{kind=link}
简体中文| English
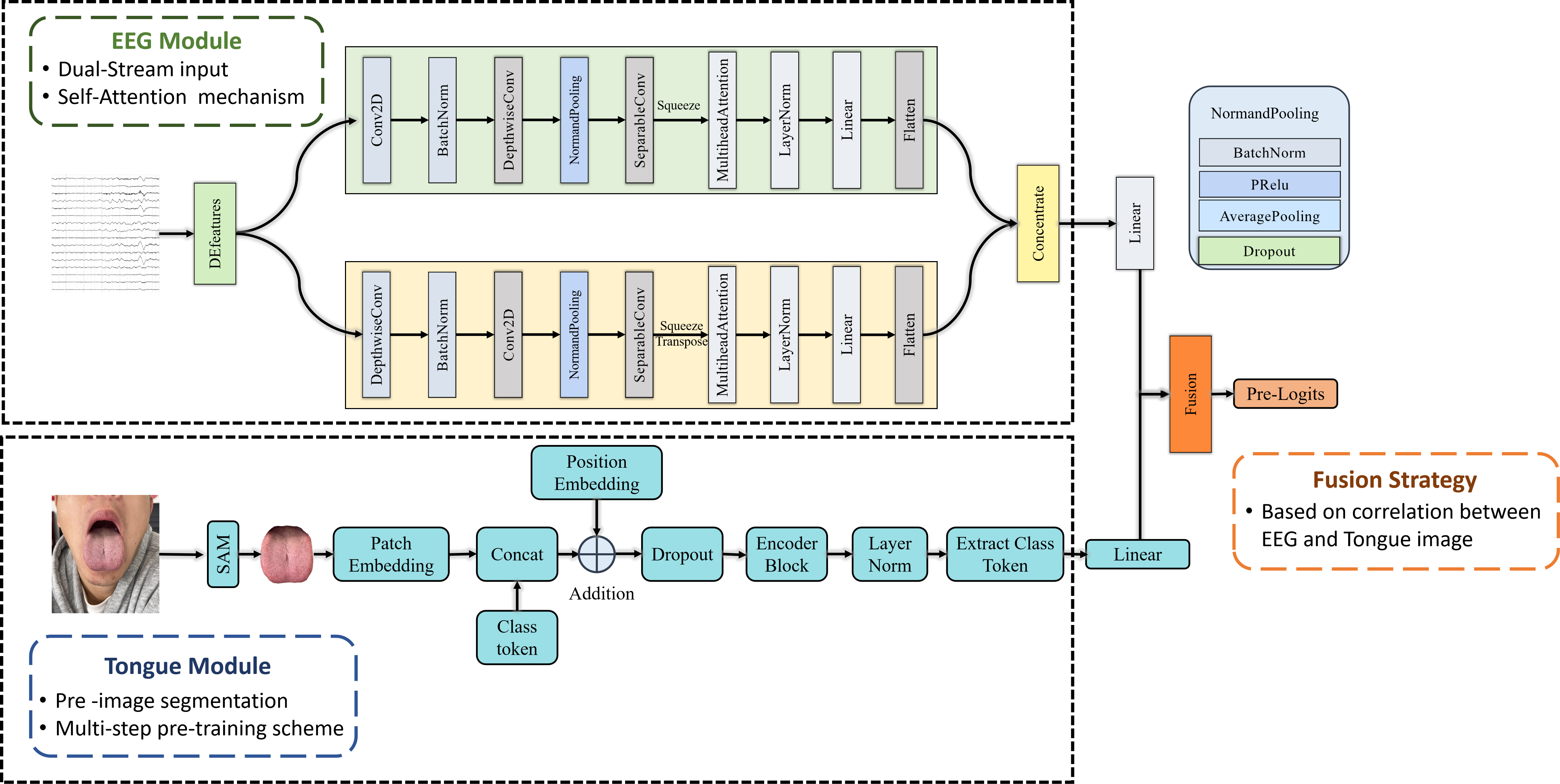
MMTV是一个基于脑电和舌象信息,结合患者瞬时脑部状态以及长期身体状况来诊断抑郁症的模型。该模型由三个模块组成,即脑电模块,舌象模块以及多模态模块。
在脑电模块中,我们提出了以双流输入和自注意力机制为特点的全新架构Trans_EEGNet。
在舌象模块中,我们为ViT设计了结合了图像分割,元学习等手段的预处理以及多步预训练方案。
在多模态模块中,我们验证了脑舌之间的相关性,并使用多种手段进行特征融合。
推荐读者仅阅读mmtv.ipynb即可。
-
README.md/README-EN.md: 提供项目的基本信息和使用说明。 -
overview.png:模型的总览。 -
mmtv.ipynb:模型整体运作的demo。 -
EEGPreProcess/: 脑电以及多模态数据预处理。 -
TongueLabelPreProcess/: 舌象数据标签处理。TongueLabelMap.py: 将舌象的文字标签合理转为数字编码。EEG2TongueLabels.py:将舌象的标签与同一被试者的EEG片段对应起来,便于进行脑舌相关性验证。
-
OnlineUtils/: 在线工具。 -
OtherCodes/: 补全代码。由于目录较乱不推荐阅读,核心代码已在mmtv.ipynb中详细给出,该部分仅作为补充理解。keras_CRNN.ipynb: 复现的上述4DCRNN架构及其子模块和变种模型,以及使用传统机器学习进行分类的代码。Trans_EEGNet.ipynb:Trans_EEGNet架构的各类变种,以及其处理其余数据集的示范。