This repo contains the scripts and notebooks used to train a convolutional neural network (+LSTM) on a corpus of text and predict the language of that text with 99% accuracy.
Initially, I based the neural network on a WildMl.org blog post that aims to predict sentiment from movie reviews. The WildML post has references to 2014 paper by Kim Yoon. I found this to only achieve ~98% acc and 11+ hours to train, so I chose to try out other architectures. The final architecture I settled on was a combination of CNN + LSTM, which achieved 99.7% accuracy on a held out set of 21k records provided by Startup.ml. Interestingly, the second architecture only required about 58mins to train.
Layers used in training the model:
- Embedding layer: generate vector representations of individual words. (+ dropout)
- A single 1D convolutional layer -- convole the input data using a 5x64 filter with valid padding. -- Apply a relu for potential non-linearity -- Apply max pooling over the output of the relu (stride of 4)
- An LSTM layer
- Finally, a fully connected layer with sigmoid activation.
Overall accuracy on the test set was 99.7%. The Normalized Confusion Matrix from the CNN + LSTM Architecture is shown below, which demonstrates some areas where the model is weaker. In particular, the model has hard time with Finnish and Romanian. This could provide some interesting next steps - pursuing more training data for those two languages, or investigating peculiarities about their structure.
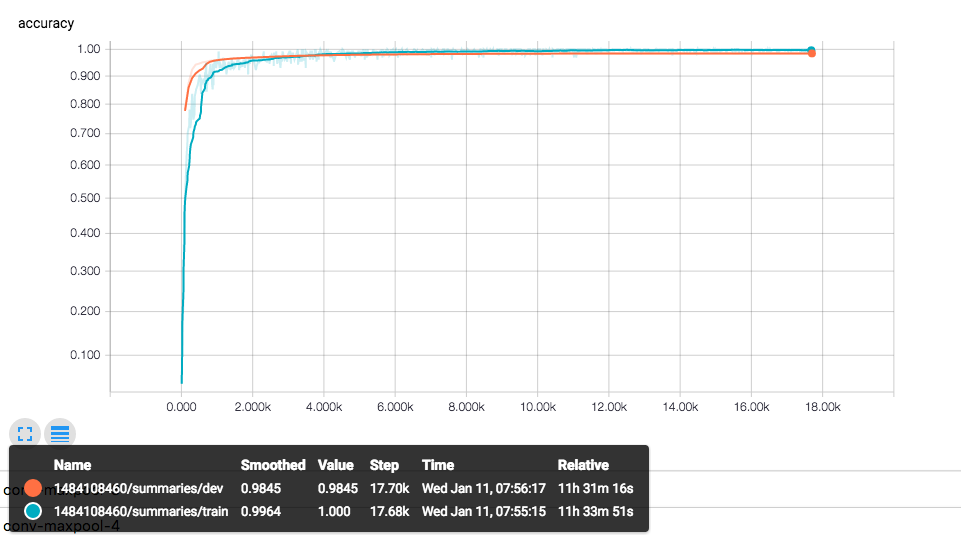
Below, is a plot demonstrating the plateauing training results from the first achitecture. The training time was 11+ hours, compared to 58mins for the second architecture of CNN + LSTM:
The data is pulled from statmt.org and comes as zipped directory containing many text files grouped into subdirectories by language.
The follwing is an example of the original data:
├── en
| ├── ep-00-01-17.txt
| └── ep-00-01-18.txt
| └──...
├── es
| ├── ep-00-01-17.txt
| └── ep-00-01-18.txt
| └──...
├── ...
Prior to running the CNN against any labeled data (for testing or training), we need to do some cleaning steps. The "exploratory work" notebook is the notebook used to perform these steps.
- Strip XML from the raw data since many lines in the raw data weren't meant to be used in training.
- Split each sentence at 70 words. Pad any sentences shorter than 70 words with the special token to all other sentences to make them 70 words. Padding sentences to the same length is useful because it allows us to efficiently batch our data since each example in a batch must be of the same length.
- Build a vocabulary index and map each word to an integer between 0 and N (the vocabulary size).
- Convert each sentence into a vector of integers.
- Training Data cleaned and prepped - A random sample of 600k records from the original corups, mapped to integer word represenations.
- Tensorflow Vocab Processor - for mapping between integer word index and actual word from the raw text
- Startup.ml Test Set Converted to Integers