This repository provides implementation of the algorithm of the paper available at https://arxiv.org/abs/1902.11132
In this paper, we propose a generative model to learn compact latent codes that can efficiently represent and reconstruct a video sequence from its missing or under-sampled measurements. We propose a low rank constraint on the corresponding latent codes of the neighboring frames in the video sequence which allow us to represent the whole video sequence with very few number of latent codes. We also could linearize the articulation manifold of a video sequence by imposing low-rank structure on the latent codes. Furthermore, we demonstrate that even if the video sequence does not belong to the range of a pretrained network, we can still recover the true video sequence by jointly updating the latent codes and the weights of the generative network.
Some results:
| Reconstructions (Joint optimization with rank=2 (linear) constraint) | Corresponding latent code representation |
|---|---|
 |
 |
 |
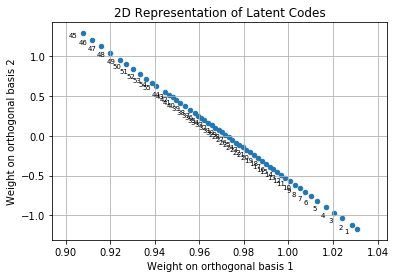 |
| Original | Generated | Interpolated (20x frames) | Corresponding latent code representation (2D plane on a 3D space) |
|---|---|---|---|
 |
 |
 |
 |
- python 2.7 (Anaconda for python 2.7: https://www.anaconda.com/distribution/)
- pytorch 0.4.1 (To install pytorch in Anaconda, run: "conda install pytorch torchvision cudatoolkit=9.0 -c pytorch")
- matplotlib 2.2.3 (Installing anaconda will automatically install it.)
- scipy 2.2.3 (Installing anaconda will automatically install it.)
- numpy 1.15.1 (Installing anaconda will automatically install it.)
The code is written for gpu enabled devices. You need to have nvidia driver installed to run it. (To install nvidia driver in Ubuntu OS, you may run: "sudo apt-get install nvidia-384" or "sudo apt-get install nvidia-current")
If you use this code in your research, please cite this paper:
Rakib Hyder and M. Salman Asif, "Generative Models for Low-Rank Video Representation and Reconstruction." arXiv preprint, arxiv:1902.11132, 2019.
@article{hyder2018GMLR,
author = {Rakib Hyder and M. Salman Asif},
title = {Generative Models for Low-Rank Video Representation and Reconstruction},
journal = {arXiv:1902.11132},
year = {2019}
}