Batched Inference slower then frame by frame #9987
Comments
|
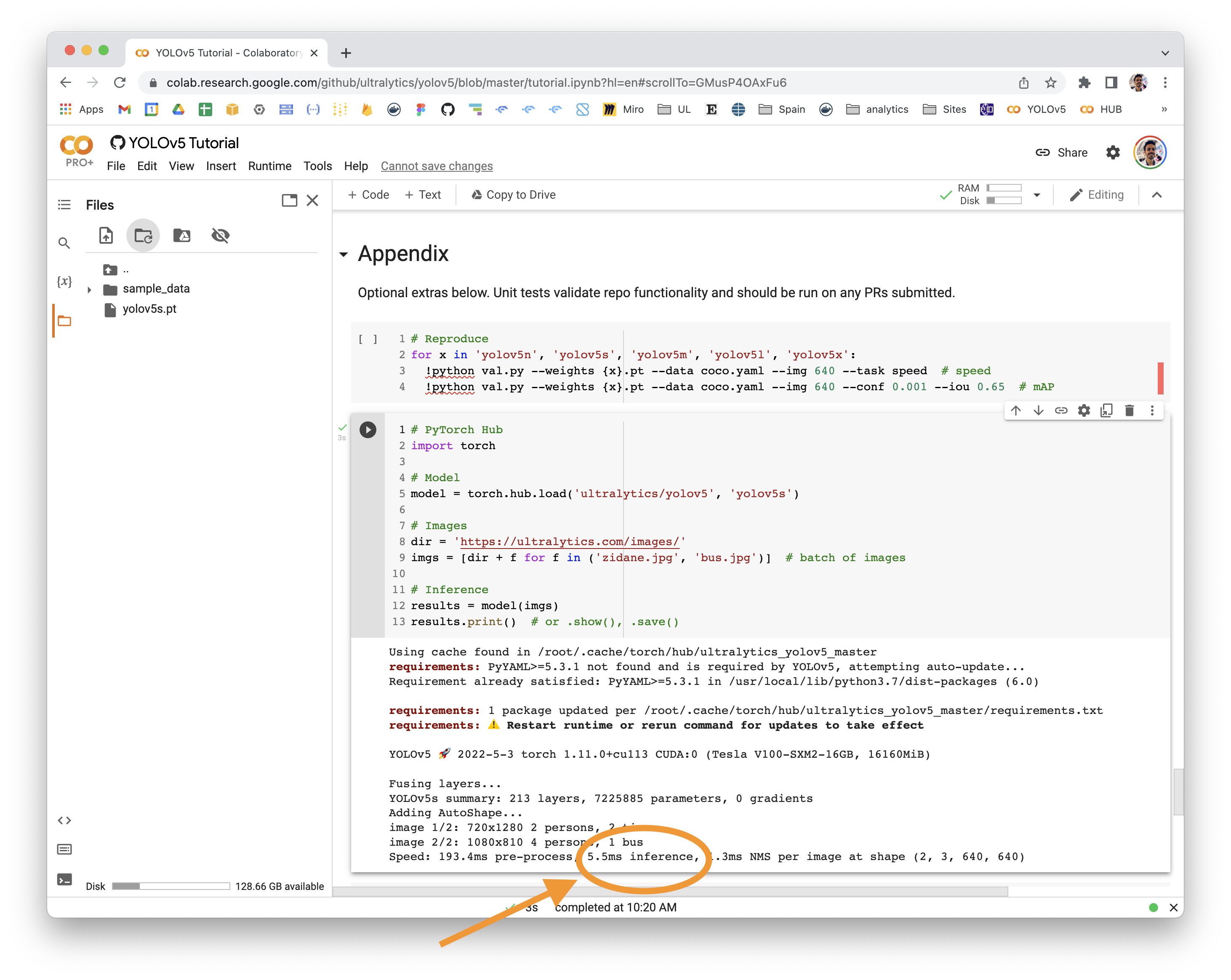
👋 Hello! Thanks for asking about inference speed issues. PyTorch Hub speeds will vary by hardware, software, model, inference settings, etc. Our default example in Colab with a V100 looks like this:
YOLOv5 🚀 can be run on CPU (i.e. detect.py inferencepython detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/
YOLOv5 PyTorch Hub inferenceimport torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
dir = 'https://ultralytics.com/images/'
imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images
# Inference
results = model(imgs)
results.print() # or .show(), .save()
# Speed: 631.5ms pre-process, 19.2ms inference, 1.6ms NMS per image at shape (2, 3, 640, 640)Increase SpeedsIf you would like to increase your inference speed some options are:
Good luck 🍀 and let us know if you have any other questions! |


|
Another question is that, in batched infetrence, can we specify a fixed batch size, regardless of the incoming batch size. So for example, if the list of images(batch) is of 100 images, I want it to automatically get processed in batches of 32, 32, 32, 4. |
|
@ahmadmustafaanis pytorch hub models run at the batch size you provide in your list of inputs, whether it's 1 or 100 Larger batch sizes should provide faster speeds per image (but of course slower overall). See YOLOv5 batch size study: |
Search before asking
Question
Hi, I have read that batch inference is always faster then frame by frame, but in my case I am getting opposite results.
Here is my code
The output is
Which is very weird as batch predictions should always be fast.
Additional
No response
The text was updated successfully, but these errors were encountered: