This is a branch of HuggingFace Diffusers to incorporate FlashAttention, optimized for high throughput.
Update 10/31/22: Easier install! You can either run from our Docker image, or install from source. Bonus: We no longer rely on the cutlass branch of FlashAttention!
From our Docker image:
You can run from our Docker image:
docker run -it --rm --gpus all danfu09/diffusers:0.1 zsh
huggingface-cli login
cd diffusers
python test.py --batch_size 1 # how many images to generate at once
To install from source:
FlashAttention requires CUDA 11, NVCC, and a Turing or Ampere GPU. To install FlashAttention:
git clone https://github.com/HazyResearch/flash-attention.git
cd flash-attention
git submodule init
git submodule update
python setup.py install
cd ..
To install diffusers:
git clone https://github.com/HazyResearch/diffusers.git
cd diffusers
pip install -e .
A sample benchmark, following HuggingFace's benchmark of diffusers:
import time
import torch
from diffusers import StableDiffusionPipeline
import functools
# torch disable grad
torch.set_grad_enabled(False)
torch.manual_seed(1231)
torch.cuda.manual_seed(1231)
prompt = "a photo of an astronaut riding a horse on mars"
# cudnn benchmarking
torch.backends.cudnn.benchmark = True
# make sure you're logged in with `huggingface-cli login`
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True,
revision="fp16",
torch_dtype=torch.float16
).to("cuda")
batch_size = 10
# warmup
with torch.inference_mode():
image = pipe([prompt] * batch_size, num_inference_steps=5).images[0]
for _ in range(3):
torch.cuda.synchronize()
start_time = time.time()
with torch.inference_mode():
image = pipe([prompt] * batch_size, num_inference_steps=50).images[0]
torch.cuda.synchronize()
print(f"Pipeline inference took {time.time() - start_time:.2f} seconds")To test the performance, you can run our test script:
python test.py --batch_size 10 # to see throughput
python test.py --batch_size 1 # to see latency
On A100, we see throughput >1 image/s when generating 10 images:
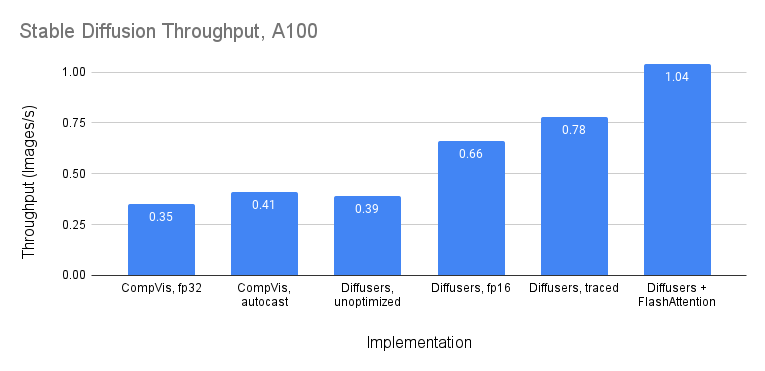
For single images, we see latency of around 1.5-1.6 seconds.