原文链接:本着什么原则,才能写出优秀的代码?
作为一名程序员,最不爱干的事情,除了开会之外,可能就是看别人的代码。
有的时候,新接手一个项目,打开代码一看,要不是身体好的话,可能直接气到晕厥。
风格各异,没有注释,甚至连最基本的格式缩进都做不到。这些代码存在的意义,可能就是为了证明一句话:又不是不能跑。
在这个时候,大部分程序员的想法是:这烂代码真是不想改,还不如直接重写。
但有的时候,我们看一些著名的开源项目时,又会感叹,代码写的真好,优雅。为什么好呢?又有点说不出来,总之就是好。
那么,这篇文章就试图分析一下好代码都有哪些特点,以及本着什么原则,才能写出优秀的代码。
先说说比较基本的原则,只要是程序员,不管是高级还是初级,都会考虑到的。
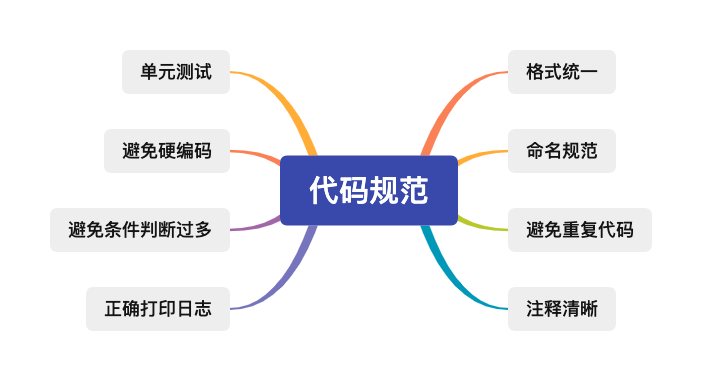
这只是列举了一部分,还有很多,我挑选四项简单举例说明一下。
- 格式统一
- 命名规范
- 注释清晰
- 避免重复代码
以下用 Python 代码分别举例说明:
格式统一包括很多方面,比如 import 语句,需要按照如下顺序编写:
- Python 标准库模块
- Python 第三方模块
- 应用程序自定义模块
然后每部分间用空行分隔。
import os
import sys
import msgpack
import zmq
import foo再比如,要添加适当的空格,像下面这段代码;
i=i+1
submitted +=1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)代码都紧凑在一起了,很影响阅读。
i = i + 1
submitted += 1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)添加空格之后,立刻感觉清晰了很多。
还有就是像 Python 的缩进,其他语言的大括号位置,是放在行尾,还是另起新行,都需要保证统一的风格。
有了统一的风格,会让代码看起来更加整洁。
好的命名是不需要注释的,只要看一眼命名,就能知道变量或者函数的作用。
比如下面这段代码:
a = 'zhangsan'
b = 0a 可能还能猜到,但当代码量大的时候,如果满屏都是 a,b,c,d,那还不得原地爆炸。
把变量名稍微改一下,就会使语义更加清晰:
username = 'zhangsan'
count = 0还有就是命名要风格统一。如果用驼峰就都用驼峰,用下划线就都用下划线,不要有的用驼峰,有点用下划线,看起来非常分裂。
看别人代码的时候,最大的愿望就是注释清晰,但在自己写代码时,却从来不写。
但注释也不是越多越好,我总结了以下几点:
- 注释不限于中文或英文,但最好不要中英文混用
- 注释要言简意赅,一两句话把功能说清楚
- 能写文档注释应该尽量写文档注释
- 比较重要的代码段,可以用双等号分隔开,突出其重要性
举个例子:
# =====================================
# 非常重要的函数,一定谨慎使用 !!!
# =====================================
def func(arg1, arg2):
"""在这里写函数的一句话总结(如: 计算平均值).
这里是具体描述.
参数
----------
arg1 : int
arg1的具体描述
arg2 : int
arg2的具体描述
返回值
-------
int
返回值的具体描述
参看
--------
otherfunc : 其它关联函数等...
示例
--------
示例使用doctest格式, 在`>>>`后的代码可以被文档测试工具作为测试用例自动运行
>>> a=[1,2,3]
>>> print [x + 3 for x in a]
[4, 5, 6]
"""随着项目规模变大,开发人员增多,代码量肯定也会增加,避免不了的会出现很多重复代码,这些代码实现的功能是相同的。
虽然不影响项目运行,但重复代码的危害是很大的。最直接的影响就是,出现一个问题,要改很多处代码,一旦漏掉一处,就会引发 BUG。
比如下面这段代码:
import time
def funA():
start = time.time()
for i in range(1000000):
pass
end = time.time()
print("funA cost time = %f s" % (end-start))
def funB():
start = time.time()
for i in range(2000000):
pass
end = time.time()
print("funB cost time = %f s" % (end-start))
if __name__ == '__main__':
funA()
funB()funA() 和 funB() 中都有输出函数运行时间的代码,那么就适合将这些重复代码抽象出来。
比如写一个装饰器:
def warps():
def warp(func):
def _warp(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print("{} cost time = {}".format(getattr(func, '__name__'), (end-start)))
return _warp
return warp这样,通过装饰器方法,实现了同样的功能。以后如果需要修改的话,直接改装饰器就好了,一劳永逸。
当代码写时间长了之后,肯定会对自己有更高的要求,而不只是格式,注释这些基本规范。
但在这个过程中,也是有一些问题需要注意的,下面就来详细说说。
第一个要说的就是「炫技」,当对代码越来越熟悉之后,总想写一些高级用法。但现实造成的结果就是,往往会使代码过度设计。
这不得不说说我的亲身经历了,曾经有一段时间,我特别迷恋各种高级用法。
有一次写过一段很长的 SQL,而且很复杂,里面甚至还包含了一个递归调用。有「炫技」嫌疑的 Python 代码就更多了,往往就是一行代码包含了 N 多魔术方法。
然后在写完之后漏出满意的笑容,感慨自己技术真牛。
结果就是各种被骂,更重要的是,一个星期之后,自己都看不懂了。

其实,代码并不是高级方法用的越多就越牛,而是要找到最适合的。
越简单的代码,越清晰的逻辑,就越不容易出错。而且在一个团队中,你的代码并不是你一个人维护,降低别人阅读,理解代码的成本也是很重要的。
第二点需要关注的是代码的脆弱性,是否细微的改变就可能引起重大的故障。
代码里是不是充满了硬编码?如果是的话,则不是优雅的实现。很可能导致每次性能优化,或者配置变更就需要修改源代码。甚至还要重新打包,部署上线,非常麻烦。
而把这些硬编码提取出来,设计成可配置的,当需要变更时,直接改一下配置就可以了。
再来,对参数是不是有校验?或者容错处理?假如有一个 API 被第三方调用,如果第三方没按要求传参,会不会导致程序崩溃?
举个例子:
page = data['page']
size = data['size']这样的写法就没有下面的写法好:
page = data.get('page', 1)
size = data.get('size', 10)继续,项目中依赖的库是不是及时升级更新了?
积极,及时的升级可以避免跨大版本升级,因为跨大版本升级往往会带来很多问题。
还有就是在遇到一些安全漏洞时,升级是一个很好的解决办法。
最后一点,单元测试完善吗?覆盖率高吗?
说实话,程序员喜欢写代码,但往往不喜欢写单元测试,这是很不好的习惯。
有了完善,覆盖率高的单元测试,才能提高项目整体的健壮性,才能把因为修改代码带来的 BUG 的可能性降到最低。
随着代码规模越来越大,重构是每一个开发人员都要面对的功课,Martin Fowler 将其定义为:在不改变软件外部行为的前提下,对其内部结构进行改变,使之更容易理解并便于修改。
重构的收益是明显的,可以提高代码质量和性能,并提高未来的开发效率。
但重构的风险也很大,如果没有理清代码逻辑,不能做好回归测试,那么重构势必会引发很多问题。
这就要求在开发过程中要特别注重代码质量。除了上文提到的一些规范之外,还要注意是不是滥用了面向对象编程原则,接口之间设计是不是过度耦合等一系列问题。
那么,在开发过程中,有没有一个指导性原则,可以用来规避这些问题呢?
当然是有的,接着往下看。
最近刚读完一本书,Bob 大叔的**《架构整洁之道》**,感觉还是不错的,收获很多。

全书基本上是在描述软件设计的一些理论知识。大体分成三个部分:编程范式(结构化编程、面向对象编程和函数式编程),设计原则(主要是 SOLID),以及软件架构(其中讲了很多高屋建翎的内容)。
总体来说,这本书中的内容可以让你从微观(代码层面)和宏观(架构层面)两个层面对整个软件设计有一个全面的了解。
其中 SOLID 就是指面向对象编程和面向对象设计的五个基本原则,在开发过程中适当应用这五个原则,可以使软件维护和系统扩展都变得更容易。
五个基本原则分别是:
- 单一职责原则(SRP)
- 开放封闭原则(OCP)
- 里氏替换原则(LSP)
- 接口隔离原则(ISP)
- 依赖倒置原则(DIP)
A class should have one, and only one, reason to change. – Robert C Martin
一个软件系统的最佳结构高度依赖于这个系统的组织的内部结构,因此每个软件模块都有且只有一个需要被改变的理由。
这个原则非常容易被误解,很多程序员会认为是每个模块只能做一件事,其实不是这样。
举个例子:
假如有一个类 T,包含两个函数,分别是 A() 和 B(),当有需求需要修改 A() 的时候,但却可能会影响 B() 的功能。
这就不是一个好的设计,说明 A() 和 B() 耦合在一起了。
Software entities should be open for extension, but closed for modification. – Bertrand Meyer, Object-Oriented Software Construction
如果软件系统想要更容易被改变,那么其设计就必须允许新增代码来修改系统行为,而非只能靠修改原来的代码。
通俗点解释就是设计的类对扩展是开放的,对修改是封闭的,即可扩展,不可修改。
看下面的代码示例,可以简单清晰地解释这个原则。
void DrawAllShape(ShapePointer list[], int n)
{
int i;
for (i = 0; i < n; i++)
{
struct Shape* s = list[i];
switch (s->itsType)
{
case square:
DrawSquare((struct Square*)s);
break;
case circle:
DrawSquare((struct Circle*)s);
break;
default:
break;
}
}
}上面这段代码就没有遵守 OCP 原则。
假如我们想要增加一个三角形,那么就必须在 switch 下面新增一个 case。这样就修改了源代码,违反了 OCP 的封闭原则。
缺点也很明显,每次新增一种形状都需要修改源代码,如果代码逻辑复杂的话,发生问题的概率是相当高的。
class Shape
{
public:
virtual void Draw() const = 0;
}
class Square: public Shape
{
public:
virtual void Draw() const;
}
class Circle: public Shape
{
public:
virtual void Draw() const;
}
void DrawAllShapes(vector<Shape*>& list)
{
vector<Shape*>::iterator I;
for (i = list.begin(): i != list.end(); i++)
{
(*i)->Draw();
}
}通过这样修改,代码就优雅了很多。这个时候如果需要新增一种类型,只需要增加一个继承 Shape 的新类就可以了。完全不需要修改源代码,可以放心扩展。
Require no more, promise no less.– Jim Weirich
这项原则的意思是如果想用可替换的组件来构建软件系统,那么这些组件就必须遵守同一个约定,以便让这些组件可以相互替换。
里氏替换原则可以从两方面来理解:
第一个是继承。如果继承是为了实现代码重用,也就是为了共享方法,那么共享的父类方法就应该保持不变,不能被子类重新定义。
子类只能通过新添加方法来扩展功能,父类和子类都可以实例化,而子类继承的方法和父类是一样的,父类调用方法的地方,子类也可以调用同一个继承得来的,逻辑和父类一致的方法,这时用子类对象将父类对象替换掉时,当然逻辑一致,相安无事。
第二个是多态,而多态的前提就是子类覆盖并重新定义父类的方法。
为了符合 LSP,应该将父类定义为抽象类,并定义抽象方法,让子类重新定义这些方法。当父类是抽象类时,父类就是不能实例化,所以也不存在可实例化的父类对象在程序里,也就不存在子类替换父类实例(根本不存在父类实例了)时逻辑不一致的可能。
举个例子:
看下面这段代码:
class A{
public int func1(int a, int b){
return a - b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50=" + a.func1(100, 50));
System.out.println("100-80=" + a.func1(100, 80));
}
}输出;
100-50=50
100-80=20
现在,我们新增一个功能:完成两数相加,然后再与 100 求和,由类 B 来负责。即类 B 需要完成两个功能:
- 两数相减
- 两数相加,然后再加 100
现在代码变成了这样:
class B extends A{
public int func1(int a, int b){
return a + b;
}
public int func2(int a, int b){
return func1(a,b) + 100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50=" + b.func1(100, 50));
System.out.println("100-80=" + b.func1(100, 80));
System.out.println("100+20+100=" + b.func2(100, 20));
}
}输出;
100-50=150
100-80=180
100+20+100=220
可以看到,原本正常的减法运算发生了错误。原因就是类 B 在给方法起名时重写了父类的方法,造成所有运行相减功能的代码全部调用了类 B 重写后的方法,造成原本运行正常的功能出现了错误。
这样做就违反了 LSP,使程序不够健壮。更通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖、聚合,组合等关系代替。
Clients should not be forced to depend on methods they do not use. –Robert C. Martin
软件设计师应该在设计中避免不必要的依赖。
ISP 的原则是建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法要尽量少。
也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。
在程序设计中,依赖几个专用的接口要比依赖一个综合的接口更灵活。
单一职责与接口隔离的区别:
- 单一职责原则注重的是职责;而接口隔离原则注重对接口依赖的隔离。
- 单一职责原则主要是约束类,其次才是接口和方法,它针对的是程序中的实现和细节; 而接口隔离原则主要约束接口。
举个例子:
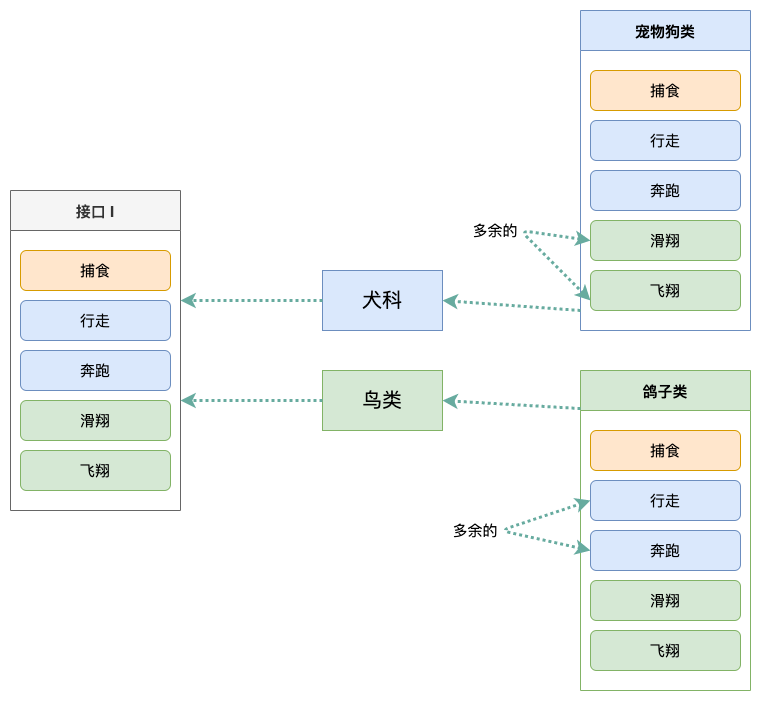
首先解释一下这个图的意思:
「犬科」类依赖「接口 I」中的方法:「捕食」,「行走」,「奔跑」; 「鸟类」类依赖「接口 I」中的方法「捕食」,「滑翔」,「飞翔」。
「宠物狗」类与「鸽子」类分别是对「犬科」类与「鸟类」类依赖的实现。
对于具体的类:「宠物狗」与「鸽子」来说,虽然他们都存在用不到的方法,但由于实现了「接口 I」,所以也 必须要实现这些用不到的方法,这显然是不好的设计。
如果将这个设计修改为符合接口隔离原则的话,就必须对「接口 I」进拆分。
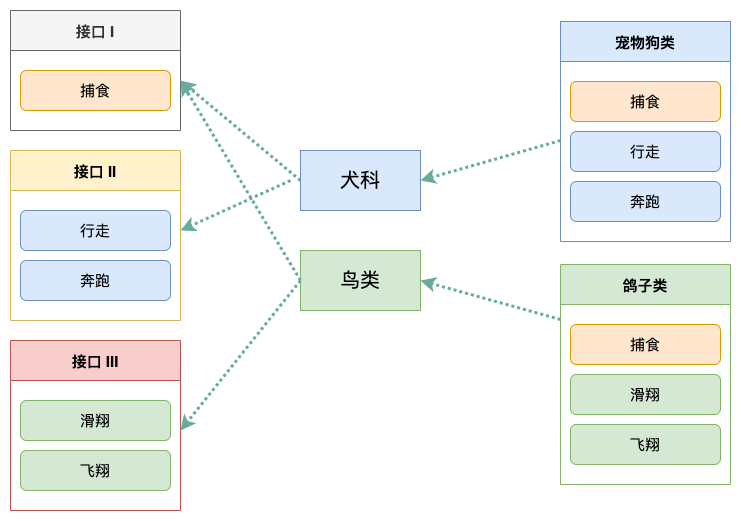
在这里,我们将原有的「接口 I」拆分为三个接口,拆分之后,每个类只需实现自己需要的接口即可。
High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.– Robert C. Martin
高层策略性的代码不应该依赖实现底层细节的代码。
这话听起来就让人听不明白,我来翻译一下。大概就是说在写代码的时候,应该多使用稳定的抽象接口,少依赖多变的具体实现。
举个例子:
看下面这段代码:
public class Test {
public void studyJavaCourse() {
System.out.println("张三正在学习 Java 课程");
}
public void studyDesignPatternCourse() {
System.out.println("张三正在学习设计模式课程");
}
}上层直接调用:
public static void main(String[] args) {
Test test = new Test();
test.studyJavaCourse();
test.studyDesignPatternCourse();
}这样写乍一看并没有什么问题,功能也实现的好好的,但仔细分析,却并不简单。
第一个问题:
如果张三又新学习了一门课程,那么就需要在 Test() 类中增加新的方法。随着需求增多,Test() 类会变得非常庞大,不好维护。
而且,最理想的情况是,新增代码并不会影响原有的代码,这样才能保证系统的稳定性,降低风险。
第二个问题:
Test() 类中方法实现的功能本质上都是一样的,但是却定义了三个不同名字的方法。那么有没有可能把这三个方法抽象出来,如果可以的话,代码的可读性和可维护性都会增加。
第三个问题:
业务层代码直接调用了底层类的实现细节,造成了严重的耦合,要改全改,牵一发而动全身。
基于 DIP 来解决这个问题,势必就要把底层抽象出来,避免上层直接调用底层。

抽象接口:
public interface ICourse {
void study();
}然后分别为 JavaCourse 和 DesignPatternCourse 编写一个类:
public class JavaCourse implements ICourse {
@Override
public void study() {
System.out.println("张三正在学习 Java 课程");
}
}
public class DesignPatternCourse implements ICourse {
@Override
public void study() {
System.out.println("张三正在学习设计模式课程");
}
}最后修改 Test() 类:
public class Test {
public void study(ICourse course) {
course.study();
}
}现在,调用方式就变成了这样:
public static void main(String[] args) {
Test test = new Test();
test.study(new JavaCourse());
test.study(new DesignPatternCourse());
}通过这样开发,上面提到的三个问题得到了完美解决。
其实,写代码并不难,通过什么设计模式来设计架构才是最难的,也是最重要的。
所以,下次有需求的时候,不要着急写代码,先想清楚了再动手也不迟。
这篇文章写的特别辛苦,主要是后半部分理解起来有些困难。而且有一些原则也确实没有使用经验,单靠文字理解还是差点意思,体会不到精髓。
其实,文章中的很多要求我都做不到,总结出来也相当于是对自己的一个激励。以后对代码要更加敬畏,而不是为了实现功能草草了事。写出健壮,优雅的代码应该是每个程序员的目标,与大家共勉。
如果觉得这篇文章还不错的,欢迎点赞和转发,感谢~
推荐阅读:
参考资料: