wordMAP suggests target words in wrong occurrence order #6237
Comments
|
Here's another example where to2 is suggested (and to3) but not to1.
|
|
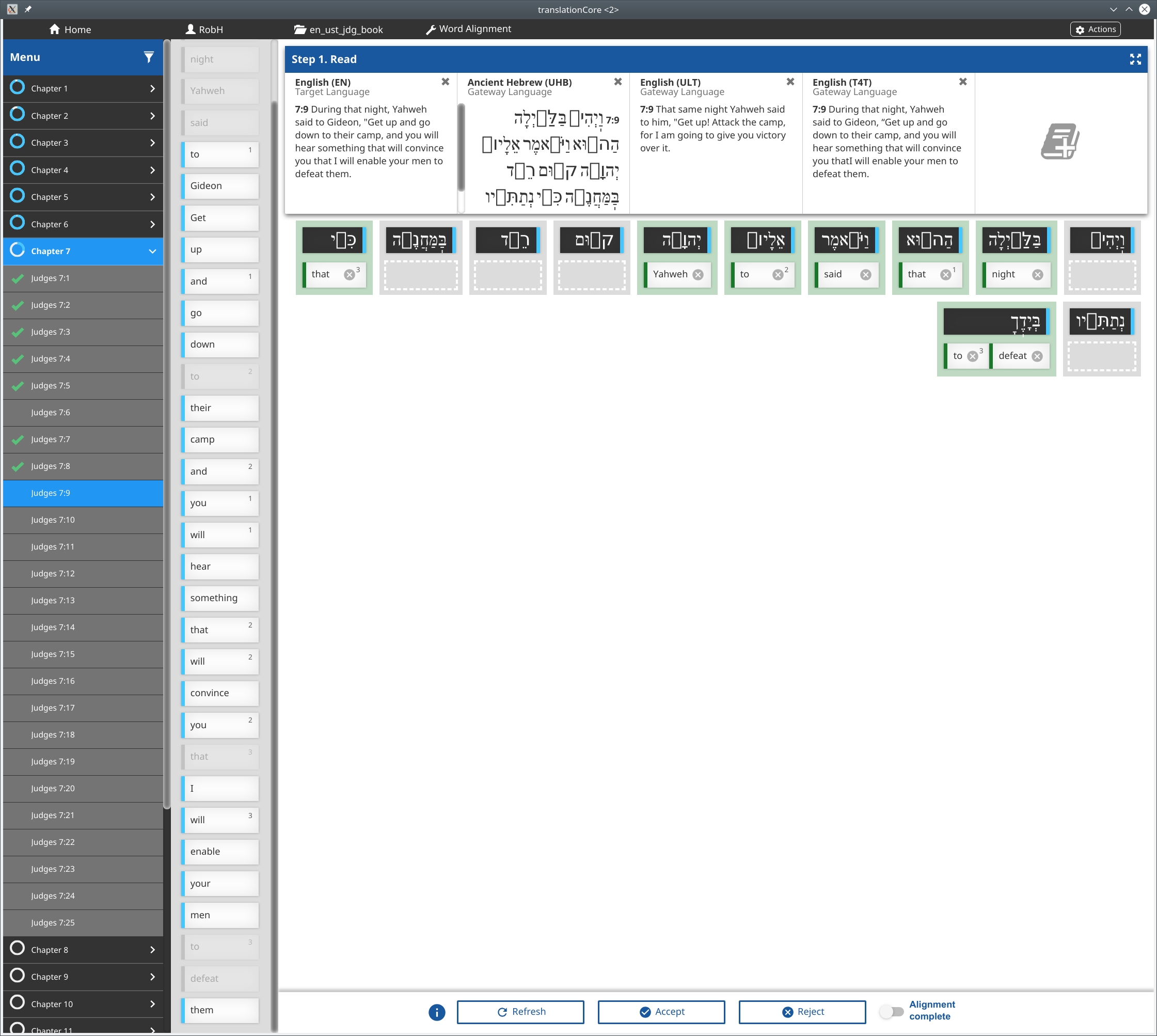
Here is an example from Zec 1:4 in tC 2.0.0 (8a6a8c5) |

|
Suggestion: SPIKE it out to figure out how to address. |
|
@jag3773 @RobH123 Has this only been seen in Hebrew text? And are the suggestions always sequential but reversed? |
|
I've identified three different areas where this bug could be coming from. And a separate bug all together. The problem is related to alignment memory and how it is used to score predictions..
I also saw that the corpus index is not using the user-defined maximum n-gram length. This isn't likely to be very noticeable, but it could result in some lost suggestions. |
|
@RobH123 do you happen to have a sample project where this issue shows up? If so could you share it here? |
|
It may be correct that it's only in Hebrew? (Haven't been in the NT lately.) Not completely sure what I can give you @neutrinog. I'm aligning UST 1 Samuel and I have lots of other projects loaded in tCore 2.0 as recommended by Larry Sallee to give extra context. It occurs frequently, more likely of course in longer verses. Are you after a Book/Chapter/Verse reference or a zip file or what? I just uploaded to https://git.door43.org/RobH/en_ust_1sa_book. |
|
@RobH123 a zip like the above, yes. But also a chapter/verse where you see this issue in the book. |
|
1 Sam 14:32 suggests they2 but not they1. v34 suggests to2 and to3 but not to1. v36 suggests soldiers3 but not soldiers1 or soldiers2. v39 suggests execute2 before execute1. v52 suggests Saul2 before Saul1. |
|
ok I think I've discovered the problem here. For example. Let's say we have the following alignment permutations where the numbers indicate the token's occurrence within the sentence:
Visually we can see that the obvious prediction should be |
Alignment Relative OccurrenceHere's my thought for an algorithm.
Sample data: Our known points of equivalence are Measure the slope between the two points above using the "Two Point Slope Form" equation Which simplifies to: This graph illustrates we can now translate occurrences between the source and target text: Now we can evaluate the relative occurrence of two tokens.
Now we have two relative occurrences that we can accurately compare. Next we must compare how close these values are to each other relative to their range Normalize range to from Interpretation:
|

|
The above should actually be performed on n-grams. A uni-gram would cover the single token case. |
|
Ok here are the results! Click on the images to see closer. Before. Notice "with": After: |


|
Verified in translationCore 2.1.0 (36a0501) |
|
Update: I've fixed a lot of bugs in wordMAP and am closing in on the ones presented in this issue. I expect to finish in a day or two. |


|
@cckozie the first screenshot should be a valid suggestion. Notice the paired suggestion The second screenshot does appear to be out of order of occurrence. |
|
@neutrinog OK, thanks. I understand that scenario 1 is working as designed even though it does not comply with the stated requirement in the first comment above. And to the average user it will most likely appear to be a bug (as it did to me:). I will write up a new issue for that scenario for future consideration. |
|
The remaining bug here (see previous comment) has been resolved in #6647. Note: since we are basically brute forcing the occurrence order, I left a few escape hatches to prevent it from killing performance in rare situations. In these corner cases wordMAP will slowly become less strict when checking the occurrence order. I've simulated some of these in the unit tests, however I haven't seen these yet in translationCore. |
|
@cckozie - Joel's fixes are here: https://github.com/unfoldingWord/translationCore/actions/runs/32631095 I only verified the performance issue on the Mac build. |
|
2.1.0 (228ed0f) |
|
@cckozie 6:27 doesn't show any suggestions now because it cannot satisfy the stricter occurrence rules. In this case it only had one suggested use of the word "did" (the second occurrence) e.g. "they did(2)". However, since suggested words are now required to begin with the first occurrence (see #6237 (comment)), there was no valid combination of suggestions. The only solutions I see to this are:
The easiest ones to implement would be 1 and 3. Option 2 could take O^2 time depending on how many problem words there are and where they are at in the sentence. EditWe probably need to implement option 3 in either case, because even without the requirement that words begin at the first occurrence, it's still possible to get an empty set if the alignment memory has two pairs of words that are forced out of order due to their counterparts. e.g. "the word(1)", "a word(3)", where another "word (2)" exists, but because it is not adjacent to a "the" or "a" it cannot be used. |
|
ok I've implemented number 3. See this PR #6748 |
|
Verified in Verified in 2.2.0 (5170810) |
|
2.2.0 (2375ae5) 07-JDG.usfm.zip |


|
@neutrinog - Are the wrong order occurrences in 7:9 above expected? |
|
@cckozie nope that's definitely due to a bug in the code. It took awhile to track down, but now that I've found it, it should be pretty easy to fix. |
|
well.. I was able to fix the problem. Strangely enough, I was able to recreate the problem in a unit test and have fixed it there, but when I use the update in translationCore there's no difference. At least now the logs tell you want's going on. I'll try sleeping on it. |
|
I went ahead and put in a PR for this at #6784. Through some painful debugging and manually constructing input data I was able to discover and fix some more bugs in wordMAP. However, the issue above still remains. |
|
@birchamp to advise on next steps based on discussions scheduled later this week. |
|
@jag3773 could take a look at this and tell us the impact on the content and GL teams? |
|
Rather than a large refactor, maybe we could just have tC make a check after wordMAP runs to see if there are target words out of order. If so, put up an alert that informs the user that one of more target words are out of order. |
|
I don't think this should hold up the 3.0 release. If it can't be fixed relatively simply then I'd save it for later (some of the wrong order scenarios were fixed which helps). I'm not sure that a pop up would be desired, that might be too distracting. |
1.2.0 (89d7abe)
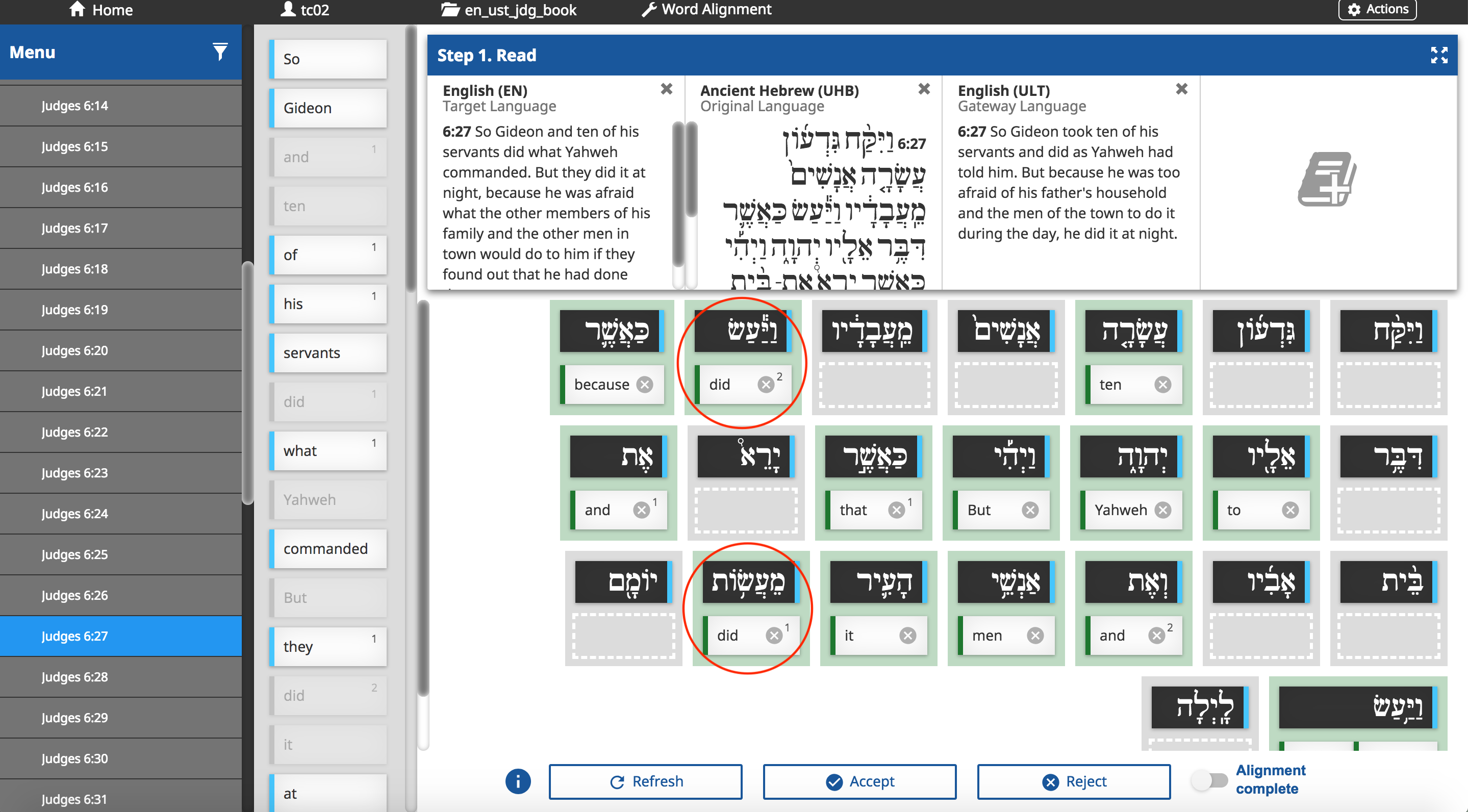
Reported by Robert using 1.1.4
The text was updated successfully, but these errors were encountered: