implement "nearly division less" algorithm for rand(a:b) #29240
Conversation
|
cc @affans |
|
Can't the behavior of |
|
Presumably, it changes what random numbers are generated. |
|
Arguably, it's only breaking API for those cases where the code uses |
|
Just saw a reference to this on Discourse. |
|
See also the discussion in #30494 — I'm skeptical that we should guarantee that the exact sequence of random number for a given seed is a stable part of the API. |
I agree that that PR set a precedent, i.e. implicitly a rule that changing the stream of generated number is considered as "minor change". Should this be triaged to confirm? Note though that we use a lot of PS: I rushed a lot of PRs before the release of Julia 1 only because I was under the belief that we would guarantee the reproducibility of streams, I'm pretty sure this idea was in the air somehow... but it was for the best I guess! |
stdlib/Random/src/generation.jl
Outdated
| # 2) "Default" which tries to use as few entropy bits as possible, at the cost of a | ||
| # a bigger upfront price associated with the creation of the sampler | ||
| # 3) "Nearly Division Less", which is the fastest algorithm for types of size | ||
| # up to 64 bits. This will be the default in a future realease. |
There was a problem hiding this comment.
| # up to 64 bits. This will be the default in a future realease. | |
| # up to 64 bits. This will be the default in a future release. |
|
People generally set Random.seed in tests not because they care about the exact sequence of random numbers but because they don’t want tests to fail on rare occasions when something extremely improbable occurs (e.g. a random matrix happens to be nearly singular, exacerbating roundoff errors). By the same token, however, such tests are extremely unlikely to fail if we change the pseudorandom stream. |
|
Yes of course you are right, I somehow confused this use case with uses of |
|
While updating to make this algorithm (NDL) the default, I realised that we have a test garanteeing that e.g. Unfortunately here this means that if we want to maintain this property, there is a (small) cost to pay. I may have made a mistake of course, but this is what I currently understand. Let's call "NDL Unified" the modification of Here are the observations (see graph below) for
(EDIT: I don't know why the x/y labels disappear when saving the graph to disk, x is "log2(range length)" and y is "time in ns".) So, I my favorite solution is to drop the guarantee that |
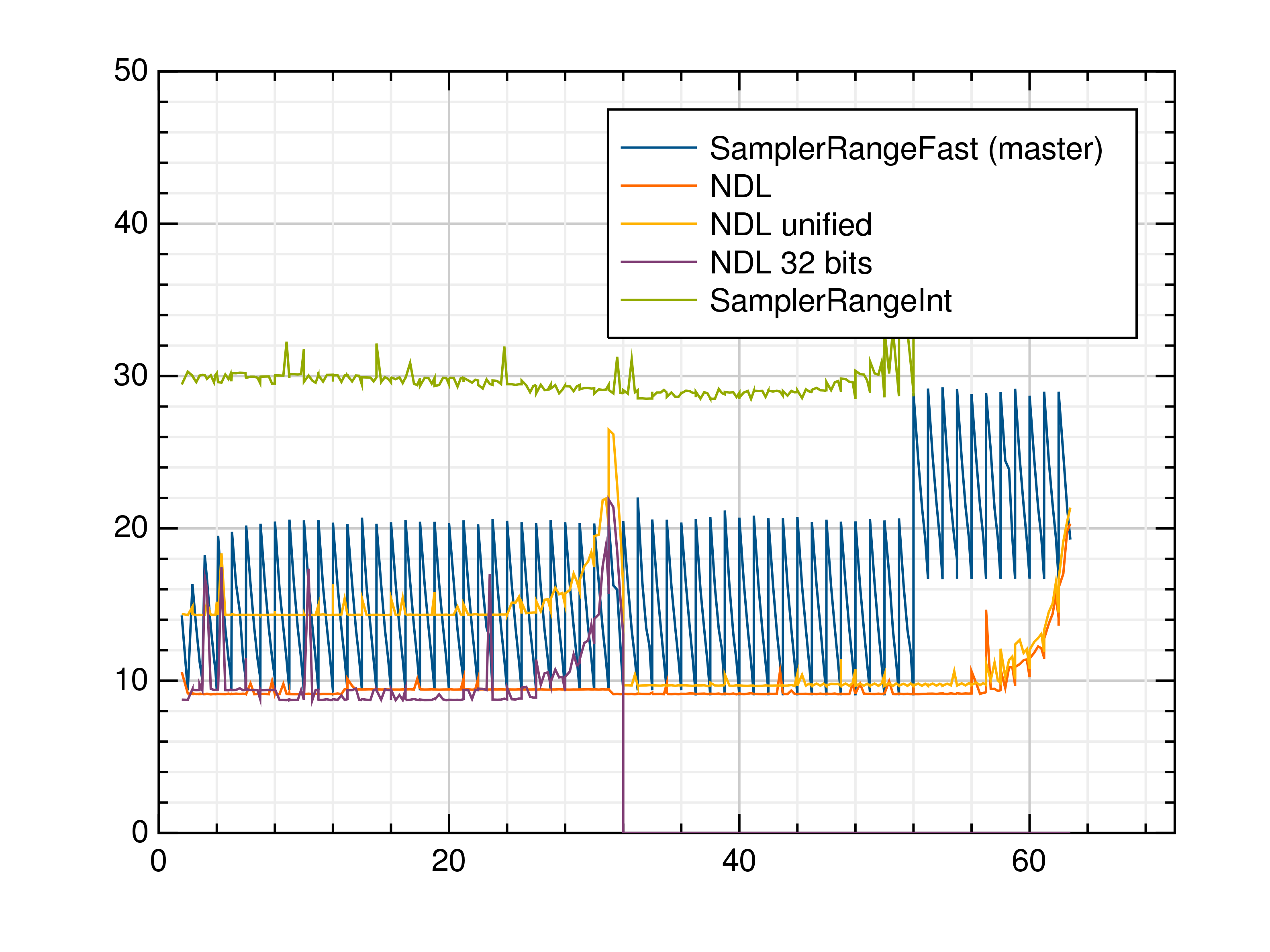
|
This goes into the next release and won't be backported, right? Then I am all for dropping the guarantees. However, |
It would be great that it goes in the next release, but for sure won't be backported indeed!
Yeah, there is a |
|
Here's what seems like a minority voice. When developing some simulations, I like to be able to compare results with previous runs. I guess this is a sort of unit test. I might experiment with algorithmic changes, performance enhancements etc. and then re-run the sim and check whether I'm still getting the same results. In fact, I just upgraded from Julia v0.6 through v0.7, v1.0 and v1.1, and wanted to compare the new sim results to the old v0.6 ones. But I needed to implement the same custom I understand the tension between progress and being held back by guarantees, especially when it is deemed the guarantee is of little benefit &/or the progress is of significant benefit. However, I do want to point out the difference between random sequence guarantees across Julia versions, and across architectures within the same Julia version. I run my simulations across a network cluster and check the results against previous runs. In my case, all machines are 64-bit, but this would break in mixed-architecture clusters. I don't like that the random sequence guarantee is broken across versions, but I'm happy to sacrifice that for progress. I feel less comfortable if the guarantee is broken across architectures on the same Julia version. |
|
I appreciate the usefulness of compatibility between architectures, however it's already not compatible for I would favor having a opt-in way of getting reproducibility. One of them would be to simply create the range with |
|
Also, I just read Numpy's policy on RNG https://www.numpy.org/neps/nep-0019-rng-policy.html, this may be relevant to the discussion. |
|
Can we put up some docs for an official reproducibility + rng-stream policy? Is there an issue/PR that discusses that? As far as I understood, (1) we have no reproducibility between 32 bit and 64 bit anyway, (2) new releases may break RNG streams 32208, 30617, (3) we attempt to avoid breaking RNG streams on bugfix / backports. Do we attempt reproducibility between architectures (e.g. aarch64 vs x86_64 vs power)? Since we break RNG streams on releases, it would be almost sensible to codify this by having seeding of the RNG incorporate the version (like The worst case is random streams being almost reproducible, which is what we have now (and what numpy appears to be doing). If we codify this dependence of RNG streams, then we also lay the groundwork for replacing mersenne twister with alternatives that are faster (e.g. xoroshiro) or better (i.e. cryptographic like aes-ctr with hardware acceleration). |
The comment from which I grabbed the link I posted above was just requesting that, and there was a small discussion yesterday on slack (triage channel) on this topic too. There is no open issue AFAIK though. I find your idea of "codifying" in each release the breaking behavior in the seeding process quite interesting! |
|
Official docs on reproducibility of random streams was merged in #33350. |
|
I have also for some time wanted to hash seed values with a cryptographic hash like SHA1 or SHA256 before passing that seed value on to the underlying RNG for actual seeding. The reason being that there are often bad seed values for RNGs and there's strong evidence that close RNG seed values produce streams that have significant correlation. By using a cryptographic hash on the seed value before passing it on to the RNG, you get (more) thoroughly uncorrelated streams for sequential seed values. It also makes it easy to use a tuple of seed values, which can be handy in situations where you want a whole family of reproducible RNG streams. |
This is great, but does not explicitly cover the question (which needs to be resolved here): must |
Sounds like a great idea, if no-one beats me to it, I will try to implement a POC when I have some time. |
I think this is a good property to have. Suppose you have a stochastic program that is working on a 64-bit machine but failing on 32-bit, and you are trying to isolate the source of the failure. Not being able to generate the same random number stream on both architectures with the same Julia versions seems like it would make debugging a lot harder. |
Certainly, but in the present case it's at the cost of performance, and there is a work-around (use |
|
I overlooked this issue. Let me come back. |
|
I think we can generally optimize for 64-bit systems at the expense of 32-bit ones. If people need really high performance, they're generally not working on 32-bit computers these days. |
I fully agree. But even then, we have a decision to make: do we keep "stream compatibility" between 32 and 64 architectures (i.e.
I would vote for the latter option. Note that with other RNGs, 64 bits generation might be the "native output" even on 32-bits systems, in which case it's possible to have "sream compatibility" for free. Off-Topic: since a couple of days, I was thinking to implement passing seeds to a crypto hash function, and I realize now it was not at all an original thought of mine 🙈 ! |
Cf. https://arxiv.org/abs/1805.10941.
Closes #20582, #29004.
This is still about 30 percent slower than the "biased" solution (e.g. #28987), but as fast as the "best case" of the current version (when the range length is a power of 2). So this is strictly better, and should become the default version in a future (major) release. How do we make this available in the meantime?
rand(Random.fast(a:b))is what the PR currently implements.