情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。它包含各式各样的任务,比如句子级情感分类、评价对象级情感分类、观点抽取、情绪分类等。情感分析是人工智能的重要研究方向,具有很高的学术价值。同时,情感分析在消费决策、舆情分析、个性化推荐等领域均有重要的应用,具有很高的商业价值。
情感预训练模型SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)。SKEP利用情感知识增强预训练模型, 在14项中英情感分析典型任务上全面超越SOTA,此工作已经被ACL 2020录用。SKEP是百度研究团队提出的基于情感知识增强的情感预训练算法,此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义。SKEP为各类情感分析任务提供统一且强大的情感语义表示。
论文地址:https://arxiv.org/abs/2005.05635
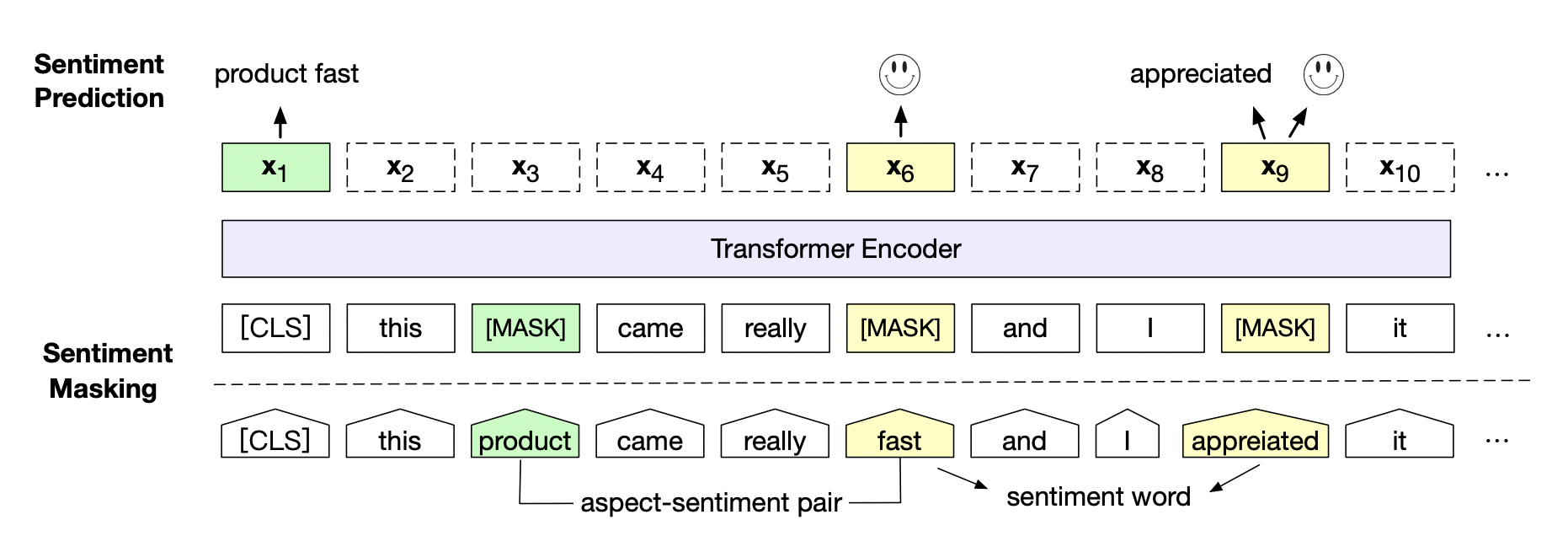
百度研究团队在三个典型情感分析任务,句子级情感分类(Sentence-level Sentiment Classification),评价对象级情感分类(Aspect-level Sentiment Classification)、观点抽取(Opinion Role Labeling),共计14个中英文数据上进一步验证了情感预训练模型SKEP的效果。实验表明,以通用预训练模型ERNIE作为初始化,具体效果如下表:
| 任务 | 数据集合 | 语言 | 指标 | SKEP | 数据集地址 |
| 句子级情感 分类 |
SST-2 | 英文 | ACC | 97.60 | 下载地址 |
| ChnSentiCorp | 中文 | ACC | 96.08 | 下载地址 | |
| 评价对象级的 情感分类 |
SE-ABSA16_PHNS | 中文 | ACC | 65.22 | 下载地址 |
| 观点 抽取 |
COTE_DP | 中文 | F1 | 86.30 | 下载地址 |
以下是本项目主要代码结构及说明:
skep/
├── deploy # 部署
│ └── python
│ └── predict.py # python预测部署示例
├── export_model.py # 动态图参数导出静态图参数脚本
├── predict_aspect.py # 对象级的情感分类任务预测脚本
├── predict_opinion.py # 观点抽取任务预测脚本
├── predict_sentence.py # 句子级情感分类任务预测脚本
├── README.md # 使用说明
├── train_aspect.py # 对象级的情感分类任务训练脚本
├── train_opinion.py # 观点抽取任务训练脚本
└── train_sentence.py # 句子级情感分类任务训练脚本
以句子级情感分类任务为例,详细说明SKEP模型在下游任务中该如何使用,其他任务(对象级的情感分类任务、观点抽取任务)使用方式以此类推。
句子级情感分类数据集,本示例采用常用开源数据集�ChnSenticorp中文数据集、GLUE-SST2英文数据集。这两个数据集PaddleNLP已经内置。 通过以下方式即可实现加载。
train_ds, dev_ds = load_dataset("chnsenticorp", splits=["train", "dev"])
train_ds, dev_ds = load_dataset("glue", "sst-2", splits=["train", "dev"])我们以情感分类公开数据集ChnSentiCorp(中文)、SST-2(英文)为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
unset CUDA_VISIBLE_DEVICES
python -m paddle.distributed.launch --gpus "0" train_sentence.py --model_name "skep_ernie_1.0_large_ch" --device gpu --save_dir ./checkpoints可支持配置的参数:
model_name: 使用预训练模型的名称,可选skep_ernie_1.0_large_ch和skep_ernie_2.0_large_en。 skep_ernie_1.0_large_ch:是SKEP模型在预训练ernie_1.0_large_ch基础之上在海量中文数据上继续预训练得到的中文预训练模型; skep_ernie_2.0_large_en:是SKEP模型在预训练ernie_2.0_large_en基础之上在海量英文数据上继续预训练得到的中文预训练模型。save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。max_seq_length:可选,ERNIE/BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.00。epochs: 训练轮次,默认为3。init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。seed:可选,随机种子,默认为1000.device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。
model = paddlenlp.transformers.SkepForSequenceClassification.from_pretrained(
"skep_ernie_1.0_large_ch")
tokenizer = paddlenlp.transformers.SkepTokenizer.from_pretrained(
"skep_ernie_1.0_large_ch")更多预训练模型,参考transformers
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的save_dir中。
如:
checkpoints/
├── model_100
│ ├── model_config.json
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...
NOTE:
- 如需恢复模型训练,则可以设置
init_from_ckpt, 如init_from_ckpt=checkpoints/model_100/model_state.pdparams。 - 如需使用ernie-tiny模型,则需要提前先安装sentencepiece依赖,如
pip install sentencepiece - 使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,具体代码见export_model.py。静态图参数保存在
output_path指定路径中。 运行方式:
python export_model.py --model_name="skep_ernie_1.0_large_ch" --params_path=./checkpoint/model_900/model_state.pdparams --output_path=./static_graph_params其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。
导出模型之后,可以用于部署,deploy/python/predict.py文件提供了python部署预测示例。运行方式:
python deploy/python/predict.py --model_name="skep_ernie_1.0_large_ch" --model_file=static_graph_params.pdmodel --params_file=static_graph_params.pdiparams启动预测:
export CUDA_VISIBLE_DEVICES=0
python predict_sentence.py --model_name "skep_ernie_1.0_large_ch" --device 'gpu' --params_path checkpoints/model_900/model_state.pdparams将待预测数据如以下示例:
这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般
怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片
作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。
可以直接调用predict函数即可输出预测结果。
如
Data: 这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 Label: negative
Data: 怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片 Label: negative
Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。 Label: positive
可以使用PaddleNLP提供的Taskflow工具来对输入的文本进行一键情感分析,具体使用方法如下:
from paddlenlp import Taskflow
senta = Taskflow("sentiment_analysis")
senta("怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片")
'''
[{'text': '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片', 'label': 'negative'}]
'''
senta(["怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片",
"作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间"])
'''
[{'text': '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片', 'label': 'negative'},
{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间', 'label': 'positive'}
]
'''
# 使用skep_ernie_1.0_large_ch模型进行情感分析
senta = Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch")
senta("作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。")
'''
[{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。', 'label': 'positive'}]
'''