Horizon Robotics
🔥 GUMP revolutionizes autonomous driving simulation with a scalable and realistic approach to modeling driving scenes. Leveraging generative models, GUMP learns the dynamic interactions of traffic, enabling diverse future scenario simulations and the creation of new driving scenarios based on user prompts. This model operates efficiently in both full-Autoregressive and partial-Autoregressive modes, making it ideal for online reinforcement learning, planning policy evaluation, and high-fidelity testing. Explore our innovative framework that seamlessly integrates data generation, realistic simulation, reactive planning, and online training.

Our release roadmap outlines the planned development and upcoming features:
- Code initialization
- Base-model configs & checkpoints
- Downstream Task: Reactive Simulation
- Evaluation Metrics
- Visualization
- Reimplement with more efficient datastructure, ~4 times faster
- Accelerate CPU code with Numba library
- More advanced architecture, i.e Llama3
- Downstream Task: Reactive Simulation
- Evaluation Metrics
- Support the Waymo Dataset
- Downstream Task: Scenario Generation
- Downstream Task: Policy Enhancement
- Downstream Task: Reinforcement Learning
- Compatible with various tokenizers, including Trajeglish and MotionLM.
- [Long-term] End to end learning
- [Long-term] Alignment with agent behavior metrics
| Task | Description | Demo |
|---|---|---|
| Scene Generation | Scenes generated by GUMP on the nuPlan Dataset. Initial frames are autoregressively created based on the static map and scenario descriptions, followed by motion simulation through scene extrapolation. These scenes share the same map but have different scenario descriptions and various agents. |   |
| Reactive Simulation | Showcasing diverse scenarios with Waymo Sim Agents, starting from the same conditions but diverging over time. Demonstrates GUMP's ability to simulate a rich, probabilistic range of future scenarios. | 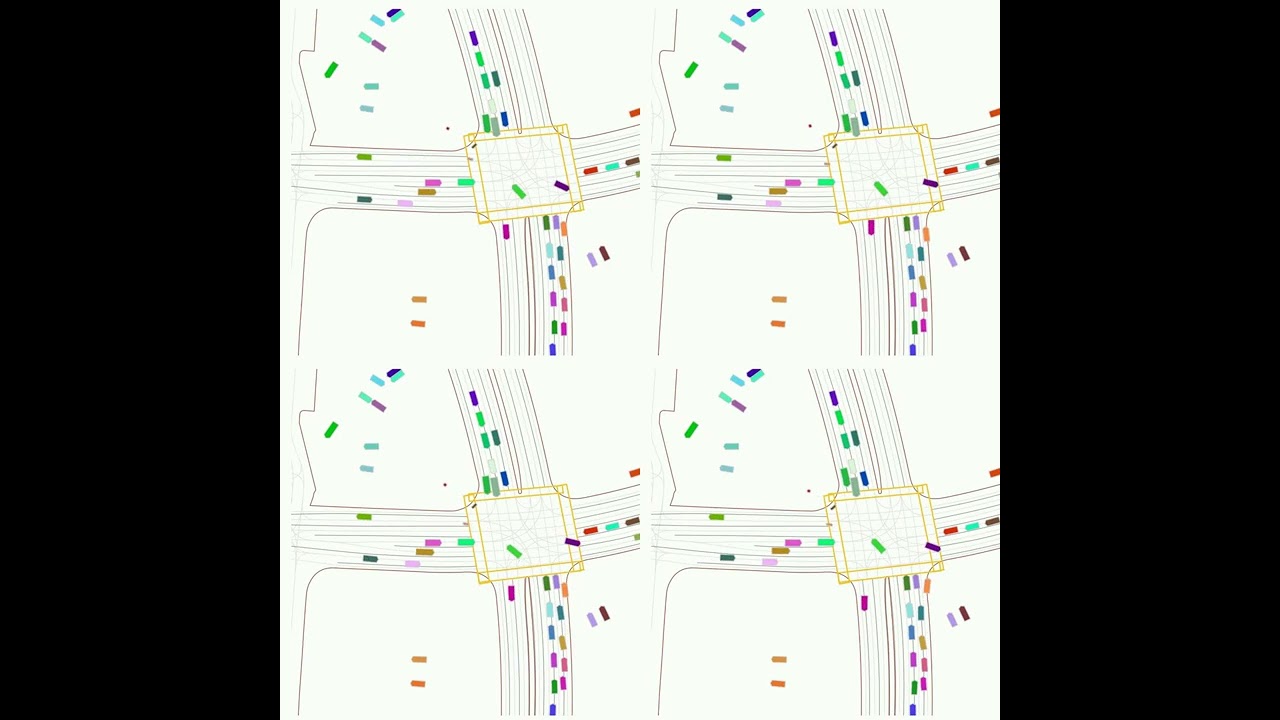 |
| Policy Training (RL) | Visual performance of planning policies trained with SAC in GUMP. The ego vehicle (red box) and log ground truth (green box) show the policy's ability to handle complex scenarios. | Policy Training Video |
| Policy Evaluation | Comparing GUMP's realism with rule-based reactive environments (IDM). Left: IDM simulator, Right: GUMP simulator. | Policy Evaluation Video |
| Policy Enhancement | Scenario featuring interactive planning with multiple planners and corresponding rewards. Green dots show the best planning proposals. | Policy Enhancement Video |
All assets and code are under the Apache 2.0 license unless specified otherwise.
If you find GUMP is useful in your research or applications, please consider giving us a star 🌟 and citing it by the following BibTeX entry.
@article{hu2024solving,
title={Solving Motion Planning Tasks with a Scalable Generative Model},
author={Hu, Yihan and Chai, Siqi and Yang, Zhening and Qian, Jingyu and Li, Kun and Shao, Wenxin and Zhang, Haichao and Xu, Wei and Liu, Qiang},
journal={arXiv preprint arXiv:2407.02797},
year={2024}
}