

Netdata is unique—although the company was founded in 2013, our CEO originally created Netdata as an open source project, which we still support today. Within the company, you see a lot of the same traits you’d find in any open source project. We’ve got people all over the world, we’re almost entirely distributed, and we rely heavily on collaboration to get things done.
The team I’m on—which is in charge of releases—has me here in the US, along with others in Athens, Greece. We’ve re-built our release process to reflect the way we work. The same person doesn’t have to be involved each time, and anyone can follow the steps.
Collaborative, continuous improvement
When I started at Netdata, there wasn’t a well-defined release process. Developers didn’t know for certain when a release was published, if the Docker images were uploaded, or when the binary packages would be ready.
Things have improved significantly since then. Releases are primarily run by my team, the Site Reliability Engineering (SRE) team. Our process developed organically, but developers played a large role in shaping it. Most of our developers use Netdata on their own systems, so they have a vested interest beyond just making sure that the code they wrote happens to work.
Best practices
Build a continuous improvement culture, then adjust and update as you learn.
Collaborate closely with developers on release and operations processes.
Make it easy for distributed teams to connect asynchronously—but don’t hesitate to talk in real-time.
Set fixed pre- and post-release practices to ensure quality and security.
See why better developer experiences equal better software
We work constantly with our developers to improve the release process and make it as easy as possible for the SRE team, developers, and our users to know what's going on. For example, we just merged some continuous integration (CI) changes to make the whole build process significantly faster by not re-running checks that we had already run. And over the past year, we’ve been using GitHub Actions to streamline pull request checks, which saves us five to 10 minutes each time versus using another service.
Building with an open source model
Our open source agent lives on GitHub, which is focused on single-node monitoring and sending metrics metadata to Netdata Cloud, our SaaS product. I actually started as an open source contributor myself. I was interested in the Netdata project and built a reputation with the rest of the team, so they offered me a job.
We build the open source agent nightly, with a regular release every four to six weeks to support our enterprise users. The main branch on GitHub is generally stable enough that most people can use the nightly builds without issue. But for someone who is using Netdata for monitoring mission-critical systems, you need it to work, period. Our regular releases provide better certainty that everything works correctly and upgrading isn’t going to randomly break things.
Ensuring quality pre-release
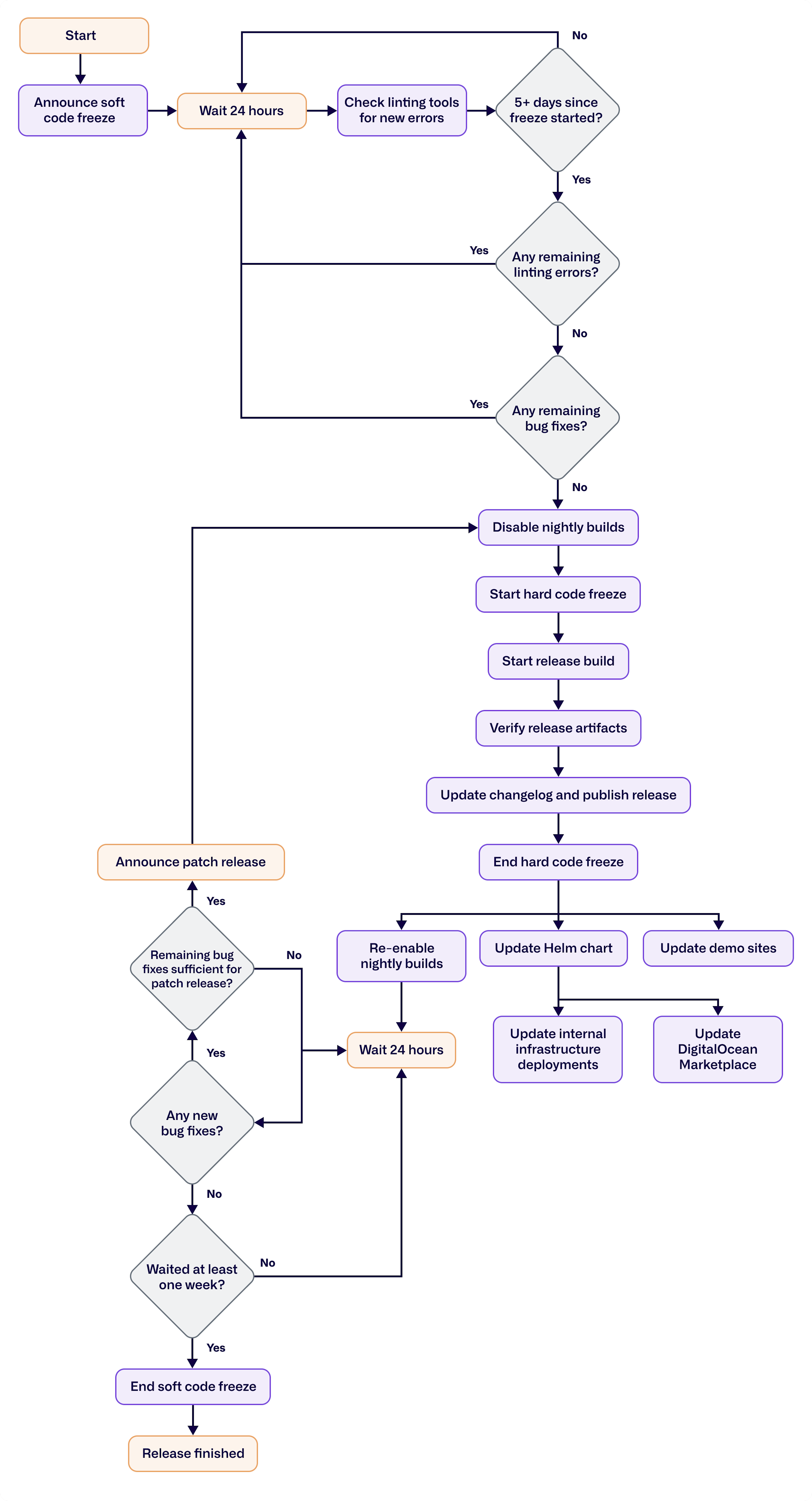
When the full release process starts, we meet as a team to discuss any known issues with the code and whether they’re worth delaying the release over. If it’s something minor, we’ll go ahead with the release and put a note about it in the release notes. From there we enter a soft code freeze. Nobody’s allowed to merge anything to the main branch that isn’t a bug fix.
Learn more about developer-first security
That’s when the buffer period begins. We use static analysis tools like Coverity and Codacy to re-check for any bugs or issues. We also use GitHub Advanced Security, which allows developers to see the bugs and fix the issues themselves. Using these tools makes less work for us, and helps us automatically increase quality in the enterprise release—we can fix issues early and don’t have to wait for a user or customer to find them.
Kicking off build and release
Once we’ve gone three to five days with no new issues, we start the actual release process. We turn off nightly builds so we don't end up with multiple release builds running concurrently, then announce a hard code freeze. During the hard freeze, nothing gets merged to the main branch at all—even bug fixes—until the release is done.
To trigger the release build process, we create an empty commit in our Git repository with a special format in the commit description. That’s pushed out to GitHub and triggers Travis CI to run the release build, including all of the checks that go beyond what we run on nightly releases. Travis CI also builds and prepares all of our release artifacts: Docker images, source code distributions, and binary packages. Then Travis CI uploads those to the right places and creates a draft release on GitHub.
When that’s all done and working correctly, we let our marketing team know we’re ready for them to review and copy the release notes. That’s usually when the hard code freeze ends. The release notes are copied into the draft release and we publish it.
Deploying updates
At this point, the release is effectively done from the perspective of our users. But there’s still more for us to do. We update our demo sites and the Kubernetes Helm chart. Since every instance of Netdata within the company runs on Kubernetes, we also use the Helm chart to update our internal deployments. Netdata is listed as an application on DigitalOcean Marketplace, so we submit a pull request for updates to them too.
Key indicators
Release cycle time
Build time
Number of open bug reports
Post-release cleanup and patching
Dive into the data on GitHub Actions and faster delivery
Then we enter a post-release development cycle. We start by re-enabling nightly builds but stay in a soft code freeze for the next week. Any new features get merged to a separate branch instead of to the main one, and every day or so we check for new bugs to see if there’s any need for a patch release. If we do end up with enough release issues or bugs, we start right back from before the hard code freeze and issue a patch release. It may be atypical, but we generally don’t do patch releases outside of this period for anything short of a critical security issue. After we make it through the post-release period, we merge the development branch with all the new features back into the main one. We update everything based on this, and then the soft code freeze ends.
Overview statistics
100% remote across 21 timezones
3M+ users worldwide
2,000+ new users added per day
~1M Docker pulls per day
Connecting it all with shared collaboration tools
Get tips for integrating GitHub with Slack
Almost all of our team discussions happen in Slack. Most releases are coordinated in Slack too, except in cases where we’re considering delaying the release or issuing a patch release. That’s typically done in real-time with Zoom or Google Meet. Whatever you use, it’s important to maintain communication between development and release teams. If you have multiple teams responsible for different parts of the release, it’s absolutely critical that all of them know where the process is, how far along things need to be before they get involved, and when that might be. With a distributed company, you can’t just walk over and tell someone, “Hey, I’m done with this step. It’s your turn to do the next one.” We’re continuing to work closely together to see where we can improve, always.


