
把一个字符串按照树的形状,分成两部分,分成两部分...直到达到叶子节点。并且可以多次交换非叶子节点的两个子树,最后从左到右读取叶子节点,记为生成的字符串。题目是给两个字符串 S1 和 S2,然后问 S2 是否是 S1 经过上述方式生成的。
开始的时候,由于给出的图示很巧都是平均分的,我以为只能平均分字符串,看了这里,明白其实可以任意位置把字符串分成两部分,这里需要注意一下。
这道题很容易想到用递归的思想去解,假如两个字符串 great 和 rgeat。考虑其中的一种切割方式。
第 1 种情况:S1 切割为两部分,然后进行若干步切割交换,最后判断两个子树分别是否能变成 S2 的两部分。

第 2 种情况:S1 切割并且交换为两部分,然后进行若干步切割交换,最后判断两个子树是否能变成 S2 的两部分。
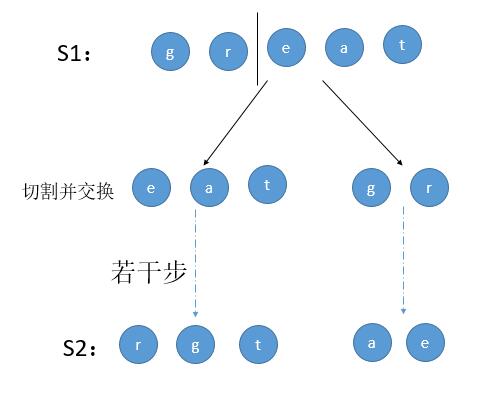
上边是一种切割方式,我们只需要遍历所有的切割点即可。
public boolean isScramble(String s1, String s2) {
if (s1.length() != s2.length()) {
return false;
}
if (s1.equals(s2)) {
return true;
}
//判断两个字符串每个字母出现的次数是否一致
int[] letters = new int[26];
for (int i = 0; i < s1.length(); i++) {
letters[s1.charAt(i) - 'a']++;
letters[s2.charAt(i) - 'a']--;
}
//如果两个字符串的字母出现不一致直接返回 false
for (int i = 0; i < 26; i++) {
if (letters[i] != 0) {
return false;
}
}
//遍历每个切割位置
for (int i = 1; i < s1.length(); i++) {
//对应情况 1 ,判断 S1 的子树能否变为 S2 相应部分
if (isScramble(s1.substring(0, i), s2.substring(0, i)) && isScramble(s1.substring(i), s2.substring(i))) {
return true;
}
//对应情况 2 ,S1 两个子树先进行了交换,然后判断 S1 的子树能否变为 S2 相应部分
if (isScramble(s1.substring(i), s2.substring(0, s2.length() - i)) &&
isScramble(s1.substring(0, i), s2.substring(s2.length() - i)) ) {
return true;
}
}
return false;
}时间复杂度:
空间复杂度:
当然,我们可以用 memoization 技术,把递归过程中的结果存储起来,如果第二次递归过来,直接返回结果即可,无需重复递归。
public boolean isScramble(String s1, String s2) {
HashMap<String, Integer> memoization = new HashMap<>();
return isScrambleRecursion(s1, s2, memoization);
}
public boolean isScrambleRecursion(String s1, String s2, HashMap<String, Integer> memoization) {
//判断之前是否已经有了结果
int ret = memoization.getOrDefault(s1 + "#" + s2, -1);
if (ret == 1) {
return true;
} else if (ret == 0) {
return false;
}
if (s1.length() != s2.length()) {
memoization.put(s1 + "#" + s2, 0);
return false;
}
if (s1.equals(s2)) {
memoization.put(s1 + "#" + s2, 1);
return true;
}
int[] letters = new int[26];
for (int i = 0; i < s1.length(); i++) {
letters[s1.charAt(i) - 'a']++;
letters[s2.charAt(i) - 'a']--;
}
for (int i = 0; i < 26; i++)
if (letters[i] != 0) {
memoization.put(s1 + "#" + s2, 0);
return false;
}
for (int i = 1; i < s1.length(); i++) {
if (isScramble(s1.substring(0, i), s2.substring(0, i)) && isScramble(s1.substring(i), s2.substring(i))) {
memoization.put(s1 + "#" + s2, 1);
return true;
}
if (isScramble(s1.substring(0, i), s2.substring(s2.length() - i))
&& isScramble(s1.substring(i), s2.substring(0, s2.length() - i))) {
memoization.put(s1 + "#" + s2, 1);
return true;
}
}
memoization.put(s1 + "#" + s2, 0);
return false;
}既然是递归,压栈压栈压栈,出栈出栈出栈,我们可以利用动态规划的思想,省略压栈的过程,直接从底部往上走。
我们用 dp [ len ][ i ] [ j ] 来表示 s1[ i, i + len ) 和 s2 [ j, j + len ) 两个字符串是否满足条件。换句话说,就是 s1 从 i 开始的 len 个字符是否能转换为 S2 从 j 开始的 len 个字符。那么解法一的两种情况,递归式可以写作。
第 1 种情况,参考下图: 假设左半部分长度是 q,dp [ len ][ i ] [ j ] = dp [ q ][ i ] [ j ] && dp [ len - q ][ i + q ] [ j + q ] 。也就是 S1 的左半部分和 S2 的左半部分以及 S1 的右半部分和 S2 的右半部分。
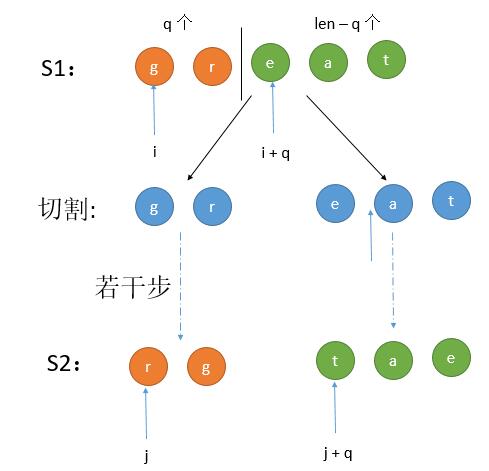
第 2 种情况,参考下图: 假设左半部分长度是 q,那么 dp [ len ][ i ] [ j ] = dp [ q ][ i ] [ j + len - q ] && dp [ len - q ][ i + q ] [ j ] 。也就是 S1 的右半部分和 S2 的左半部分以及 S1 的左半部分和 S2 的右半部分。

public boolean isScramble4(String s1, String s2) {
if (s1.length() != s2.length()) {
return false;
}
if (s1.equals(s2)) {
return true;
}
int[] letters = new int[26];
for (int i = 0; i < s1.length(); i++) {
letters[s1.charAt(i) - 'a']++;
letters[s2.charAt(i) - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (letters[i] != 0) {
return false;
}
}
int length = s1.length();
boolean[][][] dp = new boolean[length + 1][length][length];
//遍历所有的字符串长度
for (int len = 1; len <= length; len++) {
//S1 开始的地方
for (int i = 0; i + len <= length; i++) {
//S2 开始的地方
for (int j = 0; j + len <= length; j++) {
//长度是 1 无需切割
if (len == 1) {
dp[len][i][j] = s1.charAt(i) == s2.charAt(j);
} else {
//遍历切割后的左半部分长度
for (int q = 1; q < len; q++) {
dp[len][i][j] = dp[q][i][j] && dp[len - q][i + q][j + q]
|| dp[q][i][j + len - q] && dp[len - q][i + q][j];
//如果当前是 true 就 break,防止被覆盖为 false
if (dp[len][i][j]) {
break;
}
}
}
}
}
}
return dp[length][0][0];
}时间复杂度:$$O(n^4)$$。
空间复杂度:$$O(n^3)$$。
有时候太惯性思维了,二分查找做多了,看见树就想二分,这一点需要注意。这里还遇到一个问题时,解法一的 memoization 和解法二的动态规划理论上都会比解法一原始解法快一些,但是在 leetcode 上反而最开始的解法是最快的,这里有些想不通,大家有什么想法可以和我交流下。