Refactor file upload from web UI and temporary storage #6656
Comments
|
When doing upload tests for the S3 storage option I noticed the upload (step 4 in your things to note list) to the storage, that only shows a spinner, mostly was longer that the user upload to dataverse. |
|
@poikilotherm, thanks for this detailed issue. I'd like to separate out the UX/UI/ system behaviors a bit. Form the UX standpoint, it sounds like there are inefficiencies in how upload works that can cause lags. From the UI standpoint, feedback is not clear/does not represent what the system is doing:
I've clarified that issues #6604 and #6605 are primarily about addressing scaleability in the UI. |
|
@poikilotherm - good stuff! In putting together the s3 direct uploads, I've been looking at the file workflow and thinking about optimizations as well. It seems like there are a couple things that could be picked off to start:
Beyond that, I think there are multiple ways one could optimize, at least for some situations (Apologies for this part rambling a bit):
There are a few considerations there that might inform design:
My general sense for these types of considerations is that some refactoring of the StorageIO interface could help here and might enable experimentation/stores optimized for specific content over time along with helping the general case. I don't have a specific design in mind yet but things I've thought about include:
Overall, I think that changes of this nature are ones that should be done in concert with thinking through the implications of remote stores, sensitive data, large data, data tags, reproducibility (where data location near compute may be important), and anything else on the roadmap that might affect requirements for storage and it's functionality (provenance? multiple datasets referencing the same files (e.g. starting reference data or controls). I don't want to make things too complicated but, I agree that refactoring storage beyond a couple simple steps (as at the beginning of my comment) is probably big enough that we won't want to do it multiple times. |
|
To answer the question from @TaniaSchlatter; "How they get feedback": Maybe (for large saves) we should provide the user with the option to wait, or resume with other things. |
|
Thank you @TaniaSchlatter, @qqmyers and @PaulBoon for your loads of input on this! On a side note, my comment to #6505 might be related here, mentioning making things more modular at different places to speed up things. From all your input one might get the impression that this is not medium, but big and needs better planing and architecture. @scolapasta, how do you feel about this? @djbrooke how might this fit into the roadmap? This might become sth that even needs funding. Someone at Tromso mentioned some folks granting funds for refactoring. |
…e and Kubernetes deployment. Will be removed when #178 gets solved.
|
@poikilotherm thanks for the tag and for the summary above. We have two UI/UX intensive efforts underway right now (Computational Reproducibility and the Dataset/File Redesign) so I'm hesitant to add additional work that has front end impact. I'd suggest that we focus any refactoring as much as possible on improvements that don't have front end impact and revisit any front end improvements and changes when we have a bit more bandwidth on the UI/UX side. Generally, small changes that can be implemented independently are preferred, instead of a larger rewrite. This allows us to review things and get things into releases more quickly. If there's something you, @qqmyers @scolapasta and others can come up we'll be happy to review and QA through the regular processes. If there is a larger rewrite needed, we can discuss the best plan for that as well. It's also good to hear about the possibility of funding. If there's something specific, we can talk about how to best support it, whether from an IQSS perspective or from a GDCC perspective. |
|
To follow up on @PaulBoon's comment on feedback, feedback that a file has been uploaded successfully is the population of the file table. If we allowed users to do other tasks while they waited for large files to upload, we would want to present the user with a Success or Failure message that they would see. This could be in a popup, or on the page they are actively on. |
|
Thank you for opening this issue, and to everybody who participated in the discussion. |
|
To me personally, the biggest issue is the 2 temp copies created repeatedly - one by Glassfish/Primefaces, the second one by us. This is definitely a waste that should be eliminated. Yet another thing that may not be mentioned above is that while Dataverse has configurable file upload size limit, as implemented, it can only be enforced in our code - i.e. by the time the entire system temp file has been saved. I.e. you can set that limit to 8Kb in your Dataverse. But if a user attempts to upload a 100GB file, Jersey will dutifully try to save the entire stream in your /tmp before passing it to the application. I would be really happy to eliminate at least one of these temp file stages. Saving the file directly into its final location right away, thus eliminating temp storage completely, as discussed above, should also be doable. I personally like the idea of keeping the file in temp storage, at least for the UI user, until they decide to click save. If the files go to the destination folder right away, just like some junk files from incomplete uploads are piling up in the temp directories now, they will be piling up in the "real" storage folders - and it will still be the responsibility of the admin to go through files there and erase the orphaned ones. (But I'm open to either way) |
|
Adding some context from a recent internal discussion, so we don't loose it:
|
|
@TaniaSchlatter I'm really happy to hear that you are thinking of how to improve the file upload work flow, in the context of creating a new dataset and otherwise. It should probably be a whole separate issue for that - right? My reading of this one was that it was created for something fairly narrowly defined - specifically for eliminating the inefficiencies in how we use temp storage in the process of adding files. |
|
Just recently, I once again looked into this, trying to find the root cause for the temporary storage during uploads. Since I opened this issue, we moved to Payara 5 and now definitely work with JSF 2.3 etc. Looking at the PrimeFaces FileUpload docs my initial statement about using the Apache Commons uploader isn't true anymore (and might have been a false claim from the start). This is all about using the native JSF ways of doing things. Still I wondered why data is stored as parts under This attribute is used in PrimeFaces File Uploader with priority over default String getUploadDirectory(T request) {
// Servlet 2.5 compatibility, equivalent to ServletContext.TMP_DIR
File tmpDir = (File) request.getServletContext().getAttribute("javax.servlet.context.tempdir");
if (tmpDir == null) {
tmpDir = new File(System.getenv("java.io.tmpdir"));
}
return tmpDir.getAbsolutePath();
}So it looks like what we need to do here is to make this attribute configurable via our codebase to make it point to a location we want to have it. This should be a fairly small thing to do - the research was the tough part. |
|
Two things I do best... stirring the pot... expanding the scope... I'll just leave this here... for now...
|
Yeah, this github issue is potentially HUGE/all-consuming, but we should have addressed this one small thing - making this PrimeFaces temp directory (more easily) configurable. So this is what I've been doing on IQSS own prod. servers; to maintain that web upload temp on a separate partition. This is obviously a difficult configuration method. So yes, it would be great to have this value stored in a normal system property and then added to the context in the application code. The comment I'm quoting is almost a year old, maybe it's time... I'd be happy to make a PR just for this feature. Just need to read up on where this code needs to go. |
|
P.S. Thinking about it, we should've documented the hack above too in the guides somewhere. |
|
@landreev if this is coming from Sth like (MPCONFIG would allow to use a system property, env var or other source for this) |
Just a reminder that an issue about documenting temp directories is mentioned above a couple times: #2848 Obviously, we could just document the one hack. Even that would probably help a lot. |
|
I'm trying to remember, if I had tried variable substitution, and concluded it wasn't working; or not. Will try again. |
|
I did have a recollection of an issue for documenting the other temp spaces (the issue with this one, it's not even on the radar for many installations). Surprised and embarrassed it hasn't been addressed yet. |
As outlined in IQSS#6656, files will be stored in `domaindir/generated/jsp/dataverse` during upload before being moved to our temporary ingest file space at `$dataverse.files.directory/temp`. With this commit, we enable to configure a different place for these kind of generated temporary files by using MPCONFIG variable substitution inside of glassfish-web.xml. Also sorts the content of glassfish-web.xml into order as specified by the XSD. Documentation of the setting is provided.
feat(upload): make upload file storage path configurable #6656
…image and Kubernetes deployment. Will be removed when gdcc#178 gets solved.
…image and Kubernetes deployment. Will be removed when gdcc#178 gets solved.
…image and Kubernetes deployment. Will be removed when gdcc#178 gets solved.
Intro
This issues evokes from https://groups.google.com/d/topic/dataverse-community/IB1wYpoU_H8
A rough summary: when you upload data via web UI, the data is stored at a few different places before commited to real storage, as it needs to be processed, analyzed and maybe worked on.
Nonetheless, this could be tweaked, especially when starting to deal with larger data. This is kind of related to #6489. As not every big data installation might want to expose its S3 storage to the internet or even does not use this new functionality at all, this should still be addressed. From a UI and UX perspective, which is touched here, issues #6604 and #6605 seem related.
Mentions: @pdurbin @djbrooke @TaniaSchlatter @scolapasta @qqmyers @landreev
Discovery
I tested this on my local Kubernetes cluster and created a little video of what happens when. After that I digged a bit through the code to see if there are potential problems ahead for our installation.
Please enjoy the following demo (click on the image):

Things to note:
glassfish/domains/domain1/generated/jsp/dataversefolder, as already stated in the Google Group posting.tempfolder, living at the configured place of JVM optiondataverse.files. Unless this copy is done, the user experience is a "hanging progress bar at 100%".generatedfolder is not deleted.Analysis
Now let's see what happens in the background from an implementation view. The following diagram is a bit shortened and leaves out edge cases to make it more understandable.
Click on the image to access the source.
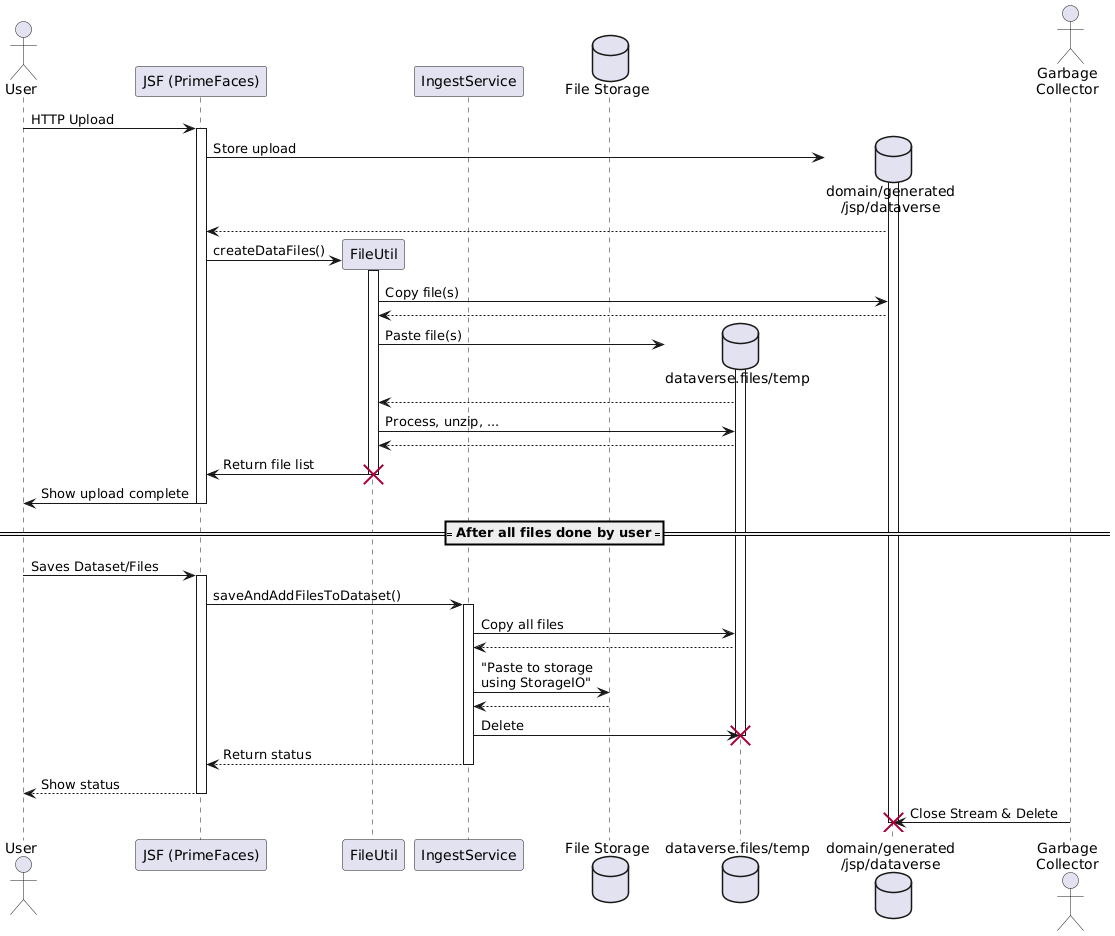
Things to note here:
InputStreamcloses. This is however not the case in current codebase, which seems to be at least one cause for dangling files as noticed in the discovery above.dataverse.fileshas been configured for. The docs lack of that information and it has a great danger of disks filling up, breaking things.Ideas and TODOs
I feel like this is a medium sized issue, as it needs quite a bit of refactoring.
A collection of ideas what to do next:
The text was updated successfully, but these errors were encountered: