{kind=link}
This project will include the files neccessary to build an ETL pipeline for a Data Lake hosted on S3. The objective of this project is to succesfully extract data from an S3 bucket and to process it with Spark to load them back into another S3 bucket as a set of dimensional tables. This Spark process will be deployed on a cluster using AWS.
This repository simulates the creation of an ETL pipeline for a music streaming startup whose data resides in S3 and want to move their data warehouse to a data lake.
The data currently is in an S3 bucket in directories which contains their log data and song data in JSON files. The objective of the main program of this repository is to process the data and create a star schema optimized for queries for the song play analysis.
The datasets used for this project that reside in S3 are:
- Song data: s3://udacity-dend/song_data
- Log data: s3://udacity-dend/log_data
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song's track ID. Here is an example of a filepath: "song_data/A/B/C/TRABCEI128F424C983.json" And here is an example of one of the json files: {"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations. Here is an example of a filepath: "log_data/2018/11/2018-11-12-events.json" And here is an example of a json file for these events: {"artist": "None", "auth": "Logged In", "gender": "F", "itemInSession": 0, "lastName": "Williams", "length": "227.15873", "level": "free", "location": "Klamath Falls OR", "method": "GET", "page": "Home", "registration": "1.541078e-12", "sessionId": "438", "Song": "None", "status": "200", "ts": "15465488945234", "userAgent": "Mozilla/5.0(WindowsNT,6.1;WOW641)", "userId": "53"}
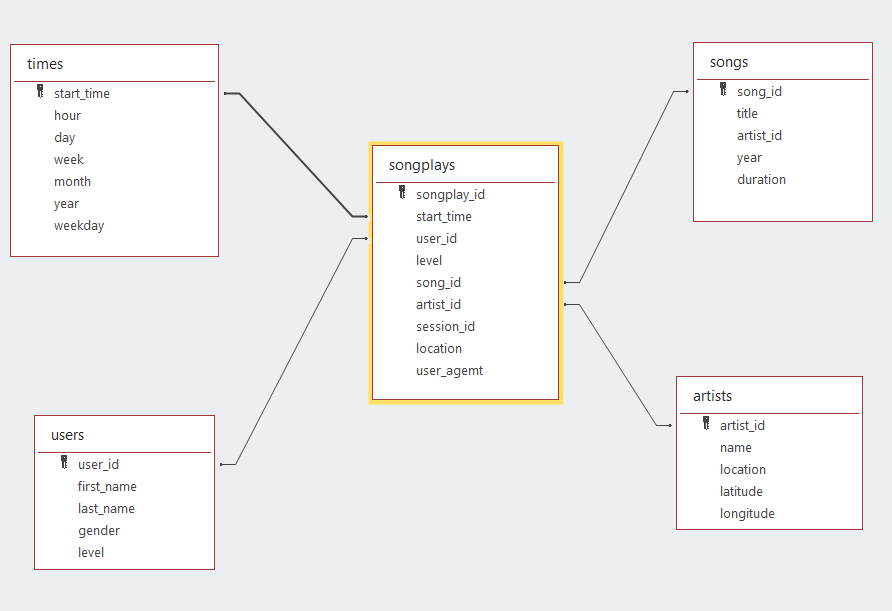
The star schema that is going to be created using this program will have the next structure:
- Fact table:
- songplays [songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent]
- Dimension tables:
- users [user_id, first_name, last_name, gender, level]
- songs [song_id, title, artist_id, year, duration]
- artist [artist_id, name, location, lattitude, longitude]
- time [start_time, hour, day, week, month, year, weekday]
This file contains the AWS credentials to access the S3 buckets. Here you will have to introduce your AWS key and secret access key:
[AWS]
AWS_ACCESS_KEY_ID=
AWS_SECRET_ACCESS_KEY=
With this file we will process all files from the S3 buckets and create the star schema (with all the tables mentioned above) and will introduce them into a new S3 which will act as our Data Lake.
This file provides the descrpition of the program and process of the etl.
Udacity provided the template and the guidelines to start this project. The completion of this was made by Guillermo Garcia and the review of the program and the verification that the project followed the proper procedures was also made by my mentor from udacity.