{kind=link}
{kind=link}
![]()
This project provides a standard model for pyspark projects enforcing python, software cratsmanship and CI/CD best practices. It relies on poetry a python packaging and dependency management library. We have used dynaconf for multi environment configuration management and pytest & chispa for pyspark unit testing.
You can use this model as an accelerator to bootstrap your own pyspark project and take advantage of all the best practices.

In this template we are using covid-19 Kaggle dataset. In the jobs package you will find 3 jobs which represent bronze, silver and gold layers of multihop data pipeline. These jobs are quite simple and straightfoward as it's just a model to help you bootstrap but in real life you can have a lot more jobs in there with various level of complexity depending on the usecase.
As the name suggests tests package contains the unit tests for pyspark jobs. We have desiged the jobs in a way that all the trasformations are put in form of environment agnostic determinitic functions. So we have created unit tests for these trasformation functions only which is sufficient as all the business logic must reside in these functions. Chispa provides utility functions to compare spark dataframe to make testing easier for us.
The dependencies package is supposed to have all the utility modules that are to be re-used by multiple other jobs. In this model we have two modules. First one is spark.py which creates the spark session and another one is logger.py which initializes the logger for pyspark. But you can add as many as you need.
Dynaconf is used for project configuration management. The config file (settings.toml) is present in config package where you can add environment (dev/qa/prod for example) specific configurations. Dynaconf also allows to override the configurations at run time using environment variables. To choose the setting for particular environment you will need to the set dynaconf environment variable ENV_FOR_DYNACONF to environment name (i.e. development, production etc).
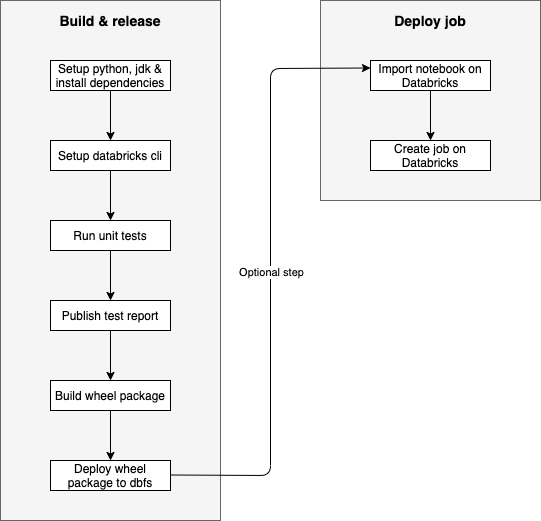
We have used the GitHub actions for CI/CD part as you can see in the cicd workflow file. This CI/CD workflow starts by installing all the necesary dependencies like python, jdk and other python packages defined in the poerty description file. We also install and set up databricks-cli as it is needed to interact with databricks workspace and file system. In the next step of workflow we run the unit tests, publish tests report, prepare poetry wheel package and copy that package to databricks file system (aka dbfs). At this step the build and release cycle is complete.
Next part of the workflow is the job creation on Databricks workspace which is completely optional. You may very well skip this step and use someother tool or process to orchestrate your jobs. For job deployment via this CI/CD workflow we start by copying the data pipeline notebook to workspace and then we create a job on Databricks with required job and cluster configuration (passed as json string). To execute the job either you can set a cron schedule for job execution in the job configuration or you can manually trigger the job once it’s created on Databricks workspace.
In job configuration json string we are running the data pipeline notebook as a notebook task and the wheel package of this project will be installed on cluster as a dependency. We have also set the required ADLS access key as spark conf in the cluster configuration to access the desired data files from ADLS. Since access key as a sensitive value so instead of putting it in clear text we have used Databricks provided secret scope. To use the production configuration settings we have also set dynaconf environment variable to production in cluster configuration.
We have used Databricks as the deployment target but you are not bound to do that. By changing the deployment step (i.e. Deploy artifact in cicd.yml) of CI/CD workflow you can deploy the wheel package to a data platform/cloud/repository of your choice. And if you prefer to publish your project's wheel package as a library to PyPi or to a private repositiry then run poetry publish command.
To add a dependency package: poetry add <package-name>. (add option --dev if want to install just a dev dependency)
To install dependencies: poetry install
To run unit tests: poetry run pytest tests -v --junitxml="result.xml"
To build a wheel package: poetry build
To run pyspark jobs locally: poetry run spark-submit --packages io.delta:delta-core_2.12:1.0.0 --py-files dist/jobs-0.1.0-py3-none-any.whl jobs/bronze.py