This repository contains codes and scripts to perform Face Clustering task.
Face clustering is the task of grouping unlabeled face images according to individual identities. Several applications require this type of clustering, for instance, social media, law enforcement, and surveillance applications.
Face recognition and face clustering are different, but highly related concepts. When performing face recognition we are applying supervised learning where we have both (1) example images of faces we want to recognize along with (2) the names that correspond to each face (i.e., the “class labels”).
But in face clustering we need to perform unsupervised learning — we have only the faces themselves with no names/labels. From there we need to identify and count the number of unique people in a dataset.
This project is executed in 2 steps :
-
One to extract and quantify the faces in a dataset
-
And another to cluster the faces, where each resulting cluster (ideally) represents a unique individual.
--> As a quick breakdown, here is everything you’ll need in your Python environment:
- OpenCV
- dlib
- face_recognition
- imutils
- scikit-learn

I have put together a dataset of five soccer players, including:
- Mohamed Salah
- Neymar Jr.
- Cristiano Ronaldo
- Lionel Messi
- Luis Suarez
In total, there are 125 images in the dataset. It is not necessary to put them in seperate folders. I have done it for ease in organizing images, only.
Our goal will be to extract features quantifying each face in the image and cluster the resulting “facial feature vectors”. Ideally each soccer player will have their own respective cluster containing just their faces.
Our project has mainly one directory and three files:
-
data/ : Contains 129 pictures of our five soccer players. Notice in the output above that there is no identifying information in the filenames or another file that identifies who is in each image. It would be impossible to know which soccer player is in which image based on filenames alone. We’re going to devise a face clustering algorithm to identify the similar and unique faces in the dataset.
-
encode_faces.py : This is our first script — it computes face embeddings for all faces in the dataset and outputs a serialized encodings file.
-
encodings.pickle : Our face embeddings serialized pickle file.
-
cluster_faces.py : The magic happens in this script where we’ll cluster similar faces and ideally find the outliers.
- encode_faces.py -->
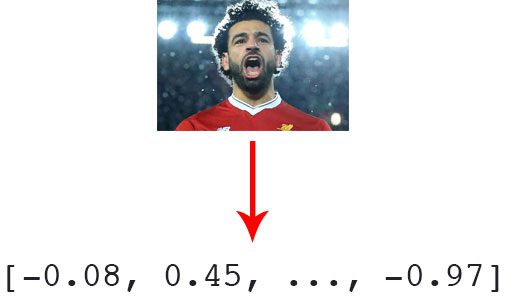
This is done is 2 phase :
-
Accepting an input image
-
And outputting a 128-d feature vector that quantifies the face. This is serialized and saved into a pickle object - encodings.pickle

- cluster_faces.py -->
Now that we have quantified and encoded all faces in our dataset as 128-d vectors, the next step is to cluster them into groups.
Our hope is that each unique individual person will have their own separate cluster.
The problem is, many clustering algorithms such as k-means and Hierarchical Agglomerative Clustering, require us to specify the number of clusters we seek ahead of time.
For this example we know there are only five soccer players — but in real-world applications you would likely have no idea how many unique individuals there are in a dataset.
Therefore, we need to use a density-based or graph-based clustering algorithm that can not only cluster the data points but can also determine the number of clusters as well based on the density of the data.
For face clustering I would recommend two algorithms:
-
Density-based spatial clustering of applications with noise (DBSCAN)
We’ll be using DBSCAN for this tutorial as our dataset is relatively small. For truly massive datasets you should consider using the Chinese whispers algorithm as it’s linear in time.
The DBSCAN algorithm works by grouping points together that are closely packed in an N-dimensional space. Points that lie close together will be grouped together in a single cluster.
DBSCAN also naturally handles outliers, marking them as such if they fall in low-density regions where their “nearest neighbors” are far away.
Let’s go ahead and implement face clustering using DBSCAN.

Later , the developer can assign a unique Name to the different cluster groups(here name of those soccer players).