- Provide a unified way for defining events in SONiC switch.
- Provide a unified way for publishing the events.
- Provide support for exporting events to external gNMI clients via Subscribe
- Provide a structured format for event data with pre-defined schema with revisioning to handle future updates.
- Provide the ability to stream at the max of 10K events per second to external clients.
The external tools that monitor system health often use syslog messages to look for events that need alert raised. The syslog messages being text string could potentially change across releases. Some log messages could get split into multiple different ones. This poses a challenge to the external tools as they are forced to adapt for multiple different versions and parse a message based on the OS version of the producer. This would become even more challenging, when we upgrade individual container images via kubernetes/app-package-manager.
The tools that use syslog messages face higher latency, as they have to wait for syslog messages to arrive to an external repository. This latency could run in the order of minutes.

An adhoc list of regex is maintained by the consumer of the regex.
Sample:
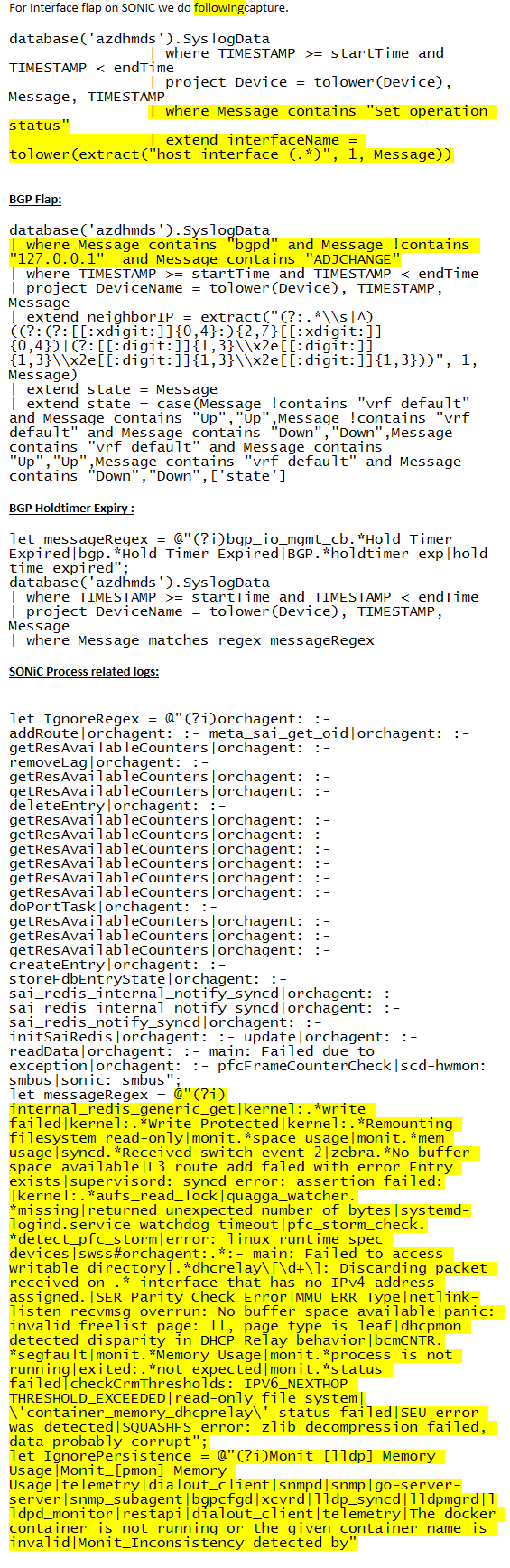
For Interface flap on SONiC we do followingcapture.
database...SyslogData
| where TIMESTAMP >= startTime and TIMESTAMP < endTime
| project Device = tolower(Device), Message, TIMESTAMP
| where Message contains "Set operation status"
| extend interfaceName = tolower(extract("host interface (.*)", 1, Message))
BGP Flap:
database...SyslogData
| where Message contains "bgpd" and Message !contains "127.0.0.1" and Message contains "ADJCHANGE"
| where TIMESTAMP >= startTime and TIMESTAMP < endTime
| project DeviceName = tolower(Device), TIMESTAMP, Message
| extend neighborIP = extract("(?:.*\\s|^)((?:(?:[[:xdigit:]]{0,4}:){2,7}[[:xdigit:]]{0,4})|(?:[[:digit:]]{1,3}\\x2e[[:digit:]]{1,3}\\x2e[[:digit:]]{1,3}\\x2e[[:digit:]]{1,3}))", 1, Message)
| extend state = Message
| extend state = case(Message !contains "vrf default" and Message contains "Up","Up",Message !contains "vrf default" and Message contains "Down","Down",Message contains "vrf default" and Message contains "Up","Up",Message contains "vrf default" and Message contains "Down","Down",['state']
BGP Holdtimer Expiry :
let messageRegex = @"(?i)bgp_io_mgmt_cb.*Hold Timer Expired|bgp.*Hold Timer Expired|BGP.*holdtimer exp|hold time expired";
database...SyslogData
| where TIMESTAMP >= startTime and TIMESTAMP < endTime
| project DeviceName = tolower(Device), TIMESTAMP, Message
| where Message matches regex messageRegex
SONiC Process related logs:
let messageRegex = @"(?i)internal_redis_generic_get|kernel:.*write failed|kernel:.*Write Protected|kernel:.*Remounting filesystem read-only|monit.*space usage|monit.*mem usage|syncd.*Received switch event 2|zebra.*No buffer space available|L3 route add faled with error Entry exists|supervisord: syncd error: assertion failed:|kernel:.*aufs_read_lock|quagga_watcher.*missing|returned unexpected number of bytes|systemd-logind.service watchdog timeout|pfc_storm_check.*detect_pfc_storm|error: linux runtime spec devices|swss#orchagent:.*:- main: Failed to access writable directory|.*dhcrelay\[\d+\]: Discarding packet received on .* interface that has no IPv4 address assigned.|SER Parity Check Error|MMU ERR Type|netlink-listen recvmsg overrun: No buffer space available|panic: invalid freelist page: 11, page type is leaf|dhcpmon detected disparity in DHCP Relay behavior|bcmCNTR.*segfault|monit.*Memory Usage|monit.*process is not running|exited:.*not expected|monit.*status failed|checkCrmThresholds: IPV6_NEXTHOP THRESHOLD_EXCEEDED|read-only file system|\'container_memory_dhcprelay\' status failed|SEU error was detected|SQUASHFS error: zlib decompression failed, data probably corrupt";
let IgnorePersistence = @"(?i)Monit_[lldp] Memory Usage|Monit_[pmon] Memory Usage|telemetry|dialout_client|snmpd|snmp|go-server-server|snmp_subagent|bgpcfgd|xcvrd|lldp_syncd|lldpmgrd|lldpd_monitor|restapi|dialout_client|telemetry|The docker container is not running or the given container name is invalid|Monit_Inconsistency detected by"
Problems with this approach are obvious. To state a few
- Hard to even decipher for correctness.
- No formal process to review/maintain/update
- No formal process for devs to indicate new events or change in log messages.
- III party code like BGP, changes the log messages nearly in every release. Keeping upto that with no formal process could lead to missing events.
- Multiple variation of messages for single event.
- As it is dependent on syslogs, the latency from event occurrence to action, can be long.
- Every message is matched against every regex - redundant/expensive.
- Severity level of an event is not tagged along.
- No more scanning logs for events, but SONiC switch publishes events.
- SONiC defines events in schema. Type of events and type of associated params.
- Events are published as just data only per schema, hence no more parsing.
- SONiC assures events per schema across releases.
- New events arrive transparently and the tool will be forced to learn on demand.
- The schema could tag events with additional metadata like, severity, globally unique event-id and more.
- All schema are published in shared global repo, which anyone can read to decipher/understand an event.

The BGP state change is taken for a sample use case.
When BGP state changes, the event is reported in syslog messages as below
bgpd.log.2.gz:Aug 17 02:39:21.286611 SN6-0101-0114-02T0 INFO bgp#bgpd[62]: %ADJCHANGE: neighbor 100.126.188.90 Down Neighbor deleted
bgpd.log.2.gz:Aug 17 02:46:42.615668 SN6-0101-0114-02T0 INFO bgp#bgpd[62]: %ADJCHANGE: neighbor 100.126.188.90 Up
bgpd.log.2.gz:Aug 17 04:46:51.290979 SN6-0101-0114-02T0 INFO bgp#bgpd[62]: %ADJCHANGE: neighbor 100.126.188.78 Down Neighbor deleted
bgpd.log.2.gz:Aug 17 05:06:26.871202 SN6-0101-0114-02T0 INFO bgp#bgpd[62]: %ADJCHANGE: neighbor 100.126.188.78 Up
An event is defined for BGP state change in YANG model as below.
module sonic-events-common {
namespace "http://github.com/Azure/sonic-events-common";
prefix evtcmn;
yang-version 1.1;
organization
"SONiC";
contact
"SONiC";
description
"SONIC Events common definition";
revision 2022-12-01 {
description
"Common reusable definitions";
}
grouping sonic-events-cmn {
leaf timestamp {
type yang::date-and-time;
description "time of the event";
}
}
grouping sonic-events-usage {
leaf usage {
type uint8 {
range "0..100" {
error-message "Incorrect val for %";
}
}
description "Percentage in use";
}
leaf limit {
type uint8 {
range "0..100" {
error-message "Incorrect val for %";
}
}
description "Percentage limit set";
}
}
}
module sonic-events-bgp {
namespace "http://github.com/Azure/sonic-events-bgp";
yang-version 1.1;
import sonic-events-common {
prefix evtcmn;
}
revision 2022-12-01 {
description "BGP alert events.";
}
organization
"SONiC";
contact
"SONiC";
description
"SONIC BGP events";
container bgp-state {
description "
Declares an event for BGP state for a neighbor IP
The status says up or down";
leaf ip {
type inet:ip-address;
description "IP of neighbor";
}
leaf status {
type enumeration {
enum "up";
enum "down";
}
description "Provides the status as up (true) or down (false)";
}
uses evtcmn:sonic-events-cmn;
}
container bgp-hold-timer {
description "
Declares an event for BGP hold timer expiry.
This event does not have any other parameter.
Hence source + tag identifies an event";
uses evtcmn:sonic-events-cmn;
}
container zebra-no-buff {
description "
Declares an event for zebra running out of buffer.
This event does not have any other parameter.
Hence source + tag identifies an event";
uses evtcmn:sonic-events-cmn;
}
}
The event will now be published as below per schema. The instance data would indicate YANG module path for validation. The event is as well sent to syslog.
{ "sonic-events-bgp:bgp-state": { "ip": "100.126.188.90", "status": "down", "timestamp": "2022-08-17T02:39:21.286611Z" } }
{ "sonic-events-bgp:bgp-state": { "ip": "100.126.188.90", "status": "up", "timestamp": "2022-08-17T02:46:42.615668Z" } }
{ "sonic-events-bgp:bgp-state": { "ip": "100.126.188.78", "status": "down", "timestamp": "2022-08-17T04:46:51.290979Z" } }
{ "sonic-events-bgp:bgp-state": { "ip": "100.126.188.78", "status": "up "timestamp": "2022-08-17T05:06:26.871202Z" } }
A gNMI client could subscribe for events in streaming mode. At the rate of 10K/second and to conserve switch resources, only one gNMI client is supported and hence all events are sent to the client with no additonal filtering. It is expected that the client will save events in a an external storage and consumer clients can watch/query from the external resource with filters. Below shows the command & o/p for subscribing all events.
gnmic --target events --path "/events/" --mode STREAM --stream-mode ON_CHANGE
The instance data would indicate YANG module path & revision that is required for validation.
o/p
{
"sonic-events-bgp:bgp-state": {
"timestamp": "2022-08-17T02:39:21.286611Z",
"ip": "100.126.188.90",
"status": "down"
}
}
{
"sonic-events-bgp:bgp-state": {
"timestamp": "2022-08-17T02:46:42.615668Z",
"ip": "100.126.188.90",
"status": "up"
}
}
{
"sonic-events-bgp:bgp-state": {
"timestamp": "2022-08-17T04:46:51.290979Z",
"ip": "100.126.188.78",
"status": "down"
}
}
{
"/events/sonic-events-bgp:bgp-state": {
"timestamp": "2022-08-17T05:06:26.871202Z",
"ip": "100.126.188.78",
"status": "up"
}
}
STATE-DB: EVENT-STATS published: 123456 missed-slow-receiver: 100 missed-offline-cache: 1012 missed-internal: 0 latency: 0.012345
Events definition, usage & update.
- Events are defined in YANG schema.
- Events are classified with source of event (as BGP, swss, ...) and type of event as tag within that source.
- A source is defined as YANG module
- Tags for a source is defined as container in the YANG module
- Each instance data provides YANG path as < module name > : < container name >
- The schema may specify a globally unique event-id.
- An event is defined with zero or more event specific parameters. A subset of the parameters are identified as key.
- Events schema updates are identified with revisions.
- YANG schema files can be set as contract between SONiC and the external events consumers.
The libswsscommon will have the APIs for publishing & receiving.
- To publish an event to all subscribers.
- To receive events from all publishers.
- Event is published with Yang module path and params.
- The publishing API is transparent to listening subscribers. The subscribers could come and go anytime.
- The subscribers are transparent to publishing sources transparently. The publishing sources could come and go anytime.
- The receiving API supports filtering by source. For an example, a receiver may choose to receive events from "BGP" & "SWSS" sources only.
- The events are sequenced internally to assess missed messages by receivers.
- The events published are validated against YANG schema. Any invalid messages is reported via syslog & event for alerting.
- The method of detection can be any.
- This can vary across events.
- The events could be published at run time by the individual components, like orchagent, syncd. The code is updated to call the event-publish API.
- The events could be inferred indirectly from syslog messages. The rsyslog plugin could be an option for live publishing, which can parse syslog messages as they arrive and raise events for messages that indicate an event.
- There can be multiple event detectors running under different scopes (host/containers), concurrently.
- An on-demand cache service is provided to cache events for a period in transient cache.
- This service can be started/stopped and retrieve cached data via an libswsscommon API.
- A receiver could use this, during its downtime and use the cache upon restart.
- The service caches uses max available cache size.
- Events that overflow the max allocatable buffer size are dropped and counted as missed.
-
Telemetry container runs a gNMI server to export events to external receiver/collector via SUBSCRIBE request.
-
Telemetry container sends all the events to the receiver in FIFO order.
-
Telemetry container ensures atleast one event sent every N seconds, by sending a heartbeat/no-op event when there are no events to publish.
-
Telemetry container uses an internal buffer, when local publishing rates overwhelms the receiver.
- Internal buffer overflow will cause new events to be dropped.
- The dropped events are counted and recorded in STATE-DB via stats.
- A telemetry service crash will lose all events in internal buffer and not included in the dropped counter.
-
Telemetry uses cache service, during downtime of main receiver or telemetry service and replay on connect.
- A long downtime can result in message drop due to cache overflow.
- A unplanned telemetry service down (say crash) will not use the cache service
-
The stats for maintained for SLA compliance verification. This inlcudes like total count of events sent, missed count, ...
- The stats are collected and recorded in STATE-DB.
- An external gNMI client could subscribe for stats table updates' streaming ON-CHANGE.

- YANG schema is written for every event.
- Schema is maintained in multiple files as one per source (src/sonic-yang-models/yang-events/events-bgp.yang)
- All the schema files are copied into one single location in the install image, like config YANG models.
- This schema could be published in an global/shared repo for use by external consumer of the events.
The Event API is provided as part of libswsscommon with API definition in a header file.
/*
* Events library
*
* APIs are for publishing & receiving events with source, tag and params along with timestamp.
*
*/
class events_base;
typedef events_base* event_handle_t;
/*
* Initialize an event publisher instance for an event source.
*
* A single publisher instance is maintained for a source.
* Any duplicate init call for a source will return the same instance.
*
* Choosing cache will help read cached data, during downtime, if any.
*
* NOTE:
* The initialization occurs asynchronously.
* Any event published before init is complete, is blocked until the init
* is complete. Hence recommend, do the init as soon as the process starts.
*
* Input:
* event_source
* The YANG module name for the event source. All events published with the handle
* returned by this call is tagged with this source, transparently. The receiver
* could subscribe with this source as filter.
* Return
* Non NULL handle
* NULL on failure
*/
event_handle_t events_init_publisher(std::string &event_source);
/*
* De-init/free the publisher
*
* Input:
* Handle returned from events_init_publisher
*
* Output:
* None
*/
void events_deinit_publisher(event_handle_t &handle);
/*
* List of event params
*/
typedef std::map<std::string, std::string> event_params_t;
/*
* Publish an event
*
* Internally a globally unique sequence number is embedded in every published event,
* The sequence numbers from same publishing instances can be compared
* to see if there any missing events between.
*
* The sequence has two components as run-time-id that distinguishes
* the running instance of a publisher and other a running sequence
* starting from 0, which is local to this runtime-id.
*
* The receiver API keep next last received number for each runtime id
* and use this info to compute missed event count upon next event.
*
* input:
* handle - As obtained from events_init_publisher for a event-source.
*
* event_tag -
* Name of the YANG container that defines this event in the
* event-source module associated with this handle.
*
* YANG path formatted as "< event_source >:< event_tag >"
* e.g. {"sonic-events-bgp:bgp-state": { "ip": "10.10.10.10", ...}}
*
* params -
* Params associated with event; This may or may not contain
* timestamp. In the absence, the timestamp is added, transparently.
*
*/
void event_publish(event_handle_t handle, const std:string &event_tag,
const event_params_t *params=NULL);
typedef std::vector<std::string> event_subscribe_sources_t;
/*
* Initialize subscriber.
* Init subscriber, optionally to filter by event-source.
*
* Input:
* use_cache
* When set to true, it will make use of the cache service transparently.
* The cache service caches events during session down time (last deinit to this
* init call).
*
* lst_subscribe_sources_t
* List of subscription sources of interest.
* The source value is the corresponding YANG module name.
* e.g. "sonic-events-bgp " is the source modulr name for bgp.
*
* Return:
* Non NULL handle on success
* NULL on failure
*/
event_handle_t events_init_subscriber(bool use_cache=false,
const event_subscribe_sources_t *sources=NULL);
/*
* De-init/free the subscriber
*
* Input:
* Handle returned from events_init_subscriber
*
* Output:
* None
*/
void events_deinit_subscriber(event_handle_t &handle);
/*
* Received event as JSON string as
* < YANG path of schema >: {
* event_params_t
* }
*/
typedef std::string event_str_t;
/*
* Receive an event.
* A blocking call.
*
* This API maintains an last received sequence number and use the received
* sequence in event to compute missed events count per publisher instance.
*
* input:
* handle - As obtained from events_init_subscriber
*
* output:
* event - Received event.
*
* missed_cnt:
* Count of missed events from this sender, before this event. Sum of
* missed count from all received events will give the total missed.
*/
int missed_cnt;
*
* return:
* 0 - On success
* -1 - On failure. The handle is not valid.
*
*/
int event_receive(event_handle_t handle, event_str_t &event, int &missed_cnt);
The event detection could happen in many ways
- Update the code to directly invoke Event publisher, which will stream it out.
- Run a periodic check (via monit/cron/daemon/...) to identify an event and raise it via event publisher
- Watch syslog messages for specific pattern; Upon match parse the required data out and call event publisher.
- Any other means of getting alerted on an event
- This is the preferred approach.
- Use the API for event publishing.
- This method is used in all SONiC owned code.
- Direct publishing from run time is the most efficient way for performance & resource usage.
- A code update could take months to get into production.
At high level:
- This is a two step process.
- The process raising the event sends a sylog message out.
- A watcher scans all the syslog messages emitted and parse/check for events of interest.
- When matching message arrives, publish the event
Here you have code that sends the log and a watcher who has the regex pattern for that log message to match. Anytime the log messsage is changed the pattern has to be updated for the event to fire consistently across releases.
Though this sounds like a redundant/roundabout way, this helps as below.
- For III party code, not owned by SONiC, this is an acceptable solution.
- A new event addition could be as simple as copying couple of small files to a switch and a rsyslog/container restart.
- For code that SONiC own, a code update would take in the order of months to reach thousands of switches, but this approach can be applied instantly to every switch
-
A rsyslog plugin is provided to raise events by parsing log messages.
-
Configure the rsyslog plugin with rsyslog via .conf file.
- For logs raised by host processes, configure this plugin at host.
- For logs raised by processes inside the container, configure plugin inside the container. This helps in container upgrade scenarios and as well help with load distribution.
- The plugin can be configured using rsyslog properties to help scale into multiple instances, so a single instance see only a subset of logs pre-filtered by rsyslog.
- A plugin instance could receive messasges only for processes that it is configured for.
-
The plugin is provided with the list of regex patterns to use for matching messages. Each pattern is associated with the name of event source and the tag.
- The regex pattern is present as files as one per plugin instance, so an instance sees only the regex expressions that it could match.
- For messages that match a pattern, retrieve parameters of interest per regex and fire event using event publisher API.
- The plugin calls the event publishing API with event source & tag from matching regex and data parsed out from message.
- The regex files carry ".reg" extension
-
rsyslog service update
- Copy the .conf & .reg files into /etc/rsyslog.d/
- Restart rsyslog service
- The plugin instances are invoked upon first message
- Each instance is fed with messages that are configured for that instance
- An instance running in BGP container can be configured to receive messages from bgpd process only. There can be another instance for messages from bgpcfgd.
-
[ TODO: Provide a PR link for a use case, say BGP here, as reference ]

- This support is external to app, hence adapts well with III party applications, bgp, teamd, ...
- As this needs just copying couple of files & restarting rsyslog only, new events can be added to switches in production via a simple script. A tool can scan for all target switches & update transparently.
- Two step process for devs. For each new/updated log message for an event in the code, remember to add/update regex as needed.
- Events are published from multiple publishers to multiple receivers.
- The publishers and receivers run in host and containers.
- The publishers should never be blocked.
- A receiver should be transparent to all publishers and vice versa
- A slow receiver should not impact either other receivers or publishers.
- The receivers should be able to learn the count of messages they have missed to receive.
- The receivers & publishers could go down and come up anytime.
- Use ZMQ PUB/SUB for publish & subscribe.
- To help with complete transparency across publishers & receivers, run a central ZMQ proxy with XPUB/XSUB.
- The proxy binds to PUB/SUB end points.
- The publishers & receivers connect to SUB & PUB end points respectively.
- Run the zmq proxy service in a dedicated eventd container.
- The systemd ensures the availability of eventd container.
- The publishers and subscribers connect to the always available, single instance ZMQ proxy.
- This proxy could transparently feed every messages to a side-car component.
- Run the events-cache service as a side component.
- All the zmq paths' defaults are hardcoded in the libswsscommon lib as part of APIs code.
- These can be overridden with config from /etc/sonic/init_cfg.json
- The publish API adds a sequence number as string, which is internal between publish & receive APIs and the cache service.
- The receiver API:
- Reads & returns one event at a time, in blocking mode.
- The serquence number is provided to caller as separate param
- The caller may use it to look up for duplicates from cache.
- This is a singleton service that runs in eventd container.
- It has access to all messages received by zmq proxy via an internal listener tied to the proxy.
- The caching is started/stopped transparently via init/de-init subscriber API, if cache-use is enabled by caller.
- When started all events are cached. Upon cache overflow, the events are dropped and count as missed.
- The cache service uses ZMQ REQ/REP pattern for communication w.r.t start/stop and replying with cached data.
- The receive API will transparently read off of cache, if cache is enabled by the caller.
The telemetry container runs gNMI server service to export events to gNMI clients via subscribe command.
- Telemetry container hosts gNMI server for streaming events to external receivers.
- The external client subscribe and receive events via gNMI connection/protocol.
- Only one client is accepted; The client is provided with all events.
- A local listener is spawned to receive events at the max rate of 10K/sec.
- The received events are sent to the connected client at the client's rate.
- Any overflow due to back-pressure/rate-limit results in events drop.
- Uses cache service transparently by enabling via init call.
- Any receiver disconnect or planned telemetry down will trigger the cache service to cache events.
- The events receive will transparently read off of cache, when cache is available.
-
Use SUBSCRIBE request
- Use paths as
- "/events" to receive all events.
- Subscribe options
- Target = EVENTS
- Mode = STREAM
- StreamMode: OnChange
- Updates_only = True
- Sample: subscribe:{prefix:{target:"EVENTS"} subscription:{path:{element:"events" } mode:ON_CHANGE}}
- Use paths as
-
The gnMI o/p is prefixed with YANG path for corresponding schema.
gnmic --target events --path "/events/" --mode STREAM --stream-mode ON_CHANGE
o/p
{
"sonic-events-bgp:bgp-state": {
"timestamp": "2022-08-17T02:39:21.286611Z",
"ip": "100.126.188.90",
"status": "down"
}
}
{
"sonic-events-bgp:bgp-state": {
"timestamp": "2022-08-17T02:46:42.615668Z",
"ip": "100.126.188.90",
"status": "up"
}
}
The message reliability is ensured as BEST effort. There are 3 kinds of missed message scenarios.
- A slow receiver that reaches overflow state causes drop of events. This is tracked as explicit drop count.
- Longer downtime of main receiver/telemetry service, could cause cache overflow and hence the drop. This is another explicit drop count.
- The internal listener for published events missed to receive an event. The missing is transparent to receiver.
- This could be due to one/more publishers publishing at a combined rate going above 10K/second.
- The eventd service is down.
- An overloaded internal control plane state making the local listener for events running too slow.
- This is computed using internal sequence number embedded in the message. This is implementation dependent and computed by receiving API.
- The cumulative count of all missed messages are tracked in STATE-DB.
- Expect the receiver do the rate-limnit.
- The telemetry service uses an internal buffer to cache upon back pressure and any overflow will cause message drop.
-
The events cache service is tapped transparently in two scenarios
- The time duration between gNMI server disconnect & re-connect.
- The planned service downtime for telemetry container.
-
The events cache service is enabled via a flag in init API. A corresponding deinit call will start the cache service until the next init call.
- This implies, a service crash will not start the cache, as it may not call deinit.
-
Upon gNMI main-receiver re-connect, the receive API will return the events from cache, and switch to subscription channel upon clearing the cache.
The stats are collected and updaed periodically in DB. The stats can be used to assess the performance and SLA (Service Level Agreement) compliance.
The stats are collected by telemetry service that serves the main receiver. Hence the stats update occur only when main receiver is connected.
- The counters are persisted in STATE-DB with keys as "EVENT-STATS|< counter name >"
- The counters are cumulative.
- The counters lifetime is tied with lifetime of STATE-DB.
- The telemetry supports streaming of EVENT-STATS table ON-CHANGE in streaming mode.
- The counters are updated periodically as every M seconds, where defaulted value M can be overridden by init-cfg.json config.
-
published-cnt
- The count of all events sent to the external gNMI receiver. In other words count of events the main receiver is expected to receive.
- This would not include count missed.
-
missed-slow-receiver:
- The count of events dropped due to internal buffer overflow caused by slow receiver.
-
missed-offline-state:
- An extended downtime of either main receiver or telemetry service, can result in offline cache overflow.
-
missed-internal
- missed by local listener from local publishers. An internal drop between local publishers & listener inside SONiC switch.
- This may be due to either one or more publishers publishing at excessively high rate or control plane pressure indirectly causing slow down at listener or the eventd service is down.
-
Latency
- Computed as < timestamp of write into main receiver's gNMI channel > - < timestamp in the event as inserted by publisher >
- The latency of last N events published to external receiver is maintained as a moving window.
- Average value from the window
- Show commands is provided to vew STATS collected
Refer PR #10801 for set of YANG models defined for identified events.
Tests are critical to have static events staying static across releases and ensuring the processes indeed fire those events in every release.
- Each event is covered by Unit test & nightly test
- Unit test -- For ||| party code that raises events based on log messages, have hard coded log message and run it by rsyslog plugin binary with current regex list in the source and validate the o/p reported against schema. This ensures the data fired is per schema.
- Unit test -- For events reported by code, mock it as needed to exercise the code that raises the event. Verify the received event data against the schema.
- Nightly test: For each event, hardcode the sample event data and validate against the schema. This is additional layer of protection to validate the immutability of the schema.
- Nightly test -- For each event simulate the scenario for the event, look for the event raised by process and validate the event reported against the schema. This may not be able to cover every event, but unit tests can.
The following are under brainstorming for possible future implementations.
- The publishers specify event source & type as strings. e.g. "sonic-events-bgp" and "bgp-state".
- To avoid publishers making mistakes in the strings or publish an event w/o yang model, create these strings as constants for "c++" & "python".
- These constants can be created at compile time from YANG schema.
- The code could be forced to use these constants instead of literal strings.
- Sample:
sonic_events_bgp.h
namespace SONIC_EVENTS_BGP {
const string name = “sonic-events-bgp”;
namespace BGP_STATE {
const string name =”bgp-state”;
const string IP = “ip”;
const string STATUS = “status”;
}
}
- New events could be identified after an image release.
- These could be captured via rsyslog plugin approach, by adding/updating a regex file & plugin.conf file at host and restart of rsyslog service.
- These new regex expressions could be pushed via incremental config update with no impact to dataplane.
- These pushed updates could be transparently absorbed and would result in publishing of new events.
- In short, a new event could be added via config push.
- The consumer of events get the instance data of event as a key-value pair, where key points to the YANG model.
- The YANG schema defintion could be enhanced with additional custom data types created using YANG extensions.
- An extension could be defined for "severity". The developer of the schema could use this to specify the severity of an event added.
- An extension could be defined for globally unique event-id, which could be used by event consumer, when publishing the event to external parties.