How to implement offloadable stateful functions #1768
Comments
|
Hey @Fabrizzz,
In terms of what service to implement to keep track of session locations, you could implement a simple service registry that keeps track of the locations of each replica. This registry can be updated whenever a replica is offloaded to a new node, and clients can use it to determine where their session is located. Overall, it sounds like you have a good understanding of the approach you want to take. Just make sure to consider all of the different components and how they interact with each other, and keep an eye on scalability and failover considerations.Good luck with your project, and feel free to reach out for further clarification if needed! |
My actions before raising this issue
Why do you need this?
Who is this for?
I am a student in computer science and i am currently studying how to implement stateful functions using OpenFaas and Redis, and how to offload them
Are you listed in the ADOPTERS.md file?
No, i am not.
Are you a GitHub Sponsor (Yes/No?)
Check at: https://github.com/sponsors/openfaas
Context
If it isn't the right place to post this, I apologize.
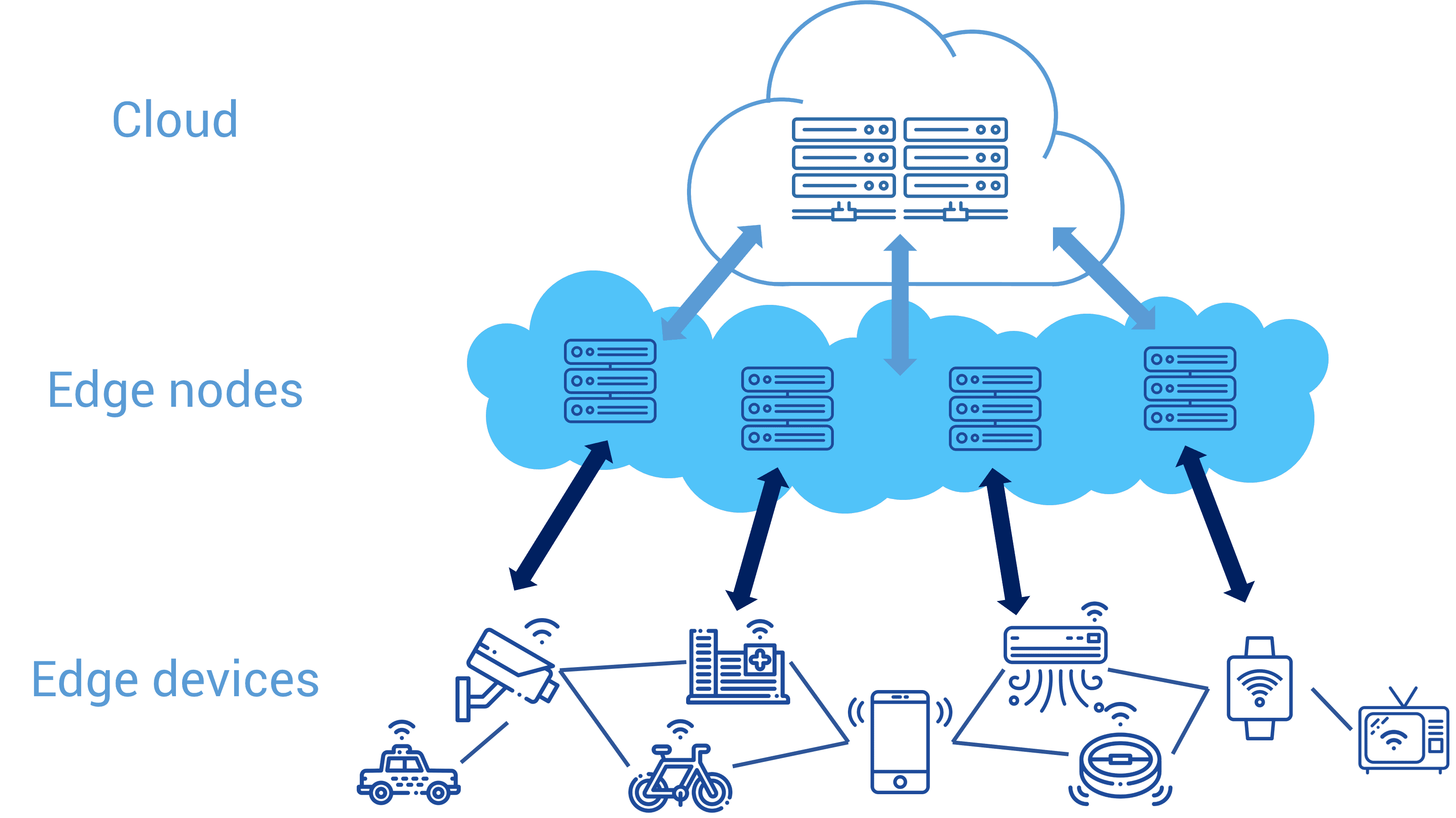
Anyway, i am a student in computer science and I have been studying how kubernetes and OpenFaas work over the last few months.
What I would like to do is to implement a system to deploy OpenFaas stateful functions over a network made of edge nodes (spanned geographically) with limited resources, and to offload the computation of those nodes to higher level nodes (with more computational power), when local computational resources are not enough, and if it works, i would like to share it with the rest of the community.
Topology image for reference:
The use case would be any kind of stateful function that holds a session in memory, associated to a user (for example an online document editor that also stores the log of changes).
I was wondering if someone already did it or if there is any service that implements this, or otherwise I am looking for some hints on
how to do it.
Here is how i was planning to implement it:
The stateful functions could be implemented using redis to store data locally, assuming clients are sticky and always communicates
with the same node, in order to access to their own "session". I could have a single Redis instance (statefulSet backed by a local drive), that is shared by all the replicas.
Or each replica could have his own Redis instance. In that case each client should communicate always with the same pod (i think this is possible using sticky client of Traefik ingress).
The ideal scenario would be to always contact the closest node to the client (assuming the client already knows which node to contact) to keep data and computation close to the origin, but if a single node receives too many requests, it could not be able to manage them all (either not enough CPU time, or enough memory to store the state into Redis). What i would like to do in this case is to automatically detect the saturation of resources (possibly using prometheus) and "move" some or all the replicas of a function to an higher level node (and of course the redis sessions associated to each replica) and let it manage them until the original lower level node has enough resources to process new requests again.
"Moving" the replicas would actually mean to reduce the number of local replicas, and increasing the same number of replicas on the upper node, while moving the data from the older node to the new node.
What i want to develop is a tool that automatically manages the replicas and the redis sessions associated with each replica (I think an easy way would be to clone the dump file that redis periodically creates on the drive from the previous node to the new node, then create a new redis instance in the new node and let it restore its state by reading the file). Assuming a single replica has been moved/offloaded from a node to another, how can i not break the sticky client logic? Should i Implement an external service that always keeps info about where each session of each client is currently located, so that the client can ask it where his session is located? I think it would be better to have a system in which the client doesn't need to know if and when the replica containing his session has been offloaded, but the ingress should automatically redirect his requests to the new node where the replica associated to the client has been offloaded.
I know i am asking a lot, and I am still thinking about how to implements all those things in the best way. If you have any opinion to share, even a simple hint on what to do, it would be greatly appreciated!
Your Environment
faas-cli version):0.15.4
docker version(e.g. Docker 17.0.05 ):I am using K3S
OpenFaas
Ubuntu 22.04
The text was updated successfully, but these errors were encountered: