This repository has been archived by the owner on Aug 10, 2023. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 1.6k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Community Tutorial: inspect BigQuery with DLP at scale with Dataflow …
…and integrate with Data Catalog (#1558) * ADD new all bq dataflow dlp and dc tutorial * FIX typo on image * Fixes typo and remove some leftovers (#1) * fixed Google Cloud brand names * updated image links to public bucket * line edit during first readthrough * added links to previous tutorial * amplified the large scale aspects of this solution * copy edit Co-authored-by: Todd Kopriva <43478937+ToddKopriva@users.noreply.github.com>
- Loading branch information
1 parent
3a46a90
commit ea62e8f
Showing
28 changed files
with
3,194 additions
and
0 deletions.
There are no files selected for viewing
70 changes: 70 additions & 0 deletions
70
tutorials/dataflow-dlp-to-datacatalog-tags/bq_dlp_and_dc_worker.yaml
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,70 @@ | ||
| # Copyright 2020 The Data Catalog Tag History Authors. | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
|
|
||
| title: "BigQuery, DLP, and Data Catalog Worker" | ||
| description: "Allow the service account to read from BigQuery, call DLP, and create Data Catalog tags." | ||
| stage: "BETA" | ||
| includedPermissions: | ||
| # Generic | ||
| - iam.serviceAccounts.actAs | ||
| - iam.serviceAccounts.get | ||
| - iam.serviceAccounts.list | ||
| - resourcemanager.projects.get | ||
| # Data Catalog permissions | ||
| - datacatalog.tagTemplates.create | ||
| - datacatalog.tagTemplates.getTag | ||
| - datacatalog.tagTemplates.getIamPolicy | ||
| - datacatalog.tagTemplates.get | ||
| - datacatalog.tagTemplates.use | ||
| - bigquery.datasets.updateTag | ||
| - bigquery.models.updateTag | ||
| - bigquery.tables.updateTag | ||
| - datacatalog.entries.updateTag | ||
| - datacatalog.entries.get | ||
| - datacatalog.entries.list | ||
| - datacatalog.entryGroups.get | ||
| - datacatalog.entryGroups.list | ||
| # BigQuery permissions | ||
| - bigquery.readsessions.create | ||
| - bigquery.readsessions.getData | ||
| - bigquery.readsessions.update | ||
| - bigquery.datasets.get | ||
| - bigquery.datasets.getIamPolicy | ||
| - bigquery.models.getData | ||
| - bigquery.models.getMetadata | ||
| - bigquery.models.list | ||
| - bigquery.tables.get | ||
| - bigquery.tables.getData | ||
| - bigquery.tables.getIamPolicy | ||
| - bigquery.tables.list | ||
| # DLP permissions | ||
| - dlp.inspectFindings.list | ||
| - dlp.inspectTemplates.get | ||
| - dlp.inspectTemplates.list | ||
| - serviceusage.services.use | ||
| # Dataflow permissions | ||
| - storage.objects.create | ||
| - storage.objects.get | ||
| - storage.objects.update | ||
| - storage.objects.delete | ||
| - storage.objects.getIamPolicy | ||
| - storage.objects.list | ||
| - storage.objects.setIamPolicy | ||
| - storage.buckets.update | ||
| - storage.buckets.get | ||
| - storage.buckets.getIamPolicy | ||
| - storage.buckets.list | ||
| - storage.buckets.create | ||
| - storage.buckets.delete | ||
| - storage.buckets.setIamPolicy |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,30 @@ | ||
| # The Google Cloud project to use for this tutorial | ||
| export PROJECT_ID="your-project-id" | ||
|
|
||
| # The Compute Engine region to use for running Dataflow jobs and create a temporary storage bucket | ||
| export REGION_ID=us-central1 | ||
|
|
||
| # define the bucket ID | ||
| export TEMP_GCS_BUCKET=all_bq_dlp_dc_sync | ||
|
|
||
| # define the pipeline name | ||
| export PIPELINE_NAME=all_bq_dlp_dc_sync | ||
|
|
||
| # define the pipeline folder | ||
| export PIPELINE_FOLDER=gs://${TEMP_GCS_BUCKET}/dataflow/pipelines/${PIPELINE_NAME} | ||
|
|
||
| # Set Dataflow number of workers | ||
| export NUM_WORKERS=5 | ||
|
|
||
| # DLP execution name | ||
| export DLP_RUN_NAME=all-bq-dlp-dc-sync | ||
|
|
||
| # Set the DLP Inspect Template suffix | ||
| export INSPECT_TEMPLATE_SUFFIX=dlp_default_inspection | ||
|
|
||
| # Set the DLP Inspect Template name | ||
| export INSPECT_TEMPLATE_NAME=projects/${PROJECT_ID}/inspectTemplates/${INSPECT_TEMPLATE_SUFFIX} | ||
|
|
||
| # name of the service account to use (not the email address) | ||
| export ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT="all-bq-dlp-dataflow-sa" | ||
| export ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT_EMAIL="${ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT}@$(echo $PROJECT_ID | awk -F':' '{print $2"."$1}' | sed 's/^\.//').iam.gserviceaccount.com" |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Binary file added
BIN
+44.6 KB
tutorials/dataflow-dlp-to-datacatalog-tags/images/inspectTemplateCreated.png
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,242 @@ | ||
| --- | ||
| title: Create Data Catalog tags on a large scale by inspecting BigQuery data with Cloud DLP using Dataflow | ||
| description: Learn how to inspect BigQuery data using Cloud Data Loss Prevention and automatically create Data Catalog tags for sensitive elements with results from inspection scans at a large scale using Dataflow. | ||
| author: mesmacosta | ||
| tags: database, Cloud DLP, Java, PII, Cloud Dataflow | ||
| date_published: 2021-01-20 | ||
| --- | ||
|
|
||
| [Cloud Data Loss Prevention (Cloud DLP)](https://cloud.google.com/dlp) can help you to discover, inspect, and classify sensitive elements in your data. The | ||
| results of these inspections can be valuable as [tags](https://cloud.google.com/data-catalog/docs/concepts/overview#tags) in | ||
| [Data Catalog](https://cloud.google.com/data-catalog). This tutorial shows you how to inspect [BigQuery](https://cloud.google.com/bigquery) data on a large | ||
| scale with [Dataflow](https://cloud.google.com/dataflow) using the Cloud Data Loss Prevention API and then use the Data Catalog API to create tags at the column | ||
| level with the sensitive elements found. | ||
|
|
||
| This tutorial includes instructions to create a Cloud DLP inspection template to define what data elements to inspect for and sample code and commands that | ||
| demonstrate how to run a Dataflow job using the command-line interface. | ||
|
|
||
| For a related tutorial that uses a JDBC driver to connect to BigQuery and doesn't use Dataflow, see | ||
| [Create Data Catalog tags by inspecting BigQuery data with Cloud Data Loss Prevention](https://cloud.google.com/community/tutorials/dlp-to-datacatalog-tags). The | ||
| solution described in the current document is more appropriate for situations when you need to inspect data on a larger scale. | ||
|
|
||
| ## Objectives | ||
|
|
||
| - Enable Cloud Data Loss Prevention, BigQuery, Data Catalog, and Dataflow APIs. | ||
| - Create a Cloud DLP inspection template. | ||
| - Deploy a Dataflow pipeline that uses Cloud DLP findings to tag BigQuery table columns with Data Catalog. | ||
| - Use Data Catalog to quickly understand where sensitive data exists in your BigQuery table columns. | ||
|
|
||
| ## Costs | ||
|
|
||
| This tutorial uses billable components of Google Cloud, including the following: | ||
|
|
||
| * [Data Catalog](https://cloud.google.com/data-catalog/pricing) | ||
| * [Dataflow](https://cloud.google.com/dataflow/pricing) | ||
| * [Pub/Sub](https://cloud.google.com/pubsub/pricing) | ||
| * [Cloud DLP](https://cloud.google.com/dlp/pricing) | ||
| * [BigQuery](https://cloud.google.com/bigquery/pricing) | ||
|
|
||
| Use the [pricing calculator](https://cloud.google.com/products/calculator) to generate a cost estimate based on your | ||
| projected usage. | ||
|
|
||
| ## Reference architecture | ||
|
|
||
| The following diagram shows the architecture of the solution: | ||
|
|
||
|  | ||
|
|
||
| ## Before you begin | ||
|
|
||
| 1. Select or create a Google Cloud project. | ||
|
|
||
| [Go to the **Manage resources** page.](https://console.cloud.google.com/cloud-resource-manager) | ||
|
|
||
| 1. Make sure that billing is enabled for your project. | ||
|
|
||
| [Learn how to enable billing.](https://cloud.google.com/billing/docs/how-to/modify-project) | ||
|
|
||
| 1. Enable the Data Catalog, BigQuery, Cloud Data Loss Prevention, and Dataflow APIs. | ||
|
|
||
| [Enable the APIs.](https://console.cloud.google.com/flows/enableapi?apiid=datacatalog.googleapis.com,bigquery.googleapis.com,dlp.googleapis.com,dataflow.googleapis.com) | ||
|
|
||
| ## Setting up your environment | ||
|
|
||
| 1. In Cloud Shell, clone the source repository and go to the directory for this tutorial: | ||
|
|
||
| git clone https://github.com/GoogleCloudPlatform/community/tree/master/tutorials/dataflow-dlp-to-datacatalog-tags | ||
| cd tutorials/dataflow-dlp-to-datacatalog-tags | ||
|
|
||
| 1. Use a text editor to modify the `env.sh` file to set following variables: | ||
|
|
||
| # The Google Cloud project to use for this tutorial | ||
| export PROJECT_ID="your-project-id" | ||
|
|
||
| # The Compute Engine region to use for running Dataflow jobs and create a temporary storage bucket | ||
| export REGION_ID=us-central1 | ||
|
|
||
| # define the bucket ID | ||
| export TEMP_GCS_BUCKET=all_bq_dlp_dc_sync | ||
|
|
||
| # define the pipeline name | ||
| export PIPELINE_NAME=all_bq_dlp_dc_sync | ||
|
|
||
| # define the pipeline folder | ||
| export PIPELINE_FOLDER=gs://${TEMP_GCS_BUCKET}/dataflow/pipelines/${PIPELINE_NAME} | ||
|
|
||
| # Set Dataflow number of workers | ||
| export NUM_WORKERS=5 | ||
|
|
||
| # DLP execution name | ||
| export DLP_RUN_NAME=all-bq-dlp-dc-sync | ||
|
|
||
| # Set the DLP Inspect Template suffix | ||
| export INSPECT_TEMPLATE_SUFFIX=dlp_default_inspection | ||
|
|
||
| # Set the DLP Inspect Template name | ||
| export INSPECT_TEMPLATE_NAME=projects/${PROJECT_ID}/inspectTemplates/${INSPECT_TEMPLATE_SUFFIX} | ||
|
|
||
| # name of the service account to use (not the email address) | ||
| export ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT="all-bq-dlp-dataflow-sa" | ||
| export ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT_EMAIL="${ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT}@$(echo $PROJECT_ID | awk -F':' '{print $2"."$1}' | sed 's/^\.//').iam.gserviceaccount.com" | ||
|
|
||
| 1. Run the script to set the environment variables: | ||
|
|
||
| source env.sh | ||
|
|
||
| ## Creating resources | ||
|
|
||
| ### Create BigQuery tables | ||
|
|
||
| If you don't have any BigQuery resources in your project, you can use the open source script | ||
| [BigQuery Fake PII Creator](https://github.com/mesmacosta/bq-fake-pii-table-creator) to | ||
| create BigQuery tables with example personally identifiable information (PII). | ||
|
|
||
| ### Create the inspection template in Cloud DLP | ||
|
|
||
| 1. Go to the Cloud DLP [**Create template** page](https://console.cloud.google.com/security/dlp/create/template) and create | ||
| the inspection template. Use the same value specified in the environment variable `INSPECT_TEMPLATE_SUFFIX` as the template ID. | ||
|
|
||
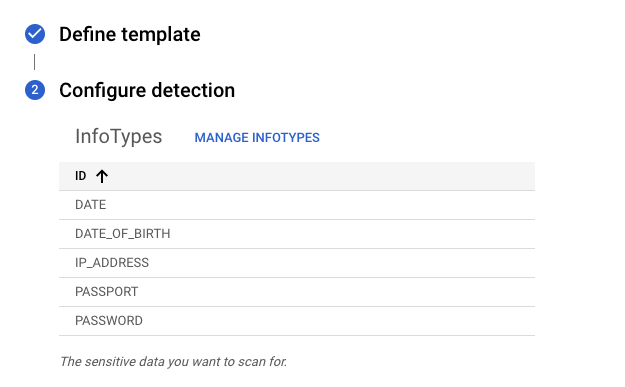
| 1. Set up the infoTypes. | ||
|
|
||
| The following image shows an example selection of infoTypes. You can choose whichever infoTypes you like. | ||
|
|
||
|  | ||
|
|
||
| 1. Finish creating the inspection template: | ||
|
|
||
|  | ||
|
|
||
| ### Create the service account | ||
|
|
||
| We recommend that you run pipelines with fine-grained access control to improve access partitioning. If your project doesn't have a user-created service | ||
| account, create one using following instructions. | ||
|
|
||
| You can use your browser by going to [**Service accounts**](https://console.cloud.google.com/projectselector/iam-admin/serviceaccounts?supportedpurview=project) | ||
| in the Cloud Console. | ||
|
|
||
| 1. Create a service account to use as the user-managed controller service account for Dataflow: | ||
|
|
||
| gcloud iam service-accounts create ${ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT} \ | ||
| --description="Service Account to run the DataCatalog bq dlp inspection pipeline." \ | ||
| --display-name="Big Query DLP inspection and Data Catalog pipeline account" | ||
|
|
||
| 1. Create a custom role with required permissions for accessing BigQuery, DLP, Dataflow, and Data Catalog: | ||
|
|
||
| export BG_DLP_AND_DC_WORKER_ROLE="bq_dlp_and_dc_worker" | ||
|
|
||
| gcloud iam roles create ${BG_DLP_AND_DC_WORKER_ROLE} --project=${PROJECT_ID} --file=bq_dlp_and_dc_worker.yaml | ||
|
|
||
| 1. Apply the custom role to the service account: | ||
|
|
||
| gcloud projects add-iam-policy-binding ${PROJECT_ID} \ | ||
| --member="serviceAccount:${ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT_EMAIL}" \ | ||
| --role=projects/${PROJECT_ID}/roles/${BG_DLP_AND_DC_WORKER_ROLE} | ||
| 1. Assign the `dataflow.worker` role to allow the service account to run as a Dataflow worker: | ||
|
|
||
| gcloud projects add-iam-policy-binding ${PROJECT_ID} \ | ||
| --member="serviceAccount:${ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT_EMAIL}" \ | ||
| --role=roles/dataflow.worker | ||
|
|
||
| ## Deploy and run the Cloud DLP and Data Catalog tagging pipeline | ||
|
|
||
| ### Configure parameters | ||
|
|
||
| The configuration file at `src/main/resources/config.properties` manages how Dataflow | ||
| parallelizes the BigQuery rows, logging, what BigQuery resources are considered, and | ||
| whether you want to wait for the execution to finish. | ||
|
|
||
| In general, we recommend that you leave the values at their defaults, but you can change and tune them to fit your use case. | ||
|
|
||
| | Parameter | Description | | ||
| |---------------------|-----------------------------------------------------------------------| | ||
| | `bigquery.tables` | A comma-separated list of table names, specifying which tables to run the pipeline on. The default value is empty, which causes the pipeline to run on all BigQuery tables.| | ||
| | `rows.batch.size` | The number of rows to process in a batch with each Cloud DLP API call. If this value is too high, you may receive errors indicating that the request has exceeded the maximum payload size. | | ||
| | `rows.shard.size` | Number of shards used to bucket and group the BigQuery rows into batches. | | ||
| | `rows.sample.size` | Number of BigQuery rows that are sampled from each table. A smaller value keeps costs lower. | | ||
| | `verbose.logging` | Flag to enable verbose logging. | | ||
| | `pipeline.serial.execution` | Flag to make the pipeline have a serial execution, so you can wait for it to finish in the command-line interface. | | ||
|
|
||
| ### Run the pipeline | ||
|
|
||
| 1. Create a Cloud Storage bucket as a temporary and staging bucket for Dataflow: | ||
|
|
||
| gsutil mb -l ${REGION_ID} \ | ||
| -p ${PROJECT_ID} \ | ||
| gs://${TEMP_GCS_BUCKET} | ||
|
|
||
| 1. Start the Dataflow pipeline using the following Maven command: | ||
|
|
||
| mvn clean generate-sources compile package exec:java \ | ||
| -Dexec.mainClass=com.google_cloud.datacatalog.dlp.snippets.DLP2DatacatalogTagsAllBigQueryInspection \ | ||
| -Dexec.cleanupDaemonThreads=false \ | ||
| -Dmaven.test.skip=true \ | ||
| -Dexec.args=" \ | ||
| --project=${PROJECT_ID} \ | ||
| --dlpProjectId=${PROJECT_ID} \ | ||
| --dlpRunName=${DLP_RUN_NAME} \ | ||
| --inspectTemplateName=${INSPECT_TEMPLATE_NAME} \ | ||
| --maxNumWorkers=${NUM_WORKERS} \ | ||
| --runner=DataflowRunner \ | ||
| --serviceAccount=${ALL_BQ_DLP_DATAFLOW_SERVICE_ACCOUNT_EMAIL} \ | ||
| --gcpTempLocation=gs://${TEMP_GCS_BUCKET}/temp/ \ | ||
| --stagingLocation=gs://${TEMP_GCS_BUCKET}/staging/ \ | ||
| --workerMachineType=n1-standard-1 \ | ||
| --region=${REGION_ID}" | ||
|
|
||
| ### Pipeline DAG | ||
|
|
||
|  | ||
|
|
||
| ### Check the results of the script | ||
|
|
||
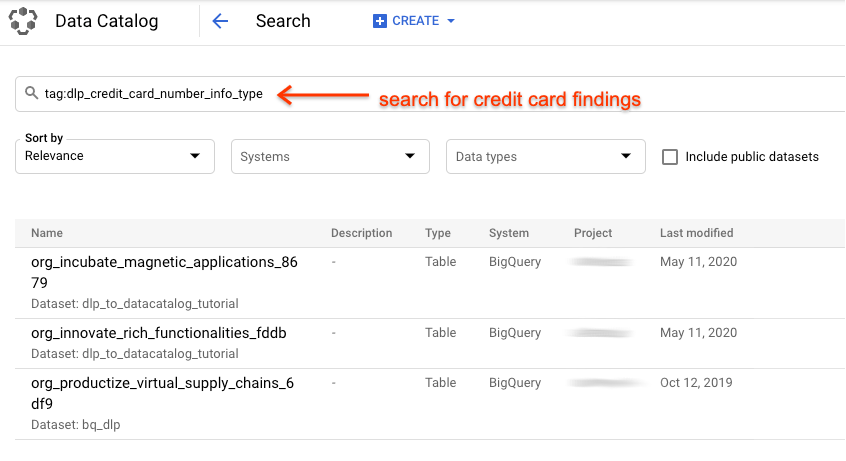
| After the script finishes, you can go to [Data Catalog](https://cloud.google.com/data-catalog) and search for sensitive | ||
| data: | ||
|
|
||
|  | ||
|
|
||
| By clicking each table, you can see which columns were marked as sensitive: | ||
|
|
||
|  | ||
|
|
||
| ## Cleaning up | ||
|
|
||
| The easiest way to avoid incurring charges to your Google Cloud account for the resources used in this tutorial is to delete | ||
| the project you created. | ||
|
|
||
| To delete the project, follow the steps below: | ||
|
|
||
| 1. In the Cloud Console, [go to the Projects page](https://console.cloud.google.com/iam-admin/projects). | ||
|
|
||
| 1. In the project list, select the project that you want to delete and click **Delete project**. | ||
|
|
||
| 1. In the dialog, type the project ID, and then click **Shut down** to delete the project. | ||
|
|
||
| ## What's next | ||
|
|
||
| - Learn about [Cloud Data Loss Prevention](https://cloud.google.com/dlp). | ||
| - Learn about [Data Catalog](https://cloud.google.com/data-catalog). | ||
| - Learn more about [Cloud developer tools](https://cloud.google.com/products/tools). | ||
| - For a related tutorial that uses a JDBC driver to connect to BigQuery and doesn't use Dataflow, see | ||
| [Create Data Catalog tags by inspecting BigQuery data with Cloud Data Loss Prevention](https://cloud.google.com/community/tutorials/dlp-to-datacatalog-tags). | ||
| - Try out other Google Cloud features. Have a look at our [tutorials](https://cloud.google.com/docs/tutorials). |
Oops, something went wrong.