markdown-it 原理解析 #252
Comments
|
自己刚好在写一个简单的markdown渲染小组件,看到这个非常开心 |
This URL https://unicode-table.com/ has changed to https://symbl.cc/ |
|
自己刚好在写一个简单的markdown渲染小组件,看到这个非常开心 |
This URL https://unicode-table.com/ has changed to https://symbl.cc/ |
前言
在 《一篇带你用 VuePress + Github Pages 搭建博客》中,我们使用 VuePress 搭建了一个博客,最终的效果查看:TypeScript 中文文档。
在搭建博客的过程中,我们出于实际的需求,在《VuePress 博客优化之拓展 Markdown 语法》中讲解了如何写一个
markdown-it插件,本篇我们将深入markdown-it的源码,讲解markdown-it的执行原理,旨在让大家对markdown-it有更加深入的理解。介绍
引用 markdown-it Github 仓库的介绍:
可以看出
markdown-it是一个 markdown 解析器,并且易于拓展。其演示地址为:https://markdown-it.github.io/
markdown-it具有以下几个优势:使用
源码解析
我们查看
markdown-it的入口代码,可以发现其代码逻辑清晰明了:从
render方法中也可以看出,其渲染分为两个过程:跟 Babel 很像,不过 Babel 是转换为抽象语法树(AST),而
markdown-it没有选择使用 AST,主要是为了遵循 KISS(Keep It Simple, Stupid) 原则。Tokens
那 Tokens 长什么样呢?我们不妨在演示页面中尝试一下:
可以看出
# header生成的 Token 格式为(注:这里为了展示方便,简化了):[ { "type": "heading_open", "tag": "h1" }, { "type": "inline", "tag": "", "children": [ { "type": "text", "tag": "", "content": "header" } ] }, { "type": "heading_close", "tag": "h1" } ]具体 Token 里的字段含义可以查看 Token Class。
通过这个简单的 Tokens 示例也可以看出 Tokens 和 AST 的区别:
Parse
查看 parse 方法相关的代码:
可以看到其具体执行的代码,应该是写在了
./parse_core里,查看下parse_core.js的代码:可以看出,Parse 过程默认有 6 条规则,其主要作用分别是:
1. normalize
在 CSS 中,我们使用
normalize.css抹平各端差异,这里也是一样的逻辑,我们查看 normalize 的代码,其实很简单:我们知道
\n是匹配一个换行符,\r是匹配一个回车符,那这里为什么要将\r\n替换成\n呢?我们可以在阮一峰老师的这篇 《回车与换行》中找到
\r\n出现的历史:之所以将
\r\n替换成\n其实是遵循规范:其中 U+000A 表示换行(LF) ,U+000D 表示回车(CR) 。
除了替换回车符外,源码里还替换了空字符,在正则中,
\0表示匹配 NULL(U+0000)字符,根据 WIKI 的解释:而我们将空字符替换为
\uFFFD,在 Unicode 中,\uFFFD表示替换字符:之所以进行这个替换,其实也是遵循规范,我们查阅 CommonMark spec 2.3 章节:
我们测试下这个效果:
效果如下,你会发现原本不可见的空字符被替换成替换字符后,展示了出来:
2. block
block 这个规则的作用就是找出 block,生成 tokens,那什么是 block?什么是 inline 呢?我们也可以在CommonMark spec 中的 Blocks and inlines 章节 找到答案:
翻译一下就是:
我们认为文档是由一组 blocks 组成,结构化的元素类似于段落、引用、列表、标题、代码区块等。一些 blocks (像引用和列表)可以包含其他 blocks,其他的一些 blocks(像标题和段落)则可以包含 inline 内容,比如文字、链接、 强调文字、图片、代码片段等等。
当然在
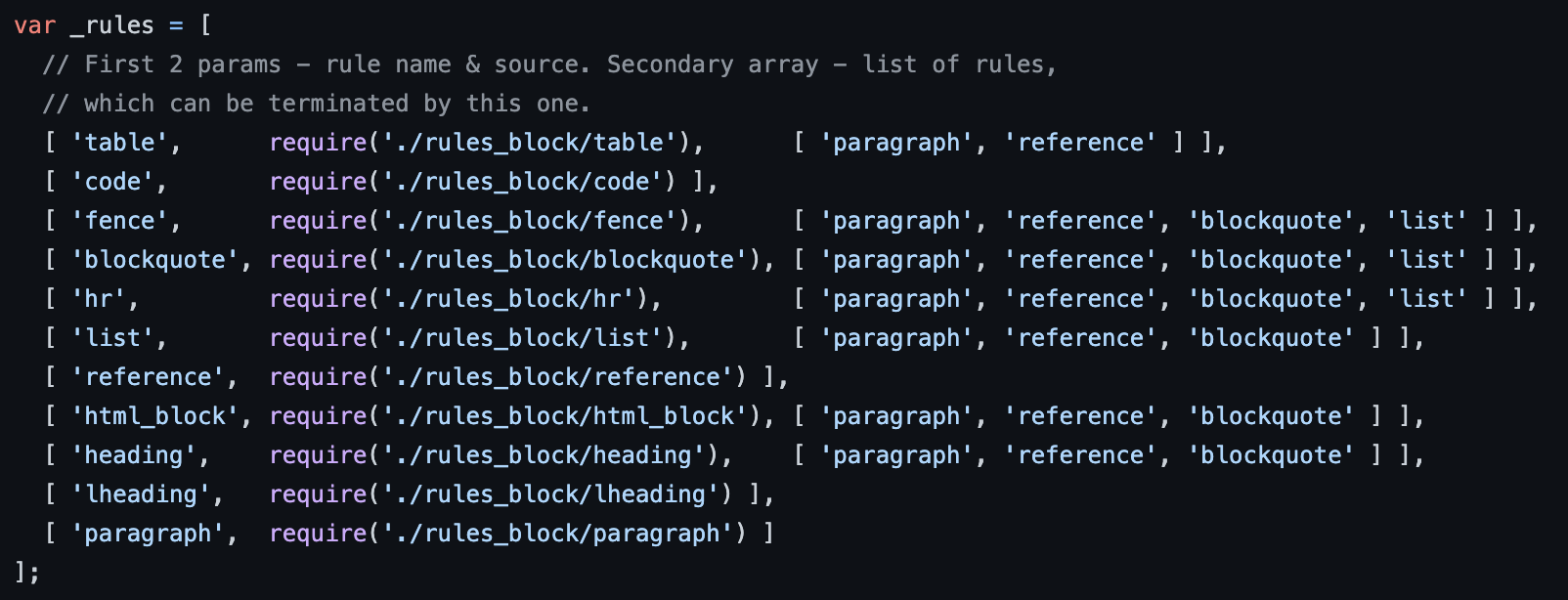
markdown-it中,哪些会识别成 blocks,可以查看 parser_block.js,这里同样定义了一些识别和 parse 的规则:关于这些规则我挑几个不常见的说明一下:
code规则用于识别Indented code blocks(4 spaces padded),在 markdown 中:fence规则用于识别 Fenced code blocks,在markdown 中:hr规则用于识别换行,在 markdown 中:reference规则用于识别reference links,在 markdown 中:html_block用于识别 markdown 中的 HTML block 元素标签,就比如div。lheading用于识别Setext headings,在 markdown 中:3. inline
inline 规则的作用则是解析 markdown 中的 inline,然后生成 tokens,之所以 block 先执行,是因为 block 可以包含 inline ,解析的规则可以查看 parser_inline.js:
关于这些规则我挑几个不常见的说明一下:
newline规则用于识别\n,将\n替换为一个 hardbreak 类型的 tokenbackticks规则用于识别反引号:entity规则用于处理 HTML entity,比如{``¯``"等:4. linkify
自动识别链接
5. replacements
将
(c)`` (C)替换成©,将????????替换成???,将!!!!!替换成!!!,诸如此类:6. smartquotes
为了方便印刷,对直引号做了处理:
Render
Render 过程其实就比较简单了,查看 renderer.js 文件,可以看到内置了一些默认的渲染 rules:
其实这些名字也是 token 的 type,在遍历 token 的时候根据 token 的 type 对应这里的 rules 进行执行,我们看下 code_inline 规则的内容,其实非常简单:
自定义 Rules
至此,我们对 markdown-it 的渲染原理进行了简单的了解,无论是 Parse 还是 Render 过程中的 Rules,markdown-it 都提供了方法可以自定义这些 Rules,这些也是写 markdown-it 插件的关键,这些后续我们会讲到。
系列文章
博客搭建系列是我至今写的唯一一个偏实战的系列教程,讲解如何使用 VuePress 搭建博客,并部署到 GitHub、Gitee、个人服务器等平台。
微信:「mqyqingfeng」,加我进冴羽唯一的读者群。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
The text was updated successfully, but these errors were encountered: