
The goal of this project is to assess whether a language implementation is highly optimizing and thus is able to remove the overhead of programming abstractions and frameworks. We are interested in comparing language implementations with each other and optimize their compilers as well as the run-time representation of objects, closures, and arrays.
This is in contrast to other projects such as the Computer Language Benchmark game, which encourage finding the smartest possible way to express a problem in a language to achieve best performance.
To allow us to compare the degree of optimization done by the implementations as well as the absolute performance achieved, we set the following basic rules:
-
The benchmark is 'identical' for all languages.
This is achieved by relying only on a widely available and commonly used subset of language features and data types. -
The benchmarks should use language 'idiomatically'.
This means, they should be realized as much as possible with idiomatic code in each language, while relying only on the core set of abstractions.
For the detailed set of rules see the guidelines document. For a description of the set of common language abstractions see the core language document.
The initial publication describing the project is Cross-Language Compiler Benchmarking: Are We Fast Yet? and can be cited as follows:
Stefan Marr, Benoit Daloze, Hanspeter Mössenböck. 2016. Cross-Language Compiler Benchmarking: Are We Fast Yet? In Proceedings of the 12th Symposium on Dynamic Languages (DLS '16). ACM.
To facilitate research, the goal of this project is specifically to assess the effectiveness of compiler and runtime optimizations for a common set of abstractions between languages. As such, many other relevant aspects such as GC, standard libraries, and language-specific abstractions are not included here. However, by focusing on one aspect, we know exactly what is compared.
Currently, we have 14 benchmarks ported to six different languages, including Crystal, Java, JavaScript, Ruby, SOM Smalltalk, and SOMns (a Newspeak implementation).
The graph below shows the results for the different implementations after warmup, to ensure peak performance is reported:
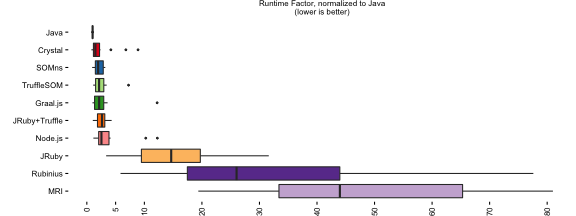
A detailed overview of the results is in docs/performance.md.
For a performance comparison over time, see the timeline view on awfy-speed.stefan-marr.de. The runs are managed at smarr/awfy-runs.
The benchmarks are listed below. A detailed analysis including metrics for the benchmarks is in docs/metrics.md.
-
CD is a simulation of an airplane collision detector. Based on WebKit's JavaScript CDjs. Originally, CD was designed to evaluate real-time JVMs.
-
DeltaBlue is a classic VM benchmark used to tune, e.g., Smalltalk, Java, and JavaScript VMs. It implements a constraint solver.
-
Havlak implements a loop recognition algorithm. It has been used to compare C++, Java, Go, and Scala performance.
-
Json is a JSON string parsing benchmark derived from the
minimal-jsonJava library. -
Richards is a classic benchmark simulating an operating system kernel. The used code is based on Wolczko's Smalltalk version.
Micro benchmarks are based on SOM Smalltalk benchmarks unless noted otherwise.
-
Bounce simulates a ball bouncing within a box.
-
List recursively creates and traverses lists.
-
Mandelbrot calculates the classic fractal. It is derived from the Computer Languages Benchmark Game.
-
NBody simulates the movement of planets in the solar system. It is derived from the Computer Languages Benchmark Game.
-
Permute generates permutations of an array.
-
Queens solves the eight queens problem.
-
Sieve finds prime numbers based on the sieve of Eratosthenes.
-
Storage creates and verifies a tree of arrays to stress the garbage collector.
-
Towers solves the Towers of Hanoi game.
Considering the large number of languages out there, we are open to contributions of benchmark ports to new languages. We would also be interested in new benchmarks that are in the range of 300 to 1000 lines of code.
When porting to a new language, please carefully consider the guidelines and description of the core language to ensure that we can compare results.
A list of languages we would definitely be interested in is on the issues tracker.
This includes languages like Dart, Scala, Python, and Go. Other interesting ports could be for Racket, Clojure, or CLOS, but might require more carefully thought-out rules for porting. Similarly, ports to C++ or Rust need additional care to account for the absence of a garbage collector.
To obtain the code, benchmarks, and documentation, checkout the git repository:
git clone --depth 1 https://github.com/smarr/are-we-fast-yet.gitNote that the repository relies on git submodules, which won't be loaded at that point. They are only needed to run the full range of language implementations and experiments.
The benchmarks are sorted by language in the benchmarks folder.
Each language has its own harness. For JavaScript and Ruby, the benchmarks are
executed like this:
cd benchmarks/JavaScript
node harness.js Richards 5 10
cd ../Ruby
ruby harness.rb Queens 5 20The harness takes three parameters: benchmark name, number of iterations, and problem size. The benchmark name corresponds to a class or file of a benchmark. The number of iterations defines how often a benchmark should be executed. The problem size can be used to influence how long a benchmark takes. Note that some benchmarks rely on magic numbers to verify their results. Those might not be included for all possible problem sizes.
The rebench.conf file specifies the supported problem sizes for each benchmark.
The setup and building of benchmarks and VMs is automated via
implementations/setup.sh. Benchmark are configured and executed with the
ReBench tool.
To execute the benchmarks on all supported VMs, the following implementations are expected to be already available on the benchmark machine:
- Crystal
- Node.js
- Ruby
- GraalVM, expected to be available in
implementations/graalvm. Please see implementations/graalvm/README.md for details.
This repository uses git submodules for some languages implementations. To build these, additional tools are required. These include Ant, Make, Python, and a C/C++ compiler.
The implementations folder contains wrapper scripts such as mri-23.sh,
java8.sh, and node.sh to execute all language implementations in a common
way by ReBench.
ReBench can be installed via the Python package manager pip:
pip install ReBench
The benchmarks can be executed with the following command in the root folder:
rebench -d --without-nice rebench.conf all
The -d gives more output during execution, and --without-nice means that
the nice tool enforcing high process priority is not used. We don't use it
here to avoid requiring root rights.
Note: The rebench.conf file specifies how and which benchmarks to execute. It also defines the arguments to be passed to the benchmarks.
-
GraalSqueak: Toward a Smalltalk-based Tooling Platform for Polyglot Programming
F. Niephaus, T. Felgentreff, R. Hirschfeld. Proceedings of 16th International Conference on Managed Programming Languages & Runtimes, MPLR'19. 2019. -
Self-Contained Development Environments
G. Chari, J. Pimás, J. Vitek, O. Flückiger. Proceedings of the 14th ACM SIGPLAN International Symposium on Dynamic Languages. 2018. -
Interflow: Interprocedural Flow-Sensitive TypeInference and Method Duplication
D. Shabalin, M. Odersky. Proceedings of the 9th ACM SIGPLAN International Symposium on Scala 2018. -
Specializing a Meta-Interpreter: JIT Compilation of DynSem Specifications on the Graal VM
V. Vergu, E. Visser. Proceedings of the 15th International Conference on Managed Languages and Runtimes, ManLang 2018. -
Newspeak and Truffle: A Platform for Grace?
S. Marr, R. Roberts, J. Noble, Grace'18, p. 3, 2018. Presentation. -
Parallelization of Dynamic Languages: Synchronizing Built-in Collections
B. Daloze, A. Tal, S. Marr, H. Mössenböck, E. Petrank Proceedings of the ACM on Programming Languages, OOPSLA'18, p. 27, 2018 -
Efficient and Deterministic Record & Replay for Actor Languages
D. Aumayr, S. Marr, C. Béra, E. Gonzalez Boix, H. Mössenböck Proceedings of the 15th International Conference on Managed Languages and Runtimes, ManLang'18, ACM, 2018. -
Fully Reflective Execution Environments: Virtual Machines for More Flexible Software
G. Chari, D. Garbervetsky, S. Marr, S. Ducasse IEEE Transactions on Software Engineering, IEEE TSE, p. 1–20, 2018. -
Garbage Collection and Efficiency in Dynamic Metacircular Runtimes
J. Pimás, J. Burroni, J., B. Arnaud, S. Marr Proceedings of the 13th ACM SIGPLAN International Symposium on Dynamic Languages, DLS'17, ACM, 2017. -
Applying Optimizations for Dynamically-typed Languages to Java
M. Grimmer, S. Marr, M. Kahlhofer, C. Wimmer, T. Würthinger, H. Mössenböck Proceedings of the 14th International Conference on Managed Languages and Runtimes, ManLang'17, ACM, 2017. -
Efficient and Thread-Safe Objects for Dynamically-Typed Languages
B. Daloze, S. Marr, D. Bonetta, Hanspeter Mössenböck In Proceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA '16). ACM.