This file mainly modified based on statsmodels.iolib.summary2. Now you can use the function summary_col()
to output the results of multiple models with stars and export them as a excel/csv file.
Next show some examples including OLS,GLM,GEE,LOGIT and Panel regression results.Other models do not test yet. But what can be determined is that multi-equation models like VAR model does not work here.
# Load the data and fit
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
# ols
dat = sm.datasets.get_rdataset("Guerry", "HistData").data
res_ols = smf.ols('Lottery ~ Literacy + np.log(Pop1831)', data=dat).fit()
#glm
data = sm.datasets.scotland.load()
data.exog = sm.add_constant(data.exog)
gamma_model = sm.GLM(data.endog, data.exog, family=sm.families.Gamma())
res_glm = gamma_model.fit()
# gee
data = sm.datasets.get_rdataset('epil', package='MASS').data
fam = sm.families.Poisson()
ind = sm.cov_struct.Exchangeable()
mod = smf.gee("y ~ age + trt + base", "subject", data, cov_struct=ind, family=fam)
res_gee = mod.fit()
# logit
spector_data = sm.datasets.spector.load()
spector_data.exog = sm.add_constant(spector_data.exog)
logit_mod = sm.Logit(spector_data.endog, spector_data.exog)
res_logit = logit_mod.fit()
# load panel data and fit the model
from linearmodels.datasets import wage_panel
data = wage_panel.load()
year = pd.Categorical(data.year)
data = data.set_index(['nr', 'year'])
data['year'] = year
from linearmodels.panel import PooledOLS
exog_vars = ['black','hisp','exper','expersq','married', 'educ', 'union', 'year']
exog = sm.add_constant(data[exog_vars])
mod = PooledOLS(data.lwage, exog)
res_pooled = mod.fit()
from linearmodels.panel import PanelOLS
exog_vars = ['expersq','union','married']
exog = sm.add_constant(data[exog_vars])
mod = PanelOLS(data.lwage, exog, entity_effects=True, time_effects=True)
res_fe_re = mod.fit()
from linearmodels.panel import FirstDifferenceOLS
exog_vars = ['exper','expersq', 'union', 'married']
exog = data[exog_vars]
mod = FirstDifferenceOLS(data.lwage, exog)
res_fd = mod.fit()
exog_vars = ['black','hisp','exper','expersq','married', 'educ', 'union']
exog = sm.add_constant(data[exog_vars])
mod = PooledOLS(data.lwage, exog)
res_robust = mod.fit(cov_type='robust')
res_clust_entity = mod.fit(cov_type='clustered', cluster_entity=True)
res_clust_entity_time = mod.fit(cov_type='clustered', cluster_entity=True, cluster_time=True)
Then we import the function summary_col() from the modified summary2 that I named summary3 as a module.Thus we can directly output the concatenated results with stars and some default model informations.
from summary3 import summary_col
For single regression result,we can directly pass the result object,surely a list is better:
# summary_col(res_ols)
summary_col([res_ols])
This will return the Summary class instance, in Notebook the output is:
 We can also use print function to output as text. Parameter
We can also use print function to output as text. Parameter more_info will add new model information to print.
For example,
print(summary_col([res_ols,res_glm,res_gee,res_logit],more_info=['df_model','scale']))
The incompete output is
 We can also use
We can also use regressor_order to designate the order of variables,show to display the anyone of pvalues,
tvalues or std.err you want,title to define a custom title for your table.
print(sumary_col([res_fe_re,res_fd,res_robust,res_clust_entity,res_clust_entity_time],
regressor_order=['black'],show='se',title='Panel Results Summary Table'))
The output is
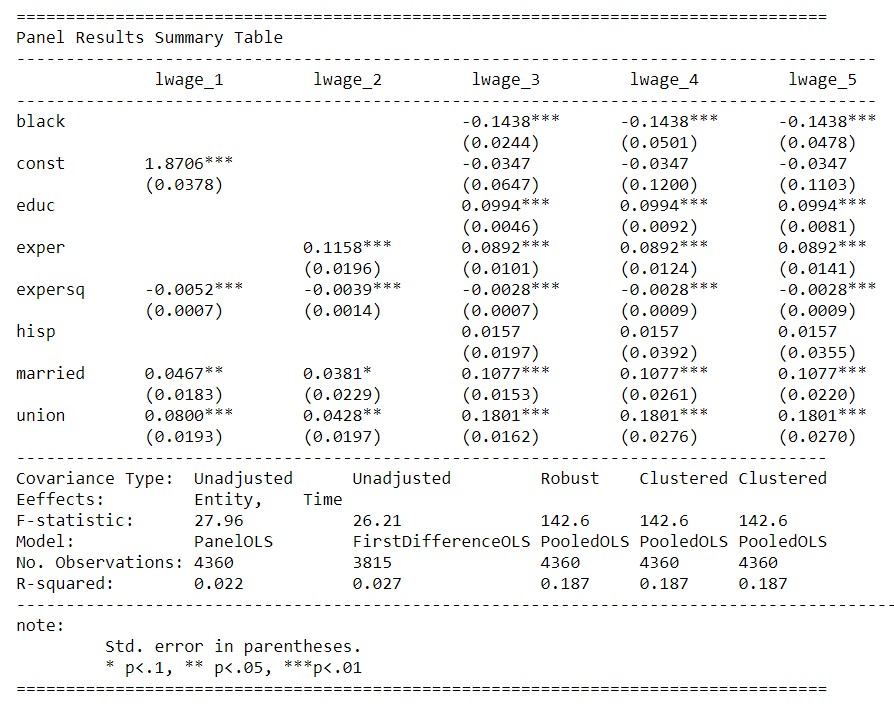 Finally,if you want to export the summary results to external files,you can do like this
Finally,if you want to export the summary results to external files,you can do like this
summary_col([res_glm,res_logit]).to_excel()
Above will obtain a excel file in your working directory named 'summary_results'. Of course you can define the filename and path just like use pandas(actually indeed so) .
summary_col([res_clust_entity,res_fd]).to_csv('your path\\filename.csv')