'end': 6}, + capture_stderr=False) + self._run_op(ds_list, tgt_list, op) + + def test_resize_parallel(self): + ds_list = [{ + 'audios': [self.aud1_path, self.aud2_path, self.aud3_path] + }] + tgt_list = [[5.501678004535147, 6.0, 6.0]] + op = AudioFFmpegWrappedMapper('atrim', + filter_kwargs={'end': 6}, + capture_stderr=False) + self._run_op(ds_list, tgt_list, op, np=2) + + +if __name__ == '__main__': + unittest.main() diff --git a/tests/ops/mapper/test_chinese_convert_mapper.py b/tests/ops/mapper/test_chinese_convert_mapper.py index fd35bbbb1..9bbe8e8df 100644 --- a/tests/ops/mapper/test_chinese_convert_mapper.py +++ b/tests/ops/mapper/test_chinese_convert_mapper.py @@ -1,9 +1,10 @@ import unittest from data_juicer.ops.mapper.chinese_convert_mapper import ChineseConvertMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class ChineseConvertMapperTest(unittest.TestCase): +class ChineseConvertMapperTest(DataJuicerTestCaseBase): def setUp(self, mode='s2t'): self.op = ChineseConvertMapper(mode) diff --git a/tests/ops/mapper/test_clean_copyright_mapper.py b/tests/ops/mapper/test_clean_copyright_mapper.py index 302942d26..726d829f7 100644 --- a/tests/ops/mapper/test_clean_copyright_mapper.py +++ b/tests/ops/mapper/test_clean_copyright_mapper.py @@ -1,9 +1,10 @@ import unittest from data_juicer.ops.mapper.clean_copyright_mapper import CleanCopyrightMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CleanCopyrightMapperTest(unittest.TestCase): +class CleanCopyrightMapperTest(DataJuicerTestCaseBase): def setUp(self): self.op = CleanCopyrightMapper() diff --git a/tests/ops/mapper/test_clean_email_mapper.py b/tests/ops/mapper/test_clean_email_mapper.py index 9e20aede9..b3f0e5e9a 100644 --- a/tests/ops/mapper/test_clean_email_mapper.py +++ b/tests/ops/mapper/test_clean_email_mapper.py @@ -1,9 +1,10 @@ import unittest from data_juicer.ops.mapper.clean_email_mapper import CleanEmailMapper +from data_juicer.utils.unittest_utils import DataJuicerTestCaseBase -class CleanEmailMapperTest(unittest.TestCase): +class CleanEmailMapperTest(DataJuicerTestCaseBase): def _run_clean_email(self, op, samples): for sample in samples: @@ -45,6 +46,7 @@ def test_replace_email(self): }] op = CleanEmailMapper(repl='