This repository contains the code and data for our ACL 2024 paper Long-Context Language Modeling Parallel Encodings.
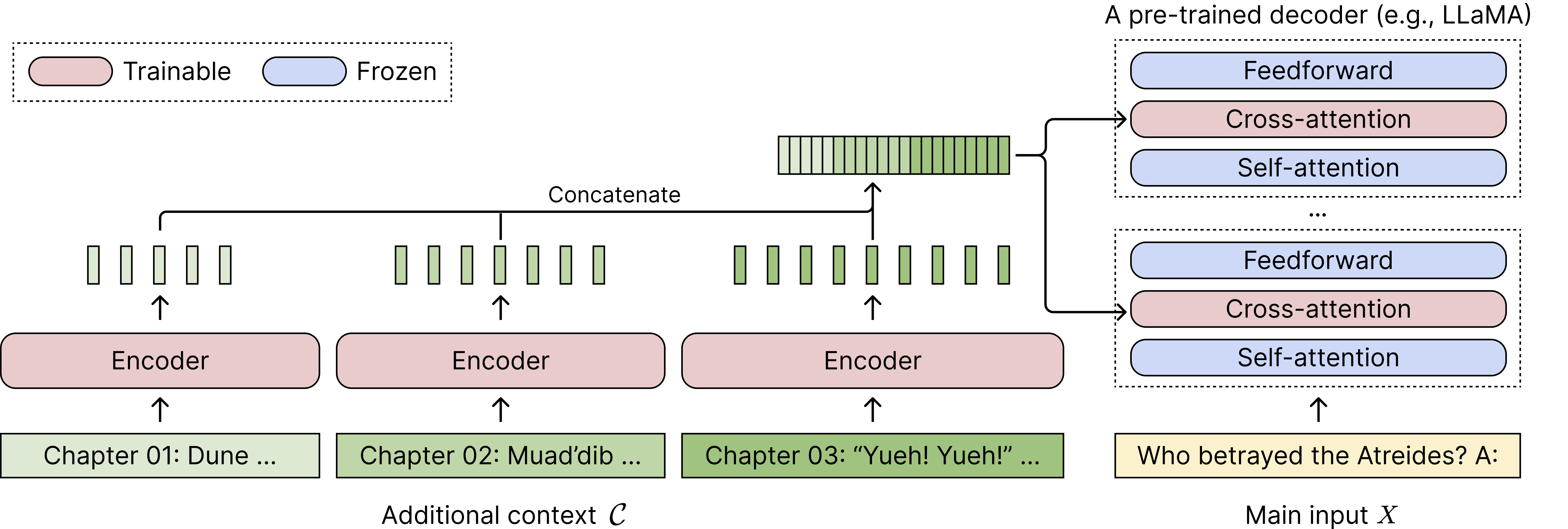
In this work, we propose CEPE ![]() — Context Expansion with Parallel Encoding — a flexible framework for extending the context window of language models.
This repository includes the code for preprocessing the data, training CEPE, and evaluating all baselines.
— Context Expansion with Parallel Encoding — a flexible framework for extending the context window of language models.
This repository includes the code for preprocessing the data, training CEPE, and evaluating all baselines.
*: CÈPE is derived from the French word for porcini mushroom
![]() and is prounouced /sep/
and is prounouced /sep/
Want to test out CEPE? Try out our models using Huggingface!
First, set up the environment by installing the requirements.
Then, simply copy and paste the modeling_llama_flash.py file into your working directory, and then you can run it with:
import torch
from transformers import LlamaTokenizer
from modeling_llama_flash import LlamaForCausalContextLM
device = "cuda"
model_name = "hyen/CEPED-LLaMA-2-Chat-7B"
tokenizer = LlamaTokenizer.from_pretrained(model_name)
model = LlamaForCausalContextLM.from_pretrained(
model_name,
use_flash_attention_2="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
).eval()
contexts = tokenizer([
"My friends and I enjoy eating out at restaurants together. However, we also enjoy cooking and making food as a group as well."
"Many of my friends like to play soccer and volleyball. We also enjoy watching movies and going to museums and galleries.",
], return_tensors="pt", padding=True)
inputs = tokenizer("Question: what are three ideas for a social with a large groups of friends in New York City.\nAnswer:", return_tensors="pt")
# encoder_input_ids and encoder_attention_mask should be in the shape of (bsz, n_ctx, seq_length)
output = model.generate(
input_ids=inputs.input_ids.to(device),
attention_mask=inputs.attention_mask.to(device),
encoder_input_ids=contexts.input_ids.unsqueeze(0).to(device),
encoder_attention_mask=contexts.attention_mask.unsqueeze(0).to(device),
max_new_tokens=200,
sample=True,
top_p=0.95,
)
print(tokenizer.batch_decode(output)[0])This prints out:
Answer: Here are three ideas for a social with a large group of friends in New York City:
1. Host a rooftop party: Find a rooftop bar or restaurant with a great view of the city. Invite a large group of friends and enjoy drinks, appetizers, and music together.
2. Go on a group scavenger hunt: Create a list of items or challenges that your friends must complete around the city. This could include taking a photo with a street performer, buying a drink from a specific bar, or finding a landmark. The group that completes the most challenges wins.
3. Take a group cooking class: Find a cooking school or culinary institute in New York City that offers classes for large groups. Choose a theme or type of cuisine to focus on, such as Italian or Asian. Then, work together to prepare a meal as a group.
Another sample:
Answer: Here are three ideas for a social with a large group of friends in New York City:
1. Visit a popular restaurant: New York City is known for its diverse and vibrant food scene. There are countless restaurants that cater to different tastes and dietary restrictions. A large group of friends can visit a popular restaurant together and enjoy a meal.
2. Go to a museum or art gallery: New York City is home to many world-class museums and art galleries. Some of the most popular museums include the Metropolitan Museum of Art, the Museum of Modern Art, and the Guggenheim Museum. A large group of friends can visit a museum or art gallery together and explore the exhibits.
3. Take a walk in a park: New York City has many parks and green spaces that offer a peaceful escape from the hustle and bustle of the city.
- Requirements
- Model List
- Data
- Code Structure
- Training
- Language Modeling Evaluation
- Downstream Evaluation
- Bug or Questions
- Citation
Please install the latest versions of PyTorch (torch) by following the official installation instructions.
You can install the rest of the requirements with pip install --r requirements.txt.
We also recommend checking out the installation instruction for flash-attention.
We tested the code with python==3.9.12, torch==2.1.1, accelerate==0.24.0, transformers==4.34.1, and CUDA version 12.3.
Our released models are listed as following. See the example above on how to use them.
| Model |
|---|
| CEPE-LLaMA-2-7B |
| CEPED-LLaMA-2-Chat-7B |
Quick tips:
encoder_input_idsandencoder_attention_maskshould be in the shape of (batch_size, n_ctx, seq_length)- Model generations are typically better with longer inputs in the decoder.
To obtain the training and evaluation data, please refer to the ./data directory.
If you simply want all the data for evaluation, you can download them from Google Drive.
| Name | Link |
|---|---|
| RedPajama test, ArXiv + Book filtered by 32K tokens | link |
| RedPajama test, ArXiv + Book filtered by 128K tokens | link |
| RedPajama test, all domains concatenated | link |
| RedPajama test, Retrieval-augmented (Contriever) | link |
It can be expensive to build and index the retrieval corpus at a large scale. We provide the test set used in the Retrieval-augmented Language Modeling section on google drive, which you can download from the link above.
If you are interested in doing more with retrieval, you can reproduce our retrieval corpus by following the steps described in the ./data directory and the ./retrieval directory.
We model our retrieval code after the Contriever code repository.
train.py: train CEPEeval_lm.py: evaluate CEPE and other baselines on language modelingeval_downstream.py: evaluate CEPE and other baselines on downstream tasksconfigs/: folder that contains all config files to reproduce baselines
Training consists of two stage: a warmup stage and the standard training stage.
Make sure that you have downloaded the necessary data as indicated by the --train_file and --validation_file arguments.
You can change the path of these arguments for your own system.
In the warmup stage, we simply train the model with the same inputs to both the encoder and the decoder. To reproduce the models from the paper, you can use:
torchrun --nnodes=1 --nproc_per_node=4 train.py --config configs/train_llama2_warmup
torchrun --nnodes=1 --nproc_per_node=4 train.py --config configs/train_llama2chat_warmup
You can also customize this for your own purposes by taking a closer look at the config files and train.py.
In this stage, we take the model after the warmup stage and apply the standard cross-entropy loss.
torchrun --nnodes=1 --nproc_per_node=8 train.py --config configs/train_llama2_cepe
Note that to train with 4K tokens of encoder input and 4K tokens of decoder input, your GPU must have 80GB of memory.
For CEPED, we also add the KL Divergence loss. You can customize the coefficient of each loss in the arguments --kl_loss_cof and --lm_loss_cof
torchrun --nnodes=1 --nproc_per_node=8 train.py --config configs/train_llama2chat_cepe
If you are interested in pre-training your own encoder model, you can use:
torchrun --nnodes=1 --nproc_per_node=8 train_mlm.py --config configs/train_mlm
Alternatively, you can simply use the MLM encoder that we have pre-trained, which you can download from here.
To evaluate CEPE on ArXiv, you can run
python eval_lm.py --config configs/test_ab_32k_prevdoc_112x_4096 --model_name_or_path hyen/CEPE-LLaMA-2-7B --model_class cepe --validation_domains arxiv --output_dir output/CEPE-LLaMA-2-7B
You can find all other configs for evaluation in the ./config directory.
Alternatively, you can reproduce all LM experiments from the paper using our scripts:
# CEPE
bash scripts/run_cepe_lm.sh
# StreamingLLM
bash scripts/run_streamingllm_lm.sh
# Vanilla models (LLaMA-2, LLaMA-2-32K, YaRN-64K, YaRN-128K)
bash scripts/run_vanilla_lm.sh
# RePlug
bash scripts/run_replug_lm.sh
The language modeling code in eval_lm.py is modeled after the training code in train.py.
However, there are just a few minor difference:
- We implement the baseline models for evaluation (notably, StreamingLLM evalaution requires extra logic not supported by the Transformers Trainer).
- We use a loop over the dataloader as opposed to using the Trainer evaluation loop, which gives a slightly faster throughput and lower memory usage.
- We add support for the HuggingFace datasets (PG19, ProofPile, and CodeParrot).
First, you want to download the datasets with Contriever-retrieved passages
| Name | Link |
|---|---|
| Natural Questions | link |
| TriviaQA | link |
| PopQA | link |
Then, you can run all the experiments from our paper with:
bash scripts/run_qa.sh
If you are interested in more customized runs, you can use the script above as an example.
You can simply modify the config file or add additional command line arguments to python eval_downstream.py.
All ICL datasets are available on HuggingFace, which means that you can simply use datasets.load_dataset for everything.
To run the experiments from the paper, use:
bash scripts/run_icl.sh
To run the experiments from the paper, use:
bash scripts/run_zeroscrolls.sh
We use the validation sets available on HuggingFace, which may either use the version released by the original authors or by SCROLLS (Shaham et al., 2022).
If you have any questions related to the code or the paper, feel free to email Howard (hyen@cs.princeton.edu). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
Please cite our paper if you use CEPE in your work:
@inproceedings{yen2024long,
title={Long-Context Language Modeling with Parallel Context Encoding},
author={Yen, Howard and Gao, Tianyu and Chen, Danqi},
booktitle={Association for Computational Linguistics (ACL)},
year={2024}
}