DeepFillv2 release #62
Comments
|
I am quite amazed by the effect of DeepFillv2 !!! Also, I want to know the expected date of the code release since I want to know how it works. Thank you! |
|
+1 Here is my PyTorch code for the gated convolution. I want to hear your feedback. |
|
First, thanks for your interest! @yu45020 It seems your code is not the gated convolution we proposed. Please check carefully of the tech report.
x1 = self.conv1(x)
x2 = self.conv2(x)
x = sigmoid(x2) * activation(x1)Or a slightly faster implementation on GPU: Hope it helps. |
|
Great! By the way, I re-implemented 'Image Inpainting for Irregular Holes Using Partial Convolutions' before coming to your paper, so I was wondering where should I put the mask. But I was wrong. |
|
Really simple and efficient way ! Great idea! |
|
@limchaos Thanks for your interest first! You mentioned a good point: what's the performance difference w.r.t. different GAN architecture. The roadmap of GANs for inpainting is like: one vanilla D arch -> two global/local D arch -> SN-PatchGAN. We did not show comparison results in main paper because:
|
|
@JiahuiYu I see,thanks for your fast reply :) |
|
@JiahuiYu Thanks for your excellent work. I'm tring to reimplement the DeepFillv2 based on your code. But the results seem not good enough, can i ask you some details about it?
Thank you again! |
|
Hi, thanks for your interest.
|
|
@JiahuiYu Thanks for the reply. So will the AEloss be calculated on the whole image with the same weights between foreground and background regions? |
|
@liouxy Yes. foreground:background is 1:1 . Since the mask is no longer rectangular, it is difficult to calculate the discounted weights proposed in CVPR paper. So the final solution is just a simple pixel-wise loss over input and output. |
|
@JiahuiYu Thanks for your former help. I've read your paper carefully for several times and the implementation is almost done. However. some details confused me so I need your help
|
|
@xhh232018 I fail to find the difference between these two approaches. For the second one, I guess it is not necessary to put batch norm on top of spectral norm. PyTorch example ps: Do you find the GAN hard to train ? |
|
@xhh232018 @yu45020 I recommend this official implementation of SN-GAN. |
|
@yu45020 I got the same problem of GAN training the g_loss is quite high. Have you solved this problem? |
|
@xhh232018 I find L1 loss decreases quickly but hinge loss decreases slowly. Here are what I have tried but don't work:
I have not trained the model for a long time since I rent GPU. I am wondering whether using pre-trained networks as discriminator will help. But if I replace the partial convolution with gated convolution and use the complicated loss function from this paper, the improvement is visible within few iterations. I might misunderstand some details in GAN. |
|
@yu45020 An expert told me that It is common that training GAN is a quite long process. Also the author mentioned that there is no batch-norm operation in the network. I have trained the Deepfill V1 for 5 days in order to get good results. I tried PCONV 2 weeks ago. It converges very quickly because its structure is relatively simple. I only trained the Deepfill V2 for 2 days. I will see what it will happen after several days training.. |
|
Thanks for the info. I notice the deep fill v2 removes batch norm to reduce color consistence since the author mentioned it above. But my application focuses on black/white images, and batch norm helps. |
|
|

|
@shihaobai You are correct. |
|
@JiahuiYu Thanks for your reply. It does help. I also have an another question. I tried to use relu as activation for gated-conv. But i found my d_loss reached convergence quickly so that my generator couldn't learn well. When i used elu instead of it. The model worked better. So i think there must be something wrong in my discriminator or the frequency i trained my generator and discriminator. How often do you train the discriminator and generator? and here is my discriminator code: def dis_conv(x, cnum, ksize=5, stride=2, name='conv', training=True): ` ` |
|
@shihaobai I have six discriminator convolutions in build_SNGAN_discriminator. |
|
I implemented DeepFillv2 and now training it, but the quality of the generative results aren't good. How many iterations did you need to get the high-quality results in the paper? |
|
@JiahuiYu Hi, thanks you code and paper :) |
|
@annzheng You can have a try. I train DeepFillv2 with Tesla V100 GPU, 16GB VRAM. |
|
@nogu-atsu FYI, I use mini-batch size 24. I train it on Tesla V100 GPU, 16 GB VRAM for five days, with GPU utilization almost 100%. |
|
@JiahuiYu Hi, thank your code and paper
Including the first and last layer output? |
|
@JiahuiYu I have three more questions.
|
|
@aiueogawa Hi, here are some information:
|
|
Hey Jiahui, Thanks for being so responsive on this thread about deepfillv2. |
|
@theahura After training, we only use the generator for inpainting. Thus 4.1M is only the generator. |
|
A quick follow up. In the paper you describe using a coarse network and a refinement network from your previous work. Is the coarse network trained separately/has its own loss as per the previous work? My own implementations of deepfillv2 have trouble learning anything useful in the coarse network. Thanks again for your help and quick answers! |
|
@theahura The coarse network exactly follows the training of this code, where we use a pixel-wise loss as additional supervision. They are trained jointly, instead of separately. |
|
So in DeepfillV2, both the final output of the overall network and the output of the coarse network get a pixelwise loss? |
|
@theahura Yes. |
|
@JiahuiYu You said two different things about it.
I wonder which is right. Intuitively, SN-PatchGAN loss wants output of the discriminator for fake images generated from the generator to be -1 while that for real images to be +1, hence the activation at the last layer is desired to be symmetric in its domain. What activation function did you use as that in the last layer in the discriminator for DeepFillv2? |
|
@aiueogawa Hi thanks for your interest and good question. Both my answers of #62 is correct. We use the loss function of SN-GANs as claimed in What you are considering is about the activation function of last layer. You are correct that intuitively activation at the last layer is desired to be symmetric in its domain. However, I believe as long as the activation function can cover the domain of (-1, 1) and 1-Lipschitz condition holds, it is fine. Practically we find leaky relu (piecewise linear) works well. I guess using other activation function in last layer may not affect performance a lot. Feel free to report your results here if you have a try. |
|
@JiahuiYu Thank you! I see. |
|
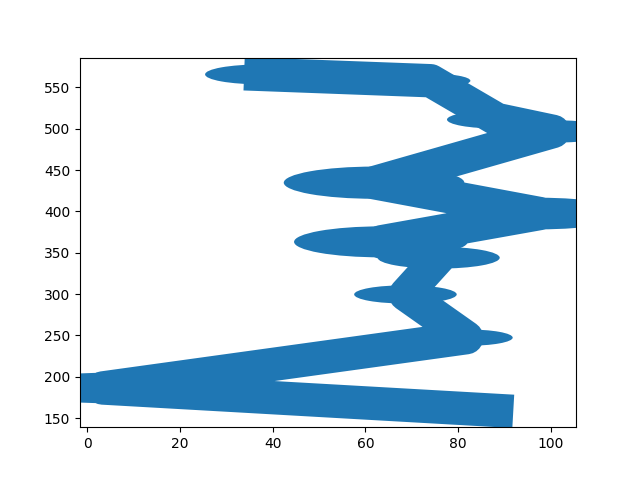
@JiahuiYu I implemented the algorithm for generating random mask as suggested in the paper. Following are the masks which the algorithm generates. |
|
@khemrajrathore The joints between two lines should be very smooth as shown in our paper. It is done by setting the joint width the same as line width. ps: to make this issue compact, I have modified your image as links instead of direct display. |
|
@JiahuiYu |
|
@aiueogawa @khemrajrathore I am using: min_num_vertex = 4
max_num_vertex = 12
mean_angle = 2*math.pi / 5
angle_range = 2*math.pi / 15
min_width = 12
max_width = 40
average_length = math.sqrt(H*H+W*W) / 8
l = np.clip(np.random.normal(loc=average_length, scale= average_length//2), 0, 2*average_length) |
|
@JiahuiYu Thanks for your answer.
However, how |
|
@khemrajrathore |
|
@aiueogawa I set it as |
|
@JiahuiYu Thanks for revised information. Q1:
How are the loss values are summed up into a single total loss.
in the DeepFillv2 paper. Q2:
and another option in DeepFillv2.
In DeepFillv2, what values did you use as Q3: Q4: Q5:
Are multiple strokes used in training? P.S.
I already tried to ask all my related questions for one time but you always answered only part of my questions. Therefore, I asked you many times. |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
@aiueogawa I have merged your questions and deleted redundant ones. Can you please ask all your questions for one time instead of long mutual conversations? So others who see this issue can have a clean view. Q1: Reduce mean, as shown here. |
|
@aiueogawa I have opened a specific issue for your case. I do not understand what is confusing to you so we can communicate in issue #158. I am trying my best to help. |
Really nice work and great idea for the DeepFillv2!! Any plan and expected date to release the DeepFillv2 code?
The text was updated successfully, but these errors were encountered: