-

-
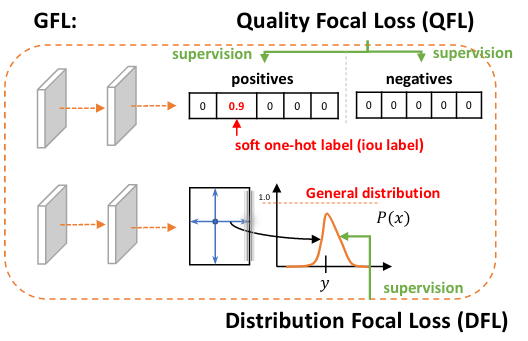
Learning to Predict the IoU-aware Classification Score.
-
 +
+ +
+ +
+ +
+ +
+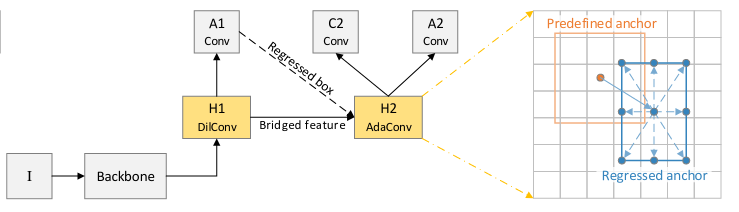 +
+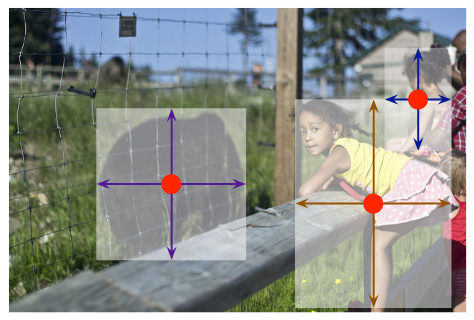 +
+ +
+ +
+ +
+ +
+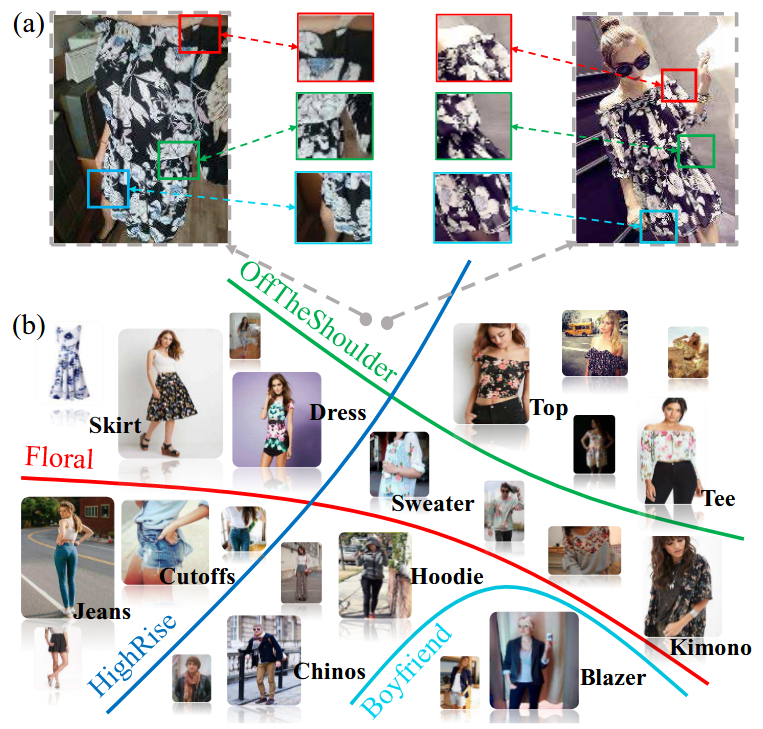 +
+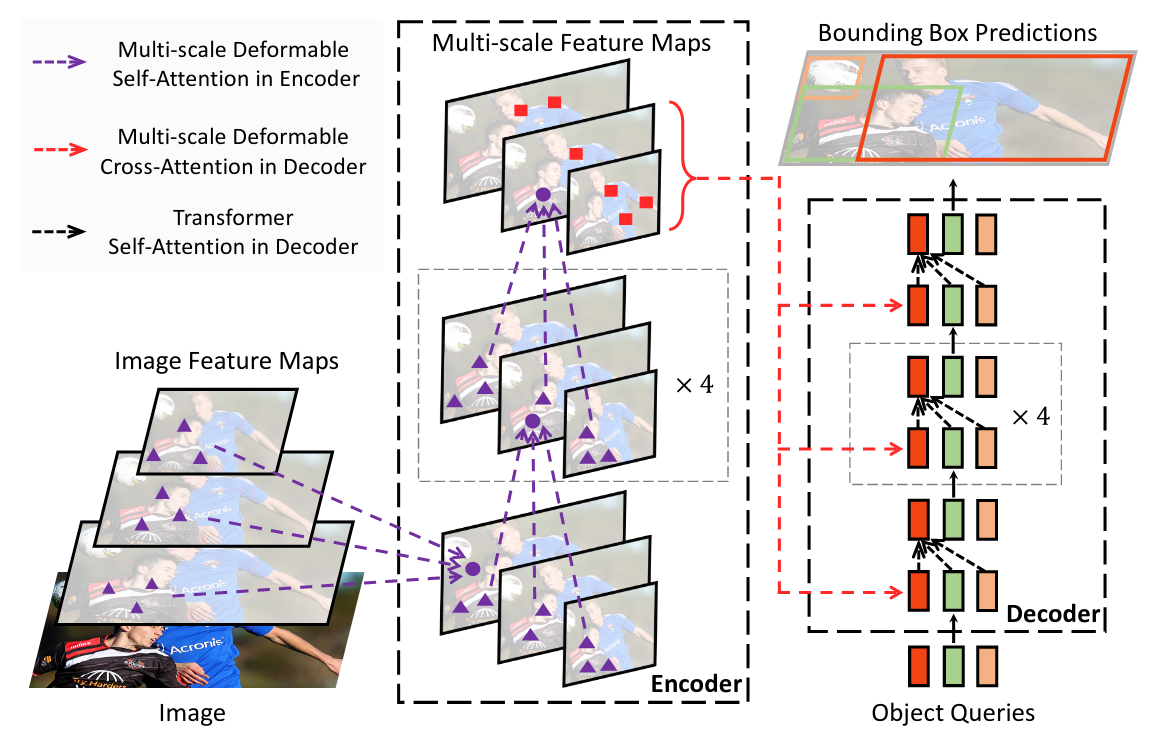 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+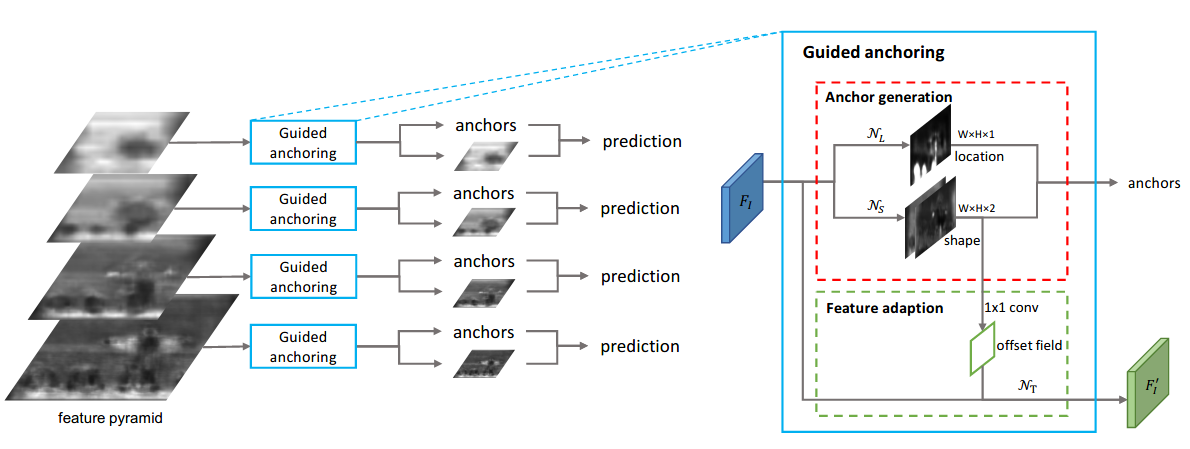 +
+ +
+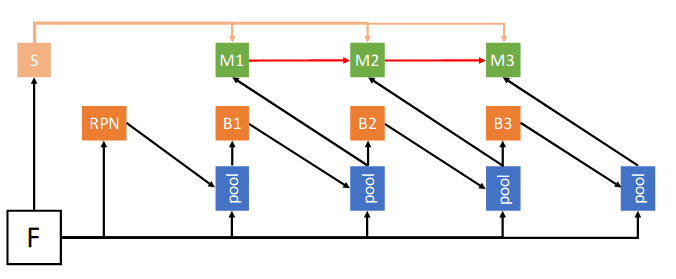 +
+ +
+ +
+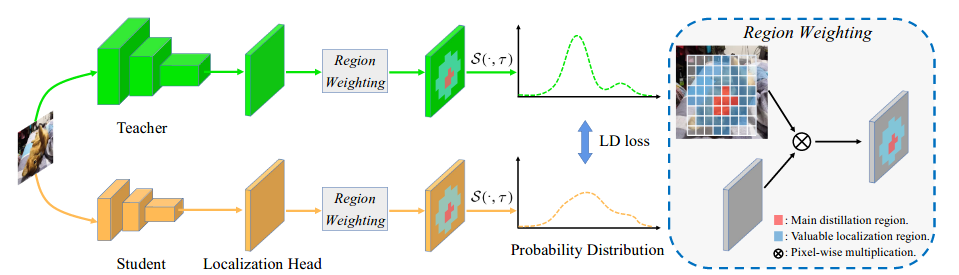 +
+ +
+ +
+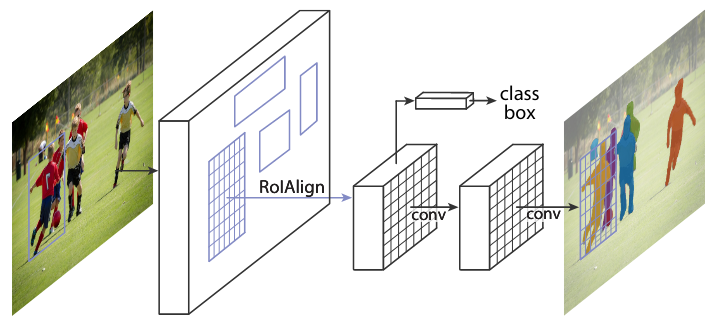 +
+ +
+ +
+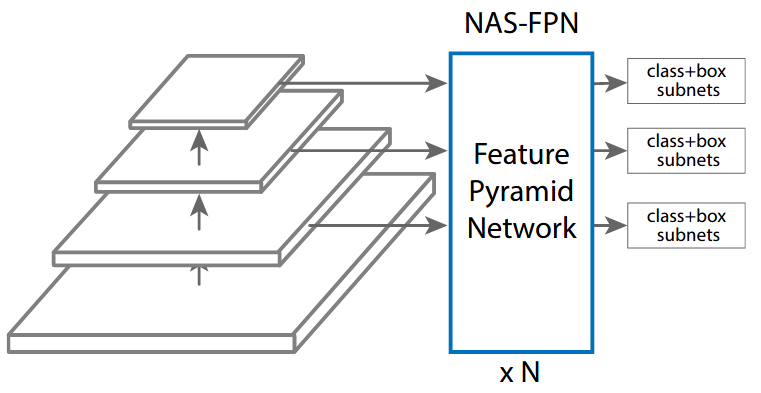 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ -
- 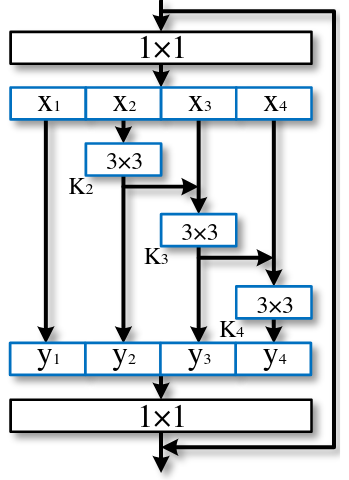 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+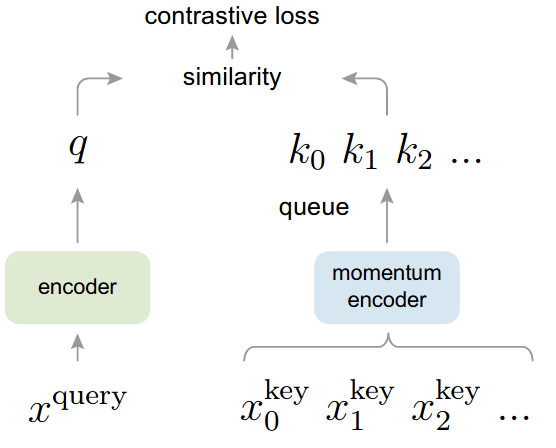 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+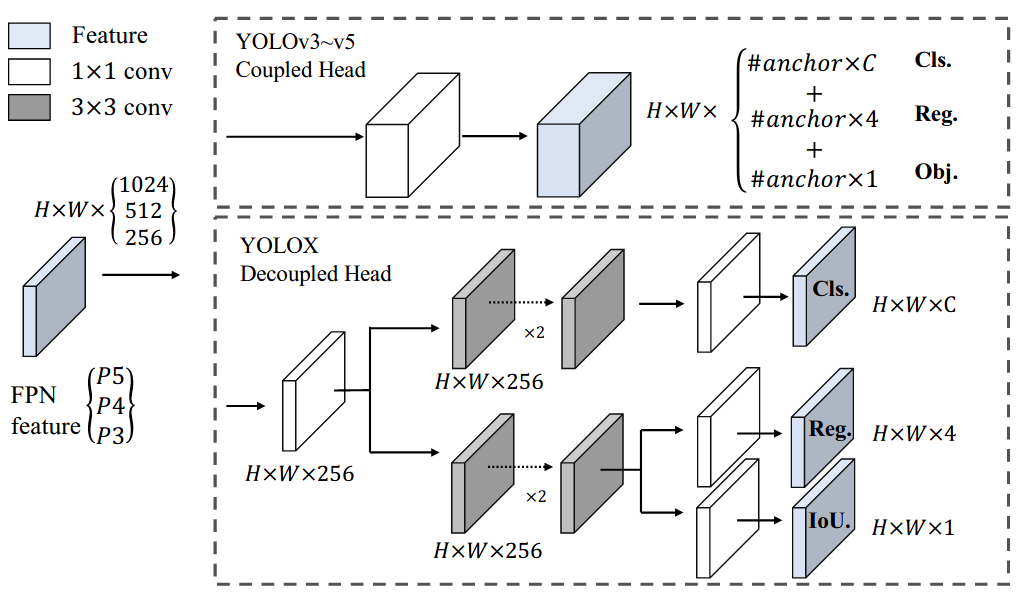 +
+