SFC 是微服务环境中的服务流程管理系统,主要用于微服务治理,解决微服务的混沌问题。 随着服务拆分力度越来越细,服务调用流程渐渐变成不可知论。 基于 opentracing 协议的各种链路追踪系统一定程度解决了出 bug 后排查定位难的问题,但是一种被动的过程。 与链路追踪系统不同, SFC 是服务调用的前序流程,在服务定义之初,即已确定。
SFC 并不是退步,而是微服务不断演进的产物。 与 SOA 不同,引入 SFC 后,每个微服务仍旧拥有独立的生命周期。并且由于服务调用流程统一交由 SFC 的流程引擎处理, 各微服务无需再关注上下游信息,进一步降低服务间的耦合。 某种层面上来说, SFC 是 ESB 的子集。
ESB(Enterprise service bus) 主要职能:
- 服务间消息路由
- 服务间消息监控和控制
- 解析上下文
- 控制服务的部署和版本
- 服务传输内容的序列化
- 事件处理,数据转换与映射,事件队列,安全,异常处理,协议转换,沟通规范约定和控制等。
SFC 主要职能:
- 服务间消息路由
- 调用流程控制与监控
引用 SFC 模式后,项目将从以下几方面获利:
- 微服务间更低的耦合性。服务无需关心下游流程,微服务本身也不用去过多的嵌入业务流程
- 为服务的功能和产生的事件提供了统一的全局视图,便于管理
- 与以往的微服务管理模式各服务各自为政不同, SFC 提供了按业务线划分,跨服务进行管控的能力,提供了更好的服务治理、业务梳理视图
- 业务线启动、暂停、复制、进度跟踪、下线等传统微服务或普通的 Pub/Sub 无法实现的高级功能。
- 对于系统中产生的任一条数据,都有全生命周期的回溯能力。
本小节翻译自 netflix conductor 文档
在使用点到点的任务编排模式过程中,我们发现他很难适应快速增长的商业需求和业务复杂性。 在流程比较简单的时候,广播/订阅模式效果很好,但是随着业务复杂度提升,这种模式的问题也凸显出来:
- 业务流程内嵌到了多个应用(服务)中。这样通常会导致系统耦合度较高,使之更难适应频繁变化的场景。
- 几乎没有办法系统性的回答诸如“某项任务已经完成了百分之多少,进展到哪一步了?”之类的问题。
| version | basic goal |
|---|---|
| 0.1 | 支持 common mode 的 worker, 能新建工作流并跑起来 |
| 0.2 | 支持 specific mode 的 worker, 实现为指定工作流弹性伸缩 |
| 0.1 | 支持动态加载,增加,修改 worker 后,不用重启原 worker |
- event
- pub/sub
- API 调用
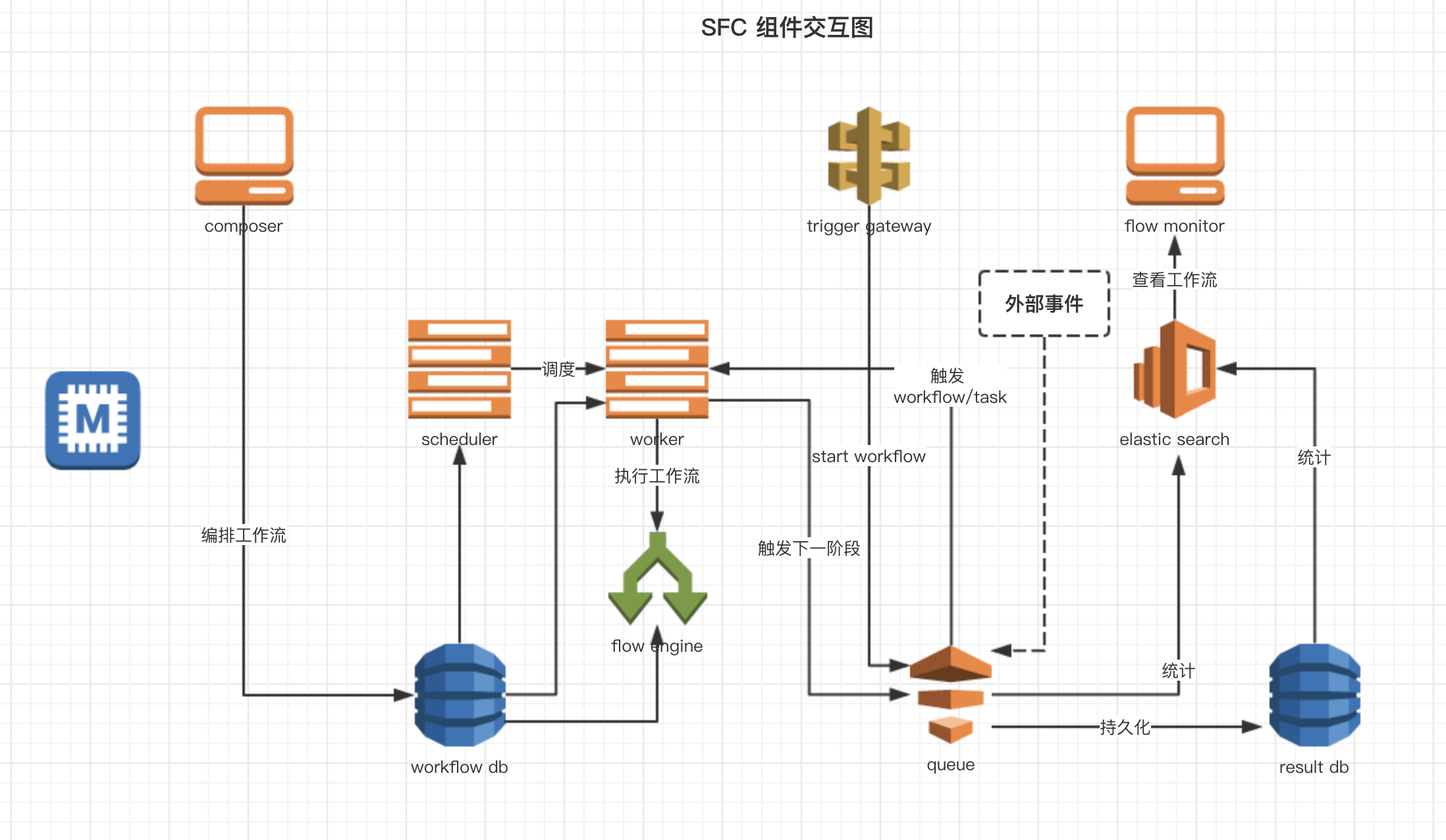
- composer
- flow engine
- job executor
- message queue
- flow monitor
- scheduler
- worker
- trigger gateway
通过图形化界面生成 workflow 的 blueprint。 blueprint 规定了工作流中的任务和如何决策。 blueprint 是符合 AWS state language DSL 的 json。
编辑/修改 blueprint blueprint 版本控制
解析 blueprint 决策工作流执行流程的状态机。状态机各个组成部分参见workflow一章。
调用或执行具体任务,理论上可以支持异步和同步两种模式,为了简单,暂时先只实现异步模式。
异步模式下, job executor 主要负责消息的传递和转发。
input topic: raw_order_tmall input consumer group: SFC
transfer topic: raw_order_tmall transfer consumer group: order_split6
为了实现 job 上下游解耦,以及工作流控制, SFC 要对消息做一次转发(有性能损耗,待优化)。 SFC 中的每个服务无需关心自己是否有下游服务,以及有多少个下游服务。 假设服务 A 被两个业务流程共用,分别被 B, C 共用,pub/sub 模式和 conductor 模式消息传递如下。
data flow in pub/sub mode and conductor mode.
pub/sub:
A
| topic: raw_order_tmall;consumer group: all
_______|________
| |
B C
conductor:
A
| topic: raw_order_tmall;consumer group: SFC
|
SFC(service flow conductor)
|
job-b______|_____________job-c
|group: order_split |group: finanical_statistic
B C
同步模式指的是 job 内部逻辑是同步的(RESTAPI, grpc),job 与 job 之间的通信仍然是异步。 同步模式下,job exector 负责调用任务的 API,然后收集 API 返回结果,传递到下游的消息队列中。 同步模式有以下好处:
- 业务服务无需关心调用方法,不用实现 kafka 消息收发机制,只关心业务逻辑,降低编程复杂度
- 不需要 SFC 进行消息转发,没有额外性能损耗,同时降低对存储空间的占用。
缺点: 同步阻塞,降低了 SFC 的吞吐量。
传递和存储任务的结果 目前仅支持 kafka 这个名字有点问题, 因为严格意义上说, kafka 的消息传递模式不是 queue, 而是 pub/sub。应该换个名字。
- 查看每类 blueprint 统计信息
- 查看每个 flow 状态信息
- 启动/停止 blueprint
- 重试 flow
flow monitor 基于 Elasticsearch 实现。
由于每个工作流的处理的数据流和处理效率差异很大,我们实现了一套调度器机制,为每个 workflow 动态地分配资源。 主要实现以下功能。
- 增加/删除 worker
- 调整指定 workflow 的 worker 副本数量
更详细信息请查看 behind the scenes
worker 用来执行 job executor 的任务,调用接口,收发队列消息等。 worker 有两种模式:
- common: 可以执行所有的 job
- specific: 仅执行指定类型的 workflow 的 job
SLA 为 S0 或每天执行次数大于 1w 次的,推荐使用 specific 类型。
每个类型的 workflow 都需要有对应的 worker 才能使工作流流转起来。
接收 HTTP 请求用于外部应用触发工作流。
common 模式下, 所有消息都进入到一个 topic 中。 TODO: specific 模式下,是为每个 task 建立 topic, 还是为每个 workflow 建立 topic? TODO: 启动工作流的时候,是发一个 http 请求,此时要不要往某个 topic 中推消息?
topic 和 consumer group 例子: topic: raw_order_tmall consumer group: order_split1
- common
- specific
example:
"HelloWorld": {
"Type": "Task",
"Mode": "Sync",
"Processor": "arn:aws:lambda:us-east-1:123456789012:function:HelloWorld",
"Next": "NextState",
"Comment": "Executes the HelloWorld Lambda function"
}- Task
- Choice
- Parallel
- Succeed
- Fail
- Join(extend)
Amazon States Language
https://states-language.net/spec.html
技术架构与组织架构相辅相成。每条业务线,有相应的负责人。你可以称他为 流程管理员/技术接口人/项目负责人/... 但是其本质上就是对某条业务线全生命周期负责。 其工作内容不局限在某一服务,该流程出现任何问题,业务线负责人都负责解决。
Conductor 是一个微服务编排引擎。
https://github.com/Netflix/conductor
http://dockone.io/article/1930
AWS Step Functions 将多个 AWS 服务协调为无服务器工作流。
https://aws.amazon.com/cn/step-functions/
为了提高系统的可复用性, task meta 被定义为全局的,而不是隶属于某个 workflow meta, 当 workflow 中需要使用 task 时,会创建 task reference, 上记录 task name, task version, task input path
为解决更新运行中的工作流的问题, task meta 和 workflow meta 都有版本信息。
每建一个 workflow 生成一个新的资源。 这个资源是一个进程还是一个 docker contqiner? 调度器是使用 go plugin 还是 kubernetes?
为每个 job 指定不同的 topic, 为每个 workflow 指定不同的 topic, 还是所有任务共用一个 topic?
添加 workflow 后,要想启用,就得加新的 worker 吗? 修改 workflow 变更版本后,就得重启对应的 worker 吗?
kafka 消息处理有两种模式: publish-subscribe 和 queue。 这个是可以在 topic 创建的时候选择的。
- publish-subscribe 模式会把每条消息广播给所有消费者
- queue 模式保证每条消息只传递给一个 consumer。
通过给想暂停或恢复的 workflow 监听的 queue 中推送特殊类型的消息实现。 confluentinc/confluent-kafka-go#280
https://github.com/confluentinc/confluent-kafka-go/blob/master/kafka/consumer.go
workflow meta 变更后, workflow meta 的 version 都会 +1。
如果 task meta 版本更新, 已经引用该 task meta 的 workflow meta 并不会自动更新, 需要手动更改 task reference 后才会使用新的 task meta(并且会导致 workflow 版本 +1).
更新正在使用中的 workflow 的 workflow meta 时,workflow 受影响如下:
- 已经执行完的工作流没有影响,查看记录时看到的也是旧版本的 workflow meta
- 正在执行中的工作流没有影响,查看记录时看到的也是旧版本的 workflow meta
- 后续新启动的工作流默认都使用最新版本的 workflow meta