diff --git a/.gitmodules b/.gitmodules
deleted file mode 100644
index e69de29b..00000000
diff --git a/CHANGELOG.md b/CHANGELOG.md
index 224cfe7b..b50293c9 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -4,6 +4,27 @@ All notable changes to the PyPI package for SWE-bench ([`swebench`](https://pypi
Prior to version 1.1.0, not all deployed versions are listed, as the PyPI package was going through development and testing. The noteworthy versions and the respective changes that were introduced by that version are included. All versions 1.1.0 onwards are fully listed.
+## [2.0.3] - 7/2/2024
+* #149 Interface fix: run_id is required
+* #151 Fix: Support JSON datasets (avoid loading json twice)
+* #152 Add very simple CI
+* #153 Various nitpicks
+* #155 Fix link to collection tutorial
+* #161 Fix path to image in docs
+* #162 Fix evaluation hanging issue and improve patch apply
+* #164 Fix so it doesn't crash when no env imgs to build
+* #166 Fix newline outputs for django's log parser
+* #168 Update reporting and skip empty model patch predictions
+
+## [2.0.0] - 6/27/2024
+Major release - the SWE-bench evaluation harness has been upgraded to incorporate containerized, sandboxed execution environments based on Docker. There are several chances to the API resulting from this:
+* Removal of the `swebench.metrics` module
+* Updates to the API of `swebench.harness` functionality
+* Significant modifications to underlying evaluation logic
+* Minor updates to installation specifications for different repos + versions.
+
+Read the full report [here](https://github.com/princeton-nlp/SWE-bench/tree/main/docs/20240627_docker)
+
## [1.1.5] - 5/15/2024
* Add support for HumanEvalFix (Python, JS, Go, Java) ([source](https://huggingface.co/datasets/bigcode/humanevalpack))
diff --git a/README.md b/README.md
index 43851265..03ca1143 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
-  +
+ 
@@ -39,7 +39,7 @@ Please refer our [website](http://swe-bench.github.io) for the public leaderboar
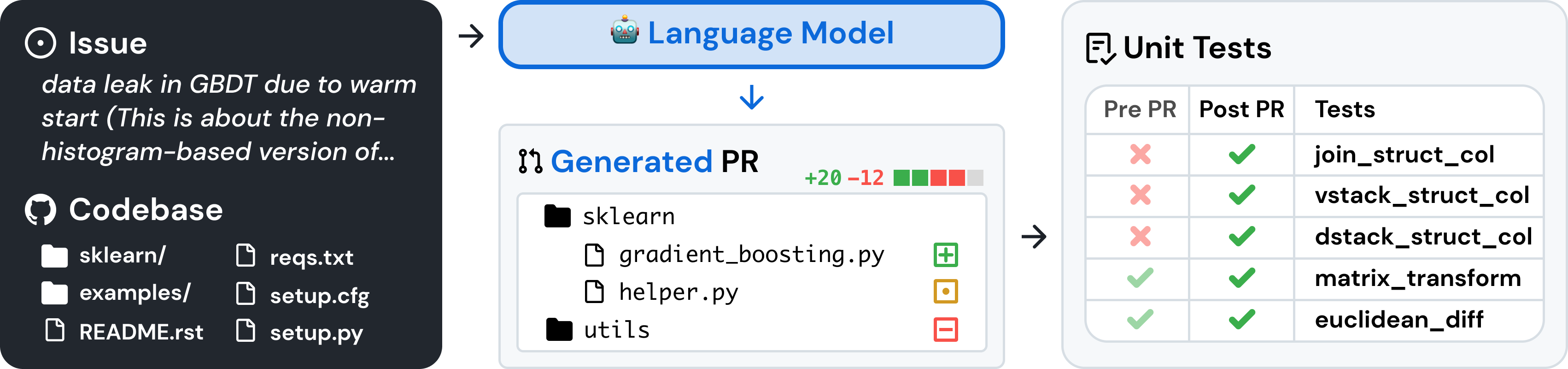
SWE-bench is a benchmark for evaluating large language models on real world software issues collected from GitHub.
Given a *codebase* and an *issue*, a language model is tasked with generating a *patch* that resolves the described problem.
- +
+ To access SWE-bench, copy and run the following code:
```python
diff --git a/build_deploy.sh b/assets/build_deploy.sh
similarity index 100%
rename from build_deploy.sh
rename to assets/build_deploy.sh
diff --git a/assets/collection.png b/assets/figures/collection.png
similarity index 100%
rename from assets/collection.png
rename to assets/figures/collection.png
diff --git a/assets/evaluation.png b/assets/figures/evaluation.png
similarity index 100%
rename from assets/evaluation.png
rename to assets/figures/evaluation.png
diff --git a/assets/swellama_banner.png b/assets/figures/swellama_banner.png
similarity index 100%
rename from assets/swellama_banner.png
rename to assets/figures/swellama_banner.png
diff --git a/assets/teaser.png b/assets/figures/teaser.png
similarity index 100%
rename from assets/teaser.png
rename to assets/figures/teaser.png
diff --git a/assets/validation.png b/assets/figures/validation.png
similarity index 100%
rename from assets/validation.png
rename to assets/figures/validation.png
diff --git a/docs/README_CN.md b/docs/README_CN.md
index 3bf77b65..65b00ad6 100644
--- a/docs/README_CN.md
+++ b/docs/README_CN.md
@@ -1,6 +1,6 @@
To access SWE-bench, copy and run the following code:
```python
diff --git a/build_deploy.sh b/assets/build_deploy.sh
similarity index 100%
rename from build_deploy.sh
rename to assets/build_deploy.sh
diff --git a/assets/collection.png b/assets/figures/collection.png
similarity index 100%
rename from assets/collection.png
rename to assets/figures/collection.png
diff --git a/assets/evaluation.png b/assets/figures/evaluation.png
similarity index 100%
rename from assets/evaluation.png
rename to assets/figures/evaluation.png
diff --git a/assets/swellama_banner.png b/assets/figures/swellama_banner.png
similarity index 100%
rename from assets/swellama_banner.png
rename to assets/figures/swellama_banner.png
diff --git a/assets/teaser.png b/assets/figures/teaser.png
similarity index 100%
rename from assets/teaser.png
rename to assets/figures/teaser.png
diff --git a/assets/validation.png b/assets/figures/validation.png
similarity index 100%
rename from assets/validation.png
rename to assets/figures/validation.png
diff --git a/docs/README_CN.md b/docs/README_CN.md
index 3bf77b65..65b00ad6 100644
--- a/docs/README_CN.md
+++ b/docs/README_CN.md
@@ -1,6 +1,6 @@
-
+
@@ -33,7 +33,7 @@
SWE-bench 是一个用于评估大型语言模型的基准,这些模型是从 GitHub 收集的真实软件问题。
给定一个 *代码库* 和一个 *问题*,语言模型的任务是生成一个 *补丁* 来解决所描述的问题。
-
+
## 🚀 设置
要从源代码构建 SWE-bench,请按照以下步骤操作:
diff --git a/docs/README_JP.md b/docs/README_JP.md
index 6bbdfde7..505b0456 100644
--- a/docs/README_JP.md
+++ b/docs/README_JP.md
@@ -4,7 +4,7 @@
-  +
+ 
@@ -34,7 +34,7 @@ ICLR 2024 の論文 SWE-bench: Ca
SWE-bench は、GitHub から収集された実世界のソフトウェアの課題に関する大規模言語モデルを評価するためのベンチマークです。
*コードベース*と*イシュー*が与えられ、言語モデルは記述された問題を解決する*パッチ*を生成するタスクを行います。
- +
+ ## 🚀 セットアップ
SWE-bench をソースからビルドするには、以下の手順に従ってください:
diff --git a/docs/README_TW.md b/docs/README_TW.md
index 5696e011..906d2a62 100644
--- a/docs/README_TW.md
+++ b/docs/README_TW.md
@@ -1,6 +1,6 @@
## 🚀 セットアップ
SWE-bench をソースからビルドするには、以下の手順に従ってください:
diff --git a/docs/README_TW.md b/docs/README_TW.md
index 5696e011..906d2a62 100644
--- a/docs/README_TW.md
+++ b/docs/README_TW.md
@@ -1,6 +1,6 @@
-
+
@@ -33,7 +33,7 @@
SWE-bench 是一個用於評估大型語言模型的基準,這些模型是從 GitHub 收集的真實軟體問題。
給定一個 *代碼庫* 和一個 *問題*,語言模型的任務是生成一個 *修補程式* 來解決所描述的問題。
-
+
## 🚀 設置
要從源代碼構建 SWE-bench,請按照以下步驟操作:
diff --git a/environment.yml b/environment.yml
deleted file mode 100644
index 50a63fa9..00000000
--- a/environment.yml
+++ /dev/null
@@ -1,20 +0,0 @@
-name: swe-bench
-dependencies:
- - python=3.9
- - pip
- - pip:
- - datasets
- - tenacity
- - anthropic
- - openai
- - tiktoken
- - beautifulsoup4
- - chardet
- - ghapi
- - GitPython
- - python-dotenv
- - requests
- - rich
- - transformers>=4.34.0
- - tqdm
- - conda-forge::gh
diff --git a/swebench/__init__.py b/swebench/__init__.py
index 14da412b..61bc1966 100644
--- a/swebench/__init__.py
+++ b/swebench/__init__.py
@@ -1,4 +1,4 @@
-__version__ = "2.0.2"
+__version__ = "2.0.3"
from swebench.collect.build_dataset import main as build_dataset
from swebench.collect.get_tasks_pipeline import main as get_tasks_pipeline
diff --git a/swebench/collect/README.md b/swebench/collect/README.md
index e4061eba..96b1d480 100644
--- a/swebench/collect/README.md
+++ b/swebench/collect/README.md
@@ -5,7 +5,7 @@ We include a comprehensive [tutorial](https://github.com/princeton-nlp/SWE-bench
> SWE-bench's collection pipeline is currently designed to target PyPI packages. We hope to expand SWE-bench to more repositories and languages in the future.
- +
+ ## Collection Procedure
To run collection on your own repositories, run the `run_get_tasks_pipeline.sh` script. Given a repository or list of repositories (formatted as `owner/name`), for each repository this command will generate...
diff --git a/swebench/collect/collection.md b/swebench/collect/collection.md
index c6abb2e0..236f718b 100644
--- a/swebench/collect/collection.md
+++ b/swebench/collect/collection.md
@@ -6,7 +6,7 @@ In this tutorial, we explain how to use the SWE-Bench repository to collect eval
> SWE-bench's collection pipeline is currently designed to target PyPI packages. We hope to expand SWE-bench to more repositories and languages in the future.
## Collection Procedure
To run collection on your own repositories, run the `run_get_tasks_pipeline.sh` script. Given a repository or list of repositories (formatted as `owner/name`), for each repository this command will generate...
diff --git a/swebench/collect/collection.md b/swebench/collect/collection.md
index c6abb2e0..236f718b 100644
--- a/swebench/collect/collection.md
+++ b/swebench/collect/collection.md
@@ -6,7 +6,7 @@ In this tutorial, we explain how to use the SWE-Bench repository to collect eval
> SWE-bench's collection pipeline is currently designed to target PyPI packages. We hope to expand SWE-bench to more repositories and languages in the future.
-

+

-

+
