Read this in other languages: 한국어.
Blockchain is a shared, immutable ledger for recording the history of transactions. The Linux Foundation’s Hyperledger Fabric, the software implementation of blockchain IBM is committed to, is a permissioned network. For developing any blockchain use-case, the very first thing is to have a development environment for Hyperledger Fabric to create and deploy the application. Hyperledger Fabric network can be setup in multiple ways.
- Hyperledger Fabric network On-Premise
- Using IBM Blockchain Platform hosted on IBM Cloud. IBM Cloud provides you Blockchain as a service.
- Hyperledger Fabric network using Kubernetes APIs on IBM Cloud Kubernetes Service
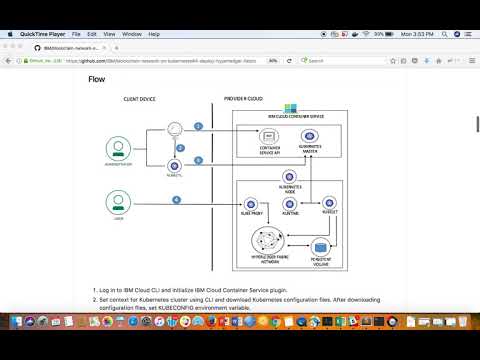
This code pattern demonstrates the steps involved in setting up your business network on Hyperledger Fabric using Kubernetes APIs on IBM Cloud Kubernetes Service.
Hosting the Hyperledger Fabric network on IBM Cloud provides you many benefits like multiple users can work on the same setup, the setup can be used for different blockchain applications, the setup can be reused and so on. Please note that the blockchain network setup on Kubernetes is good to use for demo scenarios but for production, it is recommended to use IBM Blockchain Platform hosted on IBM Cloud.
IBM Cloud Kubernetes Service allows you to create a free cluster that comes with 2 CPUs, 4 GB memory, and 1 worker node. It allows you to get familiar with and test Kubernetes capabilities. However they lack capabilities like persistent NFS file-based storage with volumes.
To setup your cluster for maximum availability and capacity, IBM Cloud allows you to create a fully customizable, production-ready cluster called standard cluster. Standard clusters allow highly available cluster configurations such as a setup with two clusters that run in different regions, each with multiple worker nodes. Please see https://cloud.ibm.com/docs/containers?topic=containers-cs_ov#cluster_types to review other options for highly available cluster configurations.
This pattern uses a free cluster provided by IBM Cloud and it can be used for proof-of-concept purpose. This pattern provides you the scripts to automate the process for setting up Hyperledger Fabric network using Kubernetes APIs on IBM Cloud.
When the reader has completed this pattern, they will understand how to:
- modify configuration files according to their network topology
- deploy the hyperledger fabric network on Kubernetes cluster

- Log in to IBM Cloud CLI and initialize IBM Cloud Kubernetes Service plugin.
- Set context for Kubernetes cluster using CLI and download Kubernetes configuration files. After downloading configuration files, set KUBECONFIG environment variable.
- Run script to deploy your hyperledger fabric network on Kubernetes cluster.
- Access Kubernetes dashboard.
-
Hyperledger Fabric: Hyperledger Fabric is a platform for distributed ledger solutions underpinned by a modular architecture delivering high degrees of confidentiality, resiliency, flexibility and scalability.
-
IBM Cloud Kubernetes Service: IBM Kubernetes Service enables the orchestration of intelligent scheduling, self-healing, and horizontal scaling.
-
Blockchain: A blockchain is a digitized, decentralized, public ledger of all transactions in a network.
-
Kubernetes Cluster: In Kubernetes Engine, a container cluster consists of at least one cluster master and multiple worker machines called nodes. A container cluster is the foundation of Kubernetes Engine.
- Kubernetes Pods - Pods represent the smallest deployable units in a Kubernetes cluster and are used to group containers that must be treated as a single unit.
- Kubernetes Jobs - A job creates one or more pods and ensures that a specified number of them successfully terminate. As pods successfully complete, the job tracks the successful completions.
- Kubernetes Deployment - A deployment is a Kubernetes resource where you specify your containers and other Kubernetes resources that are required to run your app, such as persistent storage, services, or annotations.
- Kubernetes Services - A Kubernetes service groups a set of pods and provides network connection to these pods for other services in the cluster without exposing the actual private IP address of each pod.
- Kubernetes Persistent Volumes (PV) - PersistentVolumes are a way for users to claim durable storage such as NFS file storage.
Follow these steps to setup and run this code pattern.
- Create a Kubernetes Cluster on IBM Cloud
- Setting up CLIs
- Gain access to your Kubernetes Cluster
- Deploy Hyperledger Fabric Network into Kubernetes Cluster
- Test the deployed network
- View the Kubernetes Dashboard
- Connect the network using client SDK
-
Create a Kubernetes cluster with IBM Cloud Kubernetes Service using GUI. This pattern uses the free cluster.

Note: It can take up to 15 minutes for the cluster to be set up and provisioned.

-
Install IBM Cloud CLI. The prefix for running commands by using the Bluemix CLI is
ibmcloud. -
Install Kubernetes CLI. The prefix for running commands by using the Kubernetes CLI is
kubectl. -
Install the kubernetes service plugin using the following command
ibmcloud plugin install container-service -r Bluemix
Access the IBM Cloud Dashboard. Choose the same cloud foundry org and cloud foundry space where cluster is created.
-
Check the status of your cluster
IBM Cloud Dashboard -> <your cluster> -> Worker Nodes. If status is notnormal, then you need to wait for some more time to proceed further.
-
Once your cluster is ready, open the access tab
IBM Cloud Dashboard -> <your cluster> -> Accessas shown in snapshot.
-
Perform the steps provided under the section
Gain access to your cluster. -
Verify that the kubectl commands run properly with your cluster by checking the Kubernetes CLI server version.
$ kubectl version --short Client Version: v1.14.6 Server Version: v1.16.8+IKS


This pattern provides a script which automatically provisions a sample Hyperledger Fabric network consisting of four organizations, each maintaining one peer node, and a 'solo' ordering service. Also, the script creates a channel named as channel1, joins all peers to the channel channel1, install chaincode on all peers and instantiate chaincode on channel. The pattern also helps to drive execution of transactions against the deployed chaincode.
Clone or download the Kubernetes configuration scripts to your user home directory.
$ git clone https://github.com/IBM/blockchain-network-on-kubernetes
Navigate to the source directory
$ cd blockchain-network-on-kubernetes
$ ls
In the source directory,
configFilescontains Kubernetes configuration filesartifactscontains the network configuration files*.shscripts to deploy and delete the network
If there is any change in network topology, need to modify the configuration files (.yaml files) appropriately. The configuration files are located in artifacts and configFiles directory. For example, if you decide to increase/decrease the capacity of persistent volume then you need to modify createVolume.yaml.
The Kubernetes Server version v1.11.x or above uses containerd as its container runtime therefore using docker.sock of the worker node is not possible. You need to deploy and use a Docker daemon in a container. In case, your Kubernetes server version is smaller than 1.11.x then you need to modify the configFiles/peersDeployment.yaml file to point to a Docker service. Change instances of tcp://docker:2375 to unix:///host/var/run/docker.sock with a text editor.
Once you have completed the changes (if any) in configuration files, you are ready to deploy your network.
Check your kubectl CLI version as:
$ kubectl version --short
This command will give you Client Version and Server Version.
If the Client version > v1.11.x i.e. 1.12.x or more then use setup_blockchainNetwork_v2.sh to set up the network. Run the following command:
cp setup_blockchainNetwork_v2.sh setup_blockchainNetwork.sh
If the Client version <= v1.11.x then use setup_blockchainNetwork_v1.sh to setup the network. Copy the script as shown.
cp setup_blockchainNetwork_v1.sh setup_blockchainNetwork.sh
Now execute the script to deploy your hyperledger fabric network.
$ chmod +x setup_blockchainNetwork.sh
$ ./setup_blockchainNetwork.sh
If you are using a Standard IKS cluster with multiple workers nodes, do
./setup_blockchainNetwork.sh --paidso that the shared volume of the blockchain containers would work properly.
Note: Before running the script, please check your environment. You should able to run kubectl commands properly with your cluster as explained in step 3.
If required, you can bring your hyperledger fabric network down using the script deleteNetwork.sh. This script will delete all your pods, jobs, deployments etc. from your Kubernetes cluster.
$ chmod +x deleteNetwork.sh
$ ./deleteNetwork.sh
After successful execution of the script setup_blockchainNetwork.sh, check the status of pods.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blockchain-ca-7848c48d64-2cxr5 1/1 Running 0 4m
blockchain-orderer-596ccc458f-thdgn 1/1 Running 0 4m
blockchain-org1peer1-747d6bdff4-4kzts 1/1 Running 0 4m
blockchain-org2peer1-7794d9b8c5-sn2qf 1/1 Running 0 4m
blockchain-org3peer1-59b6d99c45-dhtbp 1/1 Running 0 4m
blockchain-org4peer1-6b6c99c45-wz9wm 1/1 Running 0 4m
As mentioned above, the script joins all peers on one channel channel1, install chaincode on all peers and instantiate chaincode on channel. It means we can execute an invoke/query command on any peer and the response should be same on all peers. Please note that in this pattern tls certs are disabled to avoid complexity. In this pattern, the CLI commands are used to test the network. For running a query against any peer, need to get into a bash shell of a peer, run the query and exit from the peer container.
Use the following command to get into a bash shell of a peer:
$ kubectl exec -it <blockchain-org1peer1 pod name> bash
And the command to be used to exit from the peer container is:
# exit
Note: Stay logged into your peer to complete these commands.
Query
Chaincode was instantiated with the values as { a: 100, b: 200 }. Let’s query to org1peer1 for the value of a to make sure the chaincode was properly instantiated.
peer chaincode query -C channel1 -n cc -c '{"Args":["query","a"]}'

Invoke
Now let’s submit a request to org2peer1 to move 20 from a to b. A new transaction will be generated and upon successful completion of transaction, state will get updated.
peer chaincode invoke -o blockchain-orderer:31010 -C channel1 -n cc -c '{"Args":["invoke","a","b","20"]}'

Query
Let’s confirm that our previous invocation executed properly. We initialized the key a with a value of 100 and just removed 20 with our previous invocation. Therefore, a query against a should show 80 and a query against b should show 220. Now issue the query request to org3peer1 and org4peer1 as shown.
peer chaincode query -C channel1 -n cc -c '{"Args":["query","a"]}'
peer chaincode query -C channel1 -n cc -c '{"Args":["query","b"]}'


Go to the IBM Cloud dashboard -> Clusters -> <Your Kubernetes cluster>
Click on the button entitled Kubernetes Dashboard,

you will see the dashboard as shown.

The hyperledger fabric network is ready to use. You can start developing your blockchain applications using node sdk for this deployed network.
To develop your blockchain application on this deployed network, you need to connect to this network using client SDK. To connect to the network:
- Get the public IP of your kubernetes cluster from IBM Cloud Dashboard.
- Connect using this public IP and the ports exposed using services.
For example: The node port for CA is
30054hence CA Client url will behttp://< public IP of your cluster >:30054/
In this way, the CA client using node SDK can be created as:
fabric_ca_client = new Fabric_CA_Client('http://< public IP of your cluster >:30054/', tlsOptions , 'CA1', crypto_suite);
Similarly the following code can be used to setup the fabric network.
// setup the fabric network
var fabric_client = new Fabric_Client();
var channel = fabric_client.newChannel('channel1');
var peer = fabric_client.newPeer('grpc://< public IP of your cluster >:30110');
channel.addPeer(peer);
var order = fabric_client.newOrderer('grpc://< public IP of your cluster >:31010')
channel.addOrderer(order);
This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.