why training custom data use CPU instead of GPU #7173
Comments
|
👋 Hello @amieruddin, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://ultralytics.com or email support@ultralytics.com. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), validation (val.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
Hi, I have the same question!^^ |
|
You should use the cuda version of torch. Uninstall your current version, and follow https://pytorch.org/get-started/locally/ |

|
@amieruddin I mean torch version. It's not related to the CUDA installed on your system. |
|
im using both CUDA toolkit v.11.3 and Pytorch v.11.3.. based on my installation before...if i install Pytorch not same version with cuda toolkit...it will get error message when training |
|
based on your link to https://pytorch.org/get-started/locally/ , it show latest version of PyTorch is 11.3. @CCRcmcpe , is current PyTorch version 11.3 not support GPU to training YOLOv5? |
|
@amieruddin You have a huge misunderstanding. Latest pytorch version is 1.11.0, which uses CUDA 11.3. There's no pytorch 11.3. And you should choose compute platform CUDA and install. |
|
@CCRcmcpe , I choose Pytorch Build : LTS 1.8.2 and install using the command : pip3 install torch==1.8.2+cu111 torchvision==0.9.2+cu111 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html but it show error like this.
then when i check pip freeze : it show only torch downgrade to torch==1.8.2+cu111.
|


This comment was marked as outdated.
This comment was marked as outdated.
This comment was marked as outdated.
This comment was marked as outdated.
|
@amieruddin Alright. Seems you are already using GPU to train. My fault. The reason your GPU usage is so low is because your small batch size does not match your GPU performance. Increase your batch size to 32 or higher to solve the problem. |
|
Thank you @CCRcmcpe, actually there is nothing wrong with my training result/model...because after training, I run the model and it work fine. I just need help to train the model using GPU instead of CPU. Currently I set the epoch to 1500, and it takes me 5 days to finish the training. I want to speed up the time taken. I try your suggestion to increase the batch size. I try batch size 32 & 64, it still use CPU, not GPU. After run this command, task manager show it use 100% of the CPU.
|


|
@amieruddin 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
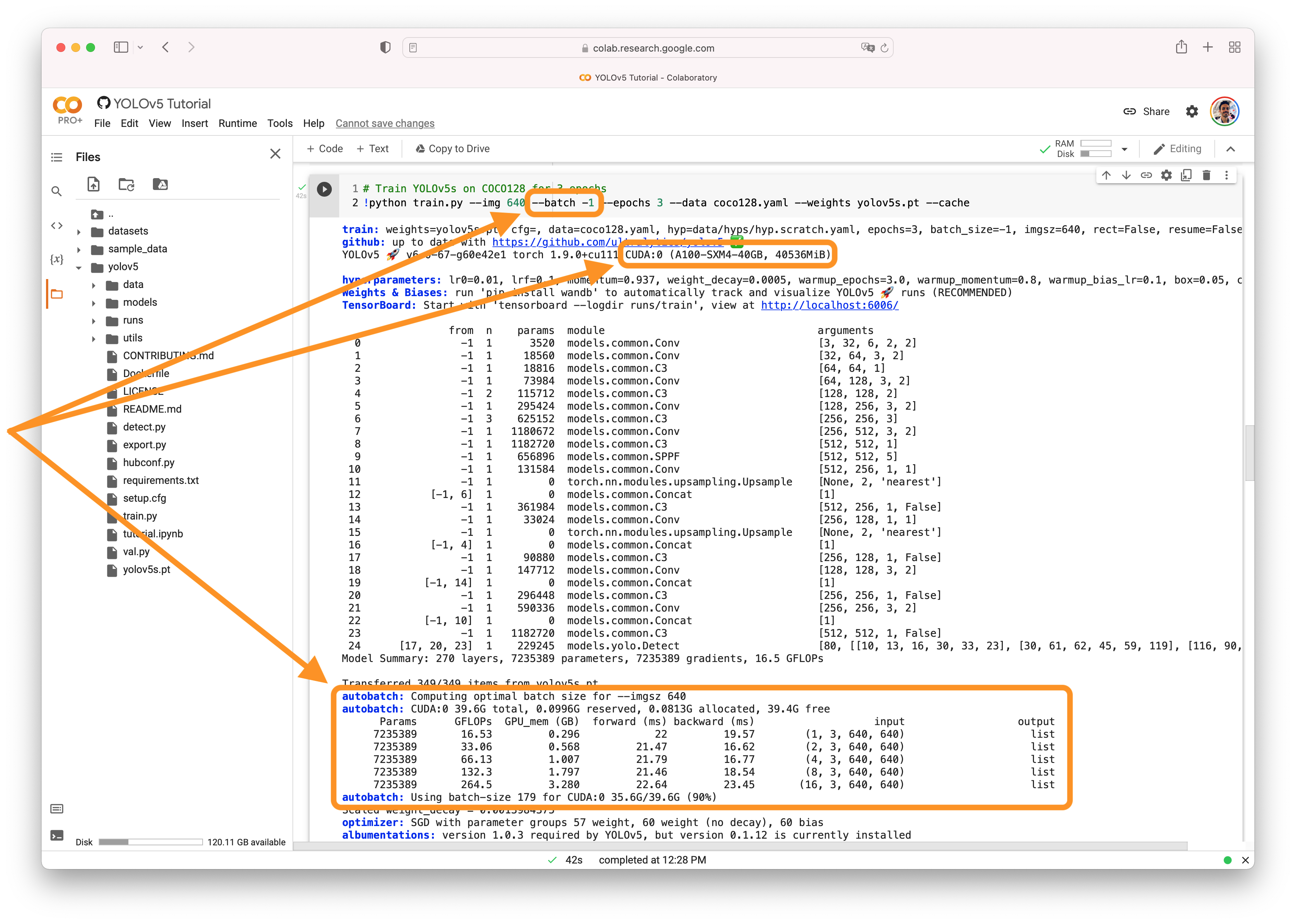
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |

|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
|
@amieruddin |
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html Do this above step. and then try running the train command directly from the command line, this made it work somehow! There should be a prompt on the command line which shows you using the GPU |
Thanks a lot |
Search before asking
Question
Hi,
i have 20k of images and already do data preparation(follow guideline by ultalytics).
I don't make any changes on any yolov5 file/hyp. I just use default setting by yolov5.
When training was started, i noticed that the training use all CPU memory (86%) rather then GPU (6%).
My device spec as below :
OS : Windows 10
GPU : NVIDIA RTX 3090
CPU : i9
Command for training : python train.py --img 640 --batch 16 --epochs 1500 --data dataset.yaml --weights yolov5s.pt --device 0
My question is why my device trained the yolo model using CPU instead of GPU? is that any line i need to make changes?
Need help to train the yolo on gpu..Thank you.
Additional
No response
The text was updated successfully, but these errors were encountered: