
Riverside County has a low retention rate in their Department of Public Social Services whether an employee is leaving for another job or transferring between different divisions within the same department. This causes employee instability in the workplace and diminishes the available resources and time since the positions take time to fill and new employees require training. The goal of this project is to find what causes the low retention rate by looking at provided data and looking and demographics such as salary, age, education, etc. We will also be using ML model to analyze the features and find any correlations between the features.
Demo: Run the notebooks. kfold.ipynb and distance_calculation.ipynb are still work in progress.
-
Use the dataset named source_2021-12-07-09-51-43.csv ( inside Machine Learning Models ) to run the following ML models inside Machine Learning Folders
-
With Feature Importance)Logistic Regression Updated .ipynb
-
With Feature Importance)Random Forest F1 scores - Updated with graph.ipynb
-
Without Feature Importance)Logistic + Random + Support Vector (Multiple Features).ipynb
-
Without Feature Importance)Logistic + Random Forest + Support Vector (3 Features).ipynb
-
Without Feature Importance)Logistic + Random Forest + Support Vector (4 Features).ipynb
-
Random Forest F1 scores.ipynb
You can use the attached PowerBI file and use the PowerBI application to view the dashboard. Data analysis and ML analysis are located in the .ipynb notebook files which you can look at our analysis or run the code yourself.
In order to run the Notebooks, install Jupyter Notebook and upload the notebooks. For any dependencies used in the notebook, view Dependencies.
Due to the unique nature of our project, we do not have diagrams. Instead we outline our project with features and descriptions on how we plan to use the ML model; list of tools, methods, and algorithms we will use; and mockups of our end-product.
-
Age - Visualize the age group of people in each department, and calculate the retention rate for this
-
Duration - Calculate the average number of days employees stayed in each department or left the job
-
Distance - Calculate how distance plays a role in an employee staying or quitting the job using Google Maps API
-
Hourly Pay/Department name - Find the average of how hourly pay has changed over the years in each department and then compare that with different counties. See if hourly pay has an effect on duration. For example comparing Riverside County vs Los Angeles County etc
-
Change Division - Calculate how many employees changed the division in recent years
-
Between Divisions - compare retention rate and salary between divisions
- Jupyter Notebook and Google Colab for data analysis in Python
- PowerBI for the dashboard as this is what Riverside County currently uses to visualize the data
- Web scraping of websites to find salary and cost of living of similar job positions
- ML tools such as linear regression and KNN to analyze the dataset
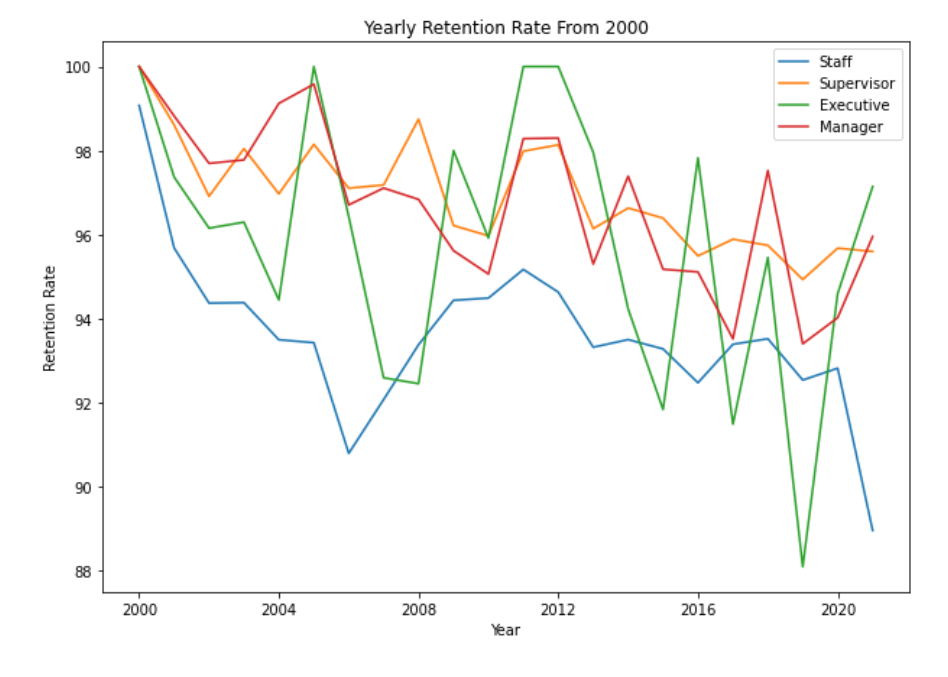
- Shows it is declining since 2010


- Children Services has the lowest retention rate followed by Self-Sufficency


- There’s no correlation between gender and retention rate as they trend together


- Staffs have lower retention rate compared to other groups

- There is no correlation between distance from work and home and retention rate.


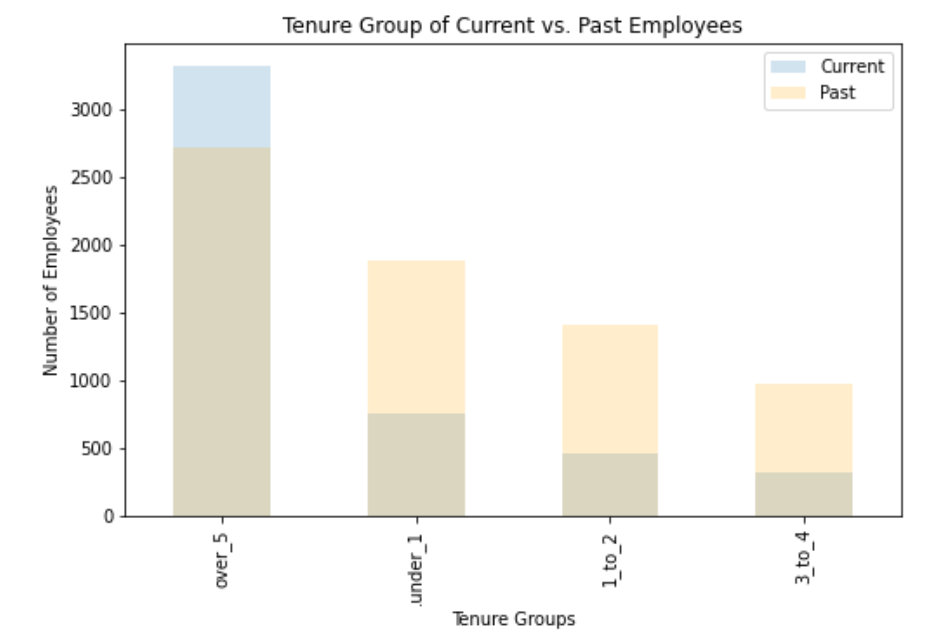
- Shows the duration of employment in the department
- Majority of employees (both past and current) has been employed for more than 5 years
- About 36% of the employees in our data were past employees who worked less than 5 years

- The number of past employees who worked less than 5 years in Children Services is higher than average


- This might be misleading as we are looking at ending age group
- Those who stay longer will moves up into higher age group so there’ll be less employees who had worked less than 5 years in those age groups


- There is less correlation when looking at the age group of when the employees were hired

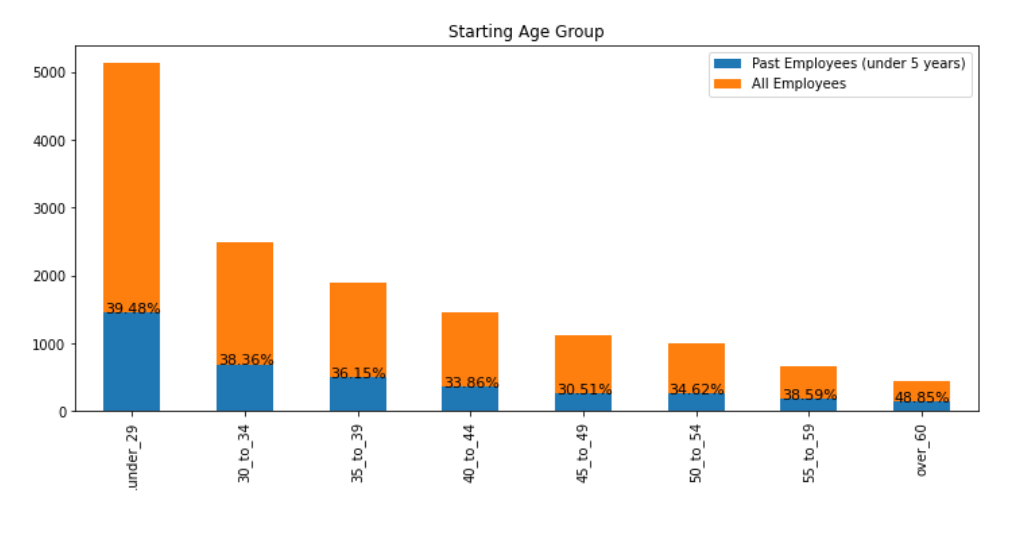
- Staffs has more employees who worked less than 5 years compared to others


- The distribution of comprate for past employees who worked less than 5 years is more to the left


- F1 scores: 71.39%, 70.97%, 76.50%, 78.09%, 80.82%, 50.58%
- Accuracy for each label:
- Retirement: 76.96%
- Termination: 88.82%
- Working: 51.85%


- Accuracy for each label:
- Retirement: 70.96%
- Termination: 81.19%
- Working: 25.67%


- Features: Duration, Age_group, comprate, Division, Last_pay_raise
- Labels and prediction accuracy
- Retirement (43.97%), Termination (77.32%), Working (55.18%)
- F1 Scores:19.36%, 67.82%, 76.5%, 78.33%, 79.11% and 64.22% average
-----------------------------------------------------------------------------------------------------------------------------
Everything below includes the MockUps and Draft versions we worked on early in the quarter to understand and clean the dataset.
-----------------------------------------------------------------------------------------------------------------------------
- Regression Analysis



PowerBI dashboard

- This was done during last quarter when we were trying to understand and clean the data.
Attrition Distribution ( Ex-employees vs Current employees )

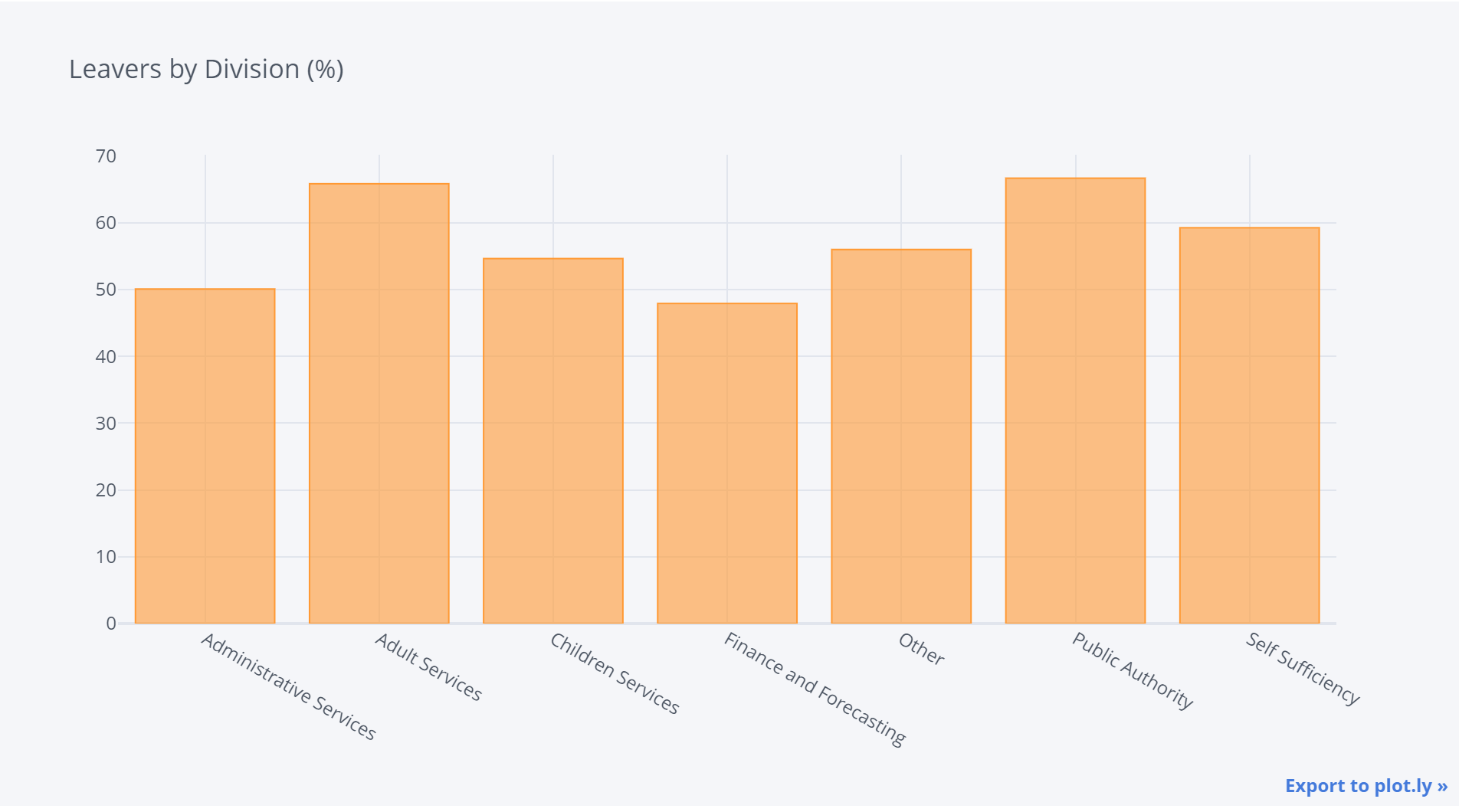
Leavers by division

Leavers by Jobrole
- Install pip Helpful Documentation
- Libraries to install using pip
- pandas Documentation
- numpy Documentation
- plotly Documentation
- scikit-learn Documentation
- xgboost Documentation
- Install googlemaps. Helpful Documentation