JavaScript 异步编程指南 - 聊聊 Node.js 中的事件循环 #21
Assignees

Labels
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
事件循环是一种控制应用程序的运行机制,在不同的运行时环境有不同的实现,上一节讲了浏览器中的事件循环,它们有很多相似的地方,也有着各自的特点,本节讨论下 Node.js 中的事件循环。
了解 Node.js 中的事件循环
Node.js 做为 JavaScript 的服务端运行时,主要与网络、文件打交道,没有了浏览器中事件循环的渲染阶段。
在浏览器中有 HTML 规范来定义事件循环的处理模型,之后由各浏览器厂商实现。Node.js 中事件循环的定义与实现均来自于 Libuv。
Libuv 围绕事件驱动的异步 I/O 模型而设计,最初是为 Node.js 编写的,提供了一个跨平台的支持库。下图展示了它的组成部分,Network I/O 是网络处理相关的部分,右侧还有文件操作、DNS,底部 epoll、kqueue、event ports、IOCP 这些是底层不同操作系统的实现。
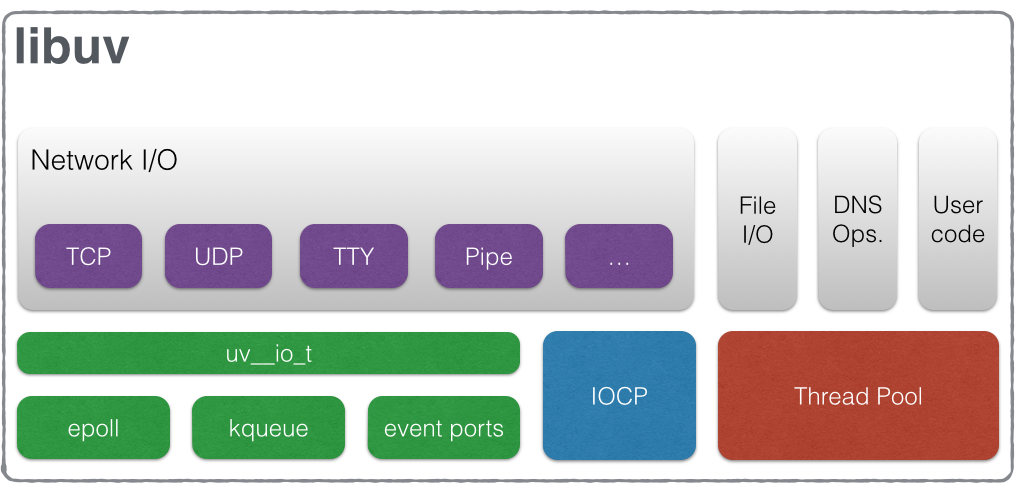
图片来源:http://docs.libuv.org/en/v1.x/_images/architecture.png
事件循环的六个阶段
当 Node.js 启动时,它会初始化事件循环,处理提供的脚本,同步代码入栈直接执行,异步任务(网络请求、文件操作、定时器等)在调用 API 传递回调函数后会把操作转移到后台由系统内核处理。目前大多数内核都是多线程的,当其中一个操作完成时,内核通知 Node.js 将回调函数添加到轮询队列中等待时机执行。
下图左侧是 Node.js 官网对事件循环过程的描述,右侧是 Libuv 官网对 Node.js 的描述,都是对事件循环的介绍,不是所有人上来都能去看源码的,这两个文档通常也是对事件循环更直接的学习参考文档,在 Node.js 官网介绍的也还是挺详细的,可以做为一个参考资料学习。
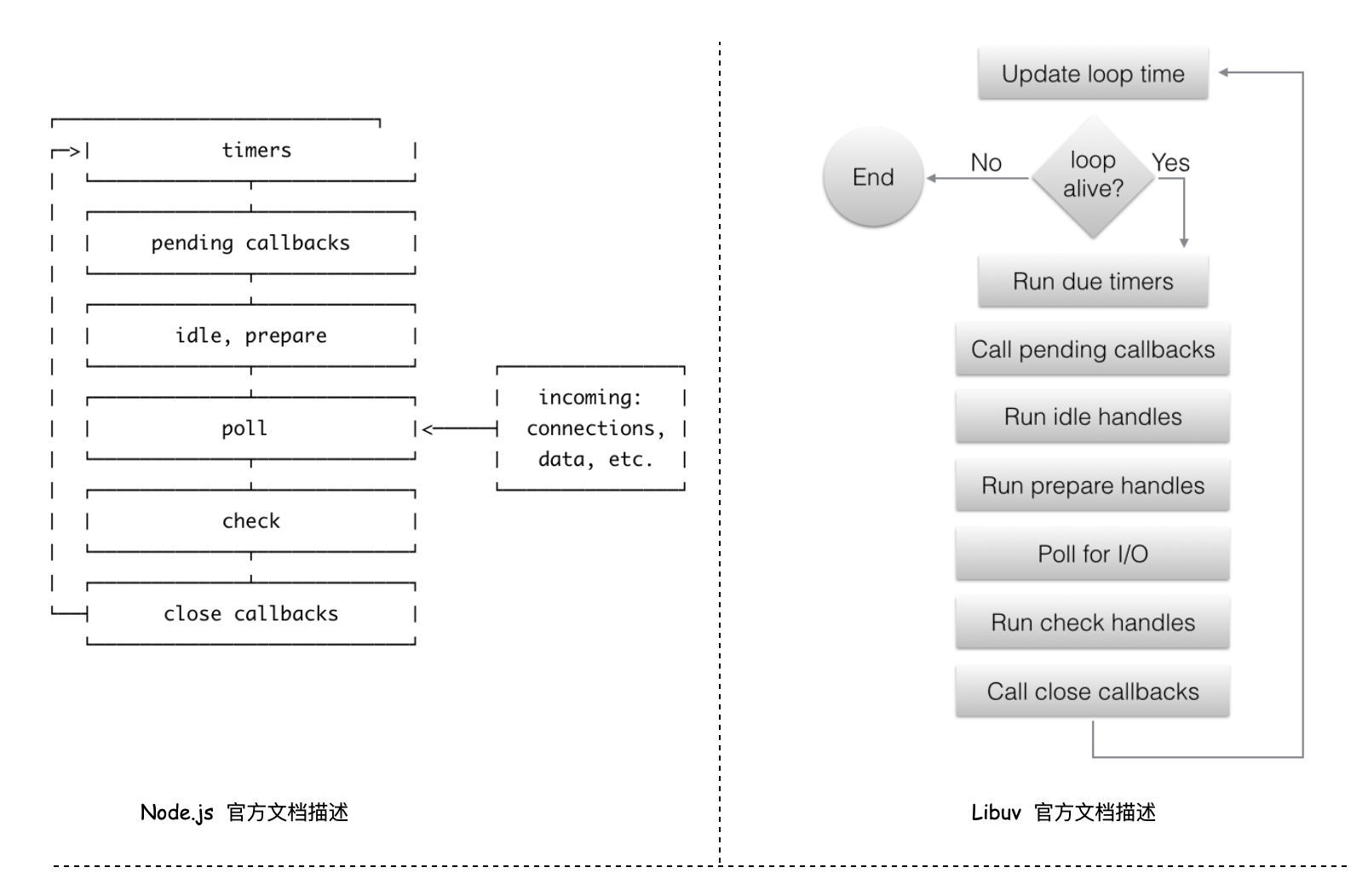 左侧 Node.js 官网展示的事件循环分为 6 个阶段,每个阶段都有一个 FIFO(先进先出)队列执行回调函数,这几个阶段之间执行的优先级顺序还是明确的。
左侧 Node.js 官网展示的事件循环分为 6 个阶段,每个阶段都有一个 FIFO(先进先出)队列执行回调函数,这几个阶段之间执行的优先级顺序还是明确的。
右侧更详细的描述了,在事件循环迭代前,先去判断循环是否处于活动状态(有等待的异步 I/O、定时器等),如果是活动状态开始迭代,否则循环将立即退出。
下面对每个阶段分别讨论。
timers(定时器阶段)
首先事件循环进入定时器阶段,该阶段包含两个 API
setTimeout(cb, ms)、setInterval(cb, ms)前一个是仅执行一次,后一个是重复执行。这个阶段检查是否有到期的定时器函数,如果有则执行到期的定时器回调函数,和浏览器中的一样,定时器函数传入的延迟时间总比我们预期的要晚,它会受到操作系统或其它正在运行的回调函数的影响。
例如,下例我们设置了一个定时器函数,并预期在 1000 毫秒后执行。
当调用 setTimeout 异步函数后,程序紧接着执行了 someOperation() 函数,中间有些耗时操作大约消耗 3000ms,当完成这些同步操作后,进入一次事件循环,首先检查定时器阶段是否有到期的任务,定时器的脚本是按照 delay 时间升序存储在堆内存中,首先取出超时时间最小的定时器函数做检查,如果
**nowTime - timerTaskRegisterTime > delay**取出回调函数执行,否则继续检查,当检查到一个没有到期的定时器函数或达到系统依赖的最大数量限制后,转移到下一阶段。在我们这个示例中,假设执行完 someOperation() 函数的当前时间为 T + 3000:
pending callbacks
定时器阶段完成后,事件循环进入到 pending callbacks 阶段,在这个阶段执行上一轮事件循环遗留的 I/O 回调。根据 Libuv 文档的描述:大多数情况下,在轮询 I/O 后立即调用所有 I/O 回调,但是,某些情况下,调用此类回调会推迟到下一次循环迭代。听完更像是上一个阶段的遗留。
idle, prepare
idle, prepare 阶段是给系统内部使用,idle 这个名字很迷惑,尽管叫空闲,但是在每次的事件循环中都会被调用,当它们处于活动状态时。这一块的资料介绍也不是很多。略...
poll
poll 是一个重要的阶段,这里有一个概念观察者,有文件 I/O 观察者,网络 I/O 观察者等,它会观察是否有新的请求进入,包含读取文件等待响应,等待新的 socket 请求,这个阶段在某些情况下是会阻塞的。
阻塞 I/O 超时时间
在阻塞 I/O 之前,要计算它应该阻塞多长时间,参考 Libuv 文档上的一些描述,以下这些是它计算超时时间的规则:
如果以上情况都没有,则采用最近定时器的超时时间,或者如果没有活动的定时器,则超时时间为无穷大,poll 阶段会一直阻塞下去。
示例一
很简单的一段代码,我们启动一个 Server,现在事件循环的其它阶段没有要处理的任务,它会在这里等待下去,直到有新的请求进来。
示例二
结合阶段一的定时器,在看个示例,首先启动 app.js 做为服务端,模拟延迟 3000ms 响应,这个只是为了配合测试。再运行 client.js 看下事件循环的执行过程:
setTimeout run after 1003 ms。当 poll 阶段队列为空时,并且脚本被 setImmediate() 调度过,此时,事件循环也会结束 poll 阶段,进入下一个阶段 check。
check
check 阶段在 poll 阶段之后运行,这个阶段包含一个 API
setImmediate(cb)如果有被 setImmediate 触发的回调函数,就取出执行,直到队列为空或达到系统的最大限制。setTimeout VS setImmediate
拿 setTimeout 和 setImmediate 对比,这是一个常见的例子,基于被调用的时机和定时器可能会受到计算机上其它正在运行的应用程序影响,它们的输出顺序,不总是固定的。
setTimeout VS setImmediate VS fs.readFile
但是一旦把这两个函数放入一个 I/O 循环内调用,setImmediate 将总是会被优先调用。因为 setImmediate 属于 check 阶段,在事件循环中总是在 poll 阶段结束后运行,这个顺序是确定的。
close callbacks
在 Libuv 中,如果调用关闭句柄 uv_close(),它将调用关闭回调,也就是事件循环的最后一个阶段 close callbacks。
这个阶段的工作更像是做一些清理工作,例如,当调用 socket.destroy(),'close' 事件将在这个阶段发出,事件循环在执行完这个阶段队列里的回调函数后,检查循环是否还 alive,如果为 no 退出,否则继续下一次新的事件循环。
包含 Microtask 的事件循环流程图
在浏览器的事件循环中,把任务划分为 Task、Microtask,在 Node.js 中是按照阶段划分的,上面我们介绍了 Node.js 事件循环的 6 个阶段,给用户使用的主要是 timer、poll、check、close callback 四个阶段,剩下两个由系统内部调度。这些阶段所产生的任务,我们可以看做 Task 任务源,也就是常说的 “Macrotask 宏任务”。
通常我们在谈论一个事件循环时还会包含 Microtask,Node.js 里的微任务有 Promise、还有一个也许很少关注的函数 queueMicrotask,它是在 Node.js v11.0.0 之后被实现的,参见 PR/22951。
Node.js 中的事件循环在每一个阶段执行后,都会检查微任务队列中是否有待执行的任务。
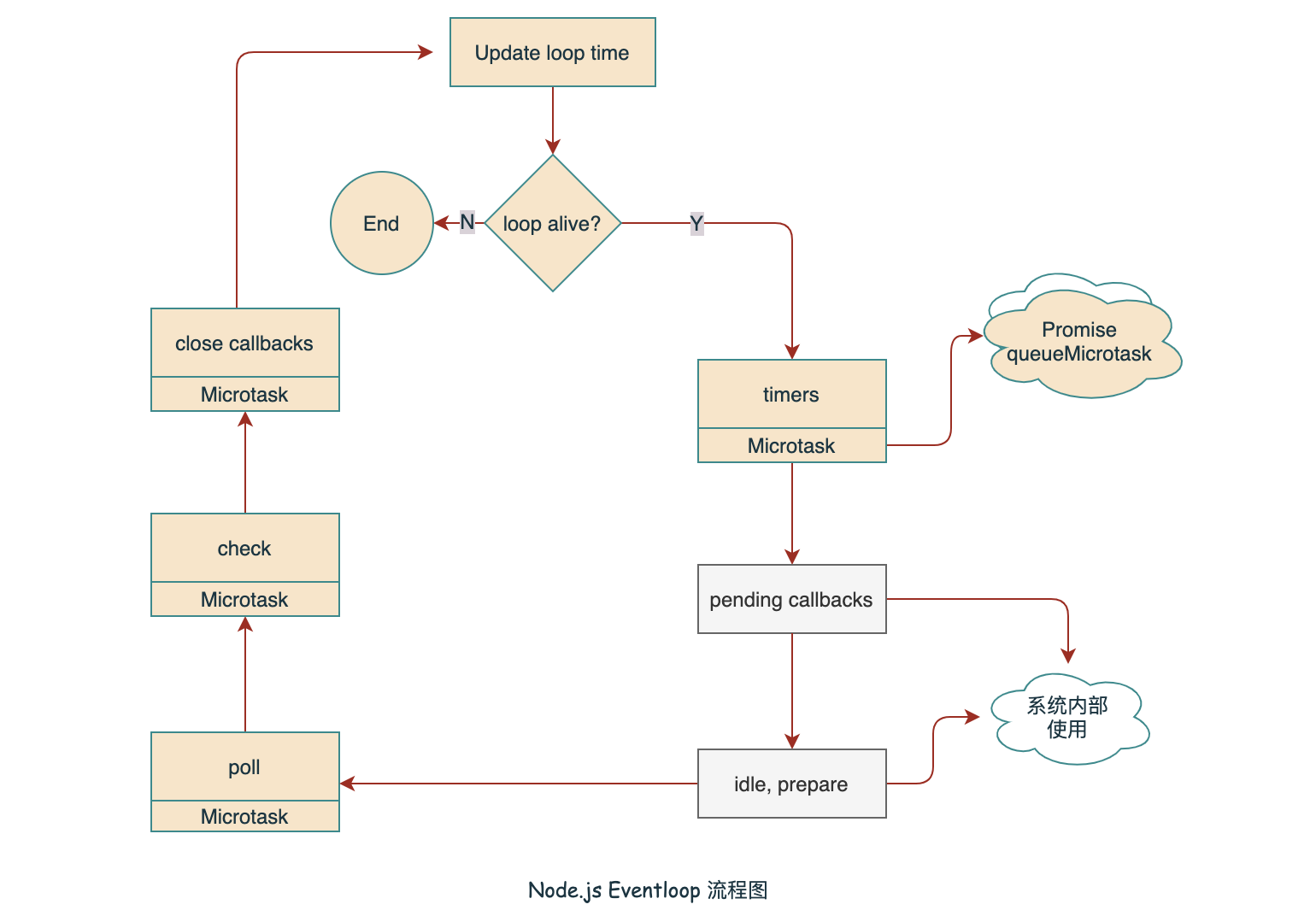
Node.js 11.x 前后差异
Node.js 在 v11.x 前后,每个阶段如果即存在可执行的 Task 又存在 Microtask 时,会有一些差异,先看一段代码:
在 Node.js v11.x 之前,当前阶段如果存在多个可执行的 Task,先执行完毕,再开始执行微任务。基于 v10.22.1 版本运行结果如下:
在 Node.js v11.x 之后,当前阶段如果存在多个可执行的 Task,先取出一个 Task 执行,并清空对应的微任务队列,再次取出下一个可执行的任务,继续执行。基于 v14.15.0 版本运行结果如下:
在 Node.js v11.x 之前的这个执行顺序问题,被认为是一个应该要修复的 Bug 在 v11.x 之后并修改了它的执行时机,和浏览器保持了一致,详细参见 issues/22257 讨论。
特别的 process.nextTick()
Node.js 中还有一个异步函数 process.nextTick(),从技术上讲它不是事件循环的一部分,它在当前操作完成后处理。如果出现递归的 process.nextTick() 调用,这将会很糟糕,它会阻断事件循环。
如下例所示,展示了一个 process.nextTick() 递归调用示例,目前事件循环位于 I/O 循环内,当同步代码执行完成后 process.nextTick() 会被立即执行,它会陷入无限循环中,与同步的递归不同的是,它不会触碰 v8 最大调用堆栈限制。但是会破坏事件循环调度,setTimeout 将永远得不到执行。
将 process.nextTick 改为 setImmediate 虽然是递归的,但它不会影响事件循环调度,setTimeout 在下一次事件循环中被执行。
process.nextTick 是立即执行,setImmediate 是在下一次事件循环的 check 阶段执行。但是,它们的名字着实让人费解,也许会想这两个名字交换下比较好,但它属于遗留问题,也不太可能会改变,因为这会破坏 NPM 上大部分的软件包。
在 Node.js 的文档中也建议开发者尽可能的使用 setImmediate(),也更容易理解。
总结
Node.js 事件循环分为 6 个阶段,每个阶段都有一个 FIFO(先进先出)队列执行回调函数,这几个阶段之间执行的优先级顺序还是明确的。
事件循环的每一个阶段,有时还会伴随着一些微任务而运行,这里以 Node.js v11.x 版本为分界线会有一些差异,文中也都有详细的介绍。
在上一篇介绍了浏览器的事件循环机制,本篇又详细的介绍了 Node.js 中的事件循环机制,留给大家一个思考问题,结合自己的理解,总结下浏览器与 Node.js 中事件循环的一些差异,这个也是常见的一个面试题,欢迎在留言区讨论。
在 Cnode 上看到的两篇事件循环相关文章,推荐给大家,文章很精彩,评论也更加精彩。
Reference
The text was updated successfully, but these errors were encountered: