Find-based replace implementation
#146
Comments
|
Great stuff @hiiamboris.
Isn't it possible that you'd want to replace a single value, anywhere in a deep structure? I agree that the normal case is |
This is an interesting one. If we remove paren support from paths, they shouldn't be nestable, right? |
|
Also on paths, are we sure we want this behavior? In some cases that will be exactly what we want, but should we always treat block/list the same? |
|
Does It's niftier than |
|
Setup thought, just more straight-line: |
|
I'm reminded that I don't love |
This case sounds made up to me ;) But anyway, if
Paths constructed at runtime will still be.
Not sure, but paths are troublesome without it. Question is, is it worth another refinement, e.g. /paths? There's also another direction here: to run deep replacement on all inner series - strings, binaries, vectors. Should we have control over it or we just forward everyone into
Let it be your homework then to find cases where
That may be less nested, but also heavier for the no-limit case. I haven't by the way considered the past-tail index case here. I'd prefer a language-wide solution for it, rather than patching holes arbitrarily. |
|
Good thoughts. More questions. :^\ |
I'm all for profiling it in the grand scheme of |
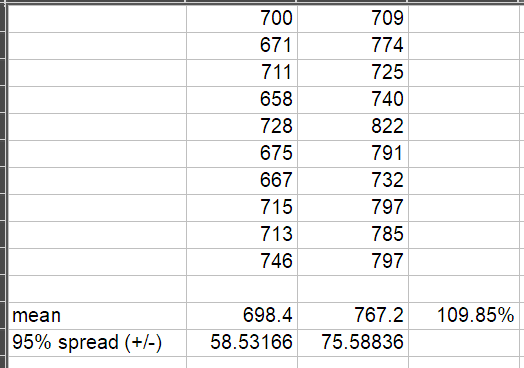
OK (init time, sample size=10): |
{kind=link}
|
Cool, I can't tell what those numbers mean though, unless it makes the whole thing 10% slower, which is surprising. |
|
It's no surprise. |
|
OK then, just flip the blocks so the check is |
|
Done. |
|
Cool. How is |
|
|
I stumbled for a couple seconds there, as I wondered what was Also: |
|
@hiiamboris, which was why I said " in the grand scheme of replace" initially. +1 for removing |
Rationale
Current
replaceimplementation was stiched together by different people with different small needs and no central design:findtoparsemode when /deep is used and in other hard to predict cases, totally changing semantics and disabling the possibility of/samecomparison and fast hash lookupsfindmode, adds loop properties to it and makes a little step intomap-each/mapparseterritorychangemakes it of quadratic complexity, seriously limiting applicabilityfindfeatures (/only, /same, /part) are not supported by itSee also red/red#4945 previously ignored
Proposal
New implementation:
replace(Parse is left tomapparse)valueis a function, it's just insertedapplyWISH: /only on REPLACE #83Arguments in favor of
mapparseand againstreplace/parserefinement:pattern, but alsovaluechanges meaning in /parse modereplaceexpects a constant value (it's optimized for that), whilemapparseevaluates a code block (how to tell /parse mode if block should be treated as code or as a value)?mapparseis consistent withforparse, and if we integrate it intoreplace, what to do withforparse?forparseandmapparseare loops, so they supportbreak&continuein their code blocks, so their logic is differentmapparsehas different argument order - same as the other loops (foreach, repeat)Performance comparison
I have made two variants of the new implementation:
replace2is straightforward and compiler-friendly, whilereplace1uses blocks of code to make the loop tighter (but they are interpreted).replace/allis the old implementation.Due to compiler benefits
replace2usually wins overreplace1. And considering that get-words in paths cannot be compiled yet, and it includes workarounds for red/red#5319 and red/red#5320 , it should perform better once those kludges are removed. Compared to the old implementation, performance is much more predictable and linear, with worst case slowdown currently down to 23% due to allocation of a new buffer.Tests
replacetest suite adapted for the new version is here. Some tests were refitted withmapparse. Some currently fail due to red/red#5321The text was updated successfully, but these errors were encountered: