事务是由单独单元的一个或多个SQL语句组成,在这 个单元中,每个MySQL语句是相互依赖的。
- 原子性(Atomicity): 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用,只有事务中的所有数据库操作都执行成功,才算整个事务都执行成功,事务中任何一个SQL瑜伽执行失败,已经执行成功的SQL语句也必须撤销,数据库状态回到执行事务之前的状态。
- 一致性(Consistency): 执行事务后,数据库从一个正确的状态变化到另一个正确的状态。在事务开始和事务结束之后,数据库的完整性约束没有被破坏。
- 隔离性(Isolation): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。
- 持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
- 脏读(Dirty read):就是指一个事务读到了另一个数据未提交的数据,由于这个数据还未提交,是脏数据,对其进行的任何操作都是不正确的;
- 不可重复读(Unrepeatableread):是指同一个事务在对记录连续读取的时候出现读取的信息不一致,由于在读的时候另一个时候对该记录进行了更改;
- 丢失修改(Lost to modify):丢失修改的原因也是由于一个事务在对某条记录进行更改时,另一个事务也对该记录进行了更改,导致前者的修改丢失。
- 幻读(Phantom read):幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
原子性、一致性、持久性通过数据库的redo log 和undo log来完成。
redo log叫做重做日志,用来保证事务的原子性和持久性。
undo log用来保证事务的原子性。
传统的UNIX实现的内核中都设置有缓冲区或者页面高速缓存,大多数磁盘IO都是通过缓冲写的。
当你想将数据write进文件时,内核通常会将该数据复制到其中一个缓冲区中,如果该缓冲没被写满的话,内核就不会把它放入到输出队列中。当这个缓冲区被写满或者内核想重用这个缓冲区时,才会将其排到输出队列中。等它到达等待队列首部时才会进行实际的IO操作。你可以回想一下你擅长使用的编程语言操作文件时,总会贴心的为你提供一个write()方法还有一个flush()方法。
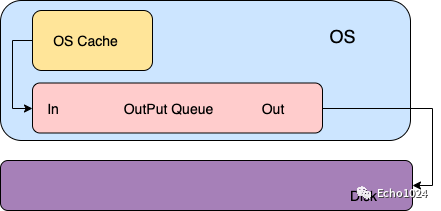
输出方式就是大家耳熟能详的:延迟写。
很明显、延迟写降低了磁盘读写的次数,但同时也降低了文件的更新速度。
这样当OS Crash时由于这种延迟写的机制可能会造成文件更新内容的丢失。而为了保证磁盘上的实际文件和缓冲区中的内容保持一致,UNIX系统提供了三个系统调用:sync、fsync、fdatasync
int sync();将所有修改过的缓冲区排入写队列,然后就返回了,它并不等实际的写磁盘的操作结束。所以它的返回并不能保证数据的安全性。通常会有一个update系统守护进程每隔30s调用一次sync。命令sync(1)也是调用sync函数。includeint fsync(int filedes):需要你在入参的位置上传递给他一个fd,然后系统调用就会对这个fd指向的文件起作用。fsync会确保一直到写磁盘操作结束才会返回,所以当你的程序使用这个函数并且它成功返回时,就说明数据肯定已经安全的落盘了。所以fsync适合数据库这种程序。int fdatasync(int filedes):和fsync类似但是它只会影响文件的一部分,因为除了文件中的数据之外,fsync还会同步文件的属性。
重做日志用来实现事务的持久性,由两部分组成:一是内存中的重做日志缓冲(redo log buffer),是易失的;二是重做日志文件(redo log file),其是持久的。InnoDB存储引擎通过Force Log at Commit 机制实现事务的持久性,当事务提交(COMMIT)时,必须先讲该事务的所有重做日志写入到重做日志文件进行持久化,等待事务COMMIT操作完成时才算完成。
每一次将重做日志缓冲写入重做日志文件后,InnoDB默认都会调用一次fsync操作,因为重做日志缓冲是先写入文件系统缓存,为了确保它写入磁盘,必须进行一次fsync操作,而fsync效率取决于磁盘,因而磁盘性能决定了事务提交的性能。用户可以手动设置非持久性,设置每次COMMIT后不马上执行fsync以提高数据库性能,这样事务提交时,日志不立即写入重做日志文件 ,而是等待一个周期时间后再执行fsync操作,此时若发生数据库宕机,会丢失最后一段时间的事务。
MySQL的二进制日志(binlog)用来进行POINT-TO-TIME(PIT)的恢复及主从复制环境的建立。与redo log区别很大。
- 二者的产生的地方不同,redo log在存储引擎层产生,而二进制日志在数据库的上层产生,且所有存储引擎对数据库的更改都会产生二进制日志。
- 两种日志记录的内容形式都不一样,binlog是一种逻辑日志,记录的是对应的sql语句。而innodb存储引擎的重做日志是物理格式日志,记录的是对于每个页的修改。
- 他们写入磁盘的时间点也不同。二进制日志只在事务提交完成后进行一次写入,而innodb存储引擎的重做日志在事务进行中不断被写入,不是随事务提交的顺序进行写入。
**log block:**重做日志大小为512字节进行存储。它们都是以块的形式进行保存的,称为重做日志块(redo log block),而磁盘扇区的大小一样,因此其写入可以保证原子性,不需要doublewrite技术。
重做日志缓存的结构如下图所示,log block由三部分组成,分别是日志头,日志内容,日志块尾。

重做日志文件(redo log file)中存储的即使之前在log buffer中保存的log block,因此其也是根据块的方式进行物理存储的管理。log buffer根据一定的规则将内存中的log blocks刷新到磁盘:
- 当事务提交时
- 当log buffer中有一半的内存空间已经被使用时
- log checkpoint时
log block的写入是追加到redo log file的最后的,当要了解诶对redo log file的写入并不是顺序的,因为它除了保存log block中的信息还保存了其他2KB大小的信息,共4个512字节的块,这些信息主要是用于存储引擎的恢复,如下图所示。

LSN是Log Seequence Number的缩写,代表的是日志序列号,占用8个字节,单调递增。表示的含义如下:
- 重做日志写入的总量;
- checkpoint的位置;
- 页的版本。
LSN不仅存在于redo log中,还存在于数据页中,在每个数据页的头部,有一个fil_page_lsn记录了当前页最终的LSN值是多少。通过数据页中的LSN值和redo log中的LSN值比较,如果页中的LSN值小于redo log中LSN值,则表示数据丢失了一部分,这时候可以通过redo log的记录来恢复到redo log中记录的LSN值时的状态。
InnoDB存储引擎在启动的时不管上次数据库运行时是否正常关闭,都会尝试进行恢复操作。物理日志的恢复速度比逻辑日志如二进制日志要快很多,同时InnoDB存储引擎对恢复做出了一定程度的优化,如顺序读取及并行应用重做日志。
innodb从执行修改语句开始:
- 首先修改内存中的数据页,并在数据页中记录LSN,暂且称之为data_in_buffer_lsn;
- 并且在修改数据页的同时(几乎是同时)向redo log in buffer中写入redo log,并记录下对应的LSN,暂且称之为redo_log_in_buffer_lsn;
- 写完buffer中的日志后,当触发了日志刷盘的几种规则时,会向redo log file on disk刷入重做日志,并在该文件中记下对应的LSN,暂且称之为redo_log_on_disk_lsn;
- 数据页不可能永远只停留在内存中,在某些情况下,会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
- 要记录checkpoint所在位置很快,只需简单的设置一个标志即可,但是刷数据页并不一定很快,例如这一次checkpoint要刷入的数据页非常多。也就是说要刷入所有的数据页需要一定的时间来完成,中途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
重启innodb时,checkpoint表示已经完整刷到磁盘上data page上的LSN,因此恢复时仅需要恢复从checkpoint开始的日志部分。例如,当数据库在上一次checkpoint的LSN为10000时宕机,且事务是已经提交过的状态。启动数据库时会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从检查点开始恢复。
还有一种情况,在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度。这时候一宕机,数据页中记录的LSN就会大于日志页中的LSN,在重启的恢复过程中会检查到这一情况,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
另外,事务日志具有幂等性,所以多次操作得到同一结果的行为在日志中只记录一次。而二进制日志不具有幂等性,多次操作会全部记录下来,在恢复的时候会多次执行二进制日志中的记录,速度就慢得多。例如,某记录中id初始值为2,通过update将值设置为了3,后来又设置成了2,在事务日志中记录的将是无变化的页,根本无需恢复;而二进制会记录下两次update操作,恢复时也将执行这两次update操作,速度比事务日志恢复更慢。
log buffer中未刷到磁盘的日志称为脏日志(dirty log)。
在上面的说过,默认情况下事务每次提交的时候都会刷事务日志到磁盘中,这是因为变量 innodb_flush_log_at_trx_commit 的值为1。但是innodb不仅仅只会在有commit动作后才会刷日志到磁盘,这只是innodb存储引擎刷日志的规则之一。
刷日志到磁盘有以下几种规则:
- 发出commit动作时。已经说明过,commit发出后是否刷日志由变量 innodb_flush_log_at_trx_commit 控制。
- 每秒刷一次。这个刷日志的频率由变量 innodb_flush_log_at_timeout 值决定,默认是1秒。要注意,这个刷日志频率和commit动作无关。
- 当log buffer中已经使用的内存超过一半时。
- 当有checkpoint时,checkpoint在一定程度上代表了刷到磁盘时日志所处的LSN位置。
undo log用来帮助事务回滚以及实现MVCC的功能。在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败或回滚了,可以借助该undo进行回滚。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。有时候应用到行版本控制的时候,也是通过undo log来实现的:当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
undo存放在数据库内部的一个特殊字段(segment)中,这个段称为undo段。undo用于将数据库逻辑地恢复到原来的样子!并不是物理地恢复到之心语句之前的或事物之前的样子,如果回滚到事物之前的样子,在并发的情况下会影响其他事务正在进行的事务。
重要的一点:undo log会产生redo log,也就是undo log 的产生会伴随着redo log的产生。
当用户读取一行记录的时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取。
innodb存储引擎对undo的管理采用段的方式。rollback segment称为回滚段,每个回滚段中有1024个undo log segment,每个undo log segment段中进行undo页的申请。
在以前老版本,只支持1个rollback segment,这样就只能记录1024个undo log segment。后来MySQL5.5可以支持128个rollback segment,即支持128*1024个undo操作,还可以通过变量 innodb_undo_logs (5.6版本以前该变量是 innodb_rollback_segments )自定义多少个rollback segment,默认值为128。
undo log默认存放在共享表空间中。

rollback segment中参数:
- innodb_undo_directory:设置rollback segment文件所在的路径,默认为'.',表示当前引擎的目录;
- innodb_undo_logs:用于设置rollback segment的个数,默认128;
- innodb_undo_tablespaces:用来设置构成rollback segment文件的数量,这样rollback segment就可以较为平均地分布在多个文件中;
当事务提交的时候,innodb不会立即删除undo log,因为后续还可能会用到undo log,如隔离级别为repeatable read时,事务读取的都是开启事务时的最新提交行版本,只要该事务不结束,该行版本就不能删除,即undo log不能删除。
但是在事务提交的时候,会将该事务对应的undo log放入到删除列表中,未来通过purge线程来删除。并且提交事务时,还会判断undo log分配的页是否可以重用,如果可以重用,则会分配给后面来的事务,避免为每个独立的事务分配独立的undo log页而浪费存储空间和性能。
通过undo log记录delete和update操作的结果发现:(insert操作无需分析,就是插入行而已)
- delete操作实际上不会直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成的。
- update分为两种情况:update的列是否是主键列。
- 如果不是主键列,在undo log中直接反向记录是如何update的。即update是直接进行的。
- 如果是主键列,update分两部执行:先删除该行,再插入一行目标行。
purge用于最终完成delete/update操作,因为innodb支持MVCC,在事务提交的时候其他事务可能正在引用这一行,故innodb需要保存记录之前的版本。若改行记录已经不被任何其他事务所引用,那么就可以进行真正的delete操作。
innodb中一个页上允许有多个事务的undo log存在,虽然不代表事务提交的顺序,但是后面事务产生的undo log总在最后,有一个history列表,他根据事务提交的顺序讲undo log进行连接,在执行purge的时候:
- innodb会先从history列表中找到第一个需要被执行清理的事务的记录,
- 清除成功之后就在该事务所在的undo log 所在页中继续寻找可以被清理的记录,因此会找到其他事务的undo log;
- 若某一个undo log还被其他事务引用,就重新回到history list中取找尾端的记录;
innodb存储引擎这种先到history list中查找undo log ,再从undo page中找undo log 的设计模式是为了避免大量的随机读取操作,从而提高purge的效率。
为了提高性能,通常会将有关联性的多个数据修改操作放在一个事务中,这样可以避免对每个修改操作都执行完整的持久化操作。这种方式,可以看作是人为的组提交(group commit)。
除了将多个操作组合在一个事务中,记录binlog的操作也可以按组的思想进行优化:将多个事务涉及到的binlog一次性flush,而不是每次flush一个binlog。
事务在提交的时候不仅会记录事务日志,还会记录二进制日志,但是它们谁先记录呢?二进制日志是MySQL的上层日志,先于存储引擎的事务日志被写入。
在MySQL5.6以前,当事务提交(即发出commit指令)后,MySQL接收到该信号进入commit prepare阶段;进入prepare阶段后,立即写内存中的二进制日志,写完内存中的二进制日志后就相当于确定了commit操作;然后开始写内存中的事务日志;最后将二进制日志和事务日志刷盘,它们如何刷盘,分别由变量 sync_binlog 和 innodb_flush_log_at_trx_commit 控制。
但因为要保证二进制日志和事务日志的一致性,在提交后的prepare阶段会启用一个prepare_commit_mutex锁来保证它们的顺序性和一致性。但这样会导致开启二进制日志后group commmit失效,特别是在主从复制结构中,几乎都会开启二进制日志。
在MySQL5.6中进行了改进。提交事务时,在存储引擎层的上一层结构中会将事务按序放入一个队列,队列中的第一个事务称为leader,其他事务称为follower,leader控制着follower的行为。虽然顺序还是一样先刷二进制,再刷事务日志,但是机制完全改变了:删除了原来的prepare_commit_mutex行为,也能保证即使开启了二进制日志,group commit也是有效的。
MySQL5.6中分为3个步骤:flush阶段、sync阶段、commit阶段。
- flush阶段:向内存中写入每个事务的二进制日志。
- sync阶段:将内存中的二进制日志刷盘。若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的刷盘操作。这在MySQL5.6中称为BLGC(binary log group commit)。
- commit阶段:leader根据顺序调用存储引擎层事务的提交,由于innodb本就支持group commit,所以解决了因为锁 prepare_commit_mutex 而导致的group commit失效问题。
在flush阶段写入二进制日志到内存中,但是不是写完就进入sync阶段的,而是要等待一定的时间,多积累几个事务的binlog一起进入sync阶段,等待时间由变量 binlog_max_flush_queue_time 决定,默认值为0表示不等待直接进入sync,设置该变量为一个大于0的值的好处是group中的事务多了,性能会好一些,但是这样会导致事务的响应时间变慢,所以建议不要修改该变量的值,除非事务量非常多并且不断的在写入和更新。
进入到sync阶段,会将binlog从内存中刷入到磁盘,刷入的数量和单独的二进制日志刷盘一样,由变量 sync_binlog 控制。
当有一组事务在进行commit阶段时,其他新事务可以进行flush阶段,它们本就不会相互阻塞,所以group commit会不断生效。当然,group commit的性能和队列中的事务数量有关,如果每次队列中只有1个事务,那么group commit和单独的commit没什么区别,当队列中事务越来越多时,即提交事务越多越快时,group commit的效果越明显。
MySQL的大多数事务型存储引擎实现都不是简单的行级锁。基于提升并发性考虑,一般都同时实现了多版本并发控制(MVCC),包括Oracle、PostgreSQL。只是实现机制各不相同。
可以认为 MVCC 是行级锁的一个变种,但它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只是锁定必要的行。
MVCC 的实现是通过保存数据在某个时间点的快照来实现的。也就是说不管需要执行多长时间,每个事物看到的数据都是一致的。
典型的MVCC实现方式,分为乐观(optimistic)并发控制和悲观(pressimistic)并发控制。下边通过 InnoDB的简化版行为来说明 MVCC 是如何工作的。
InnoDB 的 MVCC,是通过在每行记录后面保存两个隐藏的列来实现。这两个列,一个保存了行的创建时间,一个保存行的过期时间(删除时间)。当然存储的并不是真实的时间,而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
REPEATABLE READ(可重读)隔离级别下MVCC如何工作:
-
SELECT
InnoDB会根据以下两个条件检查每行记录:
- InnoDB只查找版本早于当前事务版本的数据行,这样可以确保事务读取的行,要么是在开始事务之前已经存在要么是事务自身插入或者修改过的
- 行的删除版本号要么未定义,要么大于当前事务版本号,这样可以确保事务读取到的行在事务开始之前未被删除
只有符合上述两个条件的才会被查询出来
-
INSERT:InnoDB为新插入的每一行保存当前系统版本号作为行版本号
-
DELETE:InnoDB为删除的每一行保存当前系统版本号作为行删除标识
-
UPDATE:InnoDB为插入的一行新纪录保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为删除标识
保存这两个额外系统版本号,使大多数操作都不用加锁。使数据操作简单,性能很好,并且也能保证只会读取到符合要求的行。不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作和一些额外的维护工作。
MVCC 只在 COMMITTED READ(读提交)和REPEATABLE READ(可重复读)两种隔离级别下工作。<