Objective:
To know the inside of Kafka clients.
-
Publish/Subscribe Messaging
- Pub/Sub pattern is characterized by the sender not specifically directing it to a receiver
- A lot of 1:1 connections make a system harder to trace
-
Message
- Unit of data within Kafka
-
Batch
-
A collections of messages
-
The larger the batches, the more messages that can be handled per unit of time
(Tradeoff b/w latency and throughput)
-
-
Schema
- A type of message content
- e.g. Json, xml, avro, …
-
Topic
-
Category of messages
-
Topics are broken down into a number of partitions
(Each partition can be hosted on a different server)
-
-
Kafka clients
- users of the system
- Producer
- creates new messages
- A message is produced to a specific topic
- Consumer
- reads messages
- uses offset of messages to keep track of the messages
- Consumers work as part of a consumer group
- The group assures that each partition is only consumed by one member
-
Broker
-
a single Kafka server
-
receives messages from producers
→ assigns offsets to them
→ commits the messages to storage on disk
→ responds to fetch requests from consumers
-
-
Overview
- Starts with generating an instance of
ProducerRecord- target topic and value are necessary
- key and target partition are optional
- Call
Send()API- serializes the data to byte array
Partitionerdecides a target partition to send- adds a record to a batch of records that will also be sent to a same topic and partition
- Another separate thread sends the batch to a Broker
- Starts with generating an instance of
-
Constructing a Kafka Producer
- Three mandatory properties
- bootstrap.servers
- lists of
host:portof broker - no need to know the whole lists
- lists of
- key.serializer
- value.serializer
- bootstrap.servers
- Three mandatory properties
-
Three primary methods of sending messages
- Fire and forget → Don’t care whether the message successfully arrives or not
- Synchronous send → Wait until the message arrives or not
- Asynchronous send → Use callback function, which is triggered when it receives a response from a Broker
-
Sending a message synchronously
- A thread must wait until it gets response from a broker
⇒ not common
-
Sending a message asynchronously
-
can use a callback method to handle errors from a broker
→ implement
org.apache.kafka.clients.producer.Callback→ pass the implementation to
send()method
-
-
Configuring Producers
-
client.id
⇒ to distinguish producers
-
acks
⇒ determine the number of partition replica that receives the record
acks=0: Don’t care whether any replica receives the record or notacks=1: Count as success when the a leader replica receives the recordacks=all: Count as success when all in-sync replicas receive the record
-
message delivery time
- two sections of it
- calling of send() ~ returning of result
- returning of result ~ call of callback
-
max.block.ms: Determines maximum time that the producer can be blocked -
delivery.timeout.ms: Determines maximum time between after returning of send() and before receiving a response from a broker→ delivery.timeout.ms ≥ linger.ms + request.timeout.ms
-
request.timeout.ms: Determines maximum time to wait the response from the broker -
retries: Determines maximum number to retry sending to the broker -
retry.backoff.ms: Determines waiting time between retries -
linger.ms: Determines waiting time before sending the batch -
buffer.memory: Determines maximum size of memory of waiting buffer -
batch.size: Determines the size (byte) of batch -
max.in.flight.requests.per.connection: Determines the maximum number of messages that can be sent even before receiving a response from a broker -
enable.idempotence=true: Guarantees the idempotence of recordsmax.in.flight.requests.per.connection≤ 5retries≥ 1acks = all
- two sections of it
-
-
Partition
- If key is null, pick random partition, which is available now
- If there is a key, default partitioner uses hash of key to pick a specific partition
- same key → same partition
- but, when we increase the number of partition, it can not be guaranteed
- Keep balance with round robin algorithm
- We can use custom partitioner by implementing
org.apache.kafka.clients.producer.Partitioner
-
Interceptor
- make it possible to add some features without modifying client codes
ProducerInterceptor.onSend→ Called just before serializationProducerInterceptor.onAcknowledgement→ Called after the producer receives a response from a broker


-
Concept
-
Consumer & Consumer Group
- Consumer is a part of Consumer Group
- Each consumer fetches its own partition
- Rule of assigning the partition → Implementation of
PartitionAssignor
- Rule of assigning the partition → Implementation of
- If # of consumers > # of partitions → there are idle consumers
- Different consumer groups read all messages of topic independently from each other
-
Consumer Group & Partition Rebalance
- When does rebalance occur?
- New consumer added to the group
- Topic changed (Partition added)
⇒ Reassign a partition to another consumer
-
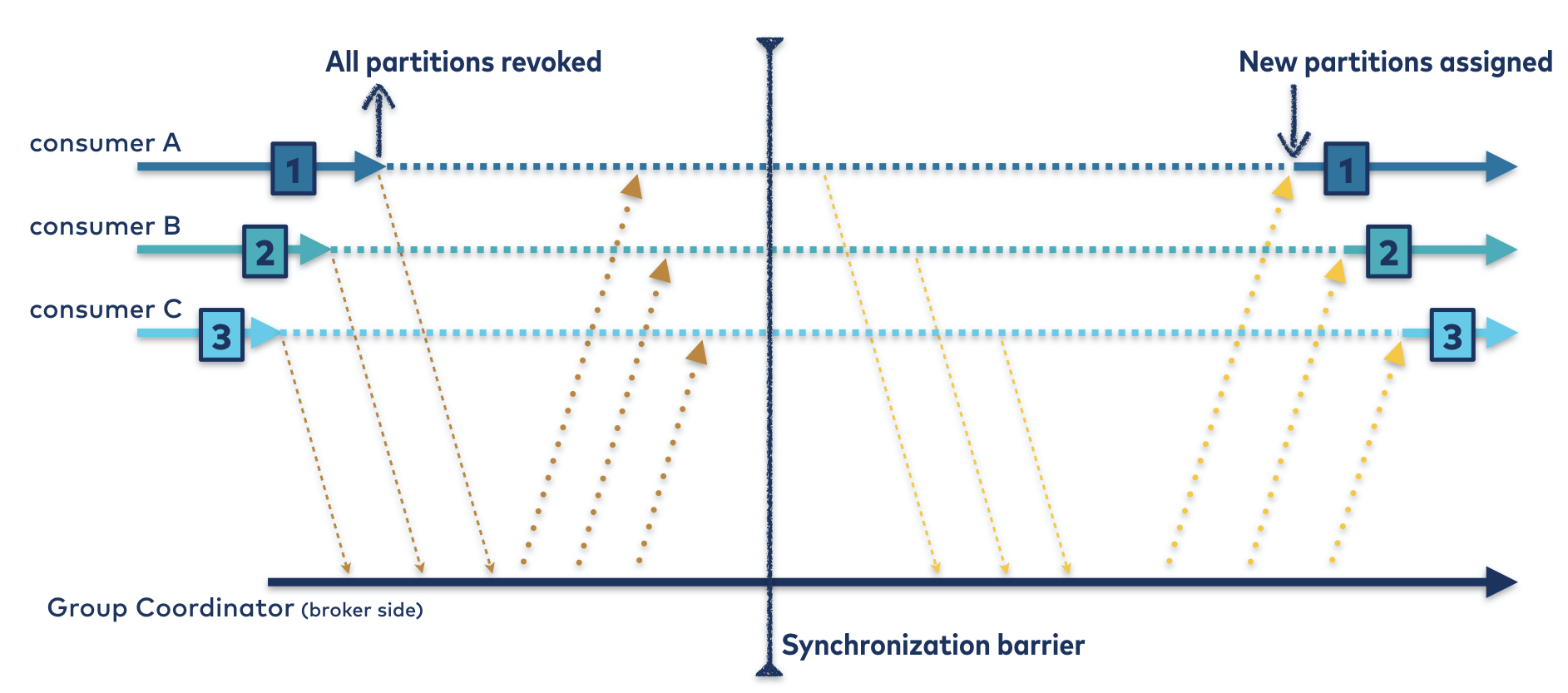
Eager Rebalance (Default before ver 2.4)
- When the rebalance starts, all consumers stop reading, relinquish its ownership on the partition, rejoin to the group, and are assigned to a new partition
- Causes Stop-The-World
-
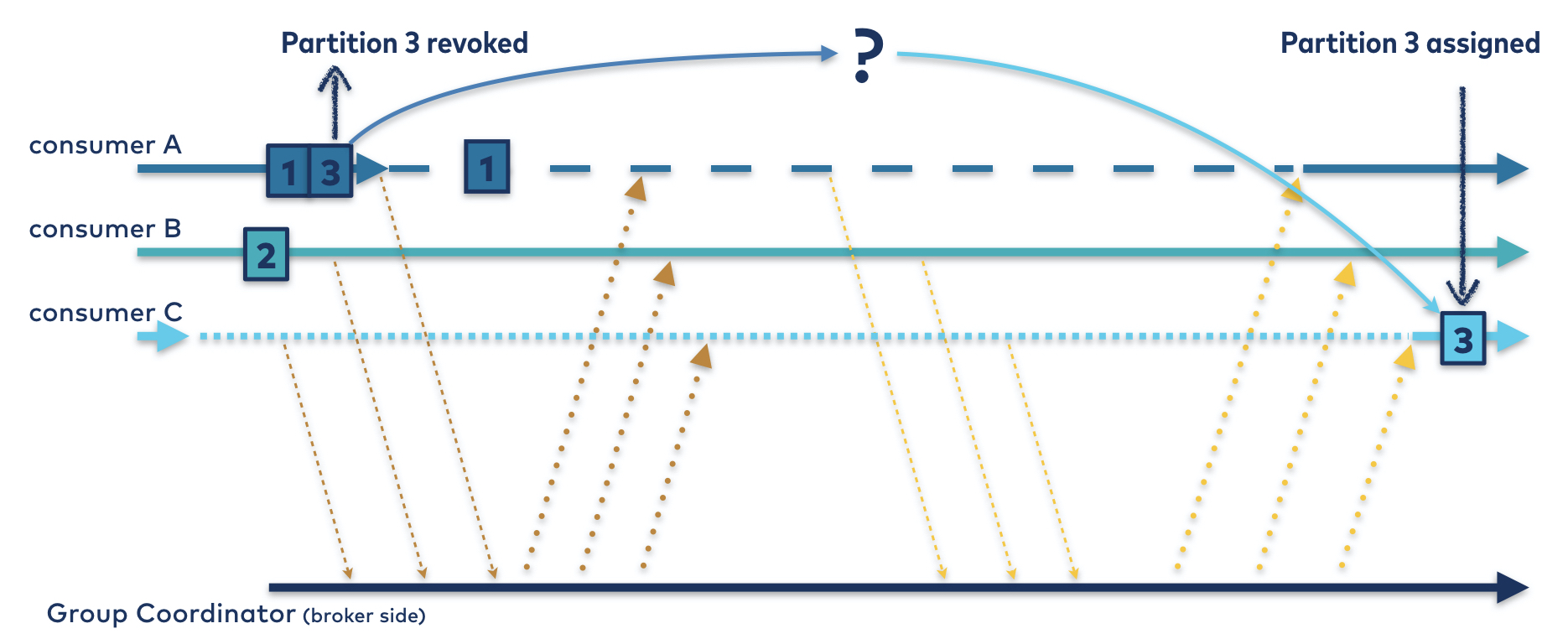
Cooperative Rebalance (Default after ver 3.1)
- Consumer Group Leader picks the partitions, which need to be reassigned
- Only consumers related to reassignment target partitions relinquish its ownership and are assigned to a new partition
- When does rebalance occur?
-
-
Consumer can read various topics (more than one)
-
Polling Loop
consumer.poll(timeout)timeout→ maximum time of blocking when there is no data in consumer buffer
- When a consumer first calls
poll()→ Find GroupCoordinator, participate in to the group, and is assigned to a partition - If
poll()is not called formax.poll.interval.ms→ Consider this consumer dead
-
One Consumer, One Thread
- Using multi-thread to process the messages → refer https://www.confluent.io/blog/kafka-consumer-multi-threaded-messaging/
-
Configuring Consumers
-
fetch.min.bytes→ Minimum byte size of fetching records (If a size of records is less than this, it waits) -
fetch.max.wait.ms→ Maximum time to wait fetching -
fetch.max.bytes→ Maximum byte size of fetching records (considering memory of client server)- but, if the batch from broker exceeds this value, broker ignores this value and send the records
-
max.poll.records→ Maximum number of records per polling -
session.timeout.ms→ Maximum time the group coordinator considers the consumer dead when no heartbeat comes from the consumer -
heartbeat.interval.ms→ Time of iteration of sending heartbeat -
max.poll.interval.ms→ Maximum time the group coordinator considers the consumer dead when no polling comes from the consumer -
request.timeout.ms→ Maximum time that consumer waits response from a broker -
auto.offset.reset→ latest (default): If there is no valid offset, consumer reads from the latest
→ earliest (default): If there is no valid offset, consumer reads from the earliest
-
enable.auto.commit→ Determine whether the consumer commits offset automatically or manually (default: true) -
partition.assignment.strategy → Determine partition assignment strategy
- Range / RoundRobin / Sticky / Cooperative Sticky
-
-
Offset & Commit
-
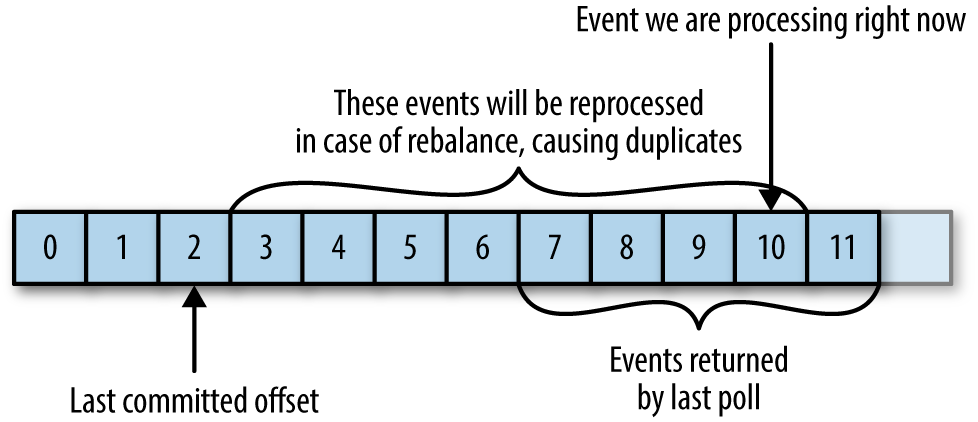
Offset Commit → update current cursor in the partition
- it commits the last message, not separately
- After rebalance, the consumer starts reading from the last committed offset
-
Automatic Commit
-
Every
auto.commit.interval.ms, consumer commits the offset of the last message -
There is a chance to find duplicated consuming
-
-
Commit Current Offset
- To reduce the number of duplicated message caused by rebalancing, we want to control the time to commit
commitSync()→ commits the last offset when polling is successful- if
commitSync()called before processing is done to prevent duplicated consuming, there is a chance to find message loss
-
Asynchronous Commit
- Manual commit blocks the application until a consumer receives a response from a broker
- To avoid the blocking, we can use
commitAsync() commitAsync()does not retry
-
Combining Synchronous and Asynchronous Commits
- To make consuming robust, we can call both before consumer closes
-
Committing a Specified Offset
commitSync(currentOffsets)orcommitSync(currentOffsets)
-
-
Rebalance Listener
-
We can use callback methods to execute when the consumer is about to close or the rebalancing is about to start →
ConsumerRebalanceListener -
onPartitionAssigned→ After a partition is reassigned and before a consumer starts to read message from the partition -
onPartitionRevoked→ After a partition is unassigned from a consumer(At here, the offset should be committed)
-
onPartitionsLost→ On exceptional rebalancing situation that a given partition is already assigned to another consumer
-
-
Consuming Records with Specific Offsets
seekToBeginning→ From the first offsetseekToEnd→ From the last offsetseek→ Find specific offset
- Cluster Membership
- Utilize Apache Zookeeper to keep the list of brokers
- Controller
- one broker in a cluster acts as a controller
- In charge of electing the leader of partition
- When the controller realizes any broker has left the cluster, it assigns new brokers to partitions that the broker was assigned as a leader
- Replication
- Essence of kafka architecture
- Leader Replica
- Write request is given to the leader
- Follower Replica
- replicates new messages from leader
- Follower replicas send read requests to a leader to sync with the leader
- gets the messages with offsets and also in order
- If a follower replica does not send any read request for 10s → consider it as out-of-sync replica
- opposite is in-sync replica
- Request Processing
- Clients know where to request by fetching metadata
- includes lists of topics, number of partitions, information of replicas, which is a leader, …
- Directly read or write the messages using above information (cached)
- Write request
- Consumers (clients) only can read the messages, which are written successfully in all in-sync replicas
- Clients know where to request by fetching metadata
- Physical Storage
- Default unit is a partition replica
- Partition Assignment
- Distribute replicas uniformly through brokers
- Each replica in a same partition should be assigned to different brokers
- File Management
- we can set retention period of each topic
- Kafka doesn’t store data ‘eternally’ and also doesn’t wait for consumers to read before deleting
- we can set retention period of each topic
- Uses index to search messages with specific offsets
- maps offsets to locations in the storage
- What does kafka guarantee?
- Order of messages in the same partition
- It considers a message as committed when the message is written in all ISR
- Committed message would not be lost if there is at least one alive replica
- Consumer only can read the committed message
- Replication
- All messages are written to a leader replica, and usually are read from the leader
replication.factor- number of replication for a topic
- needs to consider below factors
- availability → more replications, higher availability
- durability → more replications, higher durability
- throughput → more replications, lower throughput
- latency → more replications, higher latency
- cost → more replications, higher cost
unclean.leader.election.enable- option for whether to elect a new leader from out-of-sync replicas
- when all replicas are shut down
- default is
false - if
false- producer should wait until the leader is recovered
- if
true- the replica that recovered the fastest is elected as a leader
- can make message loss and break consistency
- option for whether to elect a new leader from out-of-sync replicas
min.insync.replicas- determines minimum number of in-sync-replica to consider a message as committed
- We can control a tradeoff b/w reliability and performance for each topic
- Reliability on producer
- use proper
acksconfiguration (acks=1oracks=all) - need to handle error responses from a broker (leader)
- use proper
- Reliability on consumer
- check
auto.offset.reset - use proper
enable.auto.commit,auto.commit.interval.ms
- check
- Consists of two key features; Idempotent producer and Transaction
- Idempotent producer (
enable.idempotence=true)- Every message has its own Producer ID and Sequence ID
- Producer ID + Sequence ID = UID in a specific topic of a partition
- If a broker receives a message, which is processed already (can be recognized by above UID), it makes an error
- If a broker receives a message, which has a larger Sequence ID than expected, it also makes an error
- Without Transaction feature, when a producer is initialized, it gets a new Producer ID, which is generated from a broker
- Leader replica has recent 5 Sequence IDs of messages in memory
- and follower replicas not only sync messages but also update those IDs
- limitations
- it only prevents replication caused by producer’s internal logic
- If we call
producer.send()with same message, it makes replication
- Transaction
-
This is feature is for Kafka Streams
e.g. Read Topic → Processing → Publish Topic
-
Need to consider isolation level of consumer (
isolation.level)
-
- Mirroring
- data replication b/w clusters
- Need to consider some trade-offs
- High latency
- Limited bandwidth
- Higher cost
- Architectures
-
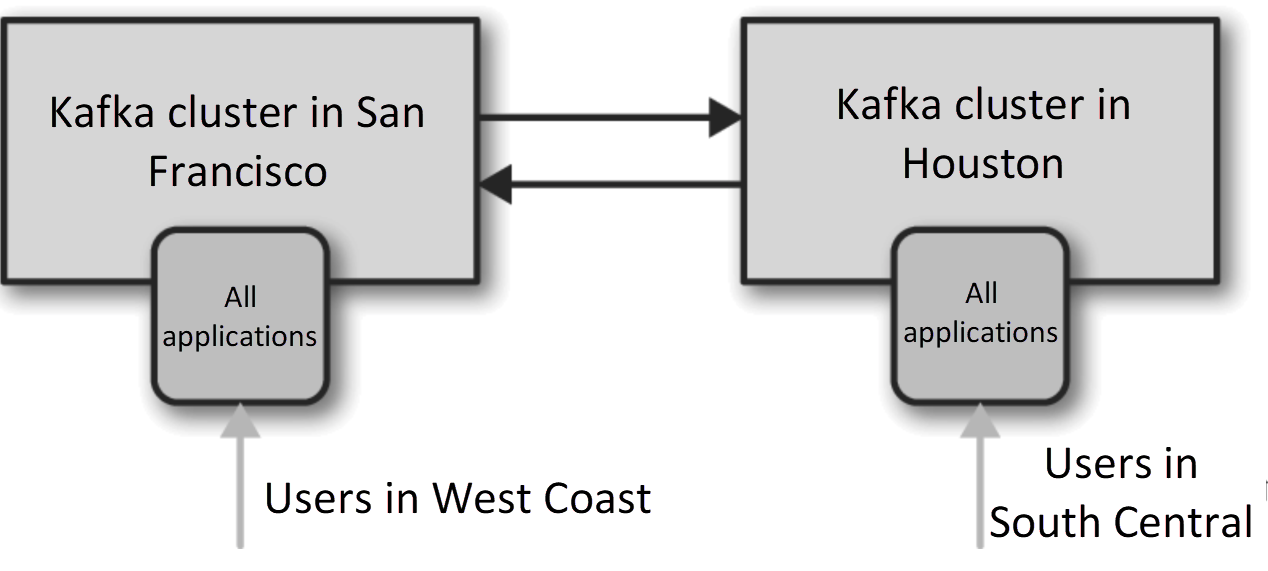
Hub-and-Spokes Architecture
- Applications are only able to use data stored in a same data center
-
Active-Active Architecture
- mirrors each other
- difficult to avoid read/write crash
-
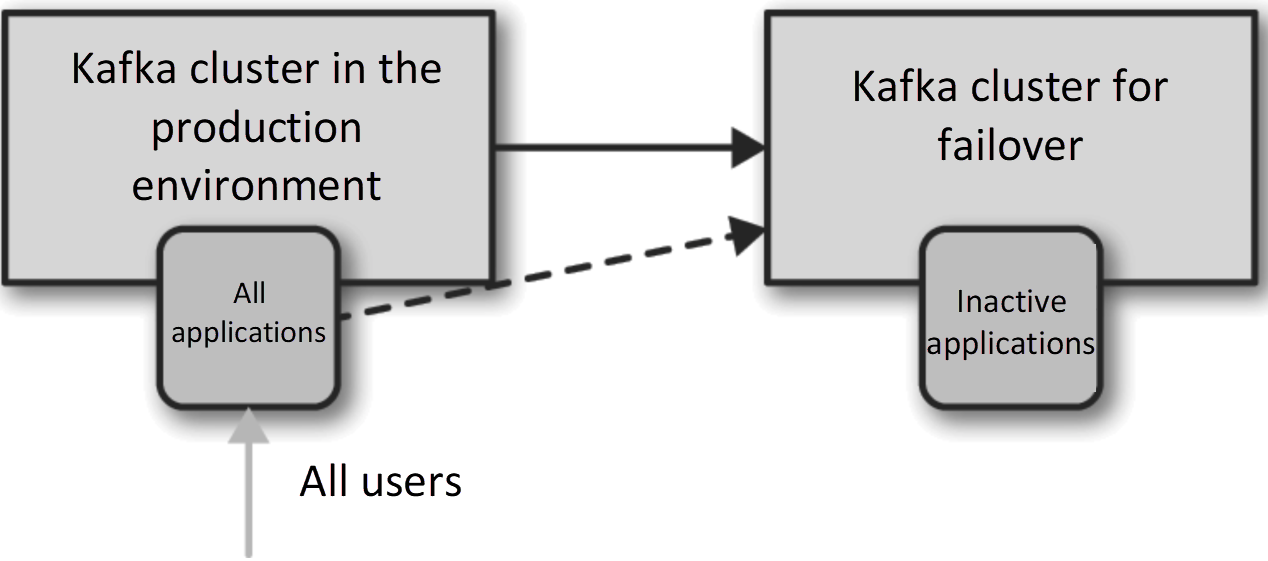
Active-Standby Architecture
- Only for failover
- Mirrors active cluster
- Inactive cluster is usually called as disaster recovery cluster
- Mirroring is usually asynchronous → DR cluster does not have the newest messages
- Determine from which offset to start reading
- offset topic replication
- timestamp-based recovery
- offset transformation
-
- Kafka Producer Client [http://117.52.129.49/helloworld/6560422]
- Three parts: KafkaProducer, RecordAccumulator, Sender
- KafkaProducer ->
send()- can pass callback method
- execute Serialization, Partitioning, Compression
- If there is no given partitioner, it uses DefaultPartitioner
- has key ⇒ key → hash → choose partition
- no key ⇒ round-robin → choose partition
- RecordAccumulator
- saves records from
KafkaProducer.send()→RecordAccumulator.append() - manages records with a data structure,
batches<TopicPartition, Deque<RecordBatch>>- to prevent concurrency issue, it uses
ConcurrentMap
- to prevent concurrency issue, it uses
- when it is called with append() method, it finds Deque with TopicPartition Key
- and check a size of last
RecordBatch - if there is a room, use it
- if not, create a new
RecordBatch
- and check a size of last
- If there is no room of
BufferPoolwhen it wants to make a newRecordBatch, it should wait until some ofBufferPoolget free (maximum ismax.block.ms)
- saves records from
- Sender
- uses another thread
- sends records in RecordAccumulator
- uses drain() method to get targets (
Deque<RecordBatch>)
- Kafka Consumer Client [https://d2.naver.com/helloworld/0974525]
- ConsumerNetworkClient
- communicates with broker asynchronously using NetworkClient
- SubscriptionState
- manages consuming topics, partitions, offsets
- ConsumerCoordinator
- in charge of rebalance, offset initialization, offset commit
- Fetcher
poll()call →Fetcher.sendFetches()- check nextInLineRecords and completedFetches (in cache)
- if there is nothing in there, call
sendFetches()to get records
- if there is nothing in there, call
- ConsumerNetworkClient