Transfer between OpenAI Gym Environments
We created four DART environments that closely match those MuJoCo environments from OpenAI Gym:
-
Cart-pole: The model used in DART is identical to the one in MuJoCo.
-
Hopper: MuJoCo has a unique parameter called "armature" which is applies to the joints of the hopper. When comparing to DART, we set the armature of MuJoCo Hopper to zero.
-
Reacher: The joints of original reacher model in MuJoCo have nonzero armature as well. When setting the armature to zero, MuJoCo exhibits unstable behaviors. To match the effect of joint armature, we added joint stiffness and damping in DART.
-
2D Walker: The armature value for the 2D Walker in MuJoCo is small (0.01) and has relatively small effect on the results. We ignored this parameter and created an otherwise identical model in DART.
This table compares the average and variance of the reward (over 10 trials) between DART and MuJoCo. We used TRPO [Schulman et al] provided by rllab to train all the examples below. The scripts for running all the experiments can be found here.
| DART (ave) | DART (stdev) | MuJoCo (ave) | MuJoCo (stdev) | |
|---|---|---|---|---|
| Cart-pole | 1000 | 0 | 1000 | 0 |
| Hopper | 4,059.45 | 377.22 | 3,561.33 | 45.23 |
| Reacher | -4.52 | 3.33 | -5.45 | 1.70 |
| 2D walker | 3,396.02 | 165.86 | 3,665.94 | 341.27 |
For each environment, we trained five policies with different random seeds and picked the one with the highest reward for testing. This table shows the training parameters for the four tasks.
| # of Iterations | Batch Size | |
|---|---|---|
| Cart-pole | 50 | 5000 |
| Hopper | 500 | 50000 |
| Reacher | 500 | 25000 |
| 2D walker | 500 | 50000 |
Given the various differences in DART and MuJoCo, we are curious about whether a policy trained in one environment can be transferred to another environment. Below we show the results of policies trained in DART and tested on MuJoCo and vice versa.
Here is a policy trained on DART (left) and tested on MuJoCo (right):


And here is the opposite transfer: a policy trained on MuJoCo (left) but tested on DART (right):


It's not surprising that both policies can transfer to the other environment successfully because this example does not involve constraint solving, which causes the main discrepancy between DART and MuJoCo.
A DART policy (left) tested on MuJoCo (right):


A MuJoCo policy (left) tested on DART (right):


As shown in the videos, neither policy can transfer successfully to the other environment. We believe that this is due to the differences in contact modeling between DART and MuJoCo.
A DART policy (left) tested on MuJoCo (right):
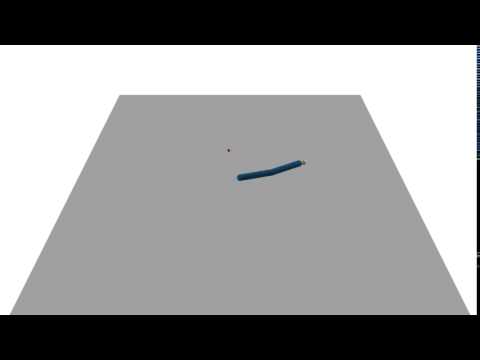

A MuJoCo policy (left) tested on DART (right):


Though there is no contact involved in this example, the armature parameter is the main source of discrepancy between the two environments. Since the purpose of armature is to modify the mass matrix (making the diagonal more dominant) to increase stability, we added some damping and spring force at each joint to stabilize the reacher in DART. Due to these differences, neither policy is able to transfer to the other environment.
To test the transferability in a better matched environment, we created a 3D reacher environment where the arm is heavier and the horizon is longer. As such, this 3D reacher can move stably in MuJoCo environment without the need of armature parameters. The comparison below shows that both policies can succeed in different environments.
A DART policy (left) tested on MuJoCo (right):

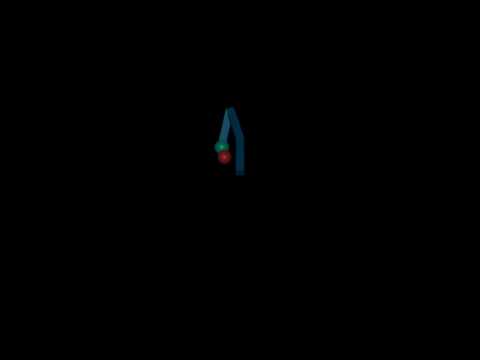
A MuJoCo policy (left) tested on DART (right):


A DART policy (left) tested on MuJoCo (right):


A MuJoCo policy (left) tested on DART (right):

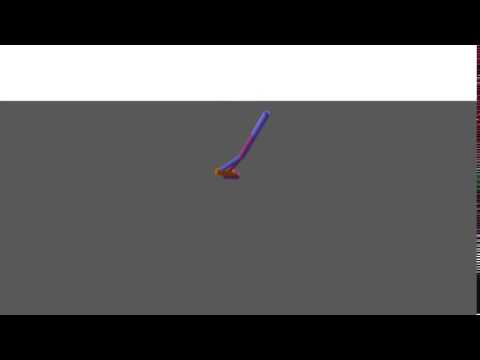
The policies in both environments learned to "walk" primarily using the ankles. Similar to the hopper example, the differences in contact modeling are likely to be the culprit of the failure in policy transfer.
So what if we tune the training regime to encourage a 'walking' policy? By simply lowering the strength of the ankle joints and adding a reward term for bending the knee, we were able to learn a policy that "walks" instead of "hops". More interestingly, such policies can transfer much better between the two simulators! This result seems to be consistent with our intuition that walking is a more robust form of locomotion than hopping.
A DART policy (left) tested on MuJoCo (right):
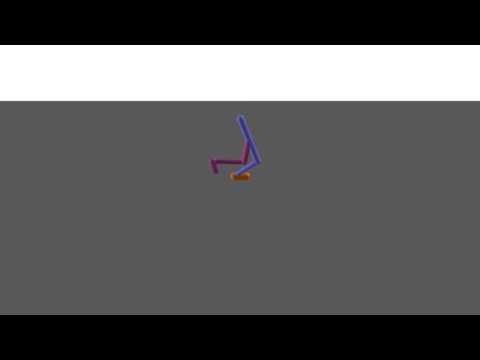

A MuJoCo policy (left) tested on DART (right):


These results came as no surprise. When the task does not involve constraint solving or joint armature, DART and MuJoCo achieve the same result in terms of policy learning. For contact-rich tasks like the hopper and the walker, we were not able to learn policies robust enough to succeed in a different environments using TRPO. However, with some minor changes like reducing the ankle strength and adding a reward term for bending the knee joint in the walker case, we showed that more robust policy can be learned and transferred. We conclude that, first, DART is a reasonable alternative physics engine to MuJoCo, and second, it is possible to learn a policy that is transferrable between two different physics engines. For researchers interested in transferring a policy from simulation to the real world, we hope that DART provides a good initial step toward the goal of closing the "reality gap".