Proyek Machine Learning ini akan menyelesaikan permasalahan dalam domain lingkungan dengan judul "Prediksi Kekeringan parah berdasarkan Data Meteorological dan Data Informasi Soil".

Kekeringan yang terjadi dengan tidak normal atau biasa disebut drought merupakan salah satu fenomena alam dengan dampak signifikan terhadap beberapa aspek seperti lingkungan, pertanian, masyarakat, hingga ekonomi. Ciri utama dari fenomena ini adalah kekurangan sumber air yang sangat parah pada suatu area tertentu ditandai dengan sangat kecilnya tingkat presipitasi dalam jangka waktu lumayan panjang. Dengan keadaan seperti itu fenomena ekstrem ini tetap dapat terjadi pada wilayah dengan tingkat presipitasi atau curah hujan sangat tinggi serta tanpa batasan keadaan iklim sama sekali. Sehingga dampak fenomena ini dapat lebih terasa jika dibandingkan dengan fenomena alam lainnya. 1
Menurut National Oceanic dan Atmospheric Administration (NOAA), 2 fenomena ini tidak tampak secara nyata dan mengerikan sebagaimana pada fenomena tornado. Namun faktanya kerugian yang dirasakan rata-rata mencapai kurang lebih 9 Miliar USD setiap tahunnya. Dampak tersebut dapat berpengaruh terhadap ekonomi seperti harga kebutuhan pokok maupun secara langsung terhadap produk olahan pertanian semisal keju, padi, dan sebagainya. Dampak lain yang dapat ditimbulkan berupa defisit air minum, penyakit sengatan panas, meningkatkan risiko kebakaran hutan, serta lainnya terutama apabila terjadi terus menerus dalam jangka waktu panjang.
Statistik menunjukkan hampir setengah wilayah atau mencapai sekitar 47% keseluruhan Amerika Serikat mengalami fenomena ini berdasarkan skala tingkatan sejumlah 5 level mulai dari D0 hingga D4, dengan fenomena drought mulai ditunjukkan pada level D1. 3
Untuk itu diperlukan suatu metode didalam membantu mengatasi fenomena ini dimana teknologi serta pemahaman peneliti semata masih terbatas untuk dapat memperkirakan akan terjadinya fenomena ini setidaknya beberapa bulan ke depan. 4 Maka proyek ini mencoba menyelesaikan permasalahan yang ada dengan menerapkan kemampuan dari machine learning sehingga dapat membantu memprediksi fenomena drought tersebut berdasarkan data historis meteorological berupa informasi cuaca serta iklim dan juga data soil yang mengandung informasi keadaan tanah pada suatu wilayah dalam proyek ini mengambil contoh Amerika Serikat. Diharapkan machine learning dapat memudahkan para ahli maupun masyarakat untuk melakukan tindakan persiapan sebelum fenomena terjadi dengan proses implementasi yang secara web hingga mobile dapat diterapkan.
1. Eslamian, S., et al. (2017). "Drought Management: Current Challenges and Future Outlook, Ch. 34 in Handbook of Drought and Water Scarcity, Vol. 3: Management of Drought and Water Scarcity, Ed. by Eslamian S. and Eslamian F., Francis and Taylor."
2. NOAA. (2021). DROUGHT: Monitoring Economic, Environmental, and Social Impacts.
3. National Integrated Drought Information System (NIDIS). U.S. Drought Monitor. Data tanggal 13 Oktober 2021.
4. Peter Folger. (2017). Drought in the United States: Causes and Current Understanding. Congressional Research Service.
Bagian ini menjelaskan proses klarifikasi masalah dengan mengajukan beberapa solusi dalam menyelesaikannya.
Berangkat dari latar belakang tersebut, maka rincian masalah yang dapat diselesaikan diantaranya:
- Bagaimana proses data preparation yang baik, sehingga dataset meteorological dan dataset soil dapat digunakan untuk membuat model yang baik?
- Bagaimana model machine learning terbaik yang dapat mengklasifikasikan fenomena drought?
Berikut merupakan tujuan dibuatnya proyek ini:
- Melakukan proses data preparation sehingga data siap untuk digunakan dalam pembuatan model.
- Membuat model machine learning terbaik untuk mengklasifikasikan fenomena drought dengan batas metrik
minimal 70%.
Solusi yang dapat diterapkan untuk mencapai tujuan tersebut diantaranya:
-
Pada bagian data preparation yang dibagi ke dalam proses data preprocessing dan data wrangling terdiri atas:
- Memilih data mulai dari tahun 2017 hingga 2020 (hanya data
test_timeseries dan validation_timeseriesdari sumber original). - Mengambil data yang menunjukkan tingkat drought secara bulat (bukan peralihan).
- Mengekstrak fitur bulan berdasarkan fitur tanggal.
- Menambahkan informasi wilayah berdasarkan climate dari data pendukung.
- Menggabungkan dataset meteorological dengan dataset soil.
- Merubah kelas kategori drought menjadi hanya dua.
- Membagi dataset ke dalam data validation (2 bulan terakhir/ 3% dari total data) dan data train (sisanya atau 97%).
- Mengubah fitur ke dalam tipe angka.
- Menghilangkan data outliers pada data train.
- Mengatasi data tidak seimbang dengan proses oversampling serta undersampling.
- Melakukan data standardization pada semua fitur.
- Memilih data mulai dari tahun 2017 hingga 2020 (hanya data
-
Pada pembuatan model digunakan algoritma Logistic Regression sebagai baseline untuk kemudian dibandingkan dengan beberapa algoritma yaitu Multi Layer Perceptron, Support Vector Machine, dan LightGBM
-
Logistic Regression: Merupakan model linear dalam kasus klasifikasi yang memprediksi response variable menggunakan fungsi persamaan sigmoid (logit) seperti pada gambar berikut. 5 Algoritma ini biasanya sering dijadikan sebagai
baseline modelkarena kesederhanaannya.Kelebihan Kekurangan Simpel, Cepat, Mudah Kurang bagus pada data Tidak butuh asumsi distribusi pada fitur Membangun berdasarkan model linear Dapat digunakan juga pada kasus multinomial Limitasi utama yang mengasumsikan hubungan linear antara predictor dengan response variabel Tidak hanya menunjukkan seberapa perlunya koefisien, namun juga arah asosiasinya Sering disalah artikan untuk kasus regresi Menghasilkan model cukup baik terutama jika terdapat hubungan linear cukup jelas Memiliki asumsi bahwa antara fitur tidak berkorelasi sangat kuat -
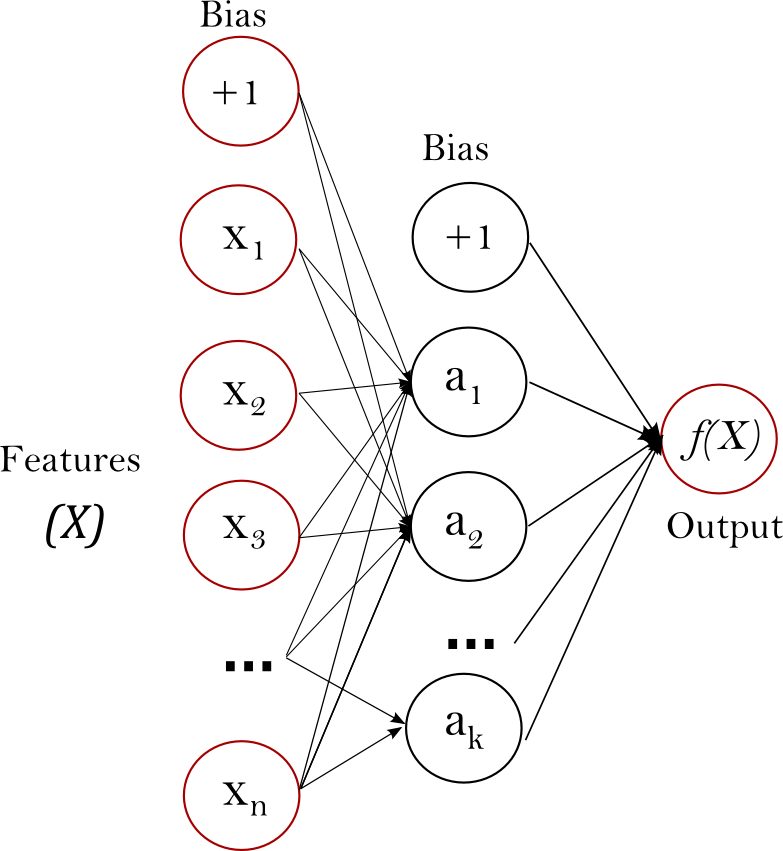
Multi Layer Perceptron (MLP): Merupakan model neural network sederhana yang biasanya hanya memiliki sebuah hidden layer seperti pada gambar di bawah berikut. Bekerja dengan meneruskan data dari input layer hingga ke hidden layer dan output layer atau biasa disebut dengan proses feedforward. Kemudian diiterasikan kembali ke belakang atau disebut proses backward propagation untuk memperkecil nilai
errorsehingga menghasilkan model yang baik. 6
Sedangkan berikut kelebihan dan kekurangannya.
Kelebihan Kekurangan Kemampuan dalam mempelajari data non-linear Sensitive terhadap feature scaling Kemampuan mempelajari model secara real time Membutuhkan tuning hyperparameter yang cukup rumit Kemampuan menyelesaikan masalah kompleks atau data sangat besardengan sangat baik (salah satu alasan pemilihan)Perbedaan inisialisasi weight dapat menyebabkan nilai metrik pada validasi berbeda -
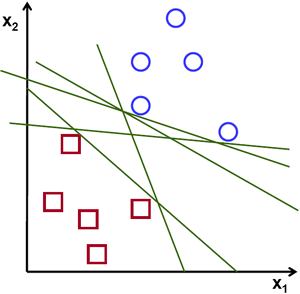
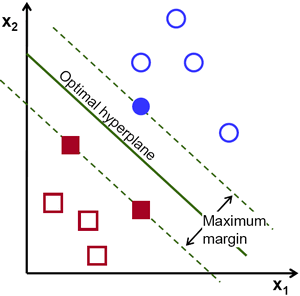
Support Vector Machine (SVM): Algoritma yang bekerja dengan cara menemukan garis pemisah (hyperplane) antar data dengan membuat kelas berbeda yang mampu menyelesaikan masalah baik linear maupun non-linear terutama pada kasus klasifikasi. Hyperplane tersebut sangat terpengaruh dengan adanya data point di dekatnya, sehingga dapat menyebabkan suatu margin yang berusaha dimaksimalkan untuk mendapatkan hasil terbaik sebagaimana pada gambar di bawah berikut. 7
Penerapan pada proyek ini sendiri dengan mengaplikasikan teknik optimasi Stochastic Gradient Descent (SGD). Dengan penjelasan detail yaitu:
- Learning Rate dituliskan dalam bentuk persamaan η0 / (1 + λ η0 t) dengan λ adalah nilai konstan untuk regularisasi,
- Nilai konstan η0 ditentukan terlebih dahulu pada subsample data,
- Learning Rate pada bias dikalikan dengan 0.001 karena biasanya dapat meningkatkan kondisinya,
- Weight direpresentasikan sebagai produk suatu skalar dan vektor dalam rangka memudahkan proses weight decay.
Berikut merupakan kelebihan serta kekurangan SVM menggunakan SGD ini:
Kelebihan Kekurangan Efektif pada data berdimensi tinggi bahkan jika jumlah sampel cenderung sedikit Jika jumlah sampel sedikit rentan overfitting Penggunaan memori yang efisien (alasan pemilihan model) Penghitungan nilai probabilitas yang butuh high computation Algoritma serbaguna (dalam arti dapat memilih fungsi decision berbeda) SGD membutuhkan parameter regularisasi dan jumlah iterasi Efisiensi yang sangat baik terutama pada data berskala besar(alasan pemilihan model)Sensitif terhadap feature scaling Kemudahan proses implementasi dan interpretasi -
LightGBM (LGBM): Algoritma berbasis gradient boosting yang berbasis tree. Dibandingkan algoritma pada golongan sama yang menumbuhkan tree secara horizontal (level-wise). LGBM menumbuhkan treenya secara vertikal (leaf-wise) yang memimilih leaf dengan nilai loss tersbesar untuk ditumbuhkan sebagaimana pada gambar di bawah. 8
Keunikan yang dimiliki oleh LGBM adalah pada metode boostingnya yang bernama GOSS (Gradient Based One Side Sampling). GOSS merupakan metode pengambilan sampel baru yaitu downsample menggunakan gradien. Dimana GOSS mengambil seluruh gradien instance yang bernilai besar, sedangkan untuk gradien bernilai kecil LGBM hanya diambil secara acak berupa sampel. Selain, itu terdapat juga EFB (Exclusive Feature Building) yang dapat mengurangi kompleksitas data dengan cara menmbundle beberapa fitur menjadi satu. 9 Berikut kelebihan dan kekurangan LGBM:
Kelebihan Kekurangan Cepat dan Efisien (alasan pemilihan model) Kurangnya support maupun komunitas Penggunaan memori yang sedikit (alasan pemilihan model) Model yang cenderung seperti blackbox Memiliki hasil lebih baik dibanding algoritma sejenis Sangat baik pada data berukuran sangat besar (alasan pemilihan model) Kemampuan menggunakan komputasi GPU Kemampuan dalam paralelization
-
-
Kemudian hasil perbandingan tersebut dipilih model dengan nilai metrik terbaik untuk selanjutnya dapat dikembangkan lebih lanjut dengan menerapkan hyperparameter tuning secara otomatis menggunakan algoritma Bayesian Optimization. Algoritma ini menerapkan prinsip Bayes Theorem didalam proses pencarian hyperparamater terbaik bagi model secara efisien dan efektif. Bayesian bekerja dengan cara membangun model probabilistik terhadap suatu objektif untuk kemudian dijadikan landasan menentukan di area mana selanjutnya hyperparameter untuk dievaluasi dengan tetap mengacu kepada hasil evaluasi dari area sebelumnya sebagaimana ditunjukkan pada gambar di bawah. 10
Kelebihan Kekurangan Meringankan beban dari objektif yang dijalankan Bekerja kurang baik pada data dengan fitur categorical Bekerja seperti high level api Berjalan lambat jika jumlah hyperparameter semakin banyak Robust terhadap fungsi evaluasi yang kurang baik Bergantung kepada suatu optimizer Optimal dalam mendapatkan hasil terbaik dengan waktu yang tidak panjang (alasan pemilihan) Algoritma tidak mudah untuk dipahami



5. Shubang Agrawal. (2021). Medium: Logistic Regression.
6. Edpresso Team. What is a multi-layered perceptron?
7. Rohith Gandhi. (2018). towardsdatascience: SVM, Introduction to Machin Learning Algorithms.
8. Rohit Dwivedi. (2020). analyticssteps: What is LightGBM Algorithm, How to use it?
9. Abhishek Sharma. (2018). towardsdatascience: What makes LightGBM lightning fast?
10. Acerbi, Luigi, and Wei Ji Ma. (2017). "Practical Bayesian optimization for model fitting with Bayesian adaptive direct search." Proceedings of the 31st International Conference on Neural Information Processing Systems.
Berikut merupakan informasi datasets yang digunakan:
| Detail | Keterangan |
|---|---|
| Source | Kaggle: Predict Droughts using Weather & Soil Data |
| License | Public (CC0 1.0) |
| Format | zip (±172 MB) |
| Domain | Weather, Climate, Earth Science, Environment |
| Timeframe | 2017/01/01 s.d. 2020/12/31 |
| Data Pendukung | us_county.csv us_climate_region.csv |
Data meterorological terdapat pada file utama. Untuk proyek ini menggunakan file test_timeseries.csv dan validation_timeseries.csv yang masing-masing berisi sebanyak 2.3 juta baris dan 21 fitur menunjukkan informasi berkaitan dengan cuaca dan iklim yang tercatat setiap hari (lebih detailnya adalah dalam sekian menit) serta telah terdapat level dari drought tercatat hanya setiap pekan (sehingga banyak informasi tidak ada). Kemudian data pada file soil_data.csv yang menunjukkan informasi berkaitan dengan tanah (tipe, ketinggian, dll) dengan 3109 baris dan 32 fitur. Serta terdapat dua data pendukung berisi informasi wilayah, selengkapnya penjelasan fitur pada datasets:
| No | Fitur | Rincian |
|---|---|---|
| 1. | fips |
Menunjukkan kode dari setiap county pada Amerika Serikat. |
| 2. | date |
Tanggal observasi (format yyyy-mm-dd). |
| 3. | PRECTOT |
Curah hujan (mm) dalam satu hari. |
| 4. | PS |
Tekanan Permukaan (kPa). |
| 5. | QV2M |
Kelembaban Spesifik pada ketinggian 2 Meter (g/kg) |
| 6. | T2M |
Suhu pada ketinggian 2 Meter (C). |
| 7. | T2MDEW |
Titik Embun/Beku pada ketinggian 2 Meter (C). |
| 8. | T2MWET |
Suhu Bola Basah pada ketinggian 2 Meter (C). |
| 9. | T2M_MAX |
Suhu maksimal pada ketinggian 2 Meter (C). |
| 10. | T2M_MIN |
Suhu minimal pada ketinggian 2 Meter (C). |
| 11. | T2M_RANGE |
T2M_MAX - T2M_MIN. |
| 12. | TS |
Suhu permukaan bumi (C). |
| 13. | WS10M |
Kecepatan angin pada ketinggian 10 Meter (m/s). |
| 14. | WS10M_MAX |
Kecepatan maksimum angin pada ketinggian 10 Meter (m/s). |
| 15. | WS10M_MIN |
Kecepatan minimum angin pada ketinggian 10 Meter (m/s). |
| 16. | WS10M_RANGE |
WS10M_MAX - WS10M_MIN. |
| 17. | WS50M |
Kecepatan angin pada ketinggian 50 Meter (m/s). |
| 18. | WS50M_MAX |
Kecepatan maksimum angin pada ketinggian 50 Meter (m/s). |
| 19. | WS50M_MIN |
Kecepatan minimum angin pada ketinggian 50 Meter (m/s). |
| 20. | WS50M_RANGE |
WS50M_MAX - WS50M_MIN. |
| 21. | score |
Ukuran tingkatan drought mulai dari D0 (tidak ada drought), D1-D4 (drought berskala). Tercatat hanya dalam kurun waktu setiap sepekan sekali. |
| No | Fitur | Rincian |
|---|---|---|
| 1. | fips |
Menunjukkan kode dari setiap county pada Amerika Serikat. |
| 2. | county |
Nama daerah county. |
| 3. | state |
Nama negara bagian. |
| 4. | state_code |
Kode dari negara bagian. |
| 5. | climate_regions |
Nama wilayah berdasar pembagian iklim. |
| No | Fitur | Rincian |
|---|---|---|
| 1. | fips |
Menunjukkan kode dari setiap county pada Amerika Serikat. |
| 2. | lat |
Informasi latitude (garis lintang). |
| 3. | lot |
Informasi longitude (garis bujur). |
| 4. | elevation |
Median dari tingkat elevasi (meter). |
| 5. | slope1 |
0 % ≤ Tingkat kemiringan ≤ 0.5 %. |
| 6. | slope2 |
0.5 % ≤ Tingkat kemiringan ≤ 2 %. |
| 7. | slope3 |
2 % ≤ Tingkat kemiringan ≤ 5 %. |
| 8. | slope4 |
5 % ≤ Tingkat kemiringan ≤ 10 %. |
| 9. | slope5 |
10 % ≤ Tingkat kemiringan ≤ 15 %. |
| 10. | slope6 |
15 % ≤ Tingkat kemiringan ≤ 30 %. |
| 11. | slope7 |
30 % ≤ Tingkat kemiringan ≤ 45 %. |
| 12. | slope8 |
45 % ≤ Tingkat kemiringan. |
| 13. | aspectN |
Utara: 0˚< aspek kemiringan ≤45˚ or 315˚< aspek kemiringan ≤360˚. |
| 14. | aspectE |
Timur: 45˚< aspek kemiringan ≤135˚. |
| 15. | aspectS |
Selatan: 135˚< aspek kemiringan ≤225˚. |
| 16. | aspectW |
Utara: 225˚< aspek kemiringan ≤315˚. |
| 17 | aspectUnknown |
Aspek kemiringan tidak terdifinisi atau jika nilai kemiringan ≤ 2%. |
| 18. | WAT_LAND |
Area perairan. |
| 19. | NVG_LAND |
Lahan tandus/sangat jarang vegetasi. |
| 20. | URB_LAND |
Perumahan dan Infrakstruktur (area pembangunan). |
| 21. | GRS_LAND |
Rumput / semak / hutan. |
| 22. | FOR_LAND |
Lahan hutan, dikalibrasi dengan statistik lahan FRA2000. |
| 23. | CULTRF_LAND |
Lahan pertanian tadah hujan. |
| 24. | CULTIR_LAND |
Lahan pertanian beririgasi, menurut GMIA 4.0. |
| 25. | CULT_LAND |
Total lahan yang ditanami. |
| 26. | SQ1 |
Ketersediaan nutrisi (Tekstur tanah, karbon organik tanah, pH tanah, total basa yang dapat ditukar) |
| 27. | SQ2 |
Kapasitas retensi nutrisi (Karbon organik tanah, tekstur tanah, kejenuhan basa, kapasitas tukar kation tanah dan fraksi liat) |
| 28. | SQ3 |
Kondisi perakaran (Tekstur tanah, bulk density, fragmen kasar, sifat tanah vertikal dan fase tanah yang mempengaruhi penetrasi akar dan kedalaman tanah dan volume tanah) |
| 29. | SQ4 |
Ketersediaan oksigen untuk akar (Drainase tanah dan fase tanah yang mempengaruhi drainase tanah) |
| 30. | SQ5 |
Kadar kelebihan garam (Salinitas tanah, sodisitas tanah dan fase tanah yang mempengaruhi kondisi garam) |
| 31. | SQ6 |
Toksisitas (Kadar calcium carbonate dan gypsum) |
| 32. | SQ7 |
Workability (tanpa adanya penghambat) (Tekstur tanah, kedalaman/volume efektif tanah, dan fase tanah yang membatasi pengelolaan tanah (kedalaman tanah, singkapan batuan, kekasaran, kerikil/konkresi, dan hardpans)). |
- Informasi tambahan fitur
SQ:
1: Tidak ada atau sedikit batasan.
2: Batasan sedang.
3: Batasan parah
4: Batasan yang sangat parah
5: Terutama non-tanah
6: daerah permafrost
7: Badan air.





- Kategori default

- Kategori menjadi binary








Sebagaimana telah disampaikan, bagian ini terbagi menjadi dua yaitu data preprocessing dan data wrangling:
Proses preparation yang dilakukan langsung setelah data mentah diambil sebelum dilakukan proses exploratory.
-
Memilih data mulai dari tahun 2017 hingga 2020 (hanya data
test_timeseries dan validation_timeseriesdari sumber original)Hal ini dilakukan mengingat data observasi keseluruhan dimulai sejak tahun 2000 dengan total ukuran datasets sebesar ±2.7 GB, total baris sebanyak ±23.8 juta, dan sebanyak 21 fitur, jika langsung diterapkan menggunakan keselurahan datasets, maka membutuhkan komputasi baik memori serta waktu yang luar biasa besar. Sehingga dilakukan iterasi mengambil sampel beberapa datasets hingga diambil keputusan berdasarkan kemampuan menghasilkan model yang baik dengan tetap mempertahankan jumlah data serta tidak membutuhkan komputasi yang sangat besar, bahwa hanya data observasi pada rentang waktu tersebut saja untuk digunakan.
-
Mengambil data yang menunjukkan tingkat drought secara bulat (bukan peralihan)
Kelas pada data yang menunjukkan fenomena drought memiliki 5 kelas, akan tetapi tidak semuanya ditunjukkan secara diskret (bulat), beberapa diantaranya tidak sedikit berada pada bilangan desimal (dapat menunjukkan kelas tersebut sedang masa peralihan atau terjadi kesalahan saat pengumpulan dataset). Sehingga perlu dilakukan proses filtering dengan hanya mengambil kelas yang menunjukkan level drought tersebut. Selain itu dikarenakan hasil observasi drought hanya terjadi setiap pekannya, maka terdapat banyak data harian meteorological memiliki NAN Values. Pada kasus supervised learning seperti ini tidak terdapatnya kelas akan menjadi masalah, oleh karena itu dilakukan pendekatan filter tersebut (sudah sekaligus menghilangkan NAN values) sehingga menyisakan dataset yang memiliki nilai pada kelasnya dan jumlah baris pada dataset menjadi ±460 ribu baris.
-
Mengekstrak fitur bulan berdasarkan fitur tanggal
Cuaca dan iklim salah satu yang berhubungan dengannya adalah informasi berkaitan dengan musim. Maka diputuskan musim diambil dari fitur tanggal dengan mengekstrak fitur bulan. Fitur tersebut diekstrak dengan memperluas pembagian musim menjadi adanya early, mid, dan late dari 4 musim yang ada agar lebih mendetailkan ciri khas dari setiap musim tersebut. 11
-
Menambahkan informasi wilayah berdasarkan climate dari data pendukung
Menurut penelitian yang dilakukan salah satunya menunjukkan, 12 informasi berdasarkan iklim ini dijelaskan yaitu daerah atau suau wilayah tertentu dapat memiliki suatu ciri khas (pola) yang menunjukkan kecenderungan keadaaan iklim pada wilayah tersebut. Sehingga diputuskan untuk menambahkan fitur ini yang dapat memperbanyak informasi terhadap dataset untuk dilakukan pemodelan.
-
Menggabungkan dataset meteorological dengan dataset soil
Kemudian langkah preprocessing terakhir adalah dengan menggabungkan seluruh datasets menjadi satu buah dataset agar memudahkan dalam pembuatan model. Proses penggabungan ini diterapkan dengan melakukan left join data soil ke data meteorological berdasarkan informasi key sama pada fitur fips yang menunjukkan kode county pada Amerika Serikat. Setelah dilakukannya proses tersebut maka perlu dihapus informasi dari state Alaska, Hawaii, dan Puerto Rico karena tidak terdapat pada dataset awal.
Proses preparation yang dilakukan setelah dataset dilakukan proses exploratory untuk menyesuaikan agar mendapatkan model machine learning yang baik.
-
Merubah kelas kategori drought menjadi hanya dua
Kategori pada data yang menunjukkan fenomena drought memiliki 5 level tingkatan dengan dimulai dari D0 hingga D4, akan tetapi mengacu kepada tujuan untuk memprediksi fenomena drought bukan mengklasifikasikannya dari tingkat keparahan. Maka tingkatan level yang menunjukkan drought dimulai dari D1 hingga D4 digabungkan menjadi satu kelas. Sehingga kelas D0 akan menjadi kelas NO Drought (dilambangkan angka '0') dan D1 hingga D4 menjadi kelas Drought (dilambangkan angka '1').
-
Membagi dataset ke dalam data validation (2 bulan terakhir/ 3% dari total data) dan data train (sisanya atau 97%)
Melakukan suatu proses evaluasi sebelum menerapkannya pada data sebenarya diperlukan pembagian dataset setidaknya ke dalam dua bagian yaitu data train dan data validation. Hal ini perlu dilakukan agar dapat menguji performa model berdasarkan metrik yang telah ditetapkan. Pembagian sendiri dilakukan dengan perbandingan 97:3 yang dilakukan secara manual dengan mengambil data 2 bulan terakhir sebagai data validation. Proses latih model sendiri akan dilakukan pada data train untuk kemudian akan diuji secara terpisah pada data validation dengan harapan hasil pengujian mendapatkan performa sebaik pada data train. Proses ini dilakukan cukup awal demi menghindari terjadinya data leakage pada kedua data tersebut.
-
Mengubah fitur ke dalam tipe angka
Model machine learning memerlukan fitur pada dataset dalam format angka untuk dilatih. Sehingga diperlukan proses pengubahan terutama dalam fitur region iklim perlu dilakukan. Proses pengimplementasian dilakukan dengan bantuan LabelEncoder yang bekerja dengan mengganti label asli fitur ke dalam angka diskret dimulai dari '0' hingga 'total kategori-1' dan dilakukan pada fitur categorical.
-
Menghilangkan data outliers pada data train
Outliers merupakan suatu nilai tidak wajar pada dataset yang dapat mengakibatkan analisis statistik menjadi kacau serta merubah asumsi yang telah ada sebelumnya. 13 Pada model sendiri adanya nilai tidak wajar ini dapat mengakibatkan interpretasi yang dihasilkan kurang begitu bagus dan berdampak terhadap performa model itu sendiri. Salah satu tindakan dalam menangani nilai tidak wajar adalah dengan membuangnya dan hal ini yang akan diterapkan dengan pendekatan nearest neighbors. Cara kerjanya dengan melakukan voting terhadap beberapa neighbors terdekat yang dihitung berdasarkan jarak manhattan. Kemudian hasil voting tersebut dapat menunjukkan apakah nilai yang terdapat pada dataset termasuk ke dalam outliers atau bukan. Proses ini dipilih karena menerapkan asumsi dari populasi memiliki batas wajar dalam hal observasi data meteorological.
-
Mengatasi data tidak seimbang dengan proses oversampling serta undersampling
Jumlah data yang tidak seimbang dapat menyebabkan model memiliki performa yang tidak sesuai harapan. Pada kasus nyata hal ini sangat dihindari karena model diharapkan memiliki kemampuan lebih utama dalam mendeteksi kelas positif (yang biasanya dilambangkan dengan selain angka '0'). Sehingga diperlukan penanganan terhadap distribusi kelas pada datasets yang dilakukan dengan menerapkan oversampling sekaligus undersampling. Teknik oversampling atau memperbanyak data dilakukan pada kelas minority yaitu Drought dengan mengimplementasikan SMOTENC (Syntethic Minority Oversampling Method for Nominal and Continous) yang bekerja dengan membuat suatu data sintetis baru baik untuk data kuantitatif serta data kualitatif yang didasarkan pada nearest neighbors berdasarkan jarak euclidian. Kemudian pada kelas majority diterapkan undersampling menggunakan TomekLinks yang bekerja dengan menerapkan prinsip nearest neighbors jika mendapatkan kelas tersebut lebih dekat kepada neighbors kelas minority maka akan dihilangkan dari dataset. Penerapan kedua metode sekaligus adalah agar menghilangkan bias yang timbul setelah diperbanyaknya kelas minority dengan mengurangi kelas majority. 14
-
Melakukan data standardization pada semua fitur
Tahapan terakhir dengan melakukan proses standardization pada semua fitur datasets kecuali response variable. Proses ini dilakukan dengan mneghilangkan nilai mean dan mengubah ke dalam satuan unit variance sama. Pentingnya tahap ini adalah karena beberapa algoritma membutuhkan asumsi data yang berada pada distrbusi sama atau format rentang sama (
sensitif terhadap feature scaling). Selain itu proses ini dapat mempersingkat jarak yang dibutuhkan terutama pada penghitungan nilai error atau loss pada performa model. 15 Fungsi persamaan dalam melakukan standardization terlihat pada gambar berikut.
:max_bytes(150000):strip_icc():format(webp)/zscore-56a8fa785f9b58b7d0f6e87b.GIF)
11. ukgardening. (2021). Planting seasons.
12. Thomas R. Karl & Walter James Koss, 1984: "Regional and National Monthly, Seasonal, and Annual Temperature Weighted by Area, 1895-1983." Historical Climatology Series 4-3, National Climatic Data Center, Asheville, NC, 38 pp.
13. Jim Frost. (2021). Guidelines for Removing and Handling Outliers in Data.
14. Zeng, M., Zou, B., Wei, F., Liu, X., and Wang, L. (2016). Effective prediction of three common diseases by combining SMOTE with Tomek links technique for imbalanced medical data. 2016 IEEE International Conference of Online Analysis and Computing Science (ICOACS), pp. 225–228..
15. Aniruddha Bhandari. (2020). Analytics Vidhya: Feature Scaling for Machine Learning: Understanding the Difference Between Normalization vs. Standardization.
Data yang telah dilakukan preparation dengan baik kemudian digunakan pada proses modelling dengan menerapkan satu algoritma baseline, selanjutnya dilakukan perbandingan terhadap beberapa algoritma lain, dan terakhir hasil perbandingan tersebut akan diambil satu model terbaik untuk dikembangkan lebih lanjut dengan harapan mengalami peningkatan performa.
-
Model baseline
Pada tahap ini model baseline yang digunakan adalah Logistic Regression tanpa menerapkan parameter khusus. Kemudian melakukan pengujian dengan memprediksi data validation yang selanjutnya performa model diukur.
-
Model perbandingan
Setelah melihat performa pada model baseline, maka dilakukan penambahan model baru sejumlah tiga yaitu SVM, MLP, dan LGBM. Kemudian ketiga model baru dilakukan proses pengujian dengan memprediksi data validation yang selanjutnya performa model terukur dibandingkan dengan model baseline.
-
Model pengembangan
Terakhir berdasarkan perbandingan dari keempat model, selanjutnya dilakukan proses optimasi mengimplementasikan hyperparameter tuning dengan harapan performa model terbaik dari hasil perbandingan tersebut mengalami peningkatan dan semakin baik serta handal dalam menangani permasalahan ini.
Berikut adalah hasil model terbaik yang didapatkan:

Beserta contoh prediksi dari model terbaik tersebut:




Hasil prediksi fenomena:

Evaluation 16
Metrik yang digunakan pada proyek permasalahan ini adalah accuracy, precision, recall, f1 score, dan ROC-AUC. Hasil performa dari semua model yang telah dibangun terlihat pada tabel dan gambar di bawah serta di bawahnya lagi terdapat penjelasan lebih detail mengenai kelima metrik tersebut.


Merupakan metrik yang akan menjadi dasar dari perhitungan metrik yang digunakan.

- True Positive (TP): Jumlah prediksi dari kelas positif yang diprediksi secara benar oleh model sebagai kelas positif.
- True Negative (TN): Jumlah prediksi dari kelas negatif yang diprediksi secara benar oleh model sebagai kelas negatif.
- False Positive (FP): Jumlah prediksi dari kelas negatif yang diprediksi secara salah oleh model sebagai kelas positif. Biasa juga disebut sebagai type 1 error.
- False Negative (FN): Jumlah prediksi dari kelas positif yang diprediksi secara salah oleh model sebagai kelas negatif. Biasa juga disebut sebagai type 2 error.
Metrik yang menunjukkan keseluruhan performa dari model atau dengan kata lain menunjukkan berapa banyak kelas yang diprediksi dengan benar oleh model. Merupakan model paling sering dipakai namun pada kasus data tidak seimbang memiliki kerentanan terhadap salahnya interpretasi performa (bias). Persamaan dari metrik ini sendiri adalah sebagai berikut:

Metrik yang menunjukkan seberapa baik model melakukan prediksi kelas positif dengan benar sebagai kelas positif (aktual). Namun metrik ini tidak dapat menggambarkan secara jelas kelas positif (aktual) memiliki berapa banyak hasil prediksi benar. Persamaan dari metrik ini sendiri adalah sebagai berikut:

Metrik yang menunjukkan seberapa baik kelas positif (aktual) diprediksi dengan benar sebagai kelas positif. Namun metrik ini tidak dapat menggambarkan seberapa baik model melakukan prediksi kelas positif sebagai kelas positif (aktual). Persamaan dari metrik ini sendiri adalah sebagai berikut:

Metrik yang menutupi kekurangan pada precision dan recall didalam penilaian performa terhadap kelas positif dengan cara menghitung rata-rata harmonic dari keduanya. Namun dikarenakan kedua metrik sebelumnya hanya berfokus pada kelas positif menyebabkan f1 score juga tidak dapat menggambarkan secara spesifik penilaian performa terhadap kelas negatif. Akan tetapi semua hal tersebut diatasi dengan menerapkan versi weighted yang memperhitungkan keseluruhan kelas yang ada beserta distribusinya. Persamaan dari metrik ini sendiri adalah sebagai berikut:

ROC AUC Score 17
Metrik yang dapat menunjukkan relasi antara TPR dengan FPR (False Positive Rate) atau dengan kata lain menunjukkan performa dari model dalam semua ambang batas pada proses prediksi yang dilakukan. Namun metrik ini kurang begitu bagus jika digunakan pada kasus yang lebih cenderung hanya mempertimbangkan kelas positifnya seperti pada kasus real. Persamaan dari metrik ini sendiri adalah sebagai berikut:


16. Joydwip Mohajon. (2020). towardsdatascience: Confusion Matrix for Your Multi-Class Machine Learning Model.
17. Google. (2021). Machine Learning Crash Course: "Classification: ROC Curve and AUC".
Terdapat 11 tahapan pada data preparation yang dilakukan sehingga dataset dapat digunakan dalam proses latih model. Kemudian model dengan performa metrik terbaik serta >70% diraih oleh model LightGBM tanpa adanya proses hyperparameter tuning. Namun, hasil tersebut menunjukkan bahwa adanya kemungkinan proses data preparation dapat lebih ditingkatkan lagi serta dalam pengolahan data tidak seimbang dapat memperbanyak jumlah dataset (seperti menggunakan rentang tahun lebih lama (dataset original train)) agar mendapatkan hasil lebih baik dan aman dari masalah data tidak seimbang. Serta, dapat melihat dan mencoba dengan model lain lagi atau menggunakan pendekatan hyperparameter tuning berbeda.
---Ini adalah bagian akhir laporan---