[feat] Add support for nonlinear operations #27
Conversation
…n specific tiles.
…n a single node. e.g. division
| } | ||
| // for (int r=0; r<t_rows; ++r) { | ||
| // for (int c=0; c<t_columns; ++c) { | ||
| // nodes[r][c]->enableCall(); |
There was a problem hiding this comment.
This change is a bug fix, right? So from now on, call can only be supported if user specify it in the param.json or user needs to modify this CGRA.cpp file?
And is this call actually how is the lut is recognized? i.e., instead of support call, user provide the lut func that is actually called in the IR.
There was a problem hiding this comment.
Yes, call can only be supported if user specify. For lut, it should be writed as call-lut in param.json after I refactored the code.
| // for (int r=0; r<t_rows; ++r) { | ||
| // for (int c=0; c<t_columns; ++c) { | ||
| // // if(c == 0 || (r%2==1 and c%2 == 1)) | ||
| // nodes[r][c]->enableComplex(); | ||
| // } | ||
| // } |
There was a problem hiding this comment.
Means heterogeneity in the param.json won't take effect any more?
There was a problem hiding this comment.
No. Here I mean complex operations should be manually specified in the param.json rather than we configure it for the default.
|
Plz also resolve the conflict. Thanks! |
|
Thanks @HobbitQia, plz also put response for each of my comments and tag them as fixed/solved (if there is such tag). Thanks a lot! |
|
Can we include at least one .cpp that leverages your nonlinear_param.json for testing the new features? |
|
I included a For previous comments that I have solved (e.g. issues about comments, codes that should be deleted), I marked them as resolved. For other comments that I think we should discuss about, I responsed to them and didn't mark them. |
Thanks a lot Jiajun~! Let me know when you wanna set up meeting for discussion~ |
|
Glad to share my improvement in detail.
|
|
One more point: |
You mean empty string for
I really appreciate the contribution!
Sure, but this could be our future work in another PR when you have bandwidth. @cwz920716 Just FYI :-) Jiajun is one of the best students we have worked with :-) |
Yes, and actually there are many cases in I tried to test |
|
Then let's have |
.github/workflows/cmake.yml
Outdated
|
|
||
| - name: Test Idiv Feature | ||
| working-directory: ${{github.workspace}}/test | ||
| run: clang-12 -emit-llvm -O3 -fno-unroll-loops -fno-vectorize -o idiv_test.bc -c idiv_test.cpp && opt-12 -load ../build/src/libmapperPass.so -mapperPass idiv_test.bc | ||
| working-directory: ${{github.workspace}}/test/nonlinear_test |
|
A little strange...let me check it carefully |
No worry~ Thanks! |
|
Based on the error msg, seems failed at |
I found something strange...We used |
Seems some library missing: jupyter-xeus/xeus-cling#234 (comment)? Or you can try to use some C++ standard string write/read/stream functions to replace the LLVM |
It's hard to replace For now, I came up with a temporary method to remove
@tancheng WDYT? If the current solution is acceptable, I will push my changes to the current branch. |
|
|
|
There are still something buggy...I print the generated |
|
Thanks Jiajun. I saw the log and the .cpp is correctly mapped, but as you mentioned the .json is messed up. You are free to keep pushing commits to test/debug the github actions (via printing). Maybe the issue is the DFG's pointer is somehow freed before being stored? |
I tried to print the instructions and their opcodename within the function at the beginning of our pass, i.e., the start of The code that I changed for debugging in bool runOnFunction(Function &t_F) override {
// traverse all instructions in the function.
for (Function::iterator bb = t_F.begin(); bb != t_F.end(); ++bb)
for (BasicBlock::iterator i = bb->begin(); i != bb->end(); ++i) {
for (User::op_iterator op = i->op_begin(); op != i->op_end(); ++op) {
if (Instruction* inst = dyn_cast<Instruction>(*op)) {
errs() << "Instruction: " << *inst << "\n";
errs() << "opcodename" << inst->getOpcodeName() << "\n";
}
}
}
// Initializes input parameters.
int rows = 4
.... |
|
Hi @HobbitQia, thanks for the investigation. This seems the opcode issue across different platforms: https://stackoverflow.com/questions/48894012/what-is-getopcode-in-llvm A quick fix to walkaround this could be:
Then change |
Oh that's may be the reason...I agree with your walkaround and I will start to update the code immediately. |
|
To avoid unnecessary |
|
To achieve it, I think we must use |
|
How about sth like this then: if (I.getOpcode == llvm::Add) return "add";. Or |
Currently I try to get the operation names through the code like this The method of relying on inst: %4 = phi i64 [ 0, %2 ], [ %11, %3 ] opcode name: select
inst: %5 = getelementptr inbounds i32, i32* %0, i64 %4 opcode name: unknown
inst: %6 = bitcast i32* %5 to <4 x i32>* opcode name: unknown
inst: %7 = load <4 x i32>, <4 x i32>* %6, align 4, !tbaa !2 opcode name: getelementptr
inst: %8 = sdiv <4 x i32> %7, <i32 3, i32 3, i32 3, i32 3> opcode name: urem |
|
Is there a way to perform |
|
I am also okay with either:
|
Yes!!! I chose the first method and it seems everthing works well during testing of my repo. I will recheck it to ensure the correctness and later I will push to this branch. Thanks for your patient instructions! |
|
LGTM. Can I merge it now~? |
src/CGRANode.cpp
Outdated
| @@ -425,13 +425,11 @@ bool CGRANode::enableFunctionality(string t_func) { | |||
| string type; | |||
| if (t_func.length() == 4) type = "none"; | |||
There was a problem hiding this comment.
Can plz add comment about what does 4 mean here? Why is it specialized?
There was a problem hiding this comment.
4 is the length of call. Here I mean the paramter in param.json is call rather than call-.... For this case, I regard it as a function call without special type name.
There was a problem hiding this comment.
Sounds good. Plz just add this comment above. And refactor the code like:
const int kLengthOfCall = 4;
if (t_func.length() == kLengthOfCall) {
type = "none";
}
src/CGRANode.cpp
Outdated
| @@ -425,13 +425,11 @@ bool CGRANode::enableFunctionality(string t_func) { | |||
| string type; | |||
| if (t_func.length() == 4) type = "none"; | |||
| else type = t_func.substr(t_func.find("call") + 5); | |||
| cout << type << endl; | |||
| enableCall(type); | |||
| } else if (t_func.find("complex") != string::npos) { | |||
| string type; | |||
| if (t_func.length() == 7) type = "none"; | |||
There was a problem hiding this comment.
sry but I remembered deleteing these printing statements and this line has been removed from the code.
|
Currently I added a parameter
Sure. Thanks for your comments~ |
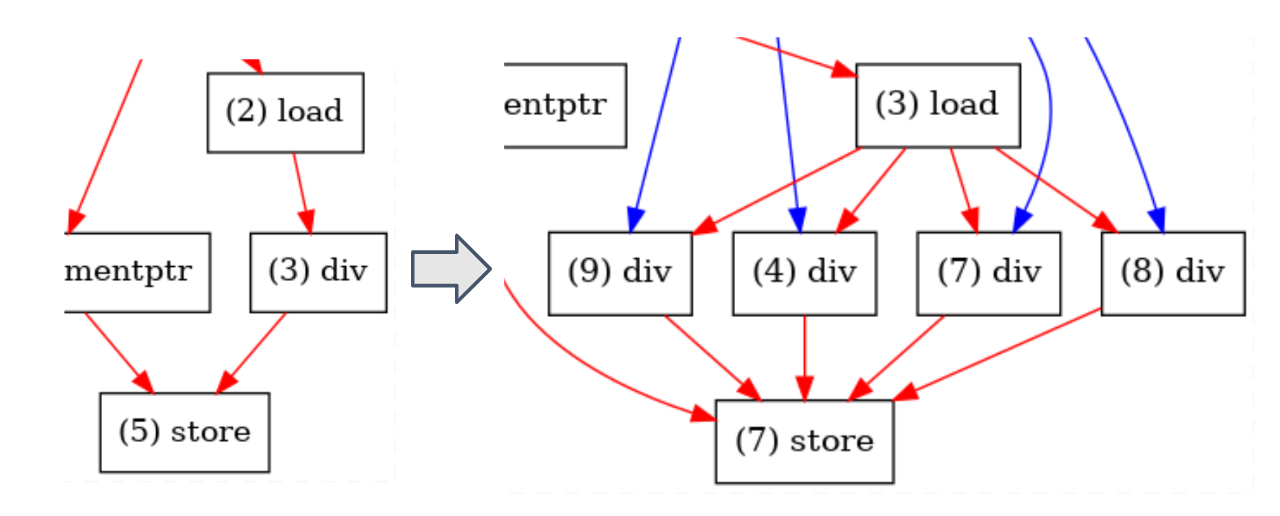
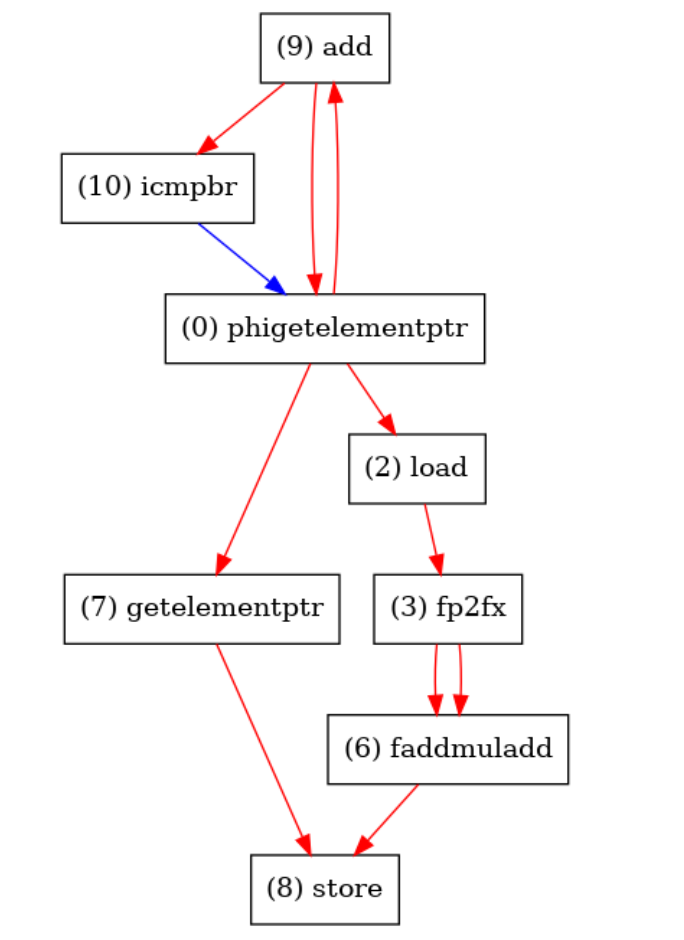
I'm so excited to share my updates on the mapper with you. The main changes are listed below:
DFG.cpp, I added a function callednonlinear_combine(), which will fuse the common patterns occurring in nonlinear operations.__attribute__((noinline)) DATA_TYPE lut(DATA_TYPE x) { ... }demangle(newName) == "lut(float)". We determine a DFG node which contains a special function throughDFGNode::getOpcodeName()and compare the operation name with names of predefined special functions. Details can be seen in DFG.cpp:408-432 andDFGNode::isLut(). l For CGRA mapping I also added special functions so that we can choose to configure a tile to equip with LUT/FP2FX or not. We can specify CGRA's nodes throughadditionalFuncinparam.json. Here's an example:DFGNode::isVectorized. However for divison we cannot vectorize it since it's hard to support efficient vector divisor from the hardware perspective. Thus I chose to split a divison nodes into multiple nodes and reconnect the precursors and successors inDFG::tuneDivPattern(). Notably, different vectorization factors will lead to different number of node (e.g. if VF=4 we should split a divison into 4 nodes) thus I added a parameter in theparams.jsonso that we can specify the VF (default to 1).param.json. Here's an example:Above are my main changes, along with some bug fixed. (sry that I cannot remember everything...)