- 执行训练脚本,开始训练语音识别模型, 每训练一轮和每2000个batch都会保存一次模型,模型保存在
PaddlePaddle-DeepSpeech/models/param/目录下,默认会使用数据增强训练,如何不想使用数据增强,只需要将参数augment_conf_path设置为None即可。关于数据增强,请查看数据增强部分。如果没有关闭测试,在每一轮训练结果之后,都会执行一次测试计算模型在测试集的准确率。执行训练时,如果是Linux下,通过CUDA_VISIBLE_DEVICES可以指定多卡训练。
CUDA_VISIBLE_DEVICES=0,1 python train.py训练输出结果如下:
2024-09-28 11:57:46.355 | INFO | utils.utils:print_arguments:11 - ----------- 额外配置参数 -----------
2024-09-28 11:57:46.355 | INFO | utils.utils:print_arguments:13 - augment_conf_path: ./conf/augmentation.yml
2024-09-28 11:57:46.355 | INFO | utils.utils:print_arguments:13 - batch_size: 8
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - learning_rate: 0.0005
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - max_duration: 20.0
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - mean_istd_path: ./dataset/mean_istd.json
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - metrics_type: cer
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - min_duration: 0.5
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - num_epoch: 100
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - num_rnn_layers: 3
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - output_model_dir: ./models/
2024-09-28 11:57:46.356 | INFO | utils.utils:print_arguments:13 - pretrained_model: None
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:13 - resume_model: None
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:13 - rnn_layer_size: 1024
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:13 - test_manifest: ./dataset/manifest.test
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:13 - train_manifest: ./dataset/manifest.train
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:13 - use_gpu: True
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:13 - vocab_path: ./dataset/vocabulary.txt
2024-09-28 11:57:46.357 | INFO | utils.utils:print_arguments:14 - ------------------------------------------------
2024-09-28 11:57:46.365 | INFO | utils.utils:print_arguments:17 - ----------- 数据增强配置 -----------
2024-09-28 11:57:46.365 | INFO | utils.utils:print_arguments:21 - noise:
2024-09-28 11:57:46.365 | INFO | utils.utils:print_arguments:28 - max_snr_dB: 50
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - min_snr_dB: 10
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - noise_dir: dataset/noise
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - prob: 0.5
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:21 - resample:
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - new_sample_rate: [8000, 16000, 24000]
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - prob: 0.0
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:21 - reverb:
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - prob: 0.2
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - reverb_dir: dataset/reverb
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:21 - shift:
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - max_shift_ms: 5
2024-09-28 11:57:46.366 | INFO | utils.utils:print_arguments:28 - min_shift_ms: -5
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - prob: 0.5
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:21 - spec_aug:
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - freq_mask_ratio: 0.15
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - max_time_warp: 5
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - n_freq_masks: 2
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - n_time_masks: 2
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - prob: 0.5
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - time_mask_ratio: 0.05
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:21 - spec_sub_aug:
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - max_time: 30
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - num_time_sub: 3
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:28 - prob: 0.5
2024-09-28 11:57:46.367 | INFO | utils.utils:print_arguments:21 - speed:
2024-09-28 11:57:46.368 | INFO | utils.utils:print_arguments:28 - prob: 0.5
2024-09-28 11:57:46.368 | INFO | utils.utils:print_arguments:21 - volume:
2024-09-28 11:57:46.371 | INFO | utils.utils:print_arguments:28 - max_gain_dBFS: 15
2024-09-28 11:57:46.371 | INFO | utils.utils:print_arguments:28 - min_gain_dBFS: -15
2024-09-28 11:57:46.371 | INFO | utils.utils:print_arguments:28 - prob: 0.5
2024-09-28 11:57:46.371 | INFO | utils.utils:print_arguments:31 - ------------------------------------------------
2024-09-28 11:57:46.373 | INFO | yeaudio.augmentation:__init__:135 - 噪声增强的噪声音频文件数量: 0
2024-09-28 11:57:46.374 | INFO | yeaudio.augmentation:__init__:170 - 混响增强音频文件数量: 0
W0928 11:57:47.821491 35864 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 12.4, Runtime API Version: 11.7
W0928 11:57:47.825518 35864 gpu_resources.cc:164] device: 0, cuDNN Version: 8.4.
2024-09-28 11:57:50.527 | INFO | __main__:train:146 - Train epoch: [1/200], batch: [0/17664], loss: 63.13452, learning_rate: 0.00000004, eta: 110 days, 1:57:04
2024-09-28 11:58:04.960 | INFO | __main__:train:146 - Train epoch: [1/200], batch: [100/17664], loss: 55.69350, learning_rate: 0.00000204, eta: 5 days, 21:14:44
- 在训练过程中,程序会使用VisualDL记录训练结果,可以通过以下的命令启动VisualDL。
visualdl --logdir=log --host=0.0.0.0- 然后再浏览器上访问
http://localhost:8040可以查看结果显示,如下。
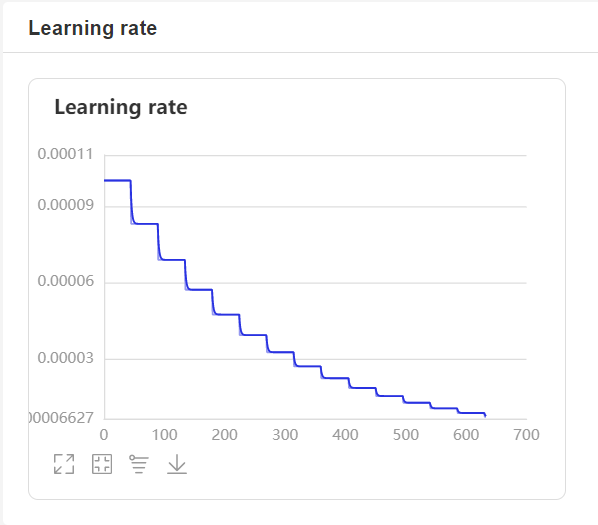
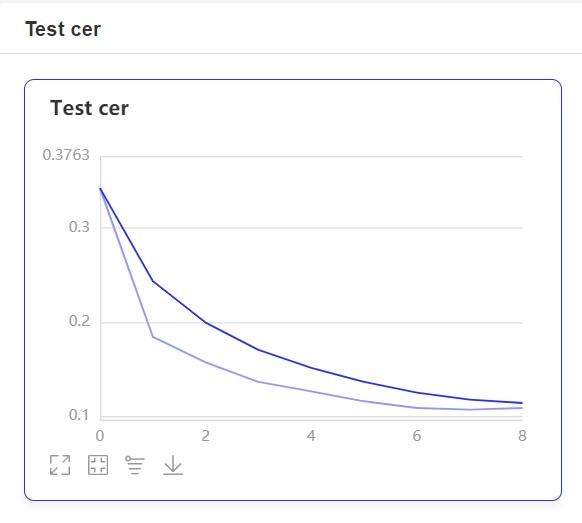
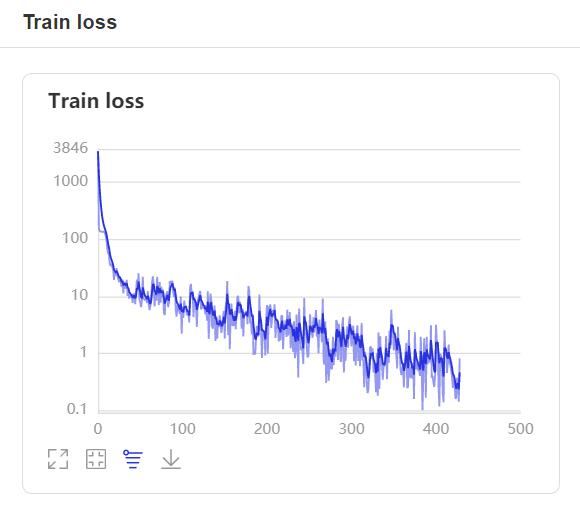
如果在训练的时候中断了,可以通过参数resume_model指定模型,然后在这基础上恢复训练,在启动训练之后会加载该模型,并以当前epoch继续训练。
CUDA_VISIBLE_DEVICES=0,1 python train.py --resume_model=./models/epoch_100/如果读者已经训练或者下载了模型,想使用自己的数据集微调模型,除了使用resume_model参数指定模型外,还需要修改训练的num_epoch,因为该模型已经是最大num_epoch保存的模型,如果不修改参数的话,可能直接就停止训练了,可以设置为110,模型就会在原来的模型在训练10个epoch。数据集需要加上原来的数据合并一起训练。
CUDA_VISIBLE_DEVICES=0,1 python train.py --resume_model=./models/epoch_100/ --num_epoch=110